1 of 26
Download to read offline
















Ad
Recommended
Sparse Coding§Ú§ §Ž§Ŕ§Į ż Ĺ§Ú Ļ§Ô§ļņŪĹ‚§Ļ§Ž£®PCA§šICA§»§őťvāS£©
Sparse Coding§Ú§ §Ž§Ŕ§Į ż Ĺ§Ú Ļ§Ô§ļņŪĹ‚§Ļ§Ž£®PCA§šICA§»§őťvāS£©Teppei Kurita
?
Sparse Coding§ň§ń§§§∆’٧Í∑Ķ§Ž°£Ń”•‚•ł•Ś•ť◊Ó ĽĮ§»Ľķ–Ķ—ßŌį1’¬
Ń”•‚•ł•Ś•ť◊Ó ĽĮ§»Ľķ–Ķ—ßŌį1’¬Hakky St
?
Ľķ–Ķ—ßŌį•◊•Ū•’•ß•√•∑•Á• •Ž•∑•Í©`•ļ§őŃ”•‚•ł•Ś•ť◊Ó ĽĮ§»Ľķ–Ķ—ßŌį§ő1’¬§őįkĪŪ◊ ŃŌ§«§Ļ°£°ĺ•Š•Ņ•Ķ©`•Ŕ•§°Ņ ż Ĺ•…•Í•÷•ůĹŐ ¶§Ę§Í—ßŌį
°ĺ•Š•Ņ•Ķ©`•Ŕ•§°Ņ ż Ĺ•…•Í•÷•ůĹŐ ¶§Ę§Í—ßŌįcvpaper. challenge
?
cvpaper.challenge §ő •Š•Ņ•Ķ©`•Ŕ•§įkĪŪ•Ļ•ť•§•…§«§Ļ°£
cvpaper.challenge§Ō•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů∑÷“į§őĹ٧ڔ≥§∑°Ę•»•ž•ů•…§ÚĄď§Í≥Ų§ĻŐŰĎť§«§Ļ°£’ďőń•Ķ•ř•Í◊ų≥…?•Ę•§•«•£•ĘŅľįł?◊h’ď?Ćg◊į?’ďőńÕ∂łŚ§ň»°§ÍĹM§Ŗ°Ę∑≤§ś§Ž÷™◊R§ÚĻ≤”–§∑§ř§Ļ°£
http://xpaperchallenge.org/cv/ ērŌĶŃ–Ĺ‚őŲ§ő Ļ§§∑Ĺ - TokyoWebMining #17
ērŌĶŃ–Ĺ‚őŲ§ő Ļ§§∑Ĺ - TokyoWebMining #17horihorio
?
ĪŌĶŃ–Ĺ‚őŲ§ÚĆgľ §ő•«©`•Ņ§š•”•ł•Õ•Ļ§ň ”√§Ļ§Ž≥°ļŌ§ň§Ō°ĘĹŐŅ∆ ť§«—ߧů§ņņŪ¬ŘŐŚŌĶ§»§Ō“ž§ §√§ŅįkŌŽ§őň≥–Ú§šŅĪňý§¨§Ę§Ž§ő§«§Ō£Ņ§»§őő Ő‚“‚ ∂§»ó Ő÷÷–§őįł§Ú…‹Ĺť§§§Ņ§∑§ř§Ļ°£įš≥’∑÷“į§ň§™§Ī§Ž•Ķ©`•Ŕ•§∑Ĺ∑®
įš≥’∑÷“į§ň§™§Ī§Ž•Ķ©`•Ŕ•§∑Ĺ∑®Hirokatsu Kataoka
?
•Ķ©`•Ŕ•§∑Ĺ∑®§š•Ę•§•«•£•Ę§őįkŌŽ∑®§ň§ń§§§∆§ř§»§Š§ř§∑§Ņ£ģCurriculum Learning £®ťvĖ|CV√„ŹäĽŠ£©
Curriculum Learning £®ťvĖ|CV√„ŹäĽŠ£©Yoshitaka Ushiku
?
2015ńÍ5‘¬30»’Ķŕ29Ľō•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů√„ŹäĽŠ@ťvĖ|°ł”–√Ż’ďőń§Ú’i§ŗĽŠ°ĻįkĪŪ”√ŔYŃŌ°£
Curriculum Learning [Bengio+, ICML 2009] §»§Ĺ§őŠŠĺA§ÚĹBĹť°£įŅĪŤ≥ŔĺĪ≥ĺĺĪ≥ķĪūįý»Ž√Ň£¶◊Ó–¬∂ĮŌÚ
įŅĪŤ≥ŔĺĪ≥ĺĺĪ≥ķĪūįý»Ž√Ň£¶◊Ó–¬∂ĮŌÚMotokawa Tetsuya
?
4/16§ň––§Ô§ž§Ņ÷Ģ≤®īů§ő ÷ČV»ŰŃ÷—–ļŌÕ¨•ľ•Ŗ§«§őįkĪŪ•Ļ•ť•§•…§«§Ļ°£»Ģīő‘™Ķ„»ļ§Ú»°§ÍíQ§¶•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ő•Ķ©`•Ŕ•§
»Ģīő‘™Ķ„»ļ§Ú»°§ÍíQ§¶•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ő•Ķ©`•Ŕ•§Naoya Chiba
?
Ver. 2§ÚĻęť_§∑§ř§∑§Ņ: https://speakerdeck.com/nnchiba/point-cloud-deep-learning-survey-ver-2
PointNet«įŠŠ°ęECCV2018§őĶ„»ļ…ÓĆ”—ßŃēťvŖB§ő’ďőń§ň§ń§§§∆§ř§»§Š§ř§∑§Ņ£ģ
ťgŖ`§§§ §…§Ę§ž§–§ī÷ł’™ŪĒ§Ī§Ž§»§Ę§Í§¨§Ņ§§§«§Ļ£ģĽ≠ŌŮ…ķ≥…?…ķ≥…•‚•«•Ž •Š•Ņ•Ķ©`•Ŕ•§
Ľ≠ŌŮ…ķ≥…?…ķ≥…•‚•«•Ž •Š•Ņ•Ķ©`•Ŕ•§cvpaper. challenge
?
The document presents an overview of the research group 'Generations' focused on image generation and generative models, detailing their contributions to fields like unpaired image-to-image translation and domain adaptation. It highlights various studies and techniques, including CycleGAN and neural radiance fields, aimed at enhancing image translation while preserving contextual integrity. The group is actively seeking new members for collaboration on these innovative themes.ĪŠĺĪĪ Ī įŅ/≥ß4Ĺ‚’h
ĪŠĺĪĪ Ī įŅ/≥ß4Ĺ‚’hMorpho, Inc.
?
