



![5
8
? Hitachi, Ltd. 2022. All rights reserved.
5.1 ©≤fl¢Ÿ:•·•‚•Í§Œ•¢•Ø•ª•π∑˘íà¥Û(1)£∫∏≈“™
•≥•‘©`‘™≈‰¡–
•≥•‘©`œ»≈‰¡–
•≥•‘©`‘™≈‰¡–
•≥•‘©`œ»≈‰¡–
Start
i = 0
d[i] = s[i]
i < N?
End
s[]
d[]
s[]
d[]
t[]
i = i + 1
Start
i = 0
t[0] = s[i]
t[1] = s[i + 1]
...
t[7] = s[i + 7]
i < N?
End
i = i + 8
d[i] = t[0]
d[i + 1] = t[1]
...
d[i + 7] = t[7]
No
Yes
No
Yes
? ≈‰¡–§´§È≈‰¡–§À•«©`•ø§Ú•≥•‘©`§π§Î•±©`•π
? ≈‰¡–§œ°¢•≥•‘©`‘™?•≥•‘©`œ»§»§‚°¢FPGA§Œƒ⁄≤ø•·•‚•Í§À•fi•√•◊§π§Î•±©`•π
? ≈‰¡–§´§È≈‰¡–§ÿ÷±Ω”•≥•‘©`§π§Î”õ ˆ§‰°¢•Î©`•◊?•¢•Û•Ì©`•Í•Û•∞§¨§µ§Ï§ §§
àˆ∫œ§À°¢£±“™Àÿ§∫§ƒ§Œ÷¥Œ•≥•‘©`§À§ §Í“◊§§
? Õæ÷–§À•Ï•∏•π•ø≈‰¡–§Ú÷√§≠°¢•Î©`•◊’πÈ_§π§Î§≥§»§«—} ˝“™ÀÿÕ¨ïr§À•≥•‘©`
? ≈‰¡–§´§È≈‰¡–§À•«©`•ø§Ú•≥•‘©`§π§Î•±©`•π
? ≈‰¡–§œ°¢•≥•‘©`‘™?•≥•‘©`œ»§»§‚°¢FPGA§Œƒ⁄≤ø•·•‚•Í§À•fi•√•◊§π§Î•±©`•π
? ≈‰¡–§´§È≈‰¡–§ÿ÷±Ω”•≥•‘©`§π§Î”õ ˆ§‰°¢•Î©`•◊?•¢•Û•Ì©`•Í•Û•∞§¨§µ§Ï§ §§
àˆ∫œ§À°¢£±“™Àÿ§∫§ƒ§Œ÷¥Œ•≥•‘©`§À§ §Í“◊§§
? Õæ÷–§À•Ï•∏•π•ø≈‰¡–§Ú÷√§≠°¢•Î©`•◊’πÈ_§π§Î§≥§»§«—} ˝“™ÀÿÕ¨ïr§À•≥•‘©`
•Ï•∏•π•ø≈‰¡–
? •Ï•∏•π•ø≈‰¡–§Ú
ΩU”…
? •Î©`•◊?
•¢•Û•Ì©`•Í•Û•∞
? •Ï•∏•π•ø≈‰¡–§Ú
ΩU”…
? •Î©`•◊?
•¢•Û•Ì©`•Í•Û•∞
1“™Àÿ§∫§ƒ•≥•‘©` —} ˝“™Àÿ
Õ¨ïr•≥•‘©`
(•≥•‘©`‘™/•≥•‘©`œ»≈‰¡–§»§‚FPGAƒ⁄≤ø
•·•‚•Í§À•fi•√•◊)
9
? Hitachi, Ltd. 2022. All rights reserved.
5.2 ©≤fl¢Ÿ:•·•‚•Í•¢•Ø•ª•π∑˘íà¥Û(2)£∫ •œ•√•∑•Â•∆©`•÷•Î∏¸–¬ ‘™§Œòã‘Ï
Œƒ◊÷¡–(9Œƒ◊÷) Œª÷√ Œƒ◊÷¡–(9Œƒ◊÷)
¢Ÿœ»Ó^4Œƒ◊÷§«
•œ•√•∑•ÂÇé”ãÀ„
Œª÷√
¢⁄“ªΩM§∫§ƒ•∑•’•»
¢€œ»Ó^§À”õÂh
œ» ··
•œ•√•∑•Â•∆©`•÷•Î
»Î¡¶•«©`•ø
(¥«ï¯)
16bit 8bit°¡9Œƒ◊÷ = 72bit
Start
¢Ÿœ»Ó^4Œƒ◊÷§«•œ•√•∑•ÂÇé§Ú”ãÀ„
i = 7
i ®R1?
•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i].Œª÷√
=•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i-1].Œª÷√
¨F‘⁄Œª÷√
j = 0
•≥•‘©`œ»Œƒ◊÷¡–[j] = •≥•‘©`‘™Œƒ◊÷¡–[j]
j = j +1
i = i - 1
j < 9?
•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][0].Œª÷√
=¨F‘⁄Œª÷√
9Œƒ◊÷•≥•‘©`:
•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][0].Œƒ◊÷¡–
= ¨F‘⁄Œª÷√§ŒŒƒ◊÷¡–
9Œƒ◊÷•≥•‘©`:
•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i].Œƒ◊÷¡– =
•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i-1].Œƒ◊÷¡–
End
9Œƒ◊÷•≥•‘©`
End
¢⁄“ªΩM§∫§ƒ•∑•’•» ¢€œ»Ó^§À”õÂh
? •œ•√•∑•Â•∆©`•÷•Î§À¥«ï¯ƒ⁄§ŒŒª÷√§»œ»Ó^§Œ
9Œƒ◊÷§∫§ƒ§¨µ«Âh§µ§Ï§∆§§§Î
? º»¥Êƒ⁄»›§Ú“∆Ñ”(•∑•’•»)§∑§ø…œ§«°¢»Î¡¶•«©`
•ø§Œ¨F‘⁄Œª÷√§´§È§Œ9Œƒ◊÷§Ú–¬“鵫Âh
? •œ•√•∑•Â•∆©`•÷•Î§À¥«ï¯ƒ⁄§ŒŒª÷√§»œ»Ó^§Œ
9Œƒ◊÷§∫§ƒ§¨µ«Âh§µ§Ï§∆§§§Î
? º»¥Êƒ⁄»›§Ú“∆Ñ”(•∑•’•»)§∑§ø…œ§«°¢»Î¡¶•«©`
•ø§Œ¨F‘⁄Œª÷√§´§È§Œ9Œƒ◊÷§Ú–¬“鵫Âh
œ»Ó^§´§Èó ñÀ
•œ•√•∑•Â•∆©`•÷•Î∏¸–¬
§Œ•’•Ì©`•¡•„©`•»(‘™)
(•µ•÷•Î©`•¡•Û§«”õ›d)
No
Yes
No
Yes
(16bit+72bit)°¡8(•∑•Œ•À•‡) = 704bit(88byte)
¥Û§≠§ •®•Û•»•Í§Ú
1Œƒ◊÷(•–•§•»)§∫§ƒ
÷¥Œ•¢•Ø•ª•π
8
9](https://image.slidesharecdn.com/9acri-220726104108-f8d2c96f/85/9-ACRi-_-5-320.jpg)
![6
10
? Hitachi, Ltd. 2022. All rights reserved.
5.3 ©≤fl¢Ÿ:•·•‚•Í•¢•Ø•ª•π∑˘íà¥Û(3)£∫•œ•√•∑•Â•∆©`•÷•Î∏¸–¬ ∏ƒ…∆≤fl
? •œ•√•∑•Â•∆©`•÷•Î§Ú°¢Œª÷√§Œ«ÈàÛ§Œ•∆©`•÷•Î§»
Œƒ◊÷¡–§Œ•∆©`•÷•Î§À∑÷∏Ó
? •®•Û•»•Í(Œª÷√+Œƒ◊÷¡–8ΩM∑÷)§Ú•Ï•∏•π•ø§À
§∫§È§∑§∆’i…œ§≤°¢ï¯§≠믧π
? •œ•√•∑•Â•∆©`•÷•Î§Ú°¢Œª÷√§Œ«ÈàÛ§Œ•∆©`•÷•Î§»
Œƒ◊÷¡–§Œ•∆©`•÷•Î§À∑÷∏Ó
? •®•Û•»•Í(Œª÷√+Œƒ◊÷¡–8ΩM∑÷)§Ú•Ï•∏•π•ø§À
§∫§È§∑§∆’i…œ§≤°¢ï¯§≠믧π
Œª÷√
16bit
Œª÷√
16bit°¡8 = 128bit
Œª÷√
72bit°¡8 = 576bit
¢Ÿœ»Ó^4Œƒ◊÷§«
•œ•√•∑•ÂÇé”ãÀ„
¢⁄§∫§È§∑§∆’i§fl…œ§≤
¢€œ»Ó^§À∏Òº{
œ» ··
•œ•√•∑•Â•∆©`•÷•Î
(∑÷∏Ó··)
»Î¡¶•«©`•ø
(¥«ï¯)
16bit 8bit°¡9Œƒ◊÷ = 72bit
¨F‘⁄Œª÷√ œ»Ó^§´§Èó ñÀ
Œƒ◊÷¡–(9Œƒ◊÷)
•Ï•∏•π•ø
¢‹ï¯§≠믧∑
Start
¢Ÿœ»Ó^4Œƒ◊÷§«•œ•√•∑•ÂÇé§Ú”ãÀ„
i = 7
i ®R1?
