More Related Content What's hot (20)
PRML 1.5-1.5.5 Q¶šÀíŐ PRML 1.5-1.5.5 Q¶šÀíŐ
Akihiro Nitta ?
ŚîĐ°æ€Î„č„é„€„É€Ï http://www.akihironitta.com/slides/ €Çč«é_€·€Æ€€€Ț€čĄŁ
The latest version of this slides is available at http://www.akihironitta.com/slides/.
„Ț„ë„ł„ŐßBæi„â„ó„Æ„«„ë„í·š (2/3€Ï„Ù„€„șÍƶš€ÎÔ) „Ț„ë„ł„ŐßBæi„â„ó„Æ„«„ë„í·š (2/3€Ï„Ù„€„șÍƶš€ÎÔ)
Yoshitake Takebayashi ?
2014.06.08
Ąž„Ù„€„șÍƶš€Ë€è€ë¶àäÁżœâÎöÈëéTĄčŁÀÚuŽóѧ
„Ù„€„șÍƶš€È„Ț„ë„ł„ŐßBæi„â„ó„Æ„«„ë„í·š€Ë€Ä€€€ÆœâŐh€·€Æ€€€Ț€čĄŁ
”±ÈŐÓ€«€·€ż„ź„Ö„č„”„ó„Ś„ê„󄰀΄ą„Ë„á©`„·„ç„ó€ÏŁŹ
ÒÔÏ€΄”„€„ȀǜBœé€”€ì€ż„ł©`„É€òČÎżŒ€Ë€·€Æ€€€Ț€čĄŁ
http://qiita.com/yagays/items/5bde6addf228b1fe24e6
șÏłÉäÁż€È„ą„ó„”„ó„Ö„ëŁș»ŰąÉ€ÈŒÓ·š„â„Ç„ë€ÎÒȘ”ă șÏłÉäÁż€È„ą„ó„”„ó„Ö„ëŁș»ŰąÉ€ÈŒÓ·š„â„Ç„ë€ÎÒȘ”ă
Ichigaku Takigawa ?
CДѧÁ€Ë€Ș€±€ëĄžÄŸĄč€äĄžÉĄč€Î„â„Ç„ë€ÎžĆÒȘ
[ŐĐŽęÖvŃĘ] șÏłÉäÁż€È„ą„ó„”„ó„Ö„ëŁș»ŰąÉ€ÈŒÓ·š„â„Ç„ë€ÎÒȘ”ă
Ąđ{ŽšÒ»Ń§Łš±±ŽóŁ©
ĐĆșĆIÀíŃĐŸż»áŁšSIPŁ©https://goo.gl/PxAbbK
2017Äê 6ÔÂ19ÈŐ(ÔÂ) - 2017Äê 6ÔÂ20ÈŐ(»đ)
»Ű·€È„·„č„Æ„àŃĐŸż»áŁšCASŁ©/
VLSIÔOÓŒŒĐgŃĐŸż»áŁšVLDŁ©/ „·„č„Æ„àÊęÀí€ÈêÓĂŃĐŸż»áŁšMSSŁ©
äżŒ)
CДѧÁŃĐŸżŐß?{ŽšÒ»Ń§€”€ó [±±ŽóÈËíèa No.5]
https://youtu.be/XNz3D26wy0o
ĄŸŐĐŽęœČŃĘĄż„Ń„é„á©`„żÖÆÔŒž¶€ĐĐÁĐ·Öœâ€Î„Ù„€„șű»ŻÎóČîœâÎöĄŸł§łÙČčłÙČőČŃłąÈôÊÖ„·„ó„Ę2020Ąż ĄŸŐĐŽęœČŃĘĄż„Ń„é„á©`„żÖÆÔŒž¶€ĐĐÁĐ·Öœâ€Î„Ù„€„șű»ŻÎóČîœâÎöĄŸł§łÙČčłÙČőČŃłąÈôÊÖ„·„ó„Ę2020Ąż
Naoki Hayashi ?