Morpho Tech Bolg§Ť§ÍĪĺŔYŃŌ§ňťv§Ļ§Ž”õ ¬§Ú§ī”E§Į§ņ§Ķ§§°£
?°łĪŠĺĪĪ Ī įŅ/≥ß4Ĺ‚’h°Ļ£ļhttps://techblog.morphoinc.com/entry/2022/05/24/102648
?ąŐĻP’Ŗ£ļCTO “•Í•Ķ©`•Ń•„©`°°Ĺ«ŐÔ
?Morpho Tech Blog: https://techblog.morphoinc.com/
?Morpho, Inc.: https://www.morphoinc.com/—–ĺŅĄŅ¬ ĽĮTips Ver.2
—–ĺŅĄŅ¬ ĽĮTips Ver.2cvpaper. challenge
?
The document outlines strategies for enhancing research efficiency, emphasizing the importance of effective literature review, management skills, and collaborative efforts among researchers. It discusses two main methods for skill enhancement: learning from peers and leveraging online resources, while highlighting the challenges and advantages of each approach. Additionally, it provides insights into the dynamics of various research labs, communication practices, and the value of sharing knowledge across institutions.°ĺDL›Ü’iĽŠ°ŅWIRE: Wavelet Implicit Neural Representations
°ĺDL›Ü’iĽŠ°ŅWIRE: Wavelet Implicit Neural RepresentationsDeep Learning JP
?
2023/1/20
Deep Learning JP
http://deeplearning.jp/seminar-2/Deep Learning§»Ľ≠ŌŮ’J◊R
°°
°ęös ∑?ņŪ’ď?Ćgľý°ę
Deep Learning§»Ľ≠ŌŮ’J◊R
°°
°ęös ∑?ņŪ’ď?Ćgľý°ęnlab_utokyo
?
Deep Learning§»Ľ≠ŌŮ’J◊R
°°
°ęös ∑?ņŪ’ď?Ćgľý°ęControl as Inference (ŹäĽĮ—ßŃē§»•Ŕ•§•ļĹy”č)
Control as Inference (ŹäĽĮ—ßŃē§»•Ŕ•§•ļĹy”č)Shohei Taniguchi
?
The document discusses control as inference in Markov decision processes (MDPs) and partially observable MDPs (POMDPs). It introduces optimality variables that represent whether a state-action pair is optimal or not. It formulates the optimal action-value function Q* and optimal value function V* in terms of these optimality variables and the reward and transition distributions. Q* is defined as the log probability of a state-action pair being optimal, and V* is defined as the log probability of a state being optimal. Bellman equations are derived relating Q* and V* to the reward and next state value.ŹäĽĮ—ßŃēľľ–g§»•≤©`•ŗ AI ? Ĺ٧«§≠§Ž ¬§»ĹŮŠŠ§«§≠§∆”Ż§∑§§ ¬ ?
ŹäĽĮ—ßŃēľľ–g§»•≤©`•ŗ AI ? Ĺ٧«§≠§Ž ¬§»ĹŮŠŠ§«§≠§∆”Ż§∑§§ ¬ ?”” ľ◊“į
?
SHIBUYA Synapse #2 ( https://shibuya.ai/ ) §«§őĶ«ČĮŔYŃŌ§Ú£¨Ļęť_”√§ňĺéľĮ£ģSSII2022 [TS1] Transformer§ő◊Ó«įĺÄ? ģířz§Ŗ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őŌ»§ō ?
SSII2022 [TS1] Transformer§ő◊Ó«įĺÄ? ģířz§Ŗ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őŌ»§ō ?SSII
?
6/8 (ňģ) 09:45°ę10:55•Š•§•ůĽŠąŲ
÷véü£ļŇ£ĺ√ Ōť–Ę Ō
°°°°£®•™•ŗ•Ū•ů•Ķ•§•ň•√•Į•®•√•Į•Ļ÷Í ĹĽŠ…Á£©
łŇ“™£ļ 2017ńͧňôC–Ķ∑≠‘U§ÚĆĚŌů§»§∑§∆ŐŠįł§Ķ§ž§ŅTransformer§Ō°ĘŹĺņī§őģířz§Ŗ§š‘ŔéʧÚŇҧ∑§∆◊‘ľļ◊Ę“‚ôCėč§ÚĽÓ”√§∑§Ņ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§«§Ę§Ž°£2019ńÍŪē§ę§ť•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů∑÷“į§«§‚ľĪňŔ§ňŹÍ”√§¨ŖM§ů§«§™§Í°Ę§Ť§Í»Š‹õ§ę§ńłŖĺę∂»§ •Õ•√•»•Ô©`•Įėč‘ž§»§∑§∆§őĶōőĽ§Úī_Ńʧ∑§ń§ń§Ę§Ž°£Īĺ•Ń•Ś©`•»•Í•Ę•Ž§«§Ō°ĘTransformer§™§Ť§”§Ĺ§ő÷‹řx§ő•Õ•√•»•Ô©`•Įėč‘ž§ň§ń§§§∆°Ę•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů§ō§őŹÍ”√§Ú÷––ń§»§∑§Ņ◊Ó«įĺħڳҒh§Ļ§Ž°£
Generative Adversarial Imitation Learning§őĹBĹť£®RL•Ę©`•≠•∆•Į•Ń•„√„ŹäĽŠ£©
Generative Adversarial Imitation Learning§őĹBĹť£®RL•Ę©`•≠•∆•Į•Ń•„√„ŹäĽŠ£©Yusuke Nakata
?
Generative Adversarial Imitation Learning §őĹBĹť•Ļ•ť•§•…
Ćg◊į•≥©`•…: https://github.com/uidilr/gail_ppo_tfSSII2019OS: …ÓĆ”—ßŃē§ň§ę§ę§Žērťg§Ú∂Ő§Į§∑§∆§Ŗ§ř§Ľ§ů§ę£Ņ °ę∑÷…Ę—ßŃē§őĄŠ§Š°ę
SSII2019OS: …ÓĆ”—ßŃē§ň§ę§ę§Žērťg§Ú∂Ő§Į§∑§∆§Ŗ§ř§Ľ§ů§ę£Ņ °ę∑÷…Ę—ßŃē§őĄŠ§Š°ęSSII
?
SSII2019 •™©`•¨• •§•ļ•…•Ľ•√•∑•Á•ů3°ł…ÓĆ”—ßŃē§őłŖňŔĽĮ °ęłŖňŔ•Ń•√•◊°Ę∑÷…Ę—ßŃē°Ę›XŃŅ•‚•«•Ž°ę°Ļ
6‘¬14»’(Ĺū) 10:35?12:05 (•Š•§•ů•Ř©`•Ž)[DL›Ü’iĽŠ]Vision Transformer with Deformable Attention £®Deformable Attention Tra...
[DL›Ü’iĽŠ]Vision Transformer with Deformable Attention £®Deformable Attention Tra...Deep Learning JP
?