•Ï•∏•π•ø(Œª÷√)[i]
=•œ•√•∑•Â•∆©`•÷•Î(Œª÷√)[•œ•√•∑•ÂÇé][i-1]
i = i - 1
•Ï•∏•π•ø(Œª÷√)[0] = ¨F‘⁄Œª÷√
9Œƒ◊÷•≥•‘©`(•◊•È•∞•fi§«•¢•Û•Ì©`•Í•Û•∞)
•Ï•∏•π•ø(Œƒ◊÷¡–)[0]=¨F‘⁄Œª÷√§ŒŒƒ◊÷¡–
9Œƒ◊÷•≥•‘©`(•◊•È•∞•fi§«•¢•Û•Ì©`•Í•Û•∞)
•Ï•∏•π•ø(Œƒ◊÷¡–)[i] =
•œ•√•∑•Â•∆©`•÷•Î(Œƒ◊÷¡–)[•œ•√•∑•ÂÇé][i-1]
End
¢⁄§∫§È§∑§∆’i§fl…œ§≤ ¢€œ»Ó^§À∏Òº{
•œ•√•∑•Â•∆©`•÷•Î∏¸–¬§Œ
•’•Ì©`•¡•„©`•»(∏ƒ…∆∞Ê)
Œª÷√°¢Œƒ◊÷¡–§Ú§Ω§Ï§æ§Ï
ÅK¡–§À•¢•Ø•ª•π
No
Yes
•œ•√•∑•Â•∆©`•÷•Î(Œª÷√)[•œ•√•∑•ÂÇé][0°´7]
= •Ï•∏•π•ø(Œª÷√)[0°´7]
9Œƒ◊÷•≥•‘©`(•◊•È•∞•fi§«•¢•Û•Ì©`•Í•Û•∞)°¡8:
•œ•√•∑•Â•∆©`•÷•Î(Œƒ◊÷¡–)[•œ•√•∑•ÂÇé][0°´7]
= •Ï•∏•π•ø(Œƒ◊÷¡–)[0°´7]
¢‹ï¯§≠믧∑
¢⁄
¢‹
¢€
11
? Hitachi, Ltd. 2022. All rights reserved.
6.1 ©≤fl¢⁄:•«©`•ø•’•Ì©`ªØ(1) •«©`•ø©`•’•Ì©`ªØflm”√«∞
? ∂˛§ƒ§ŒÑI¿Ì§Ú∫¨§‡•Î©`•◊
? §Ω§Ï§æ§Ï§ŒÑI¿Ì§ŒÈg§«°¢â‰ ˝§Ú”√§§§∆°¢“ª∑Ω§´§ÈÀ˚∑Ω§ÿ•«©`•ø§Ú ‹§±∂…§∑
?§Ω§Ï§æ§Ï§Œªÿ¬∑§¨÷¥ŒÑ”◊˜§»§ §Î
? ∂˛§ƒ§ŒÑI¿Ì§Ú∫¨§‡•Î©`•◊
? §Ω§Ï§æ§Ï§ŒÑI¿Ì§ŒÈg§«°¢â‰ ˝§Ú”√§§§∆°¢“ª∑Ω§´§ÈÀ˚∑Ω§ÿ•«©`•ø§Ú ‹§±∂…§∑
?§Ω§Ï§æ§Ï§Œªÿ¬∑§¨÷¥ŒÑ”◊˜§»§ §Î
Start
≥ı∆⁄ªØÑI¿Ì
ÑI¿Ìa
ΩK¡À≈–∂®
ÑI¿Ìb
End
ΩK¡ÀÑI¿Ì
≠˝
≠˝
≠˝
≥ı∆⁄ªØÑI¿Ì
ªÿ¬∑
ÑI¿Ìa ªÿ¬∑
ÑI¿Ìb ªÿ¬∑
≈–∂®ªÿ¬∑
ΩK¡ÀÑI¿Ì
ªÿ¬∑
≥ı∆⁄•«©`•ø
÷–Èg•«©`•ø
≥ˆ¡¶•«©`•ø
¿R∑µ§∑
–≈∫≈
ΩK¡À•«©`•ø
ïrÈg›S T1 T2 T3 T4 T5 T6 T7 T8
≥ı∆⁄ªØªÿ¬∑ Ñ”◊˜
ÑI¿Ìa ªÿ¬∑ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜
ÑI¿Ìb ªÿ¬∑ Ñ”◊˜ Ñ”◊˜
≈–∂®ªÿ¬∑ Ñ”◊˜ Ñ”◊˜
ΩK¡ÀÑI¿Ìªÿ¬∑
÷¥ŒÑ”◊˜:3•µ•§•Ø•Î•‘•√•¡
ÑI¿Ì•’•Ì©`•¡•„©`•» ªÿ¬∑òã≥…
10
11](https://image.slidesharecdn.com/9acri-220726104108-f8d2c96f/85/9-ACRi-_-6-320.jpg)

![9
16
? Hitachi, Ltd. 2022. All rights reserved.
7.3 ©≤fl¢€:Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞(3):≈‰¡–•¢•Ø•ª•π§ÿ§ŒåùèÍ
?•Ï•∏•π•ø≈‰¡–§Ú∂˛§ƒ π”√°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷¡–§Ú
•Ï•∏•π•ø≈‰¡–§À“ªµ©∏Òº{§∑§∆±»›^
? Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§Ú°¢•¢•Ø•ª•π∑˘(”“
¿˝§«§œ•¢•Û•Ì©`•Î ˝§À∫œ§Ô§ª§ø8Byte)§ÚÖg
Œª§»§π§Î∂˛¥Œ‘™≈‰¡–§»§π§Î
? •Ï•∏•π•ø≈‰¡–§œ°¢“ªªÿ§Œ≈‰¡–•¢•Ø•ª•π∑˘
(8)§Œ2±∂(16)§Œ“™Àÿ ˝§»§π§Î
? ±»›^§œ•Ï•∏•π•ø≈‰¡–…œ§«°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷
¡–Œª÷√§´§È°¢“ªªÿ§À◊Ó¥Û•¢•Û•Ì©`•Î ˝∑÷
£Ω•¢•Ø•ª•π∑˘∑÷§ŒŒƒ◊÷ ˝(8)§Ú±»›^
? ±»›^··°¢•Ï•∏•π•ø≈‰¡–§Œƒ⁄»›§Ú•∑•’•»
1. •Ï•∏•π•ø≈‰¡–§Œ··∞΃⁄»›§Ú«∞∞ΧÀ•≥•‘©`
2. Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§´§È•¢•Ø•ª•π∑˘
(8Byte)∑÷’i≥ˆ§∑°¢•Ï•∏•π•ø≈‰¡–§Œ··
∞ΧÀ∏Òº{
?•Ï•∏•π•ø≈‰¡–§Ú∂˛§ƒ π”√°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷¡–§Ú
•Ï•∏•π•ø≈‰¡–§À“ªµ©∏Òº{§∑§∆±»›^
? Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§Ú°¢•¢•Ø•ª•π∑˘(”“
¿˝§«§œ•¢•Û•Ì©`•Î ˝§À∫œ§Ô§ª§ø8Byte)§ÚÖg
Œª§»§π§Î∂˛¥Œ‘™≈‰¡–§»§π§Î
? •Ï•∏•π•ø≈‰¡–§œ°¢“ªªÿ§Œ≈‰¡–•¢•Ø•ª•π∑˘
(8)§Œ2±∂(16)§Œ“™Àÿ ˝§»§π§Î
? ±»›^§œ•Ï•∏•π•ø≈‰¡–…œ§«°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷
¡–Œª÷√§´§È°¢“ªªÿ§À◊Ó¥Û•¢•Û•Ì©`•Î ˝∑÷
£Ω•¢•Ø•ª•π∑˘∑÷§ŒŒƒ◊÷ ˝(8)§Ú±»›^
? ±»›^··°¢•Ï•∏•π•ø≈‰¡–§Œƒ⁄»›§Ú•∑•’•»
1. •Ï•∏•π•ø≈‰¡–§Œ··∞΃⁄»›§Ú«∞∞ΧÀ•≥•‘©`
2. Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§´§È•¢•Ø•ª•π∑˘
(8Byte)∑÷’i≥ˆ§∑°¢•Ï•∏•π•ø≈‰¡–§Œ··
∞ΧÀ∏Òº{
8bytes
«∞∞Î
··∞Î
•¢•Ø•ª•Î∑˘(8byte)ÖgŒª§À’i≥ˆ§∑°¢
•Ï•∏•π•ø≈‰¡–§Œ··∞ΧÀ∏Òº{
•Ï•∏•π•ø≈‰¡–a
“ªªÿ§Œ±»›^åùœÛ
(◊Ó¥Û8Œƒ◊÷)
Œƒ◊÷¡–b
(œ»Ó^Œª÷√b)
Œƒ◊÷¡–a
(œ»Ó^Œª÷√a)
Œƒ◊÷¡–§¨∏Òº{§µ§Ï§∆§§§Î≈‰¡–:
(2¥Œ‘™≈‰¡–§»§∑§∆°¢FPGAƒ⁄≤ø
•·•‚•Í§ÿ•fi•√•◊)
«∞∞Î
··∞Î
•Ï•∏•π•ø≈‰¡–b
··∞Χ´§È
«∞∞Χÿ
•≥•‘©`
··∞Χ´§È
«∞∞Χÿ
•≥•‘©`
N bytes
N bytes
“ªªÿµ±§ø§Í§Œ
’i≥ˆ§∑ÖgŒª
“ªªÿµ±§ø§Í§Œ
’i≥ˆ§∑ÖgŒª
17
? Hitachi, Ltd. 2022. All rights reserved.
7.4 ©≤fl¢€:Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞(4)£∫∏ƒ…∆··
8bytes
N bytes
N bytes
«∞∞Î
··∞Î
•Ï•∏•π•ø≈‰¡–a
“ªªÿ§Œ±»›^åùœÛ
(◊Ó¥Û8Œƒ◊÷)
Œƒ◊÷¡–b
(œ»Ó^Œª÷√b)
Œƒ◊÷¡–a
(œ»Ó^Œª÷√a)
Œƒ◊÷¡–§¨∏Òº{§µ§Ï§∆§§§Î≈‰¡–:
«∞∞Î
··∞Î
•Ï•∏•π•ø≈‰¡–b
? •Î©`•◊È_ º«∞§Œ≥ı∆⁄ªØ§«•Ï•∏•π•ø≈‰¡–§Œ◊Ó
≥ı§Œƒ⁄»›°¢Œƒ◊÷¡–±»›^Œª÷√§Úú lj
? ¿R∑µ§∑ïr§À•Ï•∏•π•ø≈‰¡–ƒ⁄»›§ÚÌò§À•∑•’•»
? •Î©`•◊È_ º«∞§Œ≥ı∆⁄ªØ§«•Ï•∏•π•ø≈‰¡–§Œ◊Ó
≥ı§Œƒ⁄»›°¢Œƒ◊÷¡–±»›^Œª÷√§Úú lj
? ¿R∑µ§∑ïr§À•Ï•∏•π•ø≈‰¡–ƒ⁄»›§ÚÌò§À•∑•’•»
Start
i < N?
