





















































More Related Content
Similar to Concurrency Control for Parallel Machine Learning (20)
More from jeykottalam (8)






Recently uploaded (20)











![Windows 8.1 Pro Activator Crack Version [April-2025]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture9-250228130043-bd676d0e-250401141425-60508047-250401150607-9cd2b2bd-thumbnail.jpg?width=560&fit=bounds)


![Typing Master Pro 12 Crack Updated Version [April-2025]](https://cdn.slidesharecdn.com/ss_thumbnails/polymercompositesclassificationreinforcementsmatrices-250401143720-528f5cdb-250401145512-321e9880-thumbnail.jpg?width=560&fit=bounds)

![Bandicut Video Cutter v3.6.8.709 Crack [April-2025]](https://cdn.slidesharecdn.com/ss_thumbnails/dataanalysisforbusiness-250322061148-eeff8a831-250401123246-f36be9ca-250401130229-e0f40fd9-thumbnail.jpg?width=560&fit=bounds)



Concurrency Control for Parallel Machine Learning
- 1. Concurrency Control for Parallel Machine Learning Dimitris Papailiopoulos Xinghao Pan, Joseph Gonzalez, Stefanie Jegelka, Tamara Broderick, Dimitris Papailiopoulos, Joseph Bradley, Michael I. Jordan
- 2. Model State Data Serial Inference
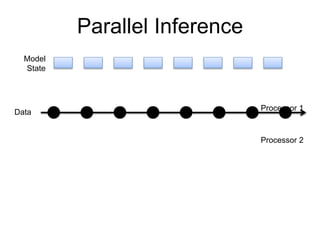
- 3. Model State Parallel Inference Processor 1 Processor 2 Data
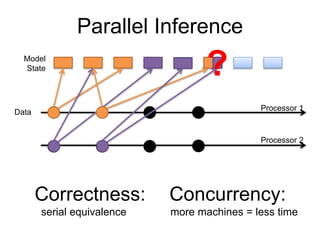
- 4. Model State Data Parallel Inference Processor 1 Processor 2 Concurrency: more machines = less time Correctness: serial equivalence ?
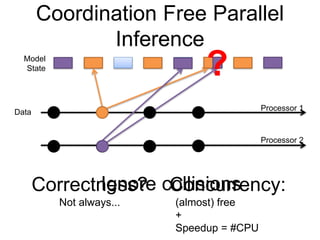
- 5. Model State Data Coordination Free Parallel Inference Processor 1 Processor 2 ? Ignore collisions Concurrency: (almost) free + Speedup = #CPU Correctness? Not always...
- 6. Correctness Serial Low High
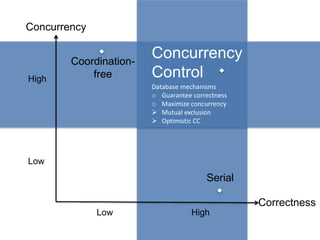
- 7. Correctness Concurrency Coordination-free Serial High Low High Low
- 8. Correctness Concurrency Coordination-free Serial High Low High Low Concurrency Control Database mechanisms o Guarantee correctness o Maximize concurrency ? Mutual exclusion ? Optimistic CC
- 9. Model State Data Mutual Exclusion Through Locking Processor 1 Processor 2 Introduce locking (scheduling) protocols to prevent conflicts.
- 10. Mutual Exclusion Through Model State Data Processor 1 Processor 2 Locking ? Enforce local serialization to avoid conflicts.
- 11. Optimistic Concurrency Control Model State Data Processor 1 Processor 2 Allow computation to proceed without blocking. Kung & Robinson. On optimistic methods for concurrency control.
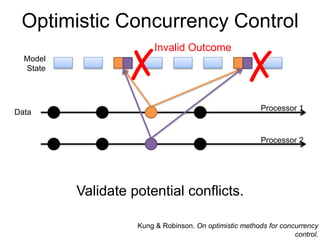
- 12. Optimistic Concurrency Control Model State Data Invalid Outcome ? ? Processor 1 Processor 2 Validate potential conflicts. Kung & Robinson. On optimistic methods for concurrency control.
- 13. Optimistic Concurrency Control Model State Data ? ? Processor 1 Processor 2 Rollback and Redo Take a compensating action. Kung & Robinson. On optimistic methods for concurrency control.
- 14. Concurrency Control 14 Coordination Free: Provably fast and correct under key assumptions. Concurrency Control: Provably correct and fast under key assumptions. Systems Ideas to Improve Efficiency
- 15. Machine Learning + Concurrency Clusteri ng Online Facility Location Control (Xinghao Pan et al.) Submodular Maximization Subset selection, diminishing marginal gains Max Graph Cut Set Cover Sensor Placement Social Network Influence Propagation Document Summarization Sports Football Word Series Giants Cardinals Politics Midterm Obama Democrat Tea Finance QE market interest Dow Topic Modelling Correlation Clustering Deduplication Community Detection