2022/01/14
Deep Learning JP:
http://deeplearning.jp/seminar-2/Ī łť≤—≥Ę—ßŌį’Ŗ§ę§ť»Ž§Ž…Ó≤„…ķ≥…•‚•«•Ž»Ž√Ň
Ī łť≤—≥Ę—ßŌį’Ŗ§ę§ť»Ž§Ž…Ó≤„…ķ≥…•‚•«•Ž»Ž√Ňtmtm otm
?
•ľ•Ŗ§«įkĪŪ§∑§Ņ◊ ŃŌ§«§Ļ°£ľšő•§√§∆§§§Ņ§ťį’∑…ĺĪ≥Ŕ≥ŔĪūįý§ňѨ¬Á§Į§ņ§Ķ§§°£į™ī«≥Ŕ≥Ŕ≤Ļ≥ĺ≥ĺ≥Ś190°ĺDL›Ü’iĽŠ°ŅA Path Towards Autonomous Machine Intelligence
°ĺDL›Ü’iĽŠ°ŅA Path Towards Autonomous Machine IntelligenceDeep Learning JP
?
2022/7/29
Deep Learning JP
http://deeplearning.jp/seminar-2/įŕ∂Ŕ≥ʬ÷’iĽŠĪ’ŌŗĽ•«ťĪ®ŃŅ◊ÓīůĽĮ§ň§Ť§ŽĪŪŌ÷—ßŌį
įŕ∂Ŕ≥ʬ÷’iĽŠĪ’ŌŗĽ•«ťĪ®ŃŅ◊ÓīůĽĮ§ň§Ť§ŽĪŪŌ÷—ßŌįDeep Learning JP
?
2019/09/13
Deep Learning JP:
http://deeplearning.jp/seminar-2/ łť§«—ߧ÷”Q≤ž•«©`•Ņ§«§ő“ÚĻŻÕ∆∂®
łť§«—ߧ÷”Q≤ž•«©`•Ņ§«§ő“ÚĻŻÕ∆∂®Hiroki Matsui
?
20120310 TokyoR#21 §«įkĪŪ§∑§ŅŔYŃŌ§«§Ļ°£’`§Í§š≤Ľ’żī_§ ≤Ņ∑÷§¨§Ę§Í§ř§∑§Ņ§ť°Ętwitter ID: Hiro_macchan §ř§«§īŖBĹjŌ¬§Ķ§§°£ĶĪ‘ďŔYŃŌ§Ō°Ę§§§Į§ń§ę§ő•Ķ•§•»§őŔYŃŌ§Ú“ż”√§∑§∆§§§ř§Ļ°£≤őŅľőńŌ◊§Ō•Ļ•ť•§•…§ő◊ÓŠŠ§ň”õ›d§∑§ř§∑§Ņ°£∑÷…Ę–Õ«ŅĽĮ—ßŌį ÷∑®§ő◊ÓĹŁ§ő∂ĮŌÚ§»∑÷…Ęľ∆ň„•’•ž©`•ŗ•Ô©`•Įłť≤Ļ≤‚§ň§Ť§ŽĆg◊į§ő ‘§Ŗ
∑÷…Ę–Õ«ŅĽĮ—ßŌį ÷∑®§ő◊ÓĹŁ§ő∂ĮŌÚ§»∑÷…Ęľ∆ň„•’•ž©`•ŗ•Ô©`•Įłť≤Ļ≤‚§ň§Ť§ŽĆg◊į§ő ‘§ŖSusumuOTA
?
(1) ∑÷…Ę–ÕŹäĽĮ—ßŃē ÷∑®§ő◊ÓĹŁ§őĄ”ŌÚ§Ú, Őō§ň MuZero (2019ńÍ11‘¬), Agent57 (2020ńÍ3‘¬)§Ú÷––ń§ňĹBĹť§∑§ř§Ļ.
(2) ∑÷…Ę”čň„•’•ž©`•ŗ•Ô©`•Į Ray §ň§Ť§√§∆•∑•ů•◊•Ž§ ∑÷…Ę–ÕŹäĽĮ—ßŃē ÷∑®§ÚĆg◊į§∑, Amazon EC2…Ō§ň•Į•ť•Ļ•Ņ§ÚėčļB§∑§∆∑÷…Ę”čň„§Ú––§¶∑Ĺ∑®§ÚĹ‚’h§∑§ř§Ļ.
- ĶĪ»’ĹBĹť§∑§Ņ•Ĺ©`•Ļ•≥©`•…§»‘O∂®•’•°•§•Ž
https://github.com/susumuota/distributed_experience_replay
- Do2dle√„ŹäĽŠ§őconnpass•ŕ©`•ł
https://do2dle.connpass.com/event/178184/More Related Content
What's hot (20)
Curriculum Learning £®ťvĖ|CV√„ŹäĽŠ£©
Curriculum Learning £®ťvĖ|CV√„ŹäĽŠ£©Yoshitaka Ushiku
?
2015ńÍ5‘¬30»’Ķŕ29Ľō•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů√„ŹäĽŠ@ťvĖ|°ł”–√Ż’ďőń§Ú’i§ŗĽŠ°ĻįkĪŪ”√ŔYŃŌ°£
Curriculum Learning [Bengio+, ICML 2009] §»§Ĺ§őŠŠĺA§ÚĹBĹť°£įŅĪŤ≥ŔĺĪ≥ĺĺĪ≥ķĪūįý»Ž√Ň£¶◊Ó–¬∂ĮŌÚ
įŅĪŤ≥ŔĺĪ≥ĺĺĪ≥ķĪūįý»Ž√Ň£¶◊Ó–¬∂ĮŌÚMotokawa Tetsuya
?
4/16§ň––§Ô§ž§Ņ÷Ģ≤®īů§ő ÷ČV»ŰŃ÷—–ļŌÕ¨•ľ•Ŗ§«§őįkĪŪ•Ļ•ť•§•…§«§Ļ°£»Ģīő‘™Ķ„»ļ§Ú»°§ÍíQ§¶•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ő•Ķ©`•Ŕ•§
»Ģīő‘™Ķ„»ļ§Ú»°§ÍíQ§¶•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§ő•Ķ©`•Ŕ•§Naoya Chiba
?
Ver. 2§ÚĻęť_§∑§ř§∑§Ņ: https://speakerdeck.com/nnchiba/point-cloud-deep-learning-survey-ver-2
PointNet«įŠŠ°ęECCV2018§őĶ„»ļ…ÓĆ”—ßŃēťvŖB§ő’ďőń§ň§ń§§§∆§ř§»§Š§ř§∑§Ņ£ģ
ťgŖ`§§§ §…§Ę§ž§–§ī÷ł’™ŪĒ§Ī§Ž§»§Ę§Í§¨§Ņ§§§«§Ļ£ģĽ≠ŌŮ…ķ≥…?…ķ≥…•‚•«•Ž •Š•Ņ•Ķ©`•Ŕ•§
Ľ≠ŌŮ…ķ≥…?…ķ≥…•‚•«•Ž •Š•Ņ•Ķ©`•Ŕ•§cvpaper. challenge
?