•Ï•∏•π•ø≈‰¡–a[x]=
•Ï•∏•π•ø≈‰¡–b[y]?
No
Yes
No
Yes
C = 0
¢€
¢Ÿ ¢⁄
•Ï•∏•π•ø≈‰¡–a[]
°˚ Œƒ◊÷¡–a§Œœ»Ó^∫¨§‡8byte
+ ¥Œ§Œ8byte
•Ï•∏•π•ø≈‰¡–b[]
°˚ Œƒ◊÷¡–b§Œœ»Ó^∫¨§‡8byte
+ ¥Œ§Œ8byte
x = Œƒ◊÷¡–a§ŒÈ_ ºŒª÷√(8§ŒÑ蔇)
y = Œƒ◊÷¡–b§ŒÈ_ ºŒª÷√(8§ŒÑ蔇)
i = 0
End
Yes
i + 7 < N?
No
Yes
No
Yes
C = 7
C = 8
i = i + C
C < 8?
No
Yes
¢€
¢Ÿ ¢⁄
¿R∑µ§∑
•Ï•∏•π•ø≈‰¡–a[x+7]=
•Ï•∏•π•ø≈‰¡–b[y+7]?
•Ï•∏•π•ø≈‰¡–a§Œƒ⁄»›•∑•’•»
(≈‰¡–«∞∞ΰ˚≈‰¡–··∞ΰ¢
≈‰¡–··∞ΰ˚Œƒ◊÷¡–a§Œ
¥Œ§Œ8byte)
•Ï•∏•π•ø≈‰¡–b§Œƒ⁄»›•∑•’•»
(≈‰¡–«∞∞ΰ˚≈‰¡–··∞ΰ¢
≈‰¡–··∞ΰ˚Œƒ◊÷¡–b§Œ
¥Œ§Œ8byte)
y
x (Œƒ◊÷¡–a§ŒÈ_ º
Œª÷√§Œ8§ŒÑ蔇)
(Œƒ◊÷¡–b§ŒÈ_ º
Œª÷√§Œ8§ŒÑ蔇)
16
17](https://image.slidesharecdn.com/9acri-220726104108-f8d2c96f/85/9-ACRi-_-9-320.jpg)































More Related Content
What's hot (20)
Similar to µ⁄9ªÿ¥°∞‰∏È汕¶•ß•”• ©`≥»’¡¢£Øµ∫ÃÔòΩ≤—›◊ ¡œ (20)










![[C23] °∏ΩÒ°π§Ú∑÷Œˆ§π§Î•π•»•Í©`•‡•«©`•øÑI¿Ìºº–g§»§Ω§Œø…ƒ‹–‘ by Takahiro Yokoyama](https://cdn.slidesharecdn.com/ss_thumbnails/c23hitachiyokoyama-131215225816-phpapp01-thumbnail.jpg?width=560&fit=bounds)







More from ÷±æ√ ◊°¥® (20)




















µ⁄9ªÿ¥°∞‰∏È汕¶•ß•”• ©`≥»’¡¢£Øµ∫ÃÔòΩ≤—›◊ ¡œ
- 1. 1 ? Hitachi, Ltd. 2022. All rights reserved. ÷Í Ωª·…Á »’¡¢—u◊˜À˘ —–æøÈ_∞k•∞•Î©`•◊ •«•∏•ø•Î•◊•È•√•»•’•©©`•‡•§•Œ•Ÿ©`•∑•Á•Û•ª•Û•ø •«©`•ø•π•»•Ï©`•∏—–æø≤ø 2022/7/26 çuÃÔ Ω°Ã´¿… —}Îj§ •¢•Î•¥•Í•∫•‡§Œ•œ©`•…ªØ§À§™§±§Î∏flŒª∫œ≥…§ŒªÓ”√ ¬¿˝ µ⁄9ªÿACRi•¶•ß•”• ©` ? Hitachi, Ltd. 2022. All rights reserved. 1. ◊‘º∫ΩBΩÈ 2. ±≥æ∞£∫—}Îj§ •¢•Î•¥•Í•∫•‡§Œ•œ©`•…ªØ§À§™§±§Î’nÓ}?∏flŒª∫œ≥…§Œ¿˚µ„ 3. Ó}≤ƒ£∫àRøs•¢•Î•¥•Í•∫•‡LZMA 4. ’nÓ}£∫∏flŒª∫œ≥…§Œ≥ı∆⁄‘á––◊¥õr 5. ©≤fl¢Ÿ£∫•·•‚•Í•¢•Ø•ª•π∑˘íà¥Û 6. ©≤fl¢⁄£∫•«©`•ø•’•Ì©`ªØ 7. ©≤fl¢€£∫Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞ 8. ‘uÅ˝£∫±æ ¬¿˝§À§™§±§Î∏ƒ…∆ ©≤fl§ŒÑøπ˚ 9. ∏flŒª∫œ≥…§ŒªÓ”√§fi§»§· Contents 1 0 1
- 2. 2 2 ? Hitachi, Ltd. 2022. All rights reserved. £±£Æ◊‘º∫ΩBΩÈ çuÃÔ Ω°Ã´¿… —–æøÈ_∞k•∞•Î©`•◊ •«•∏•ø•Î•◊•È•√•»•’•©©`•‡•§•Œ•Ÿ©`•∑•Á•Û•ª•Û•ø •«©`•ø•π•»•Ï©`•∏—–æø≤ø À˘ Ù ? 1993ƒÍ»Î…Á ? »Î…Áµ±≥ı§œ°¢•π©`•—©`•≥•Û•‘•Â©`•ø§Œ•◊•Ì•ª•√•µ§Œ‘O”ãÈ_∞k§Àèæ ¬ ? §Ω§Œ··°¢•œ©`•…•¶•ß•¢?•¢©`•≠•∆•Ø•¡•„§Œ—–æøÈ_∞k§Àèæ ¬ ? ’ì¿Ì‘O”㧜°¢ASIC§«°¢RTL§‰•≤©`•»•Ï•Ÿ•Î‘O”ã/•π•±•fi•∆•£•√•Ø§ ‘O”ã§ÚΩUÚY ? ΩÒªÿ°¢FPGA§Ú”√§§§∆—}Îj§ •¢•Î•¥•Í•∫•‡§Ú•œ©`•…ªØ§π§Î§Àµ±§ø§Í°¢∏flŒª∫œ≥…§ŒªÓ”√§Ú––§√§ø •≤©`•»•Ï•Ÿ•Î‘O”ã/•π•±•fi•∆•£•√•Ø‘O”ã Adder(int a, int b, int c) { c = a + b; } ∏flŒª∫œ≥…(∏flŒª—‘’Z”õ ˆ) a b c 3 ? Hitachi, Ltd. 2022. All rights reserved. 2.1 ±≥æ∞(1)£∫—}Îj§ •¢•Î•¥•Í•∫•‡§Œ•œ©`•…ªØ§À§™§±§Î’nÓ} 1. —}Îj§ •¢•Î•¥•Í•∫•‡§Ú•œ©`•…ªØ§π§Îàˆ∫œ°¢Õ®≥£§ŒRTL‘O”㧫§¢§Î§»°¢‘îºö‘O”ã?åg◊∞‘O”ã§Ú∫¨§·°¢ ∂‡¥Û§ È_∞kπ§ ˝§Ú“™§∑°¢•œ©`•…ªØ§Œ“äÕ®§∑§Úµ√§Î§Œ§À?∆⁄Èg§´§´§Î 2. ‘O”ãµ±≥ı§Œ∂ŒÎA( Àòî‘O”ã/ôCƒ‹‘O”ã∂ŒÎA)§«§œ°¢–‘ƒ‹§‰ŒÔ¡ø§Œ“äÕ®§∑§¨¿ßÎy 3. ‘O”ã§∑§øΩYπ˚§Ú–‘ƒ‹µ»‘uÅ˝§«§≠§Î§Œ§¨°¢··π§≥继 §Í°¢•’•£©`•…•–•√•Ø§Ú––§¶π§ ˝¥Û 4. ∏¸§À‘™§Œ•¢•Î•¥•Í•∫•‡•Ï•Ÿ•Î§«§Œ◊ÓflmªØ§Ú––§¶§»°¢∂‡¥Û§ ‘Ÿ‘O”ã§Œπ§ ˝§¨∞k…˙ ‘îºö‘O”ã (RTL‘O”ã) åg◊∞‘O”ã FPGA ’ì¿Ì∫œ≥… Àòî‘O”ã/ôCƒ‹‘O”ã RTL ”õ ˆ åg◊∞ΩYπ˚ ?–‘ƒ‹(‘îºö) ?ŒÔ¡ø(‘îºö) ôCƒ‹ Àòî/•¢•Î•¥•Í•∫•‡ ∏ƒ…∆/◊ÓflmªØ(•’•£©`•…•–•√•Ø) (åg◊∞∏ƒ…∆) åg◊∞«ÈàÛ (≤ø∑÷µƒRTL∏ƒ…∆) •¢•Î•¥•Í•∫•‡•Ï•Ÿ•Î∏ƒ…∆?¥Ûπ§ ˝∞k…˙ RTL‘O”ãfl^≥Ã(•§•·©`•∏) 2 3