”Ú5»ŰœyÓ?CДѧÁÈôÊÖ„·„ó„Ę„ž„Š„àŁšStatsMLSymposium'20Ł©€Ë€ÆŐĐŽęÖvŃĘÒÀîm€òÊÜ€±°k±í€·€Ț€·€żĄŁ
https://sites.google.com/view/statsmlsymposium20/%E3%83%9B%E3%83%BC%E3%83%A0?authuser=0
€œ€Î€È€€Î°k±íÓ»€Ï€ł€Á€é€Ç€čĄŁ
https://www.youtube.com/watch?v=ZbVfah9pnb4
„ą„Ö„č„È„é„Ż„ÈŁș
Őęt€Ç€Ê€€œyÓ„â„Ç„ë€Î„Ù„€„șű»ŻŐ`Čî€òœâÎö€č€ë€ż€á€ÎÊęѧ”Ä»ù”AŁšÌ۟ѧÁÀíŐŁ©€ŹșB€”€ìŁŹĐĐÁĐ·Öœâ€Î„Ù„€„șű»ŻŐ`Čî€òËŸ€ëѧÁSÊ꣚gÊę飩€ÏÍêÈ«€ËœâĂś€”€ì€Æ€€€ëŁź€·€«€·„Ń„é„á©`„żżŐég€ËÖÆŒsÌőŒț€Źž¶€€€żöșπˀĀ€€Æ€ÏĂś€é€«€Ë€”€ì€Æ€€€Ê€€Łź±ŸŃĐŸż€Ç€Ï„Ń„é„á©`„żÖÆŒsž¶€„â„Ç„ë€ÎŽú±í€È€·€Æ·ÇŰĐĐÁĐ·ÖœâŁšNMFŁ©€ÈDZÔÚ„Ç„Ł„ê„Ż„ìĆä·ÖŁšLDAŁ©€òÏó€È€·ŁŹ€œ€ì€é€Î„Ù„€„șű»ŻŐ`Čî€Ë€č€ëÀíŐœâÎö€ògÊ©€č€ëŁź
ÖÊ”ÄäÊę€ÎÏàév?ÒòŚÓ·ÖÎö ÖÊ”ÄäÊę€ÎÏàév?ÒòŚÓ·ÖÎö
Mitsuo Shimohata ?
Ù|”ÄäÊ꣚íĐòłß¶ÈŁ©€ËÓĐÓĂ€Ê„Ę„ê„ł„ê„Ă„ŻÏàévSÊę€òœBœé€·€Æ€€€Ț€čĄŁ
€Ț€żĄą„Ę„ê„ł„ê„Ă„ŻÏàévSÊę€òÊč€Ă€żÒòŚÓ·ÖÎö€Î·œ·š€âŐhĂś€·€Æ€€€Ț€čĄŁ
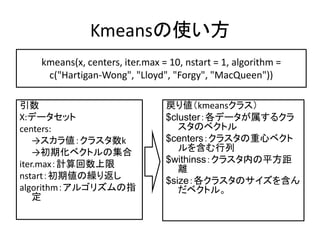
ÈËŒä€ÎÒâËŒŸö¶š€ò»úĐ”Ń§Ï°€Ç„â„DŽ뻯€Ç€€ë€« ÈËŒä€ÎÒâËŒŸö¶š€ò»úĐ”Ń§Ï°€Ç„â„DŽ뻯€Ç€€ë€«
Îśù ÙtÒ»ÀÉ ?
2021Äê€Î„”„€„š„ó„č€ËͶžć€”€ì€żÒâËŒQ¶šÀíŐ€ËCДѧÁ€òßmÓĂ€·€żŐÎÄ€òœBœé€·€Ț€čĄŁ
ÆÚŽężÓĂÀíՀ䄌„í„č„Ú„Ż„ÈÀíŐ€ò„Ù©`„č€È€·€ż„â„Ç„ë€äĄąŒÈŽæ€Î„â„Ç„ë€ò„Ù©`„č€È€·€Ê€€„â„DŽ륹ŒÈŽæ„â„Ç„ë€òßxk€Ç€€ë€è€Š€Ë€·€ż„â„Ç„ë€Ê€É€òœâŐh€·€Ț€·€żĄŁ
CДѧÁ€Źß`€Š·ÖÒ°€ÇËŰÇç€é€·€€łÉčû€òÉÏ€Č€żÀę€Î1€Ä€Ç€čĄŁ
Similar to „Ń„ż©`„óŐJŚR02 kÆœŸù·šver2.0 (20)
ÖśłÉ·Ö·ÖÎö ÖśłÉ·Ö·ÖÎö
ÙF��Öź °ËÄŸ ?