The document presents an overview of the research group 'Generations' focused on image generation and generative models, detailing their contributions to fields like unpaired image-to-image translation and domain adaptation. It highlights various studies and techniques, including CycleGAN and neural radiance fields, aimed at enhancing image translation while preserving contextual integrity. The group is actively seeking new members for collaboration on these innovative themes.ĪŠĺĪĪ Ī įŅ/≥ß4Ĺ‚’h
ĪŠĺĪĪ Ī įŅ/≥ß4Ĺ‚’hMorpho, Inc.
?
Morpho Tech Bolg§Ť§ÍĪĺŔYŃŌ§ňťv§Ļ§Ž”õ ¬§Ú§ī”E§Į§ņ§Ķ§§°£
?°łĪŠĺĪĪ Ī įŅ/≥ß4Ĺ‚’h°Ļ£ļhttps://techblog.morphoinc.com/entry/2022/05/24/102648
?ąŐĻP’Ŗ£ļCTO “•Í•Ķ©`•Ń•„©`°°Ĺ«ŐÔ
?Morpho Tech Blog: https://techblog.morphoinc.com/
?Morpho, Inc.: https://www.morphoinc.com/—–ĺŅĄŅ¬ ĽĮTips Ver.2
—–ĺŅĄŅ¬ ĽĮTips Ver.2cvpaper. challenge
?
The document outlines strategies for enhancing research efficiency, emphasizing the importance of effective literature review, management skills, and collaborative efforts among researchers. It discusses two main methods for skill enhancement: learning from peers and leveraging online resources, while highlighting the challenges and advantages of each approach. Additionally, it provides insights into the dynamics of various research labs, communication practices, and the value of sharing knowledge across institutions.°ĺDL›Ü’iĽŠ°ŅWIRE: Wavelet Implicit Neural Representations
°ĺDL›Ü’iĽŠ°ŅWIRE: Wavelet Implicit Neural RepresentationsDeep Learning JP
?
2023/1/20
Deep Learning JP
http://deeplearning.jp/seminar-2/Deep Learning§»Ľ≠ŌŮ’J◊R
°°
°ęös ∑?ņŪ’ď?Ćgľý°ę
Deep Learning§»Ľ≠ŌŮ’J◊R
°°
°ęös ∑?ņŪ’ď?Ćgľý°ęnlab_utokyo
?
Deep Learning§»Ľ≠ŌŮ’J◊R
°°
°ęös ∑?ņŪ’ď?Ćgľý°ęControl as Inference (ŹäĽĮ—ßŃē§»•Ŕ•§•ļĹy”č)
Control as Inference (ŹäĽĮ—ßŃē§»•Ŕ•§•ļĹy”č)Shohei Taniguchi
?
The document discusses control as inference in Markov decision processes (MDPs) and partially observable MDPs (POMDPs). It introduces optimality variables that represent whether a state-action pair is optimal or not. It formulates the optimal action-value function Q* and optimal value function V* in terms of these optimality variables and the reward and transition distributions. Q* is defined as the log probability of a state-action pair being optimal, and V* is defined as the log probability of a state being optimal. Bellman equations are derived relating Q* and V* to the reward and next state value.ŹäĽĮ—ßŃēľľ–g§»•≤©`•ŗ AI ? Ĺ٧«§≠§Ž ¬§»ĹŮŠŠ§«§≠§∆”Ż§∑§§ ¬ ?
ŹäĽĮ—ßŃēľľ–g§»•≤©`•ŗ AI ? Ĺ٧«§≠§Ž ¬§»ĹŮŠŠ§«§≠§∆”Ż§∑§§ ¬ ?”” ľ◊“į
?
SHIBUYA Synapse #2 ( https://shibuya.ai/ ) §«§őĶ«ČĮŔYŃŌ§Ú£¨Ļęť_”√§ňĺéľĮ£ģSSII2022 [TS1] Transformer§ő◊Ó«įĺÄ? ģířz§Ŗ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őŌ»§ō ?
SSII2022 [TS1] Transformer§ő◊Ó«įĺÄ? ģířz§Ŗ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§őŌ»§ō ?SSII
?
6/8 (ňģ) 09:45°ę10:55•Š•§•ůĽŠąŲ
÷véü£ļŇ£ĺ√ Ōť–Ę Ō
°°°°£®•™•ŗ•Ū•ů•Ķ•§•ň•√•Į•®•√•Į•Ļ÷Í ĹĽŠ…Á£©
łŇ“™£ļ 2017ńͧňôC–Ķ∑≠‘U§ÚĆĚŌů§»§∑§∆ŐŠįł§Ķ§ž§ŅTransformer§Ō°ĘŹĺņī§őģířz§Ŗ§š‘ŔéʧÚŇҧ∑§∆◊‘ľļ◊Ę“‚ôCėč§ÚĽÓ”√§∑§Ņ•ň•Ś©`•ť•Ž•Õ•√•»•Ô©`•Į§«§Ę§Ž°£2019ńÍŪē§ę§ť•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů∑÷“į§«§‚ľĪňŔ§ňŹÍ”√§¨ŖM§ů§«§™§Í°Ę§Ť§Í»Š‹õ§ę§ńłŖĺę∂»§ •Õ•√•»•Ô©`•Įėč‘ž§»§∑§∆§őĶōőĽ§Úī_Ńʧ∑§ń§ń§Ę§Ž°£Īĺ•Ń•Ś©`•»•Í•Ę•Ž§«§Ō°ĘTransformer§™§Ť§”§Ĺ§ő÷‹řx§ő•Õ•√•»•Ô©`•Įėč‘ž§ň§ń§§§∆°Ę•≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů§ō§őŹÍ”√§Ú÷––ń§»§∑§Ņ◊Ó«įĺħڳҒh§Ļ§Ž°£
Generative Adversarial Imitation Learning§őĹBĹť£®RL•Ę©`•≠•∆•Į•Ń•„√„ŹäĽŠ£©
Generative Adversarial Imitation Learning§őĹBĹť£®RL•Ę©`•≠•∆•Į•Ń•„√„ŹäĽŠ£©Yusuke Nakata
?
Generative Adversarial Imitation Learning §őĹBĹť•Ļ•ť•§•…
Ćg◊į•≥©`•…: https://github.com/uidilr/gail_ppo_tfSSII2019OS: …ÓĆ”—ßŃē§ň§ę§ę§Žērťg§Ú∂Ő§Į§∑§∆§Ŗ§ř§Ľ§ů§ę£Ņ °ę∑÷…Ę—ßŃē§őĄŠ§Š°ę
SSII2019OS: …ÓĆ”—ßŃē§ň§ę§ę§Žērťg§Ú∂Ő§Į§∑§∆§Ŗ§ř§Ľ§ů§ę£Ņ °ę∑÷…Ę—ßŃē§őĄŠ§Š°ęSSII
?
