

![≤őŅľőńŌ◊
2016ńÍ10‘¬§ň◊ů§őĪ姨≥Ų§Ņ°£
§≥§ž§Ú’i§ů§«§§§Į°£
”“Ō¬§őĪ姨ťL§ť§Į•–•§•÷•Ž
§ņ§√§Ņ§¨2000ńÍ(‘≠÷Ý1998ńÍ)
įk––°£
3
http://amzn.to/2josIJ1
http://amzn.to/2jCnYQg—‘ľį§Ļ§Žēr [§≥] §»ļۧ÷§≥§»§ň§Ļ§Ž(÷Ý’Ŗ∂ŗ§§§ő§«)](https://image.slidesharecdn.com/5-170902005015/85/5-3-320.jpg)


![ĹŮŠŠ§ő”Ť∂®
Ķŕ8Ľō 2.3 ńśŹäĽĮ—ßŃē
Ķŕ9Ľō 2.4 ĹUÚYŹäĽĮ–Õ—ßŃē
2.5 »ļŹäĽĮ—ßŃē(Ôw§–§∑§ř§Ļ)
Ķŕ10Ľō 2.6 •Í•Ļ•ĮŅľĎ]–ÕŹäĽĮ—ßŃē
2.7 —}ņŻ–ÕŹäĽĮ—ßŃē(Ôw§–§∑§ř§Ļ)
Ķŕ11Ľō
3 ŹäĽĮ—ßŃē§őĻ§—ߏ͔√
3.3 ĆĚ‘íĄIņŪ§ň§™§Ī§ŽŹäĽĮ—ßŃē
6](https://image.slidesharecdn.com/5-170902005015/85/5-6-320.jpg)



















































![[DL›Ü’iĽŠ]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=560&fit=bounds)









![[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...](https://cdn.slidesharecdn.com/ss_thumbnails/alpha-gan-inpl-180417074219-thumbnail.jpg?width=560&fit=bounds)


![[DL›Ü’iĽŠ]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)

![[DL›Ü’iĽŠ]ĹŁńͧő•™•’•ť•§•ůŹäĽĮ—ßŃē§ő§ř§»§Š °™Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=560&fit=bounds)










More Related Content
What's hot (20)
More from nishio (20)


















Recently uploaded (6)






«ŅĽĮ—ßŌį§Ĺ§ő5