ÉÏÖÇŽóѧ菱ŸŃĐŸżÊÒ€ÎĂăÇż»á°k±íŚÊÁÏ€Ç€čŁź
PRML(„Ń„ż©`„óŐJŚR€ÈCДѧÁŁ©€Î”ÚŁ±ŁČŐÂĄžßBŸADZÔÚäÊęĄč€«€éÒ»Čżi»€·€Æ€Ț€È€á€Ț€·€żŁź
Öś€ËÖśłÉ·Ö·ÖÎö€È„«©`„Í„ëÖśłÉ·Ö·ÖÎö€Ë€Ä€€€Æ€Ç€čŁź
Oshasta em Oshasta em
Naotaka Yamada ?
EM„ą„ë„Ž„ê„ș„à€Ë€Ä€€€Æ€¶€Ă€Ż€êœâŐh
ÍêÈ«„Ç©`„ż€ÎÊęÓȶȀòŚîŽó»Ż€Ê€éș
g€Ë€Ç€€ë €È€€€Šą¶š€ŹæIĄŁ€œ€Î€«€ż€Á€Ë€Š€Ț€€€ł€ÈłÖ€Ă€Æ€€€ŻĄŁÀíŐ”Ä€Ê±łŸ°€ÏPRML 9.4€òČÎŐŐ
žéłŠ±è±è€Î€č€č€á žéłŠ±è±è€Î€č€č€á
Masaki Tsuda ?
R€ÎévÊę€òC++€ÇÓÊö€č€ë€ł€È€òżÉÄ܀ˀč€ë„Ń„Ă„±©`„žRcpp€ÎÊ耀·œ€ÎœBœé€Ç€čĄŁ
”Ú10»Ű Kashiwa.R €Ç°k±í€”€»€Æ퀀€żr€ÎÙYÁÏ
|Ÿ©¶ŒÊĐŽóѧ „Ç©`„żœâÎöÈëéT 8 „Ż„é„č„ż„ê„󄰀ȷÖî·ÖÎö 1 |Ÿ©¶ŒÊĐŽóѧ „Ç©`„żœâÎöÈëéT 8 „Ż„é„č„ż„ê„󄰀ȷÖî·ÖÎö 1
hirokazutanaka ?
ÌŰŐÁżßxk€È„Ç©`„ż„Ț„€„Ë„ó„°
”ÍŽÎÔȘ€ÎöșÏŁș„ą„ä„á„Ç©`„ż„»„Ă„È
žßŽÎÔȘ€ÎöșÏŁșÖśłÉ·Ö·ÖÎö€Ë€è€ëÌŰŐłéłö
œÌ€ą€êѧÁ€ÈœÌ€Ê€·Ń§Á
ѧÁ€Î„Ń„é„À„€„à€È€œ€ÎŽú±íÀę
k-ÆœŸù„Ż„é„č„ż„ê„ó„°
ëAӔĄŻ„é„č„ż„ê„󄰀ȄDŽó„É„í„°„é„à
»ìșÏ„â„Ç„ë€ÈEM„ą„ë„Ž„ê„ș„à
ÖvŁș |Ÿ©¶ŒÊĐŽóѧ ÌïÖĐșêșÍ
ÖvÁx„Ó„Ç„ȘŁș https://www.youtube.com/playlist?list=PLXAfiwJfs0jGOvZnwUdAykZvSdRFd7K2p
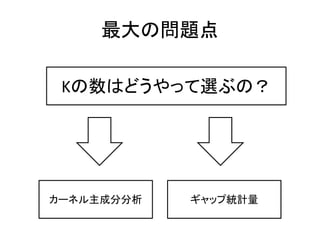
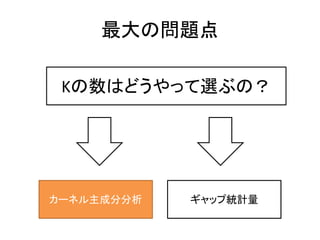
3. ”Ú2Ő€ÎÄż”Ä
K-ÆœŸù·š€Î„ą„ë„Ž„ê„ș„à
K€ÎÊę€òÍƶš€č€ë·œ·š
? „©`„ï©`„É
šC K-ÆœŸù·š
šC „«©`„Í„ëÖśłÉ·Ö·ÖÎö
šC GapœyÓÁż
8. K-ÆœŸù·š€Î„ą„ë„Ž„ê„ș„à