SSII2019 •™©`•¨• •§•ļ•…•Ľ•√•∑•Á•ů3°ł…ÓĆ”—ßŃē§őłŖňŔĽĮ °ęłŖňŔ•Ń•√•◊°Ę∑÷…Ę—ßŃē°Ę›XŃŅ•‚•«•Ž°ę°Ļ
6‘¬14»’(Ĺū) 10:35?12:05 (•Š•§•ů•Ř©`•Ž)[DL›Ü’iĽŠ]Vision Transformer with Deformable Attention £®Deformable Attention Tra...
[DL›Ü’iĽŠ]Vision Transformer with Deformable Attention £®Deformable Attention Tra...Deep Learning JP
?
2022/01/14
Deep Learning JP:
http://deeplearning.jp/seminar-2/Ī łť≤—≥Ę—ßŌį’Ŗ§ę§ť»Ž§Ž…Ó≤„…ķ≥…•‚•«•Ž»Ž√Ň
Ī łť≤—≥Ę—ßŌį’Ŗ§ę§ť»Ž§Ž…Ó≤„…ķ≥…•‚•«•Ž»Ž√Ňtmtm otm
?
•ľ•Ŗ§«įkĪŪ§∑§Ņ◊ ŃŌ§«§Ļ°£ľšő•§√§∆§§§Ņ§ťį’∑…ĺĪ≥Ŕ≥ŔĪūįý§ňѨ¬Á§Į§ņ§Ķ§§°£į™ī«≥Ŕ≥Ŕ≤Ļ≥ĺ≥ĺ≥Ś190°ĺDL›Ü’iĽŠ°ŅA Path Towards Autonomous Machine Intelligence
°ĺDL›Ü’iĽŠ°ŅA Path Towards Autonomous Machine IntelligenceDeep Learning JP
?
2022/7/29
Deep Learning JP
http://deeplearning.jp/seminar-2/įŕ∂Ŕ≥ʬ÷’iĽŠĪ’ŌŗĽ•«ťĪ®ŃŅ◊ÓīůĽĮ§ň§Ť§ŽĪŪŌ÷—ßŌį
įŕ∂Ŕ≥ʬ÷’iĽŠĪ’ŌŗĽ•«ťĪ®ŃŅ◊ÓīůĽĮ§ň§Ť§ŽĪŪŌ÷—ßŌįDeep Learning JP
?
2019/09/13
Deep Learning JP:
http://deeplearning.jp/seminar-2/ [DL›Ü’iĽŠ]Vision Transformer with Deformable Attention £®Deformable Attention Tra...
[DL›Ü’iĽŠ]Vision Transformer with Deformable Attention £®Deformable Attention Tra...Deep Learning JP
?
Similar to 20170618’ďőń’i§ŖĽŠ “ŃŐŔ (20)
łť§«—ߧ÷”Q≤ž•«©`•Ņ§«§ő“ÚĻŻÕ∆∂®
łť§«—ߧ÷”Q≤ž•«©`•Ņ§«§ő“ÚĻŻÕ∆∂®Hiroki Matsui
?
20120310 TokyoR#21 §«įkĪŪ§∑§ŅŔYŃŌ§«§Ļ°£’`§Í§š≤Ľ’żī_§ ≤Ņ∑÷§¨§Ę§Í§ř§∑§Ņ§ť°Ętwitter ID: Hiro_macchan §ř§«§īŖBĹjŌ¬§Ķ§§°£ĶĪ‘ďŔYŃŌ§Ō°Ę§§§Į§ń§ę§ő•Ķ•§•»§őŔYŃŌ§Ú“ż”√§∑§∆§§§ř§Ļ°£≤őŅľőńŌ◊§Ō•Ļ•ť•§•…§ő◊ÓŠŠ§ň”õ›d§∑§ř§∑§Ņ°£∑÷…Ę–Õ«ŅĽĮ—ßŌį ÷∑®§ő◊ÓĹŁ§ő∂ĮŌÚ§»∑÷…Ęľ∆ň„•’•ž©`•ŗ•Ô©`•Įłť≤Ļ≤‚§ň§Ť§ŽĆg◊į§ő ‘§Ŗ
∑÷…Ę–Õ«ŅĽĮ—ßŌį ÷∑®§ő◊ÓĹŁ§ő∂ĮŌÚ§»∑÷…Ęľ∆ň„•’•ž©`•ŗ•Ô©`•Įłť≤Ļ≤‚§ň§Ť§ŽĆg◊į§ő ‘§ŖSusumuOTA
?
(1) ∑÷…Ę–ÕŹäĽĮ—ßŃē ÷∑®§ő◊ÓĹŁ§őĄ”ŌÚ§Ú, Őō§ň MuZero (2019ńÍ11‘¬), Agent57 (2020ńÍ3‘¬)§Ú÷––ń§ňĹBĹť§∑§ř§Ļ.
(2) ∑÷…Ę”čň„•’•ž©`•ŗ•Ô©`•Į Ray §ň§Ť§√§∆•∑•ů•◊•Ž§ ∑÷…Ę–ÕŹäĽĮ—ßŃē ÷∑®§ÚĆg◊į§∑, Amazon EC2…Ō§ň•Į•ť•Ļ•Ņ§ÚėčļB§∑§∆∑÷…Ę”čň„§Ú––§¶∑Ĺ∑®§ÚĹ‚’h§∑§ř§Ļ.
- ĶĪ»’ĹBĹť§∑§Ņ•Ĺ©`•Ļ•≥©`•…§»‘O∂®•’•°•§•Ž
https://github.com/susumuota/distributed_experience_replay
- Do2dle√„ŹäĽŠ§őconnpass•ŕ©`•ł
https://do2dle.connpass.com/event/178184/Computational Motor Control: Reinforcement Learning (JAIST summer course)
Computational Motor Control: Reinforcement Learning (JAIST summer course) hirokazutanaka
?
This is lecure 6 note for JAIST summer school on computational motor control (Hirokazu Tanaka & Hiroyuki Kambara). Lecture video: https://www.youtube.com/watch?v=GHMcx5F0_j8NIPS KANSAI Reading Group #7: ńśŹäĽĮ—ßŃē§ő––Ą”Ĺ‚őŲ§ō§őŹÍ”√
NIPS KANSAI Reading Group #7: ńśŹäĽĮ—ßŃē§ő––Ą”Ĺ‚őŲ§ō§őŹÍ”√Eiji Uchibe
?
