More Related Content
What's hot (20)
More modern gpuMore modern gpuPreferred Networks?
GPUがなぜ速いのか,またその上でどのようなデータ構造やアルゴリズム,ライブラリが使えるのかを説明します。特にMapReduceなどの非均質で,離散的なアルゴリズムがいかに高速に実現されるかを紹介します。
実験に使ったコード
https://github.com/hillbig/gpuexperiments
セミナーの動画
https://www.youtube.com/watch?v=WmETPBK3MOI Similar to [第2版]Python機械学習プログラミング 第12章 (20)
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1hirokazutanaka?
ニューラルネットワーク
単層ネットワーク-パーセプトロン(perceptron)
パーセプトロンの学習則とその収束定理
パーセプトロンの記憶容量: Coverの数え上げ定理
パーセプトロンの限界:線形分離問題
ニューラルネットワーク
多層ネットワーク
関数近似としての教師あり学習
関数近似定理
応用例: NetTalk, Grove-TalkII, 自動運転
誤差逆伝播アルゴリズム
二乗誤差(回帰問題)とクロスエントロピー(分類問題)
確率勾配降下アルゴリズム
講師: 東京都市大学 田中宏和
講義ビデオ: https://www.youtube.com/playlist?list=PLXAfiwJfs0jGOvZnwUdAykZvSdRFd7K2p Deep learning実装の基礎と実践Deep learning実装の基礎と実践Seiya Tokui?
2014年8月26日の日本神経回路学会主催セミナー「Deep Learningが拓く世界」における発表スライドです。Deep Learningの主なフレームワークで共通する設計部分と、実験の仕方について説明しています。 深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計Yuta Sugii?
2017年4月 会津大学にて行った『深層学習』勉強会第1回目のスライドです。前半はこれまでの人工知能に関する研究の歴史について(なぜ研究が始まって2010年代にナウでヤングなものになっているのか)、後半は代表的な最も単純なニューラルネットワークのFFNN(順伝播型ニューラルネットワーク)の設計方法を紹介します。 2018年01月27日 Keras/TesorFlowによるディープラーニング事始め2018年01月27日 Keras/TesorFlowによるディープラーニング事始めaitc_jp?
発表日:2018年01月27日
イベント名: AITCオープンラボ TensorFlow勉強会シリーズ2 成果報告会
イベントURL:http://aitc.jp/events/20180127-OpenLab/info.html
タイトル:Keras/TesorFlowによるディープラーニング事始め
発表者:野田 洋��之氏
Kerasは高水準のニューラルネットワークライブラリであり、バックエンドと
してTensorFlowを使用でき、より迅速に、シンプルに、ニューラルネット
ワークを実装できます。
本発表では、ディープラーニング初心者に向け、手書き文字セットMINSTを学
習?予測するKerasのコードを、実演を交えて解説します。
サンプルコード:ipynb
AND http://www.aitc.jp/4b21e766/download.rbx?fileId=37f7e8383ef516fb&dirId=3
EXOR http://www.aitc.jp/4b21e766/download.rbx?fileId=70aef6fee200bde1&dirId=5
MNIST http://www.aitc.jp/4b21e766/download.rbx?fileId=e3632976bfa36a4a&dirId=3 More from Haruki Eguchi (13)
[第2版]Python機械学習プログラミング 第12章
- 11. 多層パーセプトロンを実装する
● MNISTデータセットのトレーニング
11
>>> nn = NeuralNetMLP(n_hidden=100,
... l2=0.01,
... epochs=200,
... eta=0.0005,
... minibatch_size=100,
... shuffle=True,
... seed=1)
>>> nn.fit(X_train=X_train[:55000],
... y_train=y_train[:55000],
... X_valid=X_train[55000:],
... y_valid=y_train[55000:])
200/200 | Cost: 5065.78 | Train/Valid Acc.: 99.28%/97.98%
コスト
正解率
正解率の差が
開いていっていることが分かる
- 12. 多層パーセプトロンを実装する
● 正しく分類できなかった数字
12
miscl_img = X_test[y_test != y_test_pred][:25]
correct_lab = y_test[y_test != y_test_pred][:25]
miscl_lab = y_test_pred[y_test != y_test_pred][:25]
fig, ax = plt.subplots(nrows=5, ncols=5, sharex=True, sharey=True,)
ax = ax.flatten()
for i in range(25):
img = miscl_img[i].reshape(28, 28)
ax[i].imshow(img, cmap='Greys', interpolation='nearest')
ax[i].set_title('%d) t: %d p: %d' ?