- 1. ŹäĽĮ—ßŃē §Ĺ§ő5 ≤Ņ∑÷”Qúy•‚•ů•∆•ę•Ž•Ūľ∆Ľ≠∑® (≤Ņ∑÷”Q≤‚•ř•Ž•≥•’ĺŲ∂®Ļż≥Ő2) 2017-08-07 @ ôC–Ķ—ßŃē√„ŹäĽŠ •Ķ•§•‹•¶•ļ?•ť•‹ őųő≤Ő©ļÕ Ŗ^»•§őŔYŃŌ: https://github.com/nishio/reinforcement_learning
- 4. ĹŮŠŠ§ő”Ť∂® Ķŕ4Ľō(«įĽō): 1’¬5ĻĚ ≤Ņ∑÷”Q≤‚•ř•Ž•≥•’ĺŲ∂®Ļż≥Ő Ķŕ5Ľō: 1’¬5ĻĚ ≤Ņ∑÷”Q≤‚•ř•Ž•≥•’ĺŲ∂®Ļż≥Ő§«§Ę§ř §Íī•§ž§ť§ž§∆§§§ §§•‚•«•Ž•’•Í©`§őPOMCP 4
- 5. ĹŮŠŠ§ő”Ť∂® Ķŕ6Ľō 2.1 Ĺy”č—ßŃē§ő”QĶ„§ę§ť“ä§ŅTD—ßŃē 2.1.1 ŹäĽĮ—ßŃē§»ĹŐéüł∂§≠—ßŃē§ő—ßŃēĄt 2.1.2~3 ťv żĹŁň∆§Ú(§Ļ§Ž/§∑§ §§)Āżāéťv żÕ∆∂® (§≥§≥§ř§«28•ŕ©`•ł) Ķŕ7Ľō 2.1.4 •Ľ•Ŗ•—•ť•Š•»•Í•√•ĮĹy”č—ßŃē§ňĽý§Ň§Į∂® Ĺ ĽĮ(10•ŕ©`•ł) 2.2 ņŪ’ď–‘ń‹Ĺ‚őŲ§»•Ŕ•§•ļ (ņŪ’ďĪ°§Š§«§š§Ž°£13•ŕ©`•ł) 5
- 6. ĹŮŠŠ§ő”Ť∂® Ķŕ8Ľō 2.3 ńśŹäĽĮ—ßŃē Ķŕ9Ľō 2.4 ĹUÚYŹäĽĮ–Õ—ßŃē 2.5 »ļŹäĽĮ—ßŃē(Ôw§–§∑§ř§Ļ) Ķŕ10Ľō 2.6 •Í•Ļ•ĮŅľĎ]–ÕŹäĽĮ—ßŃē 2.7 —}ņŻ–ÕŹäĽĮ—ßŃē(Ôw§–§∑§ř§Ļ) Ķŕ11Ľō 3 ŹäĽĮ—ßŃē§őĻ§—ߏ͔√ 3.3 ĆĚ‘íĄIņŪ§ň§™§Ī§ŽŹäĽĮ—ßŃē 6
- 7. ĹŮŠŠ§ő”Ť∂® Ķŕ12Ľō 3.5 ◊‘»Ľ—‘’ZĄIņŪ§ň§™§Ī§ŽńśŹäĽĮ—ßŃē§»ń£ āć—ßŃē Ķŕ13Ľō 3.7 …ÓĆ”—ßŃē§Ú”√§§§ŅQťv ż§ő—ßŃē Ķŕ14Ľō 4 ÷™ń‹§ő•‚•«•Ž§»§∑§∆§őŹäĽĮ—ßŃē 7
- 10. «įĽō§ő§™§Ķ§ť§§ ‘™§őMDP§¨Dīő‘™§ §ťbelief MDP§ő–ŇńÓ◊īĎBb§Ō ? ° ? ? §ň§ §√§∆īůČš –“§§belief MDP…Ō§őĀżāéťv żV§Ō«Ý∑÷ĺÄ–ő§«Ō¬§ň ÕĻ§ §ő§«°ĘDīő‘™•Ŕ•Į•»•Ž§őľĮļŌ§«ĄŅ¬ Ķń§ňĪŪ¨F §«§≠§Ž §∑§ę§∑Öó√‹§ň”čň„§Ļ§Ž§»•Ŕ•Į•»•Ž§ő ż§¨÷ł żĶń •™©`•ņ©`§«Čą§®§Ž°£§Ĺ§≥§«∂® żāħő•Ŕ•Į•»•Ž§«ĹŁ ň∆§Ļ§Ž§ő§¨Point Based Value Iteration §≥§őĀI’Ŗ§ÚĆg◊į§∑§∆2◊īĎB3––Ą”§«ĆgÚY§∑§Ņ°£ 10