Can AI predict animal movements? Filling gaps in animal trajectories using inverse reinforcement learning, Ecosphere,
Modeling sensory-motor decisions in natural behavior, PLoS Comp. Biol.Ķŕ7Ľō KAIM Ĺūõg»ňĻ§÷™ń‹√„ŹäĽŠ ĽōéĘ∑÷őŲ§» Ļ§¶…Ō§«§ő◊Ę“‚ ¬Ūó
Ķŕ7Ľō KAIM Ĺūõg»ňĻ§÷™ń‹√„ŹäĽŠ ĽōéĘ∑÷őŲ§» Ļ§¶…Ō§«§ő◊Ę“‚ ¬Ūótomitomi3 tomitomi3
?
°ý§Ę§»§«ŔYŃŌ§Ú§Ę§≤§ §™§Ļ°ý
(÷ō)ĽōéĘ∑÷őŲ§Ō°ĘĽōéʧږ–§¶ĹŐéü§Ę§ÍôC–Ķ—ßŃēľľ∑®§ő“Ľ§ń§«§Ę§Ž°£ĪĺįkĪŪ§«§Ō°ĘĽōéĘ∑÷őŲ§»ĽōéĘ∑÷őŲ§Ú––§¶…Ō§«§ő◊Ę“‚ ¬Ū󧻧ŧőĪ≥ĺį§ň§ń§§§∆łŇ’h§Ļ§Ž°£
°į(Multiple) Regression analysis°Ī is one of the basic machine learning techniques for regression. In this presentation, I will explain the points in using regression analysis.Rainbow: Combining Improvements in Deep Reinforcement Learning (AAAI2018 unde...
Rainbow: Combining Improvements in Deep Reinforcement Learning (AAAI2018 unde...Toru Fujino
?
Rainbow: Combining Improvements in Deep Reinforcement Learning (AAAI2018 under review) [DL›Ü’iĽŠ]Meta-Learning Probabilistic Inference for Prediction
[DL›Ü’iĽŠ]Meta-Learning Probabilistic Inference for PredictionDeep Learning JP
?
2018/12/14
Deep Learning JP:
http://deeplearning.jp/seminar-2/–ńņŪ—ߧň§™§Ī§Ž•Ŕ•§•ļÕ≥ľ∆§őŃų––§Ú’ŻņŪ§Ļ§Ž
–ńņŪ—ߧň§™§Ī§Ž•Ŕ•§•ļÕ≥ľ∆§őŃų––§Ú’ŻņŪ§Ļ§ŽHiroshi Shimizu
?
•Ŕ•§•ļŘ”§ő•Ŕ•§•ļÕ≥ľ∆•‚•«•Í•ů•į•Ô©`•Į•∑•Á•√•◊§«įkĪŪ§∑§Ņ•Ļ•ť•§•…§«§Ļ°£ĪĪīů’{ļÕŌĶ DL•ľ•Ŗ A3C
ĪĪīů’{ļÕŌĶ DL•ľ•Ŗ A3CTomoya Oda
?
•®•‘•Ĺ©`•…§ő•Ķ•ů•◊•Í•ů•į?—ßŃē§¨∑«Õ¨∆ŕ + Actor-Critic§ ÷∑®§őŐŠįł°£łŁ§ňGPU§«§Ō§ §ĮCPU§ő§Ŗ§«DQN§Ť§Í—ßŃēērťg§ÚŌų§Ž§≥§»§ň≥…Ļ¶°£§ř§Ņ°ĘDQN§¨Ņŗ ÷§ ––Ą”Ņ’ťg§¨ŖBĺA§ ąŲļŌ§őŅ…ń‹–‘§‚ ĺ§∑§Ņ°£
§∑§ę§∑°Ę¨F‘৫§ŌA2C£®Õ¨∆ŕ£©§ő∑ŧ¨–‘ń‹§¨Ńľ§§§»§Ķ§ž§∆§§§Ž°£ŹäĽĮ—ßŃē√„ŹäĽŠ?’ďőńĹBĹť£®Ķŕ30Ľō£©Ensemble Contextual Bandits for Personalized Recommendation
ŹäĽĮ—ßŃē√„ŹäĽŠ?’ďőńĹBĹť£®Ķŕ30Ľō£©Ensemble Contextual Bandits for Personalized RecommendationNaoki Nishimura
?
’ďőńĹBĹť:
Tang, Liang, et al. "Ensemble contextual bandits for personalized recommendation." Proceedings of the 8th ACM Conference on Recommender Systems. ACM, 2014.Decision Transformer: Reinforcement Learning via Sequence Modeling
Decision Transformer: Reinforcement Learning via Sequence ModelingYasunori Ozaki
?
ŹäĽĮ—ßŃē»Ű ÷§őĽŠ§«įkĪŪ§∑§Ņ°ļDecision Transformer: Reinforcement Learning via Sequence Modeling°Ľ §ő§ř§»§Š§ň§ §Í§ř§Ļ°£
Neural Rejuvenation: Improving Deep Network Training by Enhancing Computation...
Neural Rejuvenation: Improving Deep Network Training by Enhancing Computation...Yosuke Shinya
?
Ķŕ53Ľō •≥•ů•‘•Ś©`•Ņ•”•ł•Á•ů√„ŹäĽŠ£ņťvĖ| CVPR2019’i§ŖĽŠ(«įĺé) įkĪŪŔYŃŌ°£
Speaker Deckįś£ļ https://speakerdeck.com/shinya7y/neural-rejuvenation#…Ůńőī®īů—ßĹUÜ”—ßĺt’ď A (10/15) łā’ýĎť¬‘
#…Ůńőī®īů—ßĹUÜ”—ßĺt’ď A (10/15) łā’ýĎť¬‘Yasushi Hara
?
#…Ůńőī®īů—ßĹUÜ”—ßĺt’ď A (10/15) łā’ýĎť¬‘ §ő÷vŃxŔYŃŌ§«§Ļ°£Õ‚Ļķ”ÔĹŐ”ż—–ĺŅ§ň§™§Ī§Žłť§Ú”√§§§ŅÕ≥ľ∆ĄIņŪ»Ž√Ň
Õ‚Ļķ”ÔĹŐ”ż—–ĺŅ§ň§™§Ī§Žłť§Ú”√§§§ŅÕ≥ľ∆ĄIņŪ»Ž√ŇYusaku Kawaguchi
?
FLEAT VII •Ô©`•Į•∑•Á•√•◊°łÕ‚Ļķ”ÔĹŐ”ż—–ĺŅ§ň§™§Ī§Žłť§Ú”√§§§ŅÕ≥ľ∆ĄIņŪ»Ž√Ň°Ļ§« Ļ”√§Ļ§Ž•Ļ•ť•§•…§«§Ļ°£…ÓĆ”—ßŃē(ĆýĪĺ–Ę÷ģ ÷Ý) - Deep Learning chap.1 and 2
…ÓĆ”—ßŃē(ĆýĪĺ–Ę÷ģ ÷Ý) - Deep Learning chap.1 and 2Masayoshi Kondo
?