ÈëÁŠŁș„Ç©`„żX={x1, x2, Ą , xn} „Ż„é„č„żÊęk
Ł±ŁźłőÆÚ»ŻŁș„Ç©`„ż€«€é„é„ó„À„à€ËKßx€ÓĄą€ł€ì€ò„Ż„é„č
„ż€ÎÖŰĐĀȀč€ëĄŁ
ŁČŁź„Ż„é„č„ż€ÎQ¶šŁș€ą€ë„Ç©`„ż€Ë€·Ąą„Ż„é„č„ż€ÎÖŰĐÄ€Î
ÖЀnjî€âœü€€„Ż„é„č„ż€Ź„Ç©`„ż€ÎÊô€č€ë„Ż„é„č„ż€È€Ê€ëĄŁ
€ł€ì€òÈ«€Æ€Î„Ç©`„ż€Ë€·€ÆÓËă€č€ëĄŁ
ŁłŁź„Ż„é„č„ż€ÎÖĐĐÄ€ÎÔÙÓËăŁșŁČ€ÇÓË〷€ż„Ż„é„č„ż°€Ë
ÖŰĐÄ€òÔÙ¶ÈÓË㥣ÒÔÏÂĄą
§Êű€č€ë€Ț€ÇŁČ€ÈŁł€òÀR€ê·”
€čĄŁ
łöÁŠŁș„Ç©`„ż€Ž€È€Î„Ż„é„č„ż C={1, k, 2, Ą , 2}Ąą„Ż„é„č„żÖĐĐÄ
9. K-ÆœŸù·š€Î„ą„ë„Ž„ê„ș„à
? ŃÔÈ~€ÇŃÔ€Ă€Æ€â€ï€«€ó€Ê€€€Î€ÇĄążÉÒ»Ż€·€ż
€â€Î€ò€ß€Æ€ß€Ț€·€ç€ŠĄŁ
ÈëÁŠŁș „ą„ë„Ž„ê„ș„àŁș łöÁŠŁș
¶àŽÎÔȘ„Ç©`„żX(nxp) *KÆœŸù·š „Ç©`„ż€ÎÊô€č€ë„Ż„é„č„ż
ÔuęévÊꥹ
n
L ? ? min || xi ? cl ||
l ?1,?, k
i ?1
€òŚîĐĄ»Ż€·€Æ€€€ë
„Ż„é„č„żÊęk €Î€ÈÍŹ€žĄŁ „Ż„é„č„żÖĐĐÄ
k=3 C ? {c1 ,?ck }
ŁȘ„ą„ë„Ž„ê„ș„à€ÎÔŒ€ÏÏÂÓ„ê„ó„Ż€ò„Á„§„Ă„ŻŁĄ
http://d.hatena.ne.jp/nitoyon/20090409/kmeans_visualise
10. °łŸ±đČčČÔČő€ÎÊ耀·œ
kmeans(x, centers, iter.max = 10, nstart = 1, algorithm =
c("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen"))
ÒęÊę ű€êŁškmeans„Ż„é„裩
X:„Ç©`„ż„»„Ă„È $clusterŁșžś„Ç©`„ż€ŹÊô€č€ë„Ż„é
centers: „č„ż€Î„Ù„Ż„È„ë
Ąú„č„«„éŁș„Ż„é„č„żÊęk $centersŁș„Ż„é„č„ż€ÎÖŰĐÄ„Ù„Ż„È
ĄúłőÆÚ»Ż„Ù„Ż„È„ë€ÎŒŻșÏ „ë€òșŹ€àĐĐÁĐ
iter.maxŁșÓËă»ŰÊęÉÏÏȚ $withinssŁș„Ż„é„č„żÄÚ€ÎÆœ·œŸà