- 12. POMCP °įMonte-Carlo Planning in Large POMDPs°Ī* ◊īĎBŖw“∆ī_¬ §Ú»ňťg§¨ÍĖ§ň”Ž§®§Ž§ő§«§Ō§ §Į •÷•ť•√•Į•‹•√•Į•Ļ§ő•∑•Ŗ•Ś•ž©`•Ņ§Ú”Ž§®§∆ ņR§Í∑Ķ§∑ĆgÚY§ň§Ť§√§∆ī_¬ §Ú”čň„§∑§∆§§§Į 12 * David Silver and Joel Veness(2010)
- 15. •¨•§•Ļ•Ņ©` 15 ? 2»ňĆĚĎť–Õ•≤©`•ŗ°ĘĪP√ś§Ō6x6 ? łų•◊•ž•§•š©`§Ō≥ŗ§ő•≥•ř4§ń «ŗ§ő•≥•ř4§ń§Ú≥÷§ń°£…ŌŌ¬◊ů”“§ňĄ”§Į ? ĆĚĎť•◊•ž•§•š©`§ő•≥•ř§ő…ę§Ō §Ĺ§ő•≥•ř§Ú»°§Ž§ř§«§Ô§ę§ť§ §§
- 16. •¨•§•Ļ•Ņ©`§őĄŔņŻŐűľĢ Ō¬”õ3§ń§ő§§§ļ§ž§ę§őŐűľĢ§Úúļ§Ņ§Ļ ? Ōŗ ÷§ő«ŗ•≥•ř§Ú§Ļ§Ŕ§∆»°§Ž ? ◊‘∑÷§ő≥ŗ•≥•ř§Ú§Ļ§Ŕ§∆»°§ť§ž§Ž ? ◊‘∑÷§ő«ŗ•≥•ř§¨•ī©`•Ž§ę§ťÕ—≥Ų§Ļ§Ž 16 ≥ű∆ŕŇš÷√
- 17. ≤Ņ∑÷”Qúy–‘ °įĆĚĎť•◊•ž•§•š©`§ő•≥•ř§ő…ę§Ō §Ĺ§ő•≥•ř§Ú»°§Ž§ř§«§Ô§ę§ť§ §§°Ī § §ő§«°Ę≥ű∆ŕ◊īĎB§«Ōŗ ÷§ő8§ń§ő•≥•ř§ő§¶§Ń §…§ő4§ń§¨≥ŗ§«§Ę§Ž§ő§ę 8C4 = 70Õ®§Í§őŅ…ń‹–‘§¨§Ę§Ž 17 ◊Ę: 2^8 = 256Õ®§Í§»Ņľ§®§Ž§»°Ę•≥•ř§¨»°§ť§ž§∆…ꧨī_∂®§∑§Ņ§≥§»§ň§Ť§Ž ňŻ§ő•≥•ř§ő–ŇńÓ§őłŁ–¬§¨ĪŪ¨F§«§≠§ §Į§ §Ž
- 18. Tinyįś »ňťg§¨ÜĖÓ}§ÚņŪĹ‚§∑§š§Ļ§Į§Ļ§Ž§Ņ§Š§ň 4x4ĪP√ś§ň≥ŗ§»«ŗ§¨1•≥•ř§ļ§ń§ő•–©`•ł•Á•ů§ÚŅľ §®§Ž §≥§őąŲļŌ°ĘĄŔņŻŐűľĢ§Ō ? Ōŗ ÷§ő«ŗ•≥•ř§Ú»°§Ž ? ◊‘∑÷§ő≥ŗ•≥•ř§Ú»°§ť§ž§Ž ? ◊‘∑÷§ő«ŗ•≥•ř§¨•ī©`•Ž§ę§ťÕ—≥Ų§Ļ§Ž §»§ §Ž 18
- 29. §™§Ķ§ť§§£ļ∑Ĺ≤Ŗ(policy) ∑Ĺ≤Ŗ ? ?, ? = ? ? ? ∑Ĺ≤Ŗ§Ō§Ę§Ž◊īĎB§«»°§Ž ÷§őī_¬ ∑÷≤ľ°£ ◊ÓŖm§ ∑Ĺ≤Ŗ§Ú“ä§ń§Ī§Ž§ő§¨ŹäĽĮ—ßŃē°£ 29
- 30. –ŇńÓ◊īĎB§őłŁ–¬ ? Ĺ”ī•§∑§∆§≠§Ņ§ę§ť≥ŗ§őŅ…ń‹–‘§¨łŖ§§§ņ§Ū§¶ ? ◊Ó≥ű§ňĄ”§§§Ņ•≥•ř§ņ§ę§ť«ŗ§őŅ…ń‹–‘§¨łŖ§§§ņ §Ū§¶ ? § §…°Ę”Qúy§Ú‘™§ň–ŇńÓ◊īĎB§ÚłŁ–¬§Ļ§Ž 30