% (i+1, correct_lab[i], miscl_lab[i]))
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
人が正しく分類するのが難しいものもあることがわかる
Editor's Notes
- #3: IMDb: Internet Movie Database
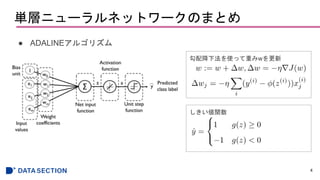
- #5: 入力と重みを掛け合わせ、総入力関数に入れて活性化関数を通り、単位ステップ関数でクラスラベルを予測する。
勾配降下法を使って、重みの更新を行う
η(イーター):学習率
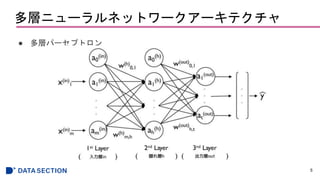
- #6: 隠れ層が1つ以上存在するネットワークは「ディープ人工ニューラルネットワーク」と呼ばれる
inとh、hとoutはそれぞれ完全に結合している。
a0はバイアスユニットで1に設定されている。入力にバイアスを足したものが伝搬する。
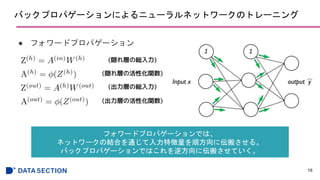
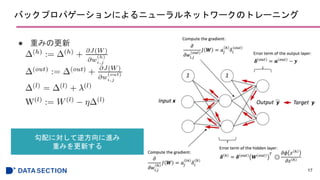
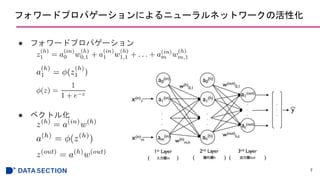
- #7: 隠れ層の総入力z^(h)は入力層aとhへの重みwの内積をとったもので、
それらを活性化関数(シグモイド関数)に入れて、隠れ層へ伝播する。
- #15: a: シグモイド関数
t: ネットワーク内のパーセプトロンの数
i: トレーニングサンプルのindex数(28*28個)
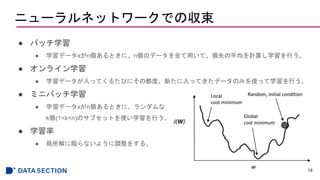
- #19: オンライン学習:通常の勾配降下法よりも早く収束し、早いが、外れ値に影響されやすかったりもする
ミニバッチは:ベクトル化された実装で計算を行えるので計算効率が良い、そして重みの更新も速い
![Python機械学習プログラミング
読み会
第12章
多層人工ニューラルネットワークを一から実装
1
[第2版]
基盤 江口春紀](https://image.slidesharecdn.com/12-181212011918/85/2-Python-12-1-320.jpg)






![多層パーセプトロンを実装する
● MNISTデータセットのトレーニング
11
>>> nn = NeuralNetMLP(n_hidden=100,
... l2=0.01,
... epochs=200,
... eta=0.0005,
... minibatch_size=100,
... shuffle=True,
... seed=1)
>>> nn.fit(X_train=X_train[:55000],
... y_train=y_train[:55000],
... X_valid=X_train[55000:],
... y_valid=y_train[55000:])
200/200 | Cost: 5065.78 | Train/Valid Acc.: 99.28%/97.98%
コスト
正解率
正解率の差が
開いていっていることが分かる](https://image.slidesharecdn.com/12-181212011918/85/2-Python-12-11-320.jpg)
![多層パーセプトロンを実装する
● 正しく分類できなかった数字
12
miscl_img = X_test[y_test != y_test_pred][:25]
correct_lab = y_test[y_test != y_test_pred][:25]
miscl_lab = y_test_pred[y_test != y_test_pred][:25]
fig, ax = plt.subplots(nrows=5, ncols=5, sharex=True, sharey=True,)
ax = ax.flatten()
for i in range(25):
img = miscl_img[i].reshape(28, 28)
ax[i].imshow(img, cmap='Greys', interpolation='nearest')
ax[i].set_title('%d) t: %d p: %d' ?
% (i+1, correct_lab[i], miscl_lab[i]))
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
人が正しく分類するのが難しいものもあることがわかる](https://image.slidesharecdn.com/12-181212011918/85/2-Python-12-12-320.jpg)