- 3. 3 4 ? Hitachi, Ltd. 2022. All rights reserved. 2.2 ±≥æ∞(2)£∫—}Îj§ •¢•Î•¥•Í•∫•‡§Œ•œ©`•…ªØ§À§™§±§Î∏flŒª∫œ≥…§Œ¿˚µ„ 1. ∏flŒª—‘’Z§«”õ ˆ§µ§Ï§ø—}Îj§ •¢•Î•¥•Í•∫•‡§«§‚°¢∂Ã∆⁄Èg§«•œ©`•…•¶•ß•¢ªØ§Œ“äÕ®§∑§¨µ√§È§Ï§Î 2. ◊ÓµÕœfifl_≥…ø…ƒ‹§ °¢–‘ƒ‹§‰ŒÔ¡ø§¨‘Á∆⁄§À§Ô§´§Î 3. –‘ƒ‹§‰ŒÔ¡ø§Ú°¢‘Á∆⁄§À•◊•Ì•’•°•§•Î•«©`•ø§´§È“ä§Î§≥§»§À§Ë§Í°¢•’•£©`•…•–•√•Ø§Œπ§ ˝µÕúpø…ƒ‹ 4. •¢•Î•¥•Í•∫•‡•Ï•Ÿ•Î§«§Œ◊ÓflmªØ§¨»›“◊ Adder(int a, int b, int c) { c = a + b; } ∏flŒª∫œ≥… ∫œ≥…ΩYπ˚ ∏flŒª—‘’Z•Ω©`•π (•¢•Î•¥•Í•∫•‡”õ ˆ) FPGA •◊•Ì•’•°•§•Î •«©`•ø ?–‘ƒ‹(»´Ã°¢Èv ˝ÖgŒª) ?ŒÔ¡ø(Õ¨…œ) ?‘îºö•«©`•ø(“¿¥ÊÈvÇSµ») ∏ƒ…∆/◊ÓflmªØ(•’•£©`•…•–•√•Ø) Àòî‘O”ã/ôCƒ‹‘O”ã ∏flŒª∫œ≥…‘O”ãfl^≥à (•§•·©`•∏) 5 ? Hitachi, Ltd. 2022. All rights reserved. 3. Ó}≤ƒ£∫àRøs•¢•Î•¥•Í•∫•‡ LZMA ? —}Îj§ •¢•Î•¥•Í•∫•‡§ÿ§Œflm”√ ¬¿˝§»§∑§∆°¢àRøs•¢•Î•¥•Í•∫•‡ LZMA(Lempel-Ziv-Markov chain-Algorithm)§Ú»° §Í…œ§≤§Î°£ ? LZMA§œ°¢àRøs¬ §Œ∏fl§§ø…ƒÊàRøs•¢•Î•¥•Í•∫•‡°£ ¥«ï¯àRøs≤ø§»°¢•Ï•Û•∏•≥©`•¿§À§Ë§Î∑˚∫≈ªØ≤ø§´§È§ §Î°£ ? ¥«ï¯àRøs≤ø: ¢Ÿ»Î¡¶•«©`•ø§Ú•–•§•»¡–§»§∑§∆°∞¥«ï¯°±§Àµ«Âh ¢⁄°±¥«ï¯°±§Œƒ⁄»›§ÚÃΩÀ˜§∑°¢»Î¡¶•«©`•øƒ⁄§Œ÷ÿ—}§Ú≥È≥ˆ ? •Ï•Û•∏•≥©`•¿: ¢Ÿ•«©`•ø÷ÿ—}•—•ø©`•Û§Àª˘§≈§≠°¢0/1§Œ≥ˆ¨F¥_¬ §Ú”Ëúy ¢⁄”Ëúy§»§Œ≤Ó∑÷§Ú∑˚∫≈§À…˙≥… ? •œ©`•…ªØ§œ°¢¥«ï¯ÃΩÀ˜§Œ÷∆”˘§¨—}Îj§À§ §Î¥«ï¯àRøs≤ø§Œ ∑Ω§¨°¢¥_¬ ”ãÀ„§Œ∑¥èÕ§«ÑI¿Ì§«§≠§Î•Ï•Û•∏•≥©`•¿§Ë§ÍÎy A B C D A B C E »Î¡¶ •«©`•ø A B C D E àRøs •«©`•ø ¥«ï¯§Àµ«Âh 4Œƒ◊÷«∞§»3◊÷“ª÷¬ áÌA. ¥«ï¯àRøs≤ø§ŒÑ”◊˜¿˝ œ» ·· A B C D E àRøs •«©`•ø 4Œƒ◊÷«∞§»3◊÷“ª÷¬ 0 0 1 0 £± £± 1 0 ÷ÿ—}•—•ø©`•Û§Ú æ§π 0/1§Œ”õ∫≈¡–(÷–Èg•≥©`•…) áÌB. •Ï•Û•∏•≥©`•¿§ŒÑ”◊˜¿˝ œ»––§π§Î•”•√•»•—•ø©`•Û§«¥Œ§Œ1bit§Œ0/1§Œ ≥ˆ¨F¥_¬ §Ú”Ëúy ”Ëúy§»§Œ≤Ó∑÷§Ú ∑˚∫≈§À…˙≥… 4 5
- 4. 4 6 ? Hitachi, Ltd. 2022. All rights reserved. 4. ’nÓ}£∫∏flŒª∫œ≥…§Œ≥ı∆⁄‘á––◊¥õr ? LZMA§Œ•™©`•◊•Û•Ω©`•π(C—‘’Z)§Ú•Ÿ©`•π§À°¢∏flŒª∫œ≥…§Ú‘á–– ? ∫œ≥…§π§Î§≥§»§œ§«§≠§ø°£ ? –‘ƒ‹§œ°¢“ä∑e§Í§Œºs1/40(àRøsÑI¿ÌïrÈg40±∂)°£ ? •◊•Ì•’•°•§•Î•«©`•ø§Ë§Í“™“Ú∑÷Œˆ ? ◊Ó¥Û§Œ“™“Ú§œ°¢¥«ï¯àRøs≤ø§«°¢Œƒ◊÷¡–ó À˜§Œ§ø§·§Œ•œ•√•∑•Â•∆©`•÷•Î§Ú∏¸–¬§π§ÎπwÀ˘ ?£±•–•§•»§∫§ƒ•¢•Ø•ª•π§∑°¢∏¸–¬§∑§∆§§§ø°£ ? §Ω§ŒÀ˚§œ°¢¥«ï¯àRøs≤ø§»•Ï•Û•∏•≥©`•¿≤ø§¨÷¥Œ§Àåg––§µ§Ï§Îòã‘Ï°£ ?¥«ï¯àRøs≤ø§¨•Ï•Û•∏•≥©`•¿≤ø§ŒÑI¿ÌÕÍ¡À§Ú¥˝§ƒ°£ ? §fi§ø°¢¥«ï¯àRøs≤ø§ŒŒƒ◊÷¡–ó À˜◊‘ç‚£±Œƒ◊÷§∫§ƒ±»›^°£ Adder(int a, int b, int c) { c = a + b; } ∏flŒª∫œ≥… ∫œ≥…ΩYπ˚ ∏flŒª—‘’Z•Ω©`•π •◊•Ì•’•°•§•Î •«©`•ø ∏ƒ…∆/◊ÓflmªØ(•’•£©`•…•–•√•Ø) 7 ? Hitachi, Ltd. 2022. All rights reserved. 4. ’nÓ}£∫∏flŒª∫œ≥…§Œ≥ı∆⁄‘á––◊¥õr Adder(int a, int b, int c) { c = a + b; } ∏flŒª∫œ≥… ∫œ≥…ΩYπ˚ ∏flŒª—‘’Z•Ω©`•π •◊•Ì•’•°•§•Î •«©`•ø ∏ƒ…∆/◊ÓflmªØ(•’•£©`•…•–•√•Ø) ? LZMA§Œ•™©`•◊•Û•Ω©`•π(C—‘’Z)§Ú•Ÿ©`•π§À°¢∏flŒª∫œ≥…§Ú‘á–– ? ∫œ≥…§π§Î§≥§»§œ§«§≠§ø°£ ? –‘ƒ‹§œ°¢“ä∑e§Í§Œºs1/40(àRøsÑI¿ÌïrÈg40±∂)°£ ? •◊•Ì•’•°•§•Î•«©`•ø§Ë§Í“™“Ú∑÷Œˆ ? ◊Ó¥Û§Œ“™“Ú§œ°¢¥«ï¯àRøs≤ø§«°¢Œƒ◊÷¡–ó À˜§Œ§ø§·§Œ•œ•√•∑•Â•∆©`•÷•Î§Ú∏¸–¬§π§ÎπwÀ˘ ?£±•–•§•»§∫§ƒ•¢•Ø•ª•π§∑°¢∏¸–¬§∑§∆§§§ø°£ ¢Ÿ•·•‚•Í§Œ•¢•Ø•ª•π∑˘íà¥Û ? §Ω§ŒÀ˚§œ°¢¥«ï¯àRøs≤ø§»•Ï•Û•∏•≥©`•¿≤ø§¨÷¥Œ§Àåg––§µ§Ï§Îòã‘Ï°£ ?¥«ï¯àRøs≤ø§¨•Ï•Û•∏•≥©`•¿≤ø§ŒÑI¿ÌÕÍ¡À§Ú¥˝§ƒ°£ ¢⁄•«©`•ø•’•Ì©`ªØ ? §fi§ø°¢¥«ï¯àRøs≤ø§ŒŒƒ◊÷¡–ó À˜◊‘ç‚£±Œƒ◊÷§∫§ƒ±»›^°£ ¢€Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞ 6 7
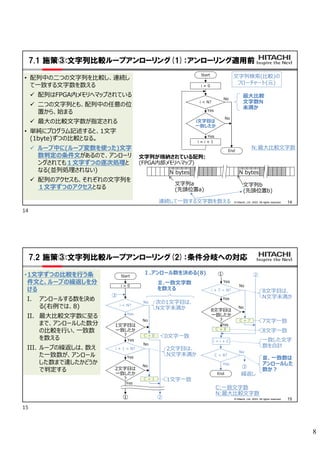