- 32. ĆgÚY§ňĪō“™§ §‚§ő ? •∑•Ŗ•Ś•ž©`•Ņ ? Õ‚§ę§ť°łĹ٧ő◊īĎB§Ō§≥§ž§ņ§»§Ľ§Ť°Ļ§»÷ł∂®§«§≠§Ž §‚§ő§«§ §Ī§ž§–§ §ť§ §§ ? ––Ą”§ÚŖxík§∑§∆∑Ķ§Ļ ? §ń§ř§Í?(?|?) ? agent§Ōs§Ú÷ĪĹ””Qúy§«§≠§ §§£Ĺ•¨•§•Ļ•Ņ©`§ő•◊•ž •§•š©`§ŌŌŗ ÷§ő…ę§Ú”Qúy§«§≠§ §§ ? “䧼§∆§§§§«ťąů§ņ§ĪŖx§ů§«agent§ň∂…§Ļ 32
- 35. ňō∆”§ Ćg◊į «ŗ•≥•ř§«◊Ó∂ŐĹU¬∑§«•ī©`•Ž§ÚńŅ÷ł§ĻFastest »ňťg§«§‚§Ô§ę§Ž°ł§≥§ž«ŗ§ņ§Ū§¶§ °Ļ 35 .vvvv. ..vvv. v..... ...... .xoox. .xoo.x 1: 44.30% 2: 38.99% 3: 44.30% 4: 24.67% 8: 42.71% 9: 64.19% 10: 40.85% 12: 100.00%
- 36. §∑§–§ť§ĮŖM§ů§« ŖM§ů§«§≠§Ņ•≥•ř§Ú»°§√§Ņ÷ĪŠŠ°ĘŌŗ ÷§őĄ”§≠§Ú“ä§∆ «ŗ§ő•≥•ř§¨»ę≤Ņ§Ô§ę§√§Ņ§»Ň–∂Ō(ťgŖ`§§) 36 .vvvv. ..v.v. ...v.. ...o.. x.oox. .xo..x 2: 100.00% 10: 100.00% 15: 100.00% .vvvv. ..v.v. ...v.. ...o.. x.oox. .xo..x §≥§ž§¨’żĹ‚ ¨F◊ī§őĆg◊į§«§Ō”QúyĹYĻŻ§»–ŇńÓ§¨√¨∂‹§∑§Ņēr§ň§Ō–ŇńÓ§Ú»ę≤ŅéŁóȧ∑§∆§š§Í÷Ī§∑
- 37. ĆĚĎťĄŔ¬ Fastest§ŌRandom§ňḈ∑§∆§ŌŹä§§ {°ģWIN°Į: 979, °ģLOSE°Į: 21}: ĄŔ¬ 98% Random§ň§Ņ§ř§ň»°§ť§ž§Ž§≥§»§¨§Ę§√§∆§‚ üo≤Ŗ§ Random§Ť§Í§Ō§ņ§§§÷•ř•∑§ņ§ę§ť°£ “Ľ∑ĹFastest§»POMCP§ņ§» {°ģLOSE°Į: 95, °ģWIN°Į: 5}: ĄŔ¬ 5% Fastest§Ō––Ą”§ę§ť…ꧨ•–•ž•–•ž§ņ§ę§ť°£ 37 ŠŠ’Ŗ§őĆgÚY§ň24∑÷힧꧎
- 43. ◊Ę“‚Ķ„ ? •‚•ů•∆•ę•Ž•ŪńĺŐĹňų§Ō§Ť§Į°ł•ť•ů•ņ•ŗ§ň ÷§Ú Ŗx§ů§«ĹKĺ÷§ř§«•◊•ž•§°ĘĄŔ¬ §«‘uĀż°Ļ§»’h√ų §Ķ§ž§Ž§¨°Ę§≥§ž§ŌŹäĽĮ—ßŃē§ő—‘»~§«§§§®§– ērťg∑ýT°ķ°ř§«§őąů≥ͧÚÖß“ś§»§Ļ§Ž§≥§»°£ ? §≥§ž§ŌĪō“™ŐűľĢ§«§Ō§ §§°£ ? POMCP§ő’ďőń§«§ŌÖß“ś§ő∂®Ńx§»§∑§∆ łÓ“żąů≥ÍļÕ§Ú Ļ§√§∆§§§Ž°£ ? §ř§ŅłÓ§Í“ż§§§ŅĹYĻŻ§¨ ģ∑÷–°§Ķ§Į§ §Ž§»§≥§Ū §«īڧѫ–§Ž§Ņ§Š°ĘĆgŔ|Ķń§ň°łńĺ§ő…Ó§Ķ§ň…ŌŌř §Ú‘O§Ī§∆§§§Ž°Ļ§»§§§¶–ő§ň§ §Ž°£ 43