ëx
nstartŁșłőÆÚ€ÎÀR€ê·”€·
$sizeŁșžś„Ż„é„č„ż€Î„”„€„ș€òșŹ€ó
algorithmŁș„ą„ë„Ž„ê„ș„à€ÎÖž €À„Ù„Ż„È„ëĄŁ
¶š
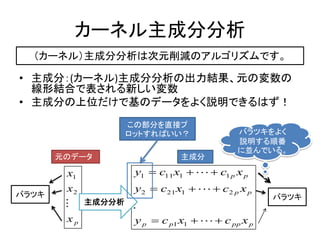
15. „«©`„Í„ëÖśłÉ·Ö·ÖÎö
Łš„«©`„̈́룩֜łÉ·Ö·ÖÎö€ÏŽÎÔȘÏśp€Î„ą„ë„Ž„ê„ș„à€Ç€čĄŁ
? ÖśłÉ·ÖŁș(„«©`„Í„ë)ÖśłÉ·Ö·ÖÎö€ÎłöÁŠœYčûĄąÔȘ€ÎäÊę€Î
ŸĐÎœYșπDZ퀔€ì€ëĐ€·€€äÊę
? ÖśłÉ·Ö€ÎÉÏλ€À€±€Ç»ù€Î„Ç©`„ż€ò€è€ŻŐhĂś€Ç€€ë€Ï€șŁĄ
€ł€ÎČż·Ö€òÖ±œÓ„Ś
„í„Ă„È€č€ì€Đ€€€€Łż „Đ„é„Ä„€ò€è€Ż
ŐhĂś€č€ëí·Ź
€ËK€ó€Ç€€€ëĄŁ
ÔȘ€Î„Ç©`„ż ÖśłÉ·Ö
x1 y1ĄĄ c11 x1 ? ? ? c1 p x p
?
x2 y2 ? c21 x1 ? ? ? c2 p x p
„Đ„é„Ä„ „Đ„é„Ä„
? ÖśłÉ·Ö·ÖÎö ?
xp y p ? c p1 x1 ? ? ? c pp x p
16. R€Ç„«©`„Í„ëÖśłÉ·Ö·ÖÎö€òĐĐ€Š
>library(kernlab) Package kernlab
>x<-as.matrix(iris[,1:4]) Iris„Ç©`„ż
>gamma<-median(dist(x)) 150x4 ,3class
>sigma<-1/(2*gamma^2) „Ź„Š„č„«©`„Í„ë€Î„Ń„é
>kp<-kpca(x, kernel=Ą°rbfdotĄ±, „á©`„żŠÒ€òŚśłÉ
kpar=list(sigma=sigma)) „Ź„Š„č„«©`„Í„ë€Ç
>plot(iris[, 1:4]) „«©`„Í„ëÖśłÉ·Ö·ÖÎö
>plot(data.frame(pcv(kp)) ÔȘ€Î„Ç©`„ż€ÇÉąČŒí
[,1:4])
ÖśłÉ·Ö€ÇÉąČŒí
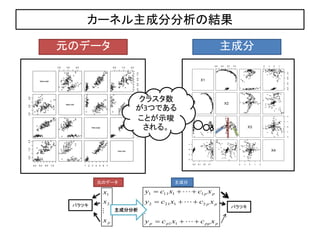
17. „«©`„Í„ëÖśłÉ·Ö·ÖÎö€ÎœYčû
ÔȘ€Î„Ç©`„ż ÖśłÉ·Ö
„Ż„é„č„żÊę
€Ź3€Ä€Ç€ą€ë
€ł€È€ŹÊŸËô
€”€ì€ëĄŁ
ÔȘ€Î„Ç©`„ż ÖśłÉ·Ö
x1 y1ĄĄ c11 x1 ? ? ? c1 p x p
?
x2 y2 ? c21 x1 ? ? ? c2 p x p
„Đ„é„Ä„ „Đ„é„Ä„
? ÖśłÉ·Ö·ÖÎö ?