- 5. 5 8 ? Hitachi, Ltd. 2022. All rights reserved. 5.1 ©≤fl¢Ÿ:•·•‚•Í§Œ•¢•Ø•ª•π∑˘íà¥Û(1)£∫∏≈“™ •≥•‘©`‘™≈‰¡– •≥•‘©`œ»≈‰¡– •≥•‘©`‘™≈‰¡– •≥•‘©`œ»≈‰¡– Start i = 0 d[i] = s[i] i < N? End s[] d[] s[] d[] t[] i = i + 1 Start i = 0 t[0] = s[i] t[1] = s[i + 1] ... t[7] = s[i + 7] i < N? End i = i + 8 d[i] = t[0] d[i + 1] = t[1] ... d[i + 7] = t[7] No Yes No Yes ? ≈‰¡–§´§È≈‰¡–§À•«©`•ø§Ú•≥•‘©`§π§Î•±©`•π ? ≈‰¡–§œ°¢•≥•‘©`‘™?•≥•‘©`œ»§»§‚°¢FPGA§Œƒ⁄≤ø•·•‚•Í§À•fi•√•◊§π§Î•±©`•π ? ≈‰¡–§´§È≈‰¡–§ÿ÷±Ω”•≥•‘©`§π§Î”õ ˆ§‰°¢•Î©`•◊?•¢•Û•Ì©`•Í•Û•∞§¨§µ§Ï§ §§ àˆ∫œ§À°¢£±“™Àÿ§∫§ƒ§Œ÷¥Œ•≥•‘©`§À§ §Í“◊§§ ? Õæ÷–§À•Ï•∏•π•ø≈‰¡–§Ú÷√§≠°¢•Î©`•◊’πÈ_§π§Î§≥§»§«—} ˝“™ÀÿÕ¨ïr§À•≥•‘©` ? ≈‰¡–§´§È≈‰¡–§À•«©`•ø§Ú•≥•‘©`§π§Î•±©`•π ? ≈‰¡–§œ°¢•≥•‘©`‘™?•≥•‘©`œ»§»§‚°¢FPGA§Œƒ⁄≤ø•·•‚•Í§À•fi•√•◊§π§Î•±©`•π ? ≈‰¡–§´§È≈‰¡–§ÿ÷±Ω”•≥•‘©`§π§Î”õ ˆ§‰°¢•Î©`•◊?•¢•Û•Ì©`•Í•Û•∞§¨§µ§Ï§ §§ àˆ∫œ§À°¢£±“™Àÿ§∫§ƒ§Œ÷¥Œ•≥•‘©`§À§ §Í“◊§§ ? Õæ÷–§À•Ï•∏•π•ø≈‰¡–§Ú÷√§≠°¢•Î©`•◊’πÈ_§π§Î§≥§»§«—} ˝“™ÀÿÕ¨ïr§À•≥•‘©` •Ï•∏•π•ø≈‰¡– ? •Ï•∏•π•ø≈‰¡–§Ú ΩU”… ? •Î©`•◊? •¢•Û•Ì©`•Í•Û•∞ ? •Ï•∏•π•ø≈‰¡–§Ú ΩU”… ? •Î©`•◊? •¢•Û•Ì©`•Í•Û•∞ 1“™Àÿ§∫§ƒ•≥•‘©` —} ˝“™Àÿ Õ¨ïr•≥•‘©` (•≥•‘©`‘™/•≥•‘©`œ»≈‰¡–§»§‚FPGAƒ⁄≤ø •·•‚•Í§À•fi•√•◊) 9 ? Hitachi, Ltd. 2022. All rights reserved. 5.2 ©≤fl¢Ÿ:•·•‚•Í•¢•Ø•ª•π∑˘íà¥Û(2)£∫ •œ•√•∑•Â•∆©`•÷•Î∏¸–¬ ‘™§Œòã‘Ï Œƒ◊÷¡–(9Œƒ◊÷) Œª÷√ Œƒ◊÷¡–(9Œƒ◊÷) ¢Ÿœ»Ó^4Œƒ◊÷§« •œ•√•∑•ÂÇé”ãÀ„ Œª÷√ ¢⁄“ªΩM§∫§ƒ•∑•’•» ¢€œ»Ó^§À”õÂh œ» ·· •œ•√•∑•Â•∆©`•÷•Î »Î¡¶•«©`•ø (¥«ï¯) 16bit 8bit°¡9Œƒ◊÷ = 72bit Start ¢Ÿœ»Ó^4Œƒ◊÷§«•œ•√•∑•ÂÇé§Ú”ãÀ„ i = 7 i ®R1? •œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i].Œª÷√ =•œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i-1].Œª÷√ ¨F‘⁄Œª÷√ j = 0 •≥•‘©`œ»Œƒ◊÷¡–[j] = •≥•‘©`‘™Œƒ◊÷¡–[j] j = j +1 i = i - 1 j < 9? •œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][0].Œª÷√ =¨F‘⁄Œª÷√ 9Œƒ◊÷•≥•‘©`: •œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][0].Œƒ◊÷¡– = ¨F‘⁄Œª÷√§ŒŒƒ◊÷¡– 9Œƒ◊÷•≥•‘©`: •œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i].Œƒ◊÷¡– = •œ•√•∑•Â•∆©`•÷•Î[•œ•√•∑•ÂÇé][i-1].Œƒ◊÷¡– End 9Œƒ◊÷•≥•‘©` End ¢⁄“ªΩM§∫§ƒ•∑•’•» ¢€œ»Ó^§À”õÂh ? •œ•√•∑•Â•∆©`•÷•Î§À¥«ï¯ƒ⁄§ŒŒª÷√§»œ»Ó^§Œ 9Œƒ◊÷§∫§ƒ§¨µ«Âh§µ§Ï§∆§§§Î ? º»¥Êƒ⁄»›§Ú“∆Ñ”(•∑•’•»)§∑§ø…œ§«°¢»Î¡¶•«©` •ø§Œ¨F‘⁄Œª÷√§´§È§Œ9Œƒ◊÷§Ú–¬“鵫Âh ? •œ•√•∑•Â•∆©`•÷•Î§À¥«ï¯ƒ⁄§ŒŒª÷√§»œ»Ó^§Œ 9Œƒ◊÷§∫§ƒ§¨µ«Âh§µ§Ï§∆§§§Î ? º»¥Êƒ⁄»›§Ú“∆Ñ”(•∑•’•»)§∑§ø…œ§«°¢»Î¡¶•«©` •ø§Œ¨F‘⁄Œª÷√§´§È§Œ9Œƒ◊÷§Ú–¬“鵫Âh œ»Ó^§´§Èó ñÀ •œ•√•∑•Â•∆©`•÷•Î∏¸–¬ §Œ•’•Ì©`•¡•„©`•»(‘™) (•µ•÷•Î©`•¡•Û§«”õ›d) No Yes No Yes (16bit+72bit)°¡8(•∑•Œ•À•‡) = 704bit(88byte) ¥Û§≠§ •®•Û•»•Í§Ú 1Œƒ◊÷(•–•§•»)§∫§ƒ ÷¥Œ•¢•Ø•ª•π 8 9
- 6. 6 10 ? Hitachi, Ltd. 2022. All rights reserved. 5.3 ©≤fl¢Ÿ:•·•‚•Í•¢•Ø•ª•π∑˘íà¥Û(3)£∫•œ•√•∑•Â•∆©`•÷•Î∏¸–¬ ∏ƒ…∆≤fl ? •œ•√•∑•Â•∆©`•÷•Î§Ú°¢Œª÷√§Œ«ÈàÛ§Œ•∆©`•÷•Î§» Œƒ◊÷¡–§Œ•∆©`•÷•Î§À∑÷∏Ó ? •®•Û•»•Í(Œª÷√+Œƒ◊÷¡–8ΩM∑÷)§Ú•Ï•∏•π•ø§À §∫§È§∑§∆’i…œ§≤°¢ï¯§≠믧π ? •œ•√•∑•Â•∆©`•÷•Î§Ú°¢Œª÷√§Œ«ÈàÛ§Œ•∆©`•÷•Î§» Œƒ◊÷¡–§Œ•∆©`•÷•Î§À∑÷∏Ó ? •®•Û•»•Í(Œª÷√+Œƒ◊÷¡–8ΩM∑÷)§Ú•Ï•∏•π•ø§À §∫§È§∑§∆’i…œ§≤°¢ï¯§≠ë¯§π Œª÷√ 16bit Œª÷√ 16bit°¡8 = 128bit Œª÷√ 72bit°¡8 = 576bit ¢Ÿœ»Ó^4Œƒ◊÷§« •œ•√•∑•ÂÇé”ãÀ„ ¢⁄§∫§È§∑§∆’i§fl…œ§≤ ¢€œ»Ó^§À∏Òº{ œ» ·· •œ•√•∑•Â•∆©`•÷•Î (∑÷∏Ó··) »Î¡¶•«©`•ø (¥«ï¯) 16bit 8bit°¡9Œƒ◊÷ = 72bit ¨F‘⁄Œª÷√ œ»Ó^§´§Èó ñÀ Œƒ◊÷¡–(9Œƒ◊÷) •Ï•∏•π•ø ¢‹ï¯§≠믧∑ Start ¢Ÿœ»Ó^4Œƒ◊÷§«•œ•√•∑•ÂÇé§Ú”ãÀ„ i = 7 i ®R1? •Ï•∏•π•ø(Œª÷√)[i] =•œ•√•∑•Â•∆©`•÷•Î(Œª÷√)[•œ•√•∑•ÂÇé][i-1] i = i - 1 •Ï•∏•π•ø(Œª÷√)[0] = ¨F‘⁄Œª÷√ 9Œƒ◊÷•≥•‘©`(•◊•È•∞•fi§«•¢•Û•Ì©`•Í•Û•∞) •Ï•∏•π•ø(Œƒ◊÷¡–)[0]=¨F‘⁄Œª÷√§ŒŒƒ◊÷¡– 9Œƒ◊÷•≥•‘©`(•◊•È•∞•fi§«•¢•Û•Ì©`•Í•Û•∞) •Ï•∏•π•ø(Œƒ◊÷¡–)[i] = •œ•√•∑•Â•∆©`•÷•Î(Œƒ◊÷¡–)[•œ•√•∑•ÂÇé][i-1] End ¢⁄§∫§È§∑§∆’i§fl…œ§≤ ¢€œ»Ó^§À∏Òº{ •œ•√•∑•Â•∆©`•÷•Î∏¸–¬§Œ •’•Ì©`•¡•„©`•»(∏ƒ…∆∞Ê) Œª÷√°¢Œƒ◊÷¡–§Ú§Ω§Ï§æ§Ï ÅK¡–§À•¢•Ø•ª•π No Yes •œ•√•∑•Â•∆©`•÷•Î(Œª÷√)[•œ•√•∑•ÂÇé][0°´7] = •Ï•∏•π•ø(Œª÷√)[0°´7] 9Œƒ◊÷•≥•‘©`(•◊•È•∞•fi§«•¢•Û•Ì©`•Í•Û•∞)°¡8: •œ•√•∑•Â•∆©`•÷•Î(Œƒ◊÷¡–)[•œ•√•∑•ÂÇé][0°´7] = •Ï•∏•π•ø(Œƒ◊÷¡–)[0°´7] ¢‹ï¯§≠믧∑ ¢⁄ ¢‹ ¢€ 11 ? Hitachi, Ltd. 2022. All rights reserved. 