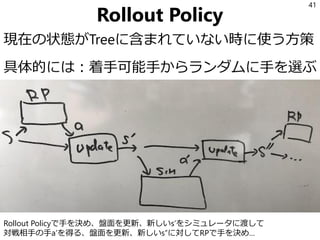
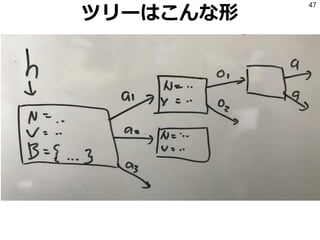
- 44. Tree Policy ¨F‘ŕ§ő◊īĎB§¨Tree§ňļ¨§ř§ž§∆§§§Ž§»§≠§ň Ļ§¶∑Ĺ≤Ŗ Tree§őłų•ő©`•…§Ō ?łųaction§≥§»§őÖß“ś§ő∆Ĺĺý V(h, a) ?łųaction§őŖxíkĽō ż N(h, a) ?–ŇńÓ B(h) §Ú≥÷§√§∆§§§Ž°£ ‘≠ ľĶń§ greedy∑Ĺ≤Ŗ:°łV§¨◊Óīů§ň§ §Ža§ÚŖx§÷°Ļ §Ť§Į Ļ§Ô§ž§ŽUCB1§ŌŖxíkĽō ż§¨…Ŕ§ §§Ŗxík÷ę§Ú łŖ§Š§ň‘uĀż§Ļ§Ž§≥§»§«ņŻ”√§»ŐĹňų§ő•»•ž©`•…•™•’ 44
- 45. ◊Ę“‚Ķ„ °ł¨F‘ŕ§ő◊īĎB§¨°ę°Ļ§»’h√ų§∑§∆§Ņ§Ī§…°Ę •ń•Í©`§ő•ő©`•…§Ō◊īĎB§«§Ō§ §Į ¬ńös(history)§ňĆ̏ͧҧ§§∆§§§Ž°£ Q: state§ňĆĚŹÍł∂§Ī§∆§Ō•ņ•Š§ §ő§ę£Ņ A: ŽL§ž◊īĎB§Ō”Qúy§«§≠§ §§§ő§«•®©`•ł•ß•ů•»§¨ §…§ő•ő©`•…§ÚŖx§ů§ņ§ť§§§§§ę§¨§Ô§ę§ť§ §§ Q: §ł§„§ĘĹ٧ő”QúyŅ…ń‹◊īĎB§ňĆĚŹÍł∂§Ī§Ņ§ť£Ņ A: ”QúyŅ…ń‹§ ĪP√ś◊īõr§¨Õ¨§ł§«§‚Ŗ^»•§ňÕ®§√§Ņ ĹU¬∑§ň§Ť§√§∆–ŇńÓ§¨ģź§ §Ž§ę§ť•ņ•Š 45
- 46. ¬ńös ¬ńös§Ō“‘Ō¬§ő§Ť§¶§ –Õ ? ≥ű∆ŕ◊īĎB: empty ? §‚§∑§Į§Ō“‘Ō¬§őĹM§ŖļŌ§Ô§Ľ ? ÷Ī«į§ř§«§ő¬ńös h ? ◊‘∑÷§¨»°§√§Ņ––Ą” a ? §Ĺ§őĹYĻŻĶ√§ť§ž§Ņ”Qúy o a, o, a, o, °≠§»§§§¶≤Ľ∂®ťL§őŃ–§ň§ §Ž 46
- 48. •ń•Í©`§Ō§≥§ů§ –ő(ąRŅs) h§őēr°Ęh§Ō•ń•Í©`§ňļ¨§ř§ž§∆§§§Ž§ő§« Tree Policy§¨§ń§ę§Ô§ž§Ž°£ ÷a0§ÚŖx§”––Ą”§∑§ŅĹYĻŻ°Ęo2§Ú”Qúy§∑§Ņ§»§Ļ§Ž (h, a0, o2)§Ō•ń•Í©`§ň§ §§§ő§«•ő©`•…§Ú…ķ≥…§∑°Ę Rollout Policy§«ĺA§≠§ÚĆg––§Ļ§Ž°£ 48