…ÓĆ”—ßŃē(ĆýĪĺ–Ę÷ģ ÷Ý)§ő£Ī?£≤’¬§őĹBĹť•Ļ•ť•§•…£ģB4, M1ŌÚ§Ī§ő•ľ•ŖŔYŃŌ£ģ§≥§ž§ę§ť…ÓĆ”—ßŃē§Ú—ߧ”§Ņ§§ņŪŌĶ—ß…ķ§ő»ŽťT’Ŗ”√§ňĻęť_£ģ§ §ľĹy”č—ߧ¨•”•ł•Õ•Ļ§ő “‚ňľõQ∂®§ň§™§§§∆īů ¬§ §ő§ę£Ņ
§ §ľĹy”č—ߧ¨•”•ł•Õ•Ļ§ő “‚ňľõQ∂®§ň§™§§§∆īů ¬§ §ő§ę£ŅTakashi J OZAKI
?
°łĶŕ2ĽōCodeSCORE§ň§Ť§Ž°Ę•®•ů•ł•ň•Ę§őĆgĄ’•Ļ•≠•Ž§őŅ…“ēĽĮ§»°Ę§Ĺ§ő÷‹řx§ő÷™“äĻ≤”–•Ľ•Ŗ• ©`°Ļ§ň§™§Ī§Ž÷v—›ńŕ»›
https://codescore.codeiq.jp/seminarŹäĽĮ—ßŃē√„ŹäĽŠ?’ďőńĹBĹť£®Ķŕ30Ľō£©Ensemble Contextual Bandits for Personalized Recommendation
ŹäĽĮ—ßŃē√„ŹäĽŠ?’ďőńĹBĹť£®Ķŕ30Ľō£©Ensemble Contextual Bandits for Personalized RecommendationNaoki Nishimura
?
Ad
20170618’ďőń’i§ŖĽŠ “ŃŐŔ
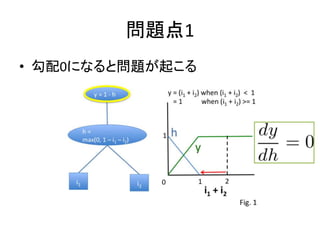
- 1. ’ďőńĹBĹť Learning Important Features Through Propagating Activation Differences Ė|ĺ©īů—ßĻ§—ßŌĶ—–ĺŅŅ∆ •∑•Ļ•∆•ŗĄď≥…—ßĆüĻ• ļÕ»™—–ĺŅ “ D1 “ŃŐŔ”—ŔF
- 2. ◊‘ľļĹBĹť ? Ė|ĺ©īů—ßĻ§—ßŌĶ—–ĺŅŅ∆ ļÕ»™—–ĺŅ “ňý Ű ®C Ĺū»ŕ§ňťv§Ļ§Ž•«©`•Ņ•ř•§•ň•ů•į ®C »ňĻ§ –ąŲ§ň§Ť§Ž•∑•Ŗ•Ś•ž©`•∑•Á•ů ? ∆’∂ő§Ō•Ū•§•Ņ©`•ň•Ś©`•Ļ§»§ę•š•’©`•’•°•§• •ů •Ļíų ĺįŚ§»§ęī•§√§∆Ŗ[§ů§«§ř§Ļ ? ĹŮ»’ĹBĹť§Ļ§Ž’ďőń°Ę§Ń§Á§§§Ń§Á§§’żī_§ňņŪĹ‚ §«§≠§∆§§§ §§§«§Ļ°≠§™ ÷»Š§ť§ę§ň§™Ó䧧÷¬§∑ §ř§Ļ
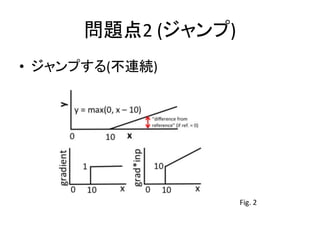
- 3. łŇ“™ ? ĹBĹť§Ļ§Ž’ďőń ®C Learning Important Features Through Propagating Activation Differences (A. Shrikumar et. Al, ICML, 2017) ? łŇ“™ ®C Neural Network §ę§ť÷ō“™§ “™ňō§Ōļő§ę§Ú≥ť≥Ų§Ļ §Ž∑Ĺ∑®§ő•Ę•◊•Ū©`•Ń(Deep Lift ∑®)§ÚŐŠįł ®C ľ»īś ÷∑®§Ť§Í…ę°©Ńľ§Ķ§Ĺ§¶
- 4. ľ»īś ÷∑® ? Perturbation approach ? Back propagation approach ®C Gradients ? (Springenberg et. al. 2014) § §… ®C Gradients °Ń Input ? (Shrikumar et. al. 2016) § §…
- 7. Deep Lift ? ĻīŇš§őÜĖÓ}§š•ł•„•ů•◊§őÜĖÓ}§ÚĹ‚õQ§Ļ§Ž∑Ĺ ∑®§ÚŐŠįł (Deep Lift ) ®C āÄ»ňĶń§ň§Ō§…§¶§∑§∆§≥§őįkŌŽ§ň§ §√§Ņ§ő§ę§Ô§ę§√ §∆§§§ §§§ő§«∂ŗ∑÷§Ń§„§ů§»ņŪĹ‚§«§≠§∆§§§ §§
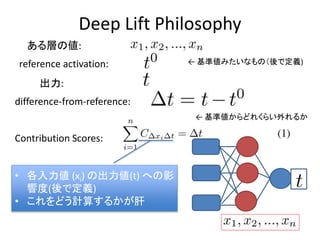
- 8. Deep Lift Philosophy §Ę§ŽĆ”§őāé: ≥ŲѶ: reference activation: difference-from-reference: °Ż Ľýú āé§Ŗ§Ņ§§§ §‚§ő£®ŠŠ§«∂®Ńx) Contribution Scores: ? łų»ŽŃ¶āé (xi) §ő≥ŲѶāé(t) §ō§ő”į ŪĎ∂»(ŠŠ§«∂®Ńx) ? §≥§ž§Ú§…§¶”čň„§Ļ§Ž§ę§¨łő °Ż Ľýú āé§ę§ť§…§ž§Į§ť§§Õ‚§ž§Ž§ę
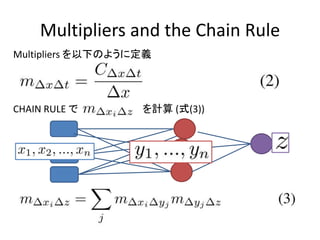
- 9. Multipliers and the Chain Rule Multipliers §Ú“‘Ō¬§ő§Ť§¶§ň∂®Ńx CHAIN RULE §« §Ú”čň„ ( Ĺ(3))
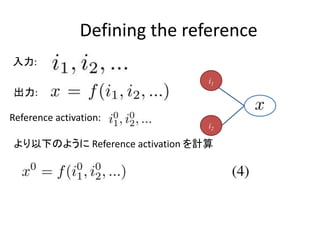
- 10. Defining the reference i1 i2 »ŽŃ¶: ≥ŲѶ: Reference activation: §Ť§Í“‘Ō¬§ő§Ť§¶§ň Reference activation §Ú”čň„