xp y p ? c p1 x1 ? ? ? c pp x p
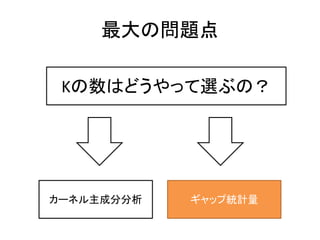
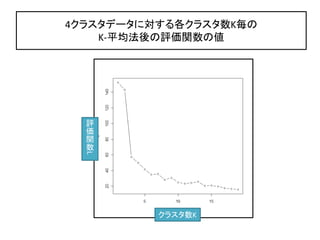
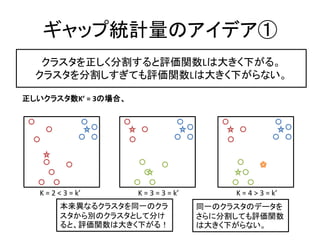
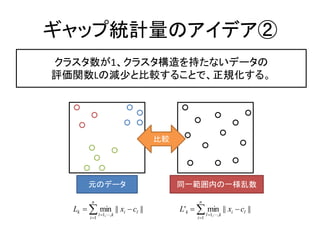
26. „ź„ă„Ă„ŚÍłŒÆÁż€Î„ą„€„Ç„ąąÙ
„Ż„é„č„ż€òŐꀷ€Ż·Öžî€č€ë€ÈÔuęévÊęL€ÏŽó€€ŻÏ€Ź€ëĄŁ
„Ż„é„č„ż€ò·Öžî€·€č€ź€Æ€âÔuęévÊęL€ÏŽó€€ŻÏ€Ź€é€Ê€€ĄŁ
Őꀷ€€„Ż„é„č„żÊęKĄŻ = 3€ÎöșÏĄą
K = 2 < 3 = kĄŻ K = 3 = 3 = kĄŻ K = 4 > 3 = kĄŻ
±ŸÀŽź€Ê€ë„Ż„é„č„ż€òÍŹÒ»€Î„Ż„é ÍŹÒ»€Î„Ż„é„č„ż€Î„Ç©`„ż€ò
„č„ż€«€ée€Î„Ż„é„č„ż€È€·€Æ·Ö€± €”€é€Ë·Öžî€·€Æ€âÔuęévÊę
€ë€ÈĄąÔuęévÊę€ÏŽó€€ŻÏ€Ź€ëŁĄ €ÏŽó€€ŻÏ€Ź€é€Ê€€ĄŁ
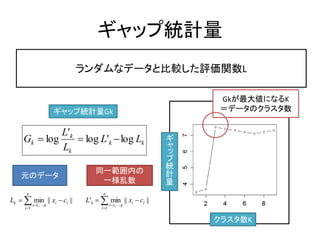
28. „ź„ă„Ă„ŚÍłŒÆÁż
„é„ó„À„à€Ê„Ç©`„ż€È±ÈĘ^€·€żÔuęévÊęL
Gk€ŹŚîŽó€Ë€Ê€ëK
„ź„ă„Ă„ŚÍłŒÆÁżGk Łœ„Ç©`„ż€Î„Ż„é„č„żÊę
L'k
Gk ? log ? log L'k ? log Lk „ź
Lk „ă
„Ă
„Ś
œy
ÍŹÒ»č ìÄڀΠÓ
ÔȘ€Î„Ç©`„ż
Ò»ÂÒÊę Áż
n n
Lk ? ? min || xi ? cl || L'k ? ? min || xi ? cl ||
l ?1,?, k l ?1,?, k
i ?1 i ?1
„Ż„é„č„żÊęK
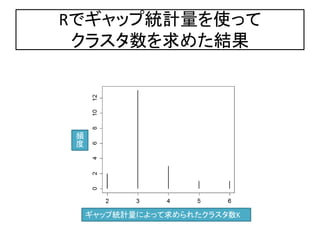
29. R€Ç„ź„ă„Ă„ŚÍłŒÆÁż€òÊč€Ă€Æ„Ç©`„ż€Î
„Ż„é„č„żÊę€òÍƶš€č€ë
> library(SLmisc) Package SLmisc
> x <- iris[,1:4]
> gap <- c() €ä€Ă€Ń€êIris„Ç©`„ż
> for (i in 1:20){ 150x4 ,3class
+ kg <- kmeansGap(x)
„ź„ă„Ă„ŚœyÓ
+ nc <- length(kg$cluster$size) Áż€òÇó€á€ëĄŁ 20»Ű
+ gap <- c(gap,nc)
Íƶš€”€ì€ż„Ż €Ż€ê€«
+}
€š€·
> par(ps=16) „é„č„żÊę€òÈĄ
> plot(table(gap),xlab="k : num. ”Ă€č€ëĄŁ
of clusters",ylab="freq.")