- 49. 49
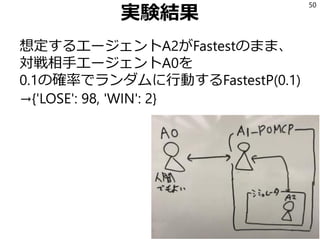
- 51. ī_¬ §ÚČš§®§∆ĆgÚY Fastest°ķ {°ģLOSE°Į: 95, °ģWIN°Į: 5} FastestP(0.1)°ķ {'LOSE': 98, 'WIN': 2} FastestP(0.3)°ķ {°ģLOSE°Į: 95, °ģWIN°Į: 5} FastestP(0.5)°ķ {'LOSE': 92, 'WIN': 8} FastestP(0.7)°ķ {'LOSE': 95, 'WIN': 5} FastestP(0.9)°ķ {'LOSE': 90, 'WIN': 10} Random°ķ {'LOSE': 88, 'WIN': 12} •ť•ů•ņ•ŗĎť¬‘§»FastestĎť¬‘§ő§…§ů§ Ī»¬ §«§őĽžļŌ §ňḈ∑§∆§‚POMCP§Ō9łÓ“‘…Ō§őĄŔ¬ 51
- 54. ŖW§§ņŪ”…2 Tree§őĆg◊į§¨ ÷íi§≠§«°Ę•Ō•√•∑•Ś§ň(h, a, o)§Ú •≠©`§»§∑§∆•ń•√•≥§ů§«§§§Ž°£ Tree§Ú’ś√śńŅ§ň•ń•Í©`§«Ćg◊į§∑§Ť§¶§»ňľ§√§Ņ§ť a(ĺŖŐŚĶń§ň§ŌĄ”§ę§Ļ•≥•ř§»§Ĺ§őĄ”§ĮŌÚ§≠)§š o(ĺŖŐŚĶń§ň§ŌĪP√ś◊īõr)§Ú’Ż ż§ň•ř•√•◊§Ļ§ŽĪō“™ §¨§Ę§Ž§¨√śĶĻ§ņ§√§Ņ§ő§«(h, a, o)§ő•Ņ•◊•Ž§ň§∑§∆ Python§ň•Ō•√•∑•Śāé§Ú”čň„§Ķ§Ľ§∆§§§Ž°£ §…§¶Ņľ§®§∆§‚•Š•‚•Í§őüoŮj«≤§§°£ 54
- 56. §ř§»§Š ? Point Based Value Iteration§Ō◊īĎBŖw“∆ī_¬ §Ú”Ž §®§ŽĪō“™§¨§Ę§Ž ? §Ĺ§≥§«•÷•ť•√•Į•‹•√•Į•Ļ•∑•Ŗ•Ś•ž©`•Ņ§Ú Ļ§¶ ≤Ņ∑÷”Qúy•‚•ů•∆•ę•Ž•Ūľ∆Ľ≠∑®(POMCP)§ÚĆg◊į ? •¨•§•Ļ•Ņ©`§ňŖm”√§∑§∆°Ę§Ę§Žī_¬ §««ŗ•≥•ř§« §ő•ī©`•Ž§ÚńŅ÷ł§Ļ§Ť§¶§ Ōŗ ÷§ňḈ∑§∆§ŌŽL§ž ◊īĎB§ÚÕ∆∂®§∑§∆9łÓĹŁ§§ĄŔ¬ §Ú≥Ų§∑§Ņ ? §‚§√§»»ňťg§ň§»§√§∆◊‘√ų§«§ §§ňľŅľ•Ž©`•Ń•ů §«ĆgÚY§Ú§∑§Ņ§§ 56
- 57. ≤őŅľőńŌ◊ David Silver and Joel Veness "Monte-Carlo planning in large POMDPs." Advances in neural information processing systems. 2010. 57