6.1 ©≤fl¢⁄:•«©`•ø•’•Ì©`ªØ(1) •«©`•ø©`•’•Ì©`ªØflm”√«∞ ? ∂˛§ƒ§ŒÑI¿Ì§Ú∫¨§‡•Î©`•◊ ? §Ω§Ï§æ§Ï§ŒÑI¿Ì§ŒÈg§«°¢â‰ ˝§Ú”√§§§∆°¢“ª∑Ω§´§ÈÀ˚∑Ω§ÿ•«©`•ø§Ú ‹§±∂…§∑ ?§Ω§Ï§æ§Ï§Œªÿ¬∑§¨÷¥ŒÑ”◊˜§»§ §Î ? ∂˛§ƒ§ŒÑI¿Ì§Ú∫¨§‡•Î©`•◊ ? §Ω§Ï§æ§Ï§ŒÑI¿Ì§ŒÈg§«°¢â‰ ˝§Ú”√§§§∆°¢“ª∑Ω§´§ÈÀ˚∑Ω§ÿ•«©`•ø§Ú ‹§±∂…§∑ ?§Ω§Ï§æ§Ï§Œªÿ¬∑§¨÷¥ŒÑ”◊˜§»§ §Î Start ≥ı∆⁄ªØÑI¿Ì ÑI¿Ìa ΩK¡À≈–∂® ÑI¿Ìb End ΩK¡ÀÑI¿Ì ≠˝ ≠˝ ≠˝ ≥ı∆⁄ªØÑI¿Ì ªÿ¬∑ ÑI¿Ìa ªÿ¬∑ ÑI¿Ìb ªÿ¬∑ ≈–∂®ªÿ¬∑ ΩK¡ÀÑI¿Ì ªÿ¬∑ ≥ı∆⁄•«©`•ø ÷–Èg•«©`•ø ≥ˆ¡¶•«©`•ø ¿R∑µ§∑ –≈∫≈ ΩK¡À•«©`•ø ïrÈg›S T1 T2 T3 T4 T5 T6 T7 T8 ≥ı∆⁄ªØªÿ¬∑ Ñ”◊˜ ÑI¿Ìa ªÿ¬∑ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ ÑI¿Ìb ªÿ¬∑ Ñ”◊˜ Ñ”◊˜ ≈–∂®ªÿ¬∑ Ñ”◊˜ Ñ”◊˜ ΩK¡ÀÑI¿Ìªÿ¬∑ ÷¥ŒÑ”◊˜:3•µ•§•Ø•Î•‘•√•¡ ÑI¿Ì•’•Ì©`•¡•„©`•» ªÿ¬∑òã≥… 10 11
- 7. 7 12 ? Hitachi, Ltd. 2022. All rights reserved. 6.2 ©≤fl¢⁄:•«©`•ø•’•Ì©`ªØ(2) •«©`•ø•’•Ì©`ªØflm”√·· ? ∂˛§ƒ§ŒÑI¿Ì§Œ•Î©`•◊§Ú∑÷∏Ó ? ∑÷∏Ó§∑§ø•Î©`•◊§ŒÑI¿Ì§ŒÈg§«°¢FIFO(•π•»•Í©`•‡â‰ ˝)§Ú”√§§§∆•«©`•ø§Ú ‹§±∂…§∑ ?§Ω§Ï§æ§Ï§Œªÿ¬∑§ŒÅK¡–Ñ”◊˜§¨ø…ƒ‹§»§ §Î ? ∂˛§ƒ§ŒÑI¿Ì§Œ•Î©`•◊§Ú∑÷∏Ó ? ∑÷∏Ó§∑§ø•Î©`•◊§ŒÑI¿Ì§ŒÈg§«°¢FIFO(•π•»•Í©`•‡â‰ ˝)§Ú”√§§§∆•«©`•ø§Ú ‹§±∂…§∑ ?§Ω§Ï§æ§Ï§Œªÿ¬∑§ŒÅK¡–Ñ”◊˜§¨ø…ƒ‹§»§ §Î Start ≥ı∆⁄ªØÑI¿Ì ÑI¿Ìa ΩK¡À≈–∂®b ÑI¿Ìb End ΩK¡ÀÑI¿Ì ≠˝ ≠˝ ≥ı∆⁄ªØÑI¿Ì ªÿ¬∑ ÑI¿Ìa ªÿ¬∑ ÑI¿Ìb ªÿ¬∑ ≈–∂®bªÿ¬∑ ΩK¡ÀÑI¿Ì ªÿ¬∑ ≥ı∆⁄•«©`•ø ÷–Èg•«©`•ø ≥ˆ¡¶•«©`•ø ¿R∑µ§∑ –≈∫≈ ΩK¡À•«©`•ø ïrÈg›S T1 T2 T3 T4 T5 T6 T7 T8 ≥ı∆⁄ªØªÿ¬∑ Ñ”◊˜ ÑI¿Ìa ªÿ¬∑ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ ≈–∂®aªÿ¬∑ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ ÑI¿Ìb ªÿ¬∑ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ ≈–∂®bªÿ¬∑ Ñ”◊˜ Ñ”◊˜ ΩK¡ÀÑI¿Ìªÿ¬∑ ΩK¡À≈–∂®a ≈–∂®aªÿ¬∑ ÷–Èg•«©`•ø ÷–Èg•«©`•ø FIFO ¿R∑µ§∑ –≈∫≈ FIFO ÅK¡–(•™©`•–©`•È•√•◊)Ñ”◊˜: 2•µ•§•Ø•Î•‘•√•¡ 13 ? Hitachi, Ltd. 2022. All rights reserved. 6.3 ©≤fl¢⁄:•«©`•ø•’•Ì©`ªØ(3) LZMA§À§™§±§Îflm”√ ? ¥«ï¯àRøs≤ø§»°¢•Ï•Û•∏•≥©`•¿§Œ∫Ù§”≥ˆ§∑§Àflm”√ ?¥«ï¯àRøs≤ø§»°¢•Ï•Û•∏•≥©`•¿§ÚÅK¡–Ñ”◊˜§µ§ª°¢Ñ”◊˜ïrÈg§Ú§€§‹∞Îúp ? ¥«ï¯àRøs≤ø§»°¢•Ï•Û•∏•≥©`•¿§Œ∫Ù§”≥ˆ§∑§Àflm”√ ?¥«ï¯àRøs≤ø§»°¢•Ï•Û•∏•≥©`•¿§ÚÅK¡–Ñ”◊˜§µ§ª°¢Ñ”◊˜ïrÈg§Ú§€§‹∞Îúp Start ¥«ï¯àRøs≤ø ΩK¡À? •Ï•Û•∏•≥©`•¿ End Start ¥«ï¯àRøs≤ø ΩK¡À? •Ï•Û•∏•≥©`•¿ End ΩK¡À? No Yes No Yes ïrÈg›S T1 T2 T3 T4 T5 T6 ¥«ï¯àRøs≤ø Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ •Ï•Û•∏•≥©`•¿ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ ¥«ï¯àRøsªÿ¬∑ •Ï•Û•∏•≥©`•¿ªÿ¬∑ ÷–Èg•«©`•ø àRøs•«©`•ø ∆ΩŒƒ•«©`•ø ¿R∑µ§∑ –≈∫≈ No Yes ïrÈg›S T1 T2 T3 T4 T5 T6 ¥«ï¯àRøs≤ø Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ •Ï•Û•∏•≥©`•¿ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ Ñ”◊˜ FIFO ¥«ï¯àRøsªÿ¬∑ •Ï•Û•∏•≥©`•¿ªÿ¬∑ ÷–Èg•«©`•ø àRøs•«©`•ø ∆ΩŒƒ•«©`•ø FIFO ÷–Èg•«©`•ø 12 13
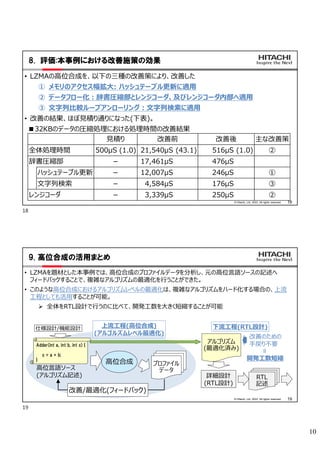
- 8. 8 14 ? Hitachi, Ltd. 2022. All rights reserved. 7.1 ©≤fl¢€:Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞(1)£∫•¢•Û•Ì©`•Í•Û•∞flm”√«∞ ? ≈‰¡–÷–§Œ∂˛§ƒ§ŒŒƒ◊÷¡–§Ú±»›^§∑°¢flBæA§∑ §∆“ª÷¬§π§ÎŒƒ◊÷ ˝§Ú ˝§®§Î ? ≈‰¡–§œFPGAƒ⁄•·•‚•Í§ÿ•fi•√•◊§µ§Ï§∆§§§Î ? ∂˛§ƒ§ŒŒƒ◊÷¡–§»§‚°¢≈‰¡–÷–§Œ»Œ“‚§ŒŒª ÷√§´§È°¢ º§fi§Î ? ◊Ó¥Û§Œ±»›^Œƒ◊÷ ˝§¨÷∏∂®§µ§Ï§Î ? ÖgºÉ§À•◊•Ì•∞•È•‡”õ ˆ§π§Î§»°¢1Œƒ◊÷ (1byte)§∫§ƒ§Œ±»›^§»§ §Î°£ ? •Î©`•◊÷–§À(•Î©`•◊≠˝§Ú π§√§ø)Œƒ◊÷ ˝≈–∂®§ŒÃıº˛Œƒ§¨§¢§Î§Œ§«°¢•¢•Û•Ì©`•Í •Û•∞§µ§Ï§∆§‚£±Œƒ◊÷§∫§ƒ§Œ÷¥ŒÑI¿Ì§» § §Î(ÅK¡–ÑI¿Ì§µ§Ï§ §§) ? ≈‰¡–§Œ•¢•Ø•ª•π§‚°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷¡–§Ú £±Œƒ◊÷§∫§ƒ§Œ•¢•Ø•ª•π§»§ §Î ? ≈‰¡–÷–§Œ∂˛§ƒ§ŒŒƒ◊÷¡–§Ú±»›^§∑°¢flBæA§∑ §∆“ª÷¬§π§ÎŒƒ◊÷ ˝§Ú ˝§®§Î ? ≈‰¡–§œFPGAƒ⁄•·•‚•Í§ÿ•fi•√•◊§µ§Ï§∆§§§Î ? ∂˛§ƒ§ŒŒƒ◊÷¡–§»§‚°¢≈‰¡–÷–§Œ»Œ“‚§ŒŒª ÷√§´§È°¢ º§fi§Î ? ◊Ó¥Û§Œ±»›^Œƒ◊÷ ˝§¨÷∏∂®§µ§Ï§Î ? ÖgºÉ§À•◊•Ì•∞•È•‡”õ ˆ§π§Î§»°¢1Œƒ◊÷ (1byte)§∫§ƒ§Œ±»›^§»§ §Î°£ ? •Î©`•◊÷–§À(•Î©`•◊≠˝§Ú π§√§ø)Œƒ◊÷ ˝≈–∂®§ŒÃıº˛Œƒ§¨§¢§Î§Œ§«°¢•¢•Û•Ì©`•Í •Û•∞§µ§Ï§∆§‚£±Œƒ◊÷§∫§ƒ§Œ÷¥ŒÑI¿Ì§» § §Î(ÅK¡–ÑI¿Ì§µ§Ï§ §§) ? ≈‰¡–§Œ•¢•Ø•ª•π§‚°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷¡–§Ú £±Œƒ◊÷§∫§ƒ§Œ•¢•Ø•ª•π§»§ §Î N bytes Œƒ◊÷¡–a (œ»Ó^Œª÷√a) Œƒ◊÷¡–b (œ»Ó^Œª÷√b) N bytes Œƒ◊÷¡–§¨∏Òº{§µ§Ï§∆§§§Î≈‰¡–: (FPGAƒ⁄≤ø•·•‚•Í§ÿ•fi•√•◊) Start i = 0 i < N? End i = i + 1 iŒƒ◊÷ƒø§œ “ª÷¬§∑§ø§´ No Yes No Yes N:◊Ó¥Û±»›^Œƒ◊÷ ˝ flBæA§∑§∆“ª÷¬§π§ÎŒƒ◊÷ ˝§Ú ˝§®§Î ◊Ó¥Û±»›^ Œƒ◊÷ ˝N Œ¥ú∫§´ Œƒ◊÷¡–ó À˜(±»›^)§Œ •’•Ì©`•¡•„©`•»(‘™) 15 ? Hitachi, Ltd. 2022. All rights reserved. 7.2 ©≤fl¢€:Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞(2)£∫Ãıº˛∑÷·™§ÿ§ŒåùèÍ ?1Œƒ◊÷§∫§ƒ§Œ±»›^§Ú––§¶Ãı º˛Œƒ§»°¢•Î©`•◊§Œ¿R∑µ§∑§Ú∑÷ §±§Î I. •¢•Û•Ì©`•Î§π§Î ˝§ÚõQ§· §Î(”“¿˝§«§œ°¢8) II. ◊Ó¥Û±»›^Œƒ◊÷ ˝§À÷¡§Î §fi§«°¢•¢•Û•Ì©`•Î§∑§ø ˝∑÷ §Œ±»›^§Ú––§§°¢“ª÷¬ ˝ §Ú ˝§®§Î III. •Î©`•◊§Œ¿R∑µ§∑§œ°¢ ˝§® §ø“ª÷¬ ˝§¨°¢•¢•Û•Ì©`•Î §∑§ø ˝§fi§«fl_§∑§ø§´§…§¶§´ §«≈–∂®§π§Î ?1Œƒ◊÷§∫§ƒ§Œ±»›^§Ú––§¶Ãı º˛Œƒ§»°¢•Î©`•◊§Œ¿R∑µ§∑§Ú∑÷ §±§Î I. •¢•Û•Ì©`•Î§π§Î ˝§ÚõQ§· §Î(”“¿˝§«§œ°¢8) II. ◊Ó¥Û±»›^Œƒ◊÷ ˝§À÷¡§Î §fi§«°¢•¢•Û•Ì©`•Î§∑§ø ˝∑÷ §Œ±»›^§Ú––§§°¢“ª÷¬ ˝ §Ú ˝§®§Î III. •Î©`•◊§Œ¿R∑µ§∑§œ°¢ ˝§® §ø“ª÷¬ ˝§¨°¢•¢•Û•Ì©`•Î §∑§ø ˝§fi§«fl_§∑§ø§´§…§¶§´ §«≈–∂®§π§Î Start i = 0 i < N? End 1Œƒ◊÷ƒø§œ “ª÷¬§∑§ø§´ ? No Yes No Yes ¥Œ§Œ1Œƒ◊÷ƒø§œ°¢ NŒƒ◊÷Œ¥ú∫§´ C = 0 i + 1 < N? 2Œƒ◊÷ƒø§œ “ª÷¬§∑§ø§´ ? No Yes No Yes C = 1 0Œƒ◊÷“ª÷¬ 2Œƒ◊÷ƒø§œ°¢ NŒƒ◊÷Œ¥ú∫§´ 1Œƒ◊÷“ª÷¬ Yes i + 7 < N? 8Œƒ◊÷ƒø§œ “ª÷¬§∑§ø§´ ? No Yes No Yes C = 7 8Œƒ◊÷ƒø§œ°¢ NŒƒ◊÷Œ¥ú∫§´ 7Œƒ◊÷“ª÷¬ C = 8 i = i + C C < 8? No Yes 8Œƒ◊÷“ª÷¬ “ª÷¬§∑§øŒƒ◊÷ ˝§Ú∫œ”ã ¢Ú.“ª÷¬Œƒ◊÷ ˝ §Ú ˝§®§Î ¢€ ¢€ ¢Ÿ ¢⁄ ¢Ÿ ¢⁄ ¿R∑µ§∑ ¢Û. “ª÷¬ ˝§œ •¢•Û•Ì©`•Î§∑§ø ˝§´? C:“ª÷¬Œƒ◊÷ ˝ N:◊Ó¥Û±»›^Œƒ◊÷ ˝ ¢Ò.•¢•Û•Ì©`•Î ˝§ÚõQ§·§Î(8) 14 15
- 9. 9 16 ? Hitachi, Ltd. 2022. All rights reserved. 7.3 ©≤fl¢€:Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞(3):≈‰¡–•¢•Ø•ª•π§ÿ§ŒåùèÍ ?•Ï•∏•π•ø≈‰¡–§Ú∂˛§ƒ π”√°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷¡–§Ú •Ï•∏•π•ø≈‰¡–§À“ªµ©∏Òº{§∑§∆±»›^ ? Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§Ú°¢•¢•Ø•ª•π∑˘(”“ ¿˝§«§œ•¢•Û•Ì©`•Î ˝§À∫œ§Ô§ª§ø8Byte)§ÚÖg Œª§»§π§Î∂˛¥Œ‘™≈‰¡–§»§π§Î ? •Ï•∏•π•ø≈‰¡–§œ°¢“ªªÿ§Œ≈‰¡–•¢•Ø•ª•π∑˘ (8)§Œ2±∂(16)§Œ“™Àÿ ˝§»§π§Î ? ±»›^§œ•Ï•∏•π•ø≈‰¡–…œ§«°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷ ¡–Œª÷√§´§È°¢“ªªÿ§À◊Ó¥Û•¢•Û•Ì©`•Î ˝∑÷ £Ω•¢•Ø•ª•π∑˘∑÷§ŒŒƒ◊÷ ˝(8)§Ú±»›^ ? ±»›^··°¢•Ï•∏•π•ø≈‰¡–§Œƒ⁄»›§Ú•∑•’•» 1. •Ï•∏•π•ø≈‰¡–§Œ··∞΃⁄»›§Ú«∞∞ΧÀ•≥•‘©` 2. Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§´§È•¢•Ø•ª•π∑˘ (8Byte)∑÷’i≥ˆ§∑°¢•Ï•∏•π•ø≈‰¡–§Œ·· ∞ΧÀ∏Òº{ ?•Ï•∏•π•ø≈‰¡–§Ú∂˛§ƒ π”√°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷¡–§Ú •Ï•∏•π•ø≈‰¡–§À“ªµ©∏Òº{§∑§∆±»›^ ? Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§Ú°¢•¢•Ø•ª•π∑˘(”“ ¿˝§«§œ•¢•Û•Ì©`•Î ˝§À∫œ§Ô§ª§ø8Byte)§ÚÖg Œª§»§π§Î∂˛¥Œ‘™≈‰¡–§»§π§Î ? •Ï•∏•π•ø≈‰¡–§œ°¢“ªªÿ§Œ≈‰¡–•¢•Ø•ª•π∑˘ (8)§Œ2±∂(16)§Œ“™Àÿ ˝§»§π§Î ? ±»›^§œ•Ï•∏•π•ø≈‰¡–…œ§«°¢§Ω§Ï§æ§Ï§ŒŒƒ◊÷ ¡–Œª÷√§´§È°¢“ªªÿ§À◊Ó¥Û•¢•Û•Ì©`•Î ˝∑÷ £Ω•¢•Ø•ª•π∑˘∑÷§ŒŒƒ◊÷ ˝(8)§Ú±»›^ ? ±»›^··°¢•Ï•∏•π•ø≈‰¡–§Œƒ⁄»›§Ú•∑•’•» 1. •Ï•∏•π•ø≈‰¡–§Œ··∞΃⁄»›§Ú«∞∞ΧÀ•≥•‘©` 2. Œƒ◊÷¡–§Ú∏Òº{§π§Î≈‰¡–§´§È•¢•Ø•ª•π∑˘ (8Byte)∑÷’i≥ˆ§∑°¢•Ï•∏•π•ø≈‰¡–§Œ·· ∞ΧÀ∏Òº{ 8bytes «∞∞Î ··∞Î •¢•Ø•ª•Î∑˘(8byte)ÖgŒª§À’i≥ˆ§∑°¢ •Ï•∏•π•ø≈‰¡–§Œ··∞ΧÀ∏Òº{ •Ï•∏•π•ø≈‰¡–a “ªªÿ§Œ±»›^åùœÛ (◊Ó¥Û8Œƒ◊÷) Œƒ◊÷¡–b (œ»Ó^Œª÷√b) Œƒ◊÷¡–a (œ»Ó^Œª÷√a) Œƒ◊÷¡–§¨∏Òº{§µ§Ï§∆§§§Î≈‰¡–: (2¥Œ‘™≈‰¡–§»§∑§∆°¢FPGAƒ⁄≤ø •·•‚•Í§ÿ•fi•√•◊) «∞∞Î ··∞Î •Ï•∏•π•ø≈‰¡–b ··∞Χ´§È «∞∞Χÿ •≥•‘©` ··∞Χ´§È «∞∞Χÿ •≥•‘©` N bytes N bytes “ªªÿµ±§ø§Í§Œ ’i≥ˆ§∑ÖgŒª “ªªÿµ±§ø§Í§Œ ’i≥ˆ§∑ÖgŒª 17 ? Hitachi, Ltd. 2022. All rights reserved. 7.4 ©≤fl¢€:Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞(4)£∫∏ƒ…∆·· 8bytes N bytes N bytes «∞∞Î ··∞Î •Ï•∏•π•ø≈‰¡–a “ªªÿ§Œ±»›^åùœÛ (◊Ó¥Û8Œƒ◊÷) Œƒ◊÷¡–b (œ»Ó^Œª÷√b) Œƒ◊÷¡–a (œ»Ó^Œª÷√a) Œƒ◊÷¡–§¨∏Òº{§µ§Ï§∆§§§Î≈‰¡–: «∞∞Î ··∞Î •Ï•∏•π•ø≈‰¡–b ? •Î©`•◊È_ º«∞§Œ≥ı∆⁄ªØ§«•Ï•∏•π•ø≈‰¡–§Œ◊Ó ≥ı§Œƒ⁄»›°¢Œƒ◊÷¡–±»›^Œª÷√§Úú lj ? ¿R∑µ§∑ïr§À•Ï•∏•π•ø≈‰¡–ƒ⁄»›§ÚÌò§À•∑•’•» ? •Î©`•◊È_ º«∞§Œ≥ı∆⁄ªØ§«•Ï•∏•π•ø≈‰¡–§Œ◊Ó ≥ı§Œƒ⁄»›°¢Œƒ◊÷¡–±»›^Œª÷√§Úú lj ? ¿R∑µ§∑ïr§À•Ï•∏•π•ø≈‰¡–ƒ⁄»›§ÚÌò§À•∑•’•» Start i < N? •Ï•∏•π•ø≈‰¡–a[x]= •Ï•∏•π•ø≈‰¡–b[y]? No Yes No Yes C = 0 ¢€ ¢Ÿ ¢⁄ •Ï•∏•π•ø≈‰¡–a[] °˚ Œƒ◊÷¡–a§Œœ»Ó^∫¨§‡8byte + ¥Œ§Œ8byte •Ï•∏•π•ø≈‰¡–b[] °˚ Œƒ◊÷¡–b§Œœ»Ó^∫¨§‡8byte + ¥Œ§Œ8byte x = Œƒ◊÷¡–a§ŒÈ_ ºŒª÷√(8§ŒÑ蔇) y = Œƒ◊÷¡–b§ŒÈ_ ºŒª÷√(8§ŒÑ蔇) i = 0 End Yes i + 7 < N? No Yes No Yes C = 7 C = 8 i = i + C C < 8? No Yes ¢€ ¢Ÿ ¢⁄ ¿R∑µ§∑ •Ï•∏•π•ø≈‰¡–a[x+7]= •Ï•∏•π•ø≈‰¡–b[y+7]? •Ï•∏•π•ø≈‰¡–a§Œƒ⁄»›•∑•’•» (≈‰¡–«∞∞ΰ˚≈‰¡–··∞ΰ¢ ≈‰¡–··∞ΰ˚Œƒ◊÷¡–a§Œ ¥Œ§Œ8byte) •Ï•∏•π•ø≈‰¡–b§Œƒ⁄»›•∑•’•» (≈‰¡–«∞∞ΰ˚≈‰¡–··∞ΰ¢ ≈‰¡–··∞ΰ˚Œƒ◊÷¡–b§Œ ¥Œ§Œ8byte) y x (Œƒ◊÷¡–a§ŒÈ_ º Œª÷√§Œ8§ŒÑ蔇) (Œƒ◊÷¡–b§ŒÈ_ º Œª÷√§Œ8§ŒÑ蔇) 16 17
- 10. 10 18 ? Hitachi, Ltd. 2022. All rights reserved. 8. ‘uÅ˝:±æ ¬¿˝§À§™§±§Î∏ƒ…∆ ©≤fl§ŒÑøπ˚ ? LZMA§Œ∏flŒª∫œ≥…§Ú°¢“‘œ¬§Œ»˝∑N§Œ∏ƒ…∆≤fl§À§Ë§Í°¢∏ƒ…∆§∑§ø ¢Ÿ •·•‚•Í§Œ•¢•Ø•ª•π∑˘íà¥Û: •œ•√•∑•Â•∆©`•÷•Î∏¸–¬§Àflm”√ ¢⁄ •«©`•ø•’•Ì©`ªØ:¥«ï¯àRøs≤ø§»•Ï•Û•∏•≥©`•¿°¢º∞§”•Ï•Û•∏•≥©`•¿ƒ⁄≤ø§ÿflm”√ ¢€ Œƒ◊÷¡–±»›^•Î©`•◊•¢•Û•Ì©`•Í•Û•∞:Œƒ◊÷¡–ó À˜§Àflm”√ ? ∏ƒ…∆§ŒΩYπ˚°¢§€§‹“ä∑e§ÍÕ®§Í§À§ §√§ø(œ¬±Ì)°£ “ä∑e§Í ∏ƒ…∆«∞ ∏ƒ…∆·· ÷˜§ ∏ƒ…∆≤fl »´ÃÂÑI¿ÌïrÈg 500¶ÃS (1.0) 21,540¶ÃS (43.1) 516¶ÃS (1.0) ¢⁄ ¥«ï¯àRøs≤ø £≠ 17,461¶ÃS 476¶ÃS •œ•√•∑•Â•∆©`•÷•Î∏¸–¬ £≠ 12,007¶ÃS 246¶ÃS ¢Ÿ Œƒ◊÷¡–ó À˜ £≠ 4,584¶ÃS 176¶ÃS ¢€ •Ï•Û•∏•≥©`•¿ £≠ 3,339¶ÃS 250¶ÃS ¢⁄ °ˆ32KB§Œ•«©`•ø§ŒàRøsÑI¿Ì§À§™§±§ÎÑI¿ÌïrÈg§Œ∏ƒ…∆ΩYπ˚ 19 ? Hitachi, Ltd. 2022. All rights reserved. 9. ∏flŒª∫œ≥…§ŒªÓ”√§fi§»§· ? LZMA§ÚÓ}≤ƒ§»§∑§ø±æ ¬¿˝§«§œ°¢∏flŒª∫œ≥…§Œ•◊•Ì•’•°•§•Î•«©`•ø§Ú∑÷Œˆ§∑°¢‘™§Œ∏flŒª—‘’Z•Ω©`•π§Œ”õ ˆ§ÿ •’•£©`•…•–•√•Ø§π§Î§≥§»§«°¢—}Îj§ •¢•Î•¥•Í•∫•‡§Œ◊ÓflmªØ§Ú––§¶§≥§»§¨§«§≠§ø°£ ? §≥§Œ§Ë§¶§ ∏flŒª∫œ≥…§À§™§±§Î•¢•Î•¥•Í•∫•‡•Ï•Ÿ•Î§Œ◊ÓflmªØ§œ°¢—}Îj§ •¢•Î•¥•Í•∫•‡§Ú•œ©`•…ªØ§π§Îàˆ∫œ§Œ°¢…œ¡˜ π§≥继∑§∆§‚ªÓ”√§π§Î§≥§»§¨ø…ƒ‹°£ ? »´Ã§ÚRTL‘O”㧫––§¶§Œ§À±»§Ÿ§∆°¢È_∞kπ§ ˝§Ú¥Û§≠§Ø∂Ãøs§π§Î§≥§»§¨ø…ƒ‹ Adder(int a, int b, int c) { c = a + b; } ∏flŒª∫œ≥… •◊•Ì•’•°•§•Î •«©`•ø ∏ƒ…∆/◊ÓflmªØ(•’•£©`•…•–•√•Ø) …œ¡˜π§≥Ã(∏flŒª∫œ≥…) (•¢•Î•¥•Î•∫•‡•Ï•Ÿ•Î◊ÓflmªØ) œ¬¡˜π§≥Ã(RTL‘O”ã) Àòî‘O”ã/ôCƒ‹‘O”ã ∏flŒª—‘’Z•Ω©`•π (•¢•Î•¥•Í•∫•‡”õ ˆ) ‘îºö‘O”ã (RTL‘O”ã) RTL ”õ ˆ •¢•Î•¥•Í•∫•‡ (◊ÓflmªØúg§fl) ∏ƒ…∆§Œ§ø§·§Œ ÷믧Í≤ª“™ È_∞kπ§ ˝∂Ãøs = 18 19
- 11. 11 ? Hitachi, Ltd. 2022. All rights reserved. 20 END —}Îj§ •¢•Î•¥•Í•∫•‡§Œ•œ©`•…ªØ§À§™§±§Î∏flŒª∫œ≥…§ŒªÓ”√ ¬¿˝ µ⁄9ªÿACRi•¶•ß•”• ©` 2022/7/26 ÷Í Ωª·…Á »’¡¢—u◊˜À˘ —–æøÈ_∞k•∞•Î©`•◊ •«•∏•ø•Î•◊•È•√•»•’•©©`•‡•§•Œ•Ÿ©`•∑•Á•Û•ª•Û•ø •«©`•ø•π•»•Ï©`•∏—–æø≤ø çuÃÔ Ω°Ã´¿… 20 21