Íƶš€”€ì€ż„Ż„é„č
„żÊę€Î„Ò„č„È„°„é
„à€òŚśłÉ
31. ±ŸÈՀ΀Ț€È€á
? K-ÆœŸù·š€ÏĄąÊÂÇ°€Ë„Ż„é„č„żÊę€òQ€á€Æ·Öî
€č€ë„Ż„é„č„ż„ê„ó„°„ą„ë„Ž„ê„ș„à€Ç€ą€ëĄŁ
? K-ÆœŸù·š€ÏĄą„Ż„é„č„ż€ÎÊę€ÎQ¶š€Ëí§ÒâĐÔ€Ź
€ą€êĄą„Ż„é„č„żÊę€ÎQ¶š€Źî}€È€Ê€ëĄŁ
„Ż„é„č„żÊę€ÎÍƶš·œ·š „«©`„Í„ëÖśłÉ·Ö·ÖÎö „ź„ă„Ă„ŚÍłŒÆÁż
·œ·š€ÎžĆÒȘ ŽÎÔȘÏśp€·€ÆżÉÒ»Ż „ź„ă„Ă„ŚÍłŒÆÁż€ÎŚî
€·€ÆĄą„Ż„é„č„żÊę€òÒ Žó€ò„Ż„é„č„żÊę€È€č
·e€â€ëĄŁ €ëĄŁ
ÌŰŐ ÊôÈË”Ä CĐ””Ä




![„Ż„é„č„ż„ê„󄰀΄ą„ë„Ž„ê„ș„à
@hamadakoichi€”€ó€ÎÙYÁÏ€è€ê
[„Ç©`„ż„Ț„€„Ë„ó„°+WEBĂă»á][RĂă»á] RŃÔŐZ€Ë€è€ë„Ż„é„č„ż©`·ÖÎö - »îÓĂŸ
http://www.slideshare.net/hamadakoichi/r-3754836](https://image.slidesharecdn.com/02-kver2-0-110528032516-phpapp02/85/02-k-ver2-0-6-320.jpg)




![R€Ç„«©`„Í„ëÖśłÉ·Ö·ÖÎö€òĐĐ€Š
>library(kernlab) Package kernlab
>x<-as.matrix(iris[,1:4]) Iris„Ç©`„ż
>gamma<-median(dist(x)) 150x4 ,3class
>sigma<-1/(2*gamma^2) „Ź„Š„č„«©`„Í„ë€Î„Ń„é
>kp<-kpca(x, kernel=Ą°rbfdotĄ±, „á©`„żŠÒ€òŚśłÉ
kpar=list(sigma=sigma)) „Ź„Š„č„«©`„Í„ë€Ç
>plot(iris[, 1:4]) „«©`„Í„ëÖśłÉ·Ö·ÖÎö
>plot(data.frame(pcv(kp)) ÔȘ€Î„Ç©`„ż€ÇÉąČŒí
[,1:4])
ÖśłÉ·Ö€ÇÉąČŒí](https://image.slidesharecdn.com/02-kver2-0-110528032516-phpapp02/85/02-k-ver2-0-16-320.jpg)


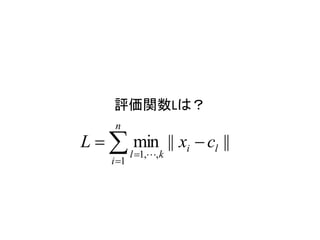



![R€Ç„ź„ă„Ă„ŚÍłŒÆÁż€òÊč€Ă€Æ„Ç©`„ż€Î
„Ż„é„č„żÊę€òÍƶš€č€ë
> library(SLmisc) Package SLmisc
> x <- iris[,1:4]
> gap <- c() €ä€Ă€Ń€êIris„Ç©`„ż
> for (i in 1:20){ 150x4 ,3class
+ kg <- kmeansGap(x)
„ź„ă„Ă„ŚœyÓ
+ nc <- length(kg$cluster$size) Áż€òÇó€á€ëĄŁ 20»Ű
+ gap <- c(gap,nc)
Íƶš€”€ì€ż„Ż €Ż€ê€«
+}
€š€·
> par(ps=16) „é„č„żÊę€òÈĄ
> plot(table(gap),xlab="k : num. ”Ă€č€ëĄŁ
of clusters",ylab="freq.")
Íƶš€”€ì€ż„Ż„é„č
„żÊę€Î„Ò„č„È„°„é
„à€òŚśłÉ](https://image.slidesharecdn.com/02-kver2-0-110528032516-phpapp02/85/02-k-ver2-0-29-320.jpg)