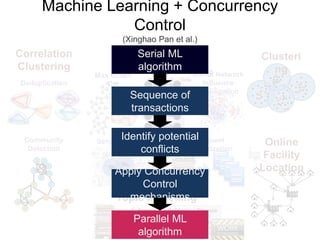
- 16. Machine Learning + Concurrency Clusteri ng Online Facility Location Control (Xinghao Pan et al.) Submodular Maximization Subset selection, diminishing marginal gains Max Graph Cut Set Cover Sensor Placement Social Network Influence Propagation Document Summarization Sports Football Word Series Giants Cardinals Politics Midterm Obama Democrat Tea Finance QE market interest Dow Topic Modelling Correlation Clustering Deduplication Community Detection Serial ML algorithm Sequence of transactions Identify potential conflicts Apply Concurrency Control mechanisms Parallel ML algorithm
- 17. Application: Deduplication Computer Science Division ¨C University of California Berkeley CA University of California at Berkeley Department of Physics Stanford University California Lawrence Berkeley National Labs <ref>California</ref>
- 19. Serial Correlation Clustering Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Journal of the ACM (JACM), 55(5):23, 2008. Serially process vertices
- 20. Serial Correlation Clustering Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Journal of the ACM (JACM), 55(5):23, 2008. Serially process vertices
- 21. Serial Correlation Clustering Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Journal of the ACM (JACM), 55(5):23, 2008. Serially process vertices
- 22. Serial Correlation Clustering Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Journal of the ACM (JACM), 55(5):23, 2008. Serially process vertices
- 23. Serial Correlation Clustering Nir Ailon, Moses Charikar, and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Journal of the ACM (JACM), 55(5):23, 2008. Serially process vertices Approximation 3 OPT (in expectation)
- 25. Concurrency Control Correlation Clustering (C4) Parallel Correlation Clustering Cannot Resolve introduce by Mutual adjacent Exclusion cluster centers
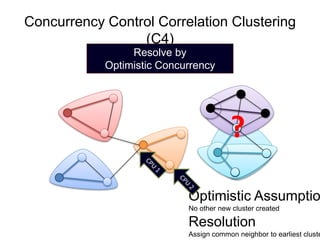
- 26. Concurrency Control Correlation Clustering (C4) Common Resolve neighbor by must be assigned Optimistic to Concurrency earliest center Control ? Optimistic Assumption No other new cluster created Resolution Assign common neighbor to earliest cluster
- 27. Properties of C4 (Concurrency Control Correlation Clustering) Theorem: C4 is correct. C4 preserves same guarantees as serial algorithm (3 OPT). Concurren Correctness Theorem: C4 has provably small overheads. cy = almost linear speedup Expected #blocked transactions < 2¦Ó |E| / |V|. ¦Ó ˇÔ diff in parallel cpuˇŻs progress
- 28. Empirical Validation on Billion Edge Graphs Amazon EC2 r3.8xlarge instances Multicore up to 16 threads Real and synthetic graphs 100 runs (10 random orderings x 10 runs) Graph Vertices Edges IT-2004 Italian web-graph 41 Million 1.14 Billion Webbase-2001 WebBase crawl 118 Million 1.02 Billion Erdos-Renyi Synthetic random 100 Million ˇÖ 1.0 Billion
- 29. C4: Cost of Coordination < 0.02% blocked
- 30. C4: Speed-up Ideal 10x speedu p
- 31. Conclusion Concurrency Control for Parallel ML o Guarantee correctness o Maximize concurrency Code release in the works! https://amplab.cs.berkeley.edu/projects/cc ml/ xinghao@berkeley.edu Applications Correlation Clustering Submodular Maximization Clustering Online Facility Location Feature Modeling