This document summarizes a presentation on offline reinforcement learning. It discusses how offline RL can learn from fixed datasets without further interaction with the environment, which allows for fully off-policy learning. However, offline RL faces challenges from distribution shift between the behavior policy that generated the data and the learned target policy. The document reviews several offline policy evaluation, policy gradient, and deep deterministic policy gradient methods, and also discusses using uncertainty and constraints to address distribution shift in offline deep reinforcement learning.
The document summarizes a research paper that compares the performance of MLP-based models to Transformer-based models on various natural language processing and computer vision tasks. The key points are:
1. Gated MLP (gMLP) architectures can achieve performance comparable to Transformers on most tasks, demonstrating that attention mechanisms may not be strictly necessary.
2. However, attention still provides benefits for some NLP tasks, as models combining gMLP and attention outperformed pure gMLP models on certain benchmarks.
3. For computer vision, gMLP achieved results close to Vision Transformers and CNNs on image classification, indicating gMLP can match their data efficiency.
データマイニングや機械学習をやるときによく問題となる「リーケージ」を防ぐ方法について論じた論文「Leakage in Data Mining: Formulation, Detecting, and Avoidance」(Kaufman, Shachar, et al., ACM Transactions on Knowledge Discovery from Data (TKDD) 6.4 (2012): 1-21.)を解説します。
主な内容は以下のとおりです。
?過去に起きたリーケージの事例の紹介
?リーケージを防ぐための2つの考え方
?リーケージの発見
?リーケージの修正
This document summarizes a presentation on offline reinforcement learning. It discusses how offline RL can learn from fixed datasets without further interaction with the environment, which allows for fully off-policy learning. However, offline RL faces challenges from distribution shift between the behavior policy that generated the data and the learned target policy. The document reviews several offline policy evaluation, policy gradient, and deep deterministic policy gradient methods, and also discusses using uncertainty and constraints to address distribution shift in offline deep reinforcement learning.
The document summarizes a research paper that compares the performance of MLP-based models to Transformer-based models on various natural language processing and computer vision tasks. The key points are:
1. Gated MLP (gMLP) architectures can achieve performance comparable to Transformers on most tasks, demonstrating that attention mechanisms may not be strictly necessary.
2. However, attention still provides benefits for some NLP tasks, as models combining gMLP and attention outperformed pure gMLP models on certain benchmarks.
3. For computer vision, gMLP achieved results close to Vision Transformers and CNNs on image classification, indicating gMLP can match their data efficiency.
データマイニングや機械学習をやるときによく問題となる「リーケージ」を防ぐ方法について論じた論文「Leakage in Data Mining: Formulation, Detecting, and Avoidance」(Kaufman, Shachar, et al., ACM Transactions on Knowledge Discovery from Data (TKDD) 6.4 (2012): 1-21.)を解説します。
主な内容は以下のとおりです。
?過去に起きたリーケージの事例の紹介
?リーケージを防ぐための2つの考え方
?リーケージの発見
?リーケージの修正
![Python機械学習プログラミング
読み会
第11章
クラスタ分析 - ラベルなしデータの分析
1
[第2版]
基盤 江口春纪](https://image.slidesharecdn.com/11-181212011918/85/2-Python-11-1-320.jpg)



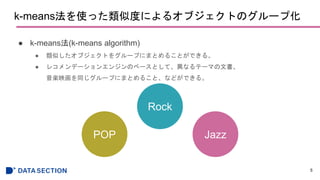

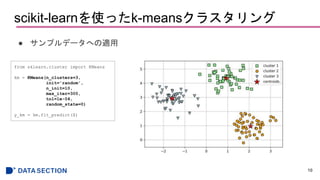
![scikit-learnを使ったk-meansクラスタリング
● k-means法を説明するための簡易的な例
● ランダムに生成された150個のサンプル点を用意する。
7
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=150,
n_features=2,
centers=3,
cluster_std=0.5,
shuffle=True,
random_state=0)
plt.scatter(X[:, 0], X[:, 1],
c='white', marker='o', edgecolor='black',
s=50)
plt.grid()
plt.tight_layout()
plt.show()](https://image.slidesharecdn.com/11-181212011918/85/2-Python-11-7-320.jpg)
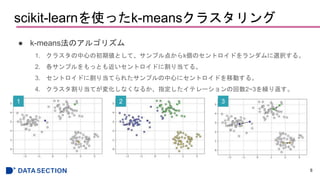









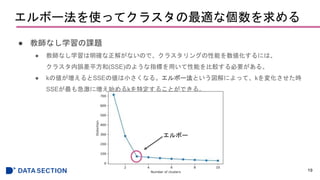

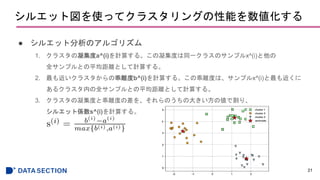
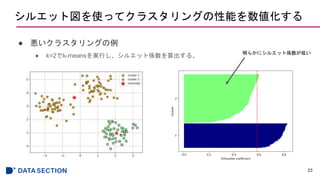
![シルエット図を使ってクラスタリングの性能を数値化する
● シルエット係数のプロット
22
from sklearn.metrics import silhouette_samples
cluster_labels = np.unique(y_km)
n_clusters = cluster_labels.shape[0]
silhouette_vals = silhouette_samples(X, y_km, metric='euclidean')
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i, c in enumerate(cluster_labels):
c_silhouette_vals = silhouette_vals[y_km == c]
c_silhouette_vals.sort()
y_ax_upper += len(c_silhouette_vals)
color = cm.jet(float(i) / n_clusters)
plt.barh(range(y_ax_lower,y_ax_upper),
c_silhouette_vals,
height=1.0,
edgecolor='none',
color=color)
yticks.append((y_ax_lower + y_ax_upper) / 2.)
y_ax_lower += len(c_silhouette_vals)](https://image.slidesharecdn.com/11-181212011918/85/2-Python-11-22-320.jpg)