- 11. Separating positive and negative ? •›•ł•∆•£•÷Ū󧻕Օ¨•∆•£•÷Ūó§ÚĄe°©§ňŅľ§®§Ž Linear Rule, Rescale Rule, or Reveal cancel Rule §ň§Ť§Í”čň„(ŠŠ§«∂®Ńx)
- 12. Contribution Scores §ő”čň„ ? ĺÄ–ő§ ČšďQ °ķ Linear Rule §«”čň„ ®C ņż: ĹYļŌĆ”?§Ņ§Ņ§Ŗřz§ŖĆ” ? ∑«ĺÄ–ő§ ČšďQ °ķ Rescale Rule or Reveal cancel Rule §«”čň„ ®C ņż: tanh, ReLU
- 13. The Linear Rule ? ĺÄ–ő§ ≤Ņ∑÷ (ĹYļŌ?ģí§Ŗřz§Ŗ)§«§Ō“‘Ō¬§ő§Ť§¶ §ňContribution Scores §Ú”čň„ §ňḈ∑§∆
- 14. The Linear Rule §≥§ő§»§≠, “‘Ō¬§¨≥…ŃĘ
- 15. THE RESCALE RULE ? ∑«ĺÄ–ő≤Ņ∑÷(ReLU, tanh § §…)§«§Ō“‘Ō¬§ő§Ť§¶ §ň Contribution Scores §Ú”čň„ ? §≥§ő§»§≠“‘Ō¬§¨≥…ŃĘ
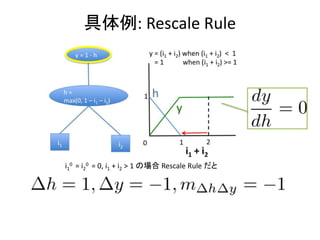
- 16. ĺŖŐŚņż: Rescale Rule i1 0 = i2 0 = 0, i1 + i2 > 1 §őąŲļŌ Rescale Rule §ņ§»
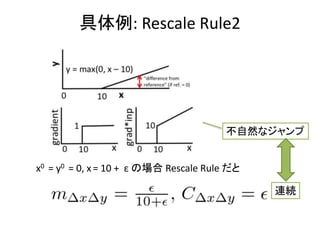
- 17. ĺŖŐŚņż: Rescale Rule2 x0 = y0 = 0, x = 10 + ¶Ň §őąŲļŌ Rescale Rule §ņ§» ≤Ľ◊‘»Ľ§ •ł•„•ů•◊ ŖBĺA
- 18. The Reveal Cancel Rule
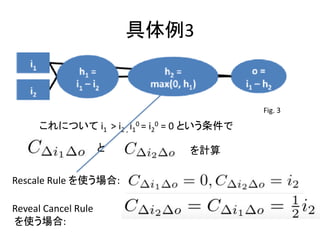
- 19. ĺŖŐŚņż3 Fig. 3 §≥§ž§ň§ń§§§∆ i1 > i2 , i1 0 = i2 0 = 0 §»§§§¶ŐűľĢ§« §» §Ú”čň„ Rescale Rule §Ú Ļ§¶ąŲļŌ: Reveal Cancel Rule §Ú Ļ§¶ąŲļŌ:
- 20. §Ĺ§őňŻ§őĻ§∑Ú ? ◊ÓĹKĆ”§őĽÓ–‘ĽĮŠŠ§őāé§ňḈĻ§Ž»ŽŃ¶āé§ő Contribution Score §«§Ō§ §ĮĽÓ–‘ĽĮ«į§ő Contribution Score §Ú”čň„ ? ◊ÓĹKĆ”§¨ Softmax §ő§»§≠§Ō»ęŐŚ§ő∆Ĺĺý§Ú“ż §§§Ņ•Ļ•≥•Ę§«Ņľ§®§Ž
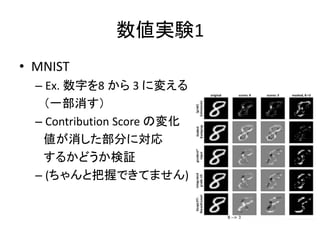
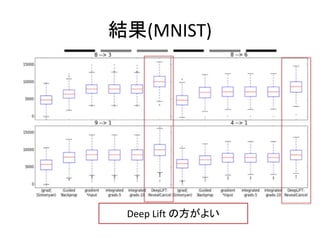
- 21. żāéĆgÚY1 ? MNIST ®C Ex. ż◊÷§Ú8 §ę§ť 3 §ňČš§®§Ž £®“Ľ≤ŅŌŻ§Ļ£© ®C Contribution Score §őČšĽĮ ā駨ŌŻ§∑§Ņ≤Ņ∑÷§ňĆĚŹÍ §Ļ§Ž§ę§…§¶§ęó ‘^ ®C (§Ń§„§ů§»į—ő’§«§≠§∆§ř§Ľ§ů)
- 22. żāéĆgÚY2 ? DNA Қі§ő∑÷Óź§ňťv§Ļ§ŽĆgÚY ? “‚áŪÕ®§Í§ň Contribution Score §¨§ń§Į§ę§…§¶ §ę§Úó ‘^ ? (§Ļ§§§ř§Ľ§ů°Ę§Ń§„§ů§»į—ő’§«§≠§∆§ř§Ľ§ů°£)
- 23. Ī»›^ ÷∑® ? ľ»īś ÷∑® ®C Guided backprop * inp () ®C Gradient * input ®C Integrated gradient -5 ®C Integrated gradient -10 ? ŐŠįł ÷∑® (Deep LIFT) ®C Deep LIFT Rescale ®C Deep LIFT Reveal Cancel ®C Deep LIFT fc-RC-conv-RS
- 25. ĹYĻŻ (DNA) ? Deep Lift §ő∑ŧ¨§Ť§§ĹYĻŻ ? Reveal Cancel »Ž§ž§Ņ∑ŧ¨§Ť§§ĹYĻŻ
- 26. ĹY’ď ? Deep Li£ś£Ű §»§§§¶÷ō“™§ “™ňō§Ōļő§ę§Ú≥ť≥Ų§Ļ§Ž∑Ĺ∑® §ő•’•ž©`•ŗ•Ô©`•Į(Deep Lift ∑®)§ÚŐŠįł ? ľ»īś ÷∑® (gradient §š gradient * input §«∆ū§≥§Ž§Ť§¶ § ≤Ľ◊‘»Ľ§ •ł•„•ů•◊§šĻīŇš§¨0§ő§»§≠§ň∆ū§≥§ŽÜĖÓ} §ÚĹ‚õQ) ? RNN§ō§őŖm”√∑Ĺ∑®, Maxout, MaxPooling §ō§ő•Ŕ•Ļ•» § Ŗm”√∑Ĺ∑® § §…§¨’nÓ}