Talks on my machine: Drupal: AI e Typesense come integrare la ricerca semantica
0 likes15 views

Il documento esplora come integrare la ricerca semantica in Drupal utilizzando Typesense, evidenziando le differenze tra ricerca tradizionale e semantica. Viene descritta l'importanza del retrieval-augmented generation (RAG) e il funzionamento dei database vettoriali per migliorare l'esperienza di ricerca. Infine, si presenta il modulo Search API Typesense per configurare la ricerca all'interno di Drupal.

















![29
Con’¼ügurazione dei campi
Ō×ö Search API Typesense de’¼ünisce un set di
nuovi tipi di campo, ├© obbligatorio utilizzarli
quando si indicizzano i dati su Typesense
Ō×ö I tipi di campo supportati da Typesense sono:
ŌŚå string
ŌŚå string[]
ŌŚå int32
ŌŚå int32[]
ŌŚå int64
ŌŚå int64[]
ŌŚå ’¼éoat
ŌŚå ’¼éoat[]
ŌŚå bool
ŌŚå bool[]](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-29-320.jpg)

![Ō×ö Gli Embeds vengono generati utilizzando un LLM (sia
localmente che con un provider remoto, come
OpenAI)
Ō×ö Gli Embeds vengono salvati in un campo ’¼éoat[]
denominato embedding
Ō×ö Il contenuto dei campi embedding viene
concatenato insieme e poi suddiviso in blocchi detti
chunks
Ō×ö ├ł possibile con’¼ügurare la dimensione dei chunks e la
sovrapposizione tra chunks consecutivi
Abilitare la ricerca Semantica
31](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-31-320.jpg)
![Ricerca Semantica
curl 'http://localhost:8108/multi_search'
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}"
-X POST
-d '{
"searches": [
{
"q": "device to type things on",
"query_by": "embedding",
"collection": "products",
"prefix": "false",
"exclude_fields": "embedding",
"per_page": 1
}
]
}'
32
Ō×ö Typesense generer├Ā lŌĆÖembedding
per la chiave di ricerca e
utilizzer├Ā la similarit├Ā del coseno
per trovare documenti simili
Ō×ö Di solito vogliamo escludere il
campo di embedding dai risultati
perch├® ├© solo un enorme vettore
di numeri ’¼éoat](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-32-320.jpg)


![Ō×ö Il team di Typesense ha
sviluppato un adattatore per
rendere le chiamate API di
instantsearch compatibili con il
server Typesense
Ō×ö Con Instantsearch, un client
(esempio un browser) comunica
direttamente con Typesense,
senza Drupal nel mezzo
Ō×ö Importante: la chiave API deve
essere una che consenta solo
l'azione documents:search sulle
collections desiderate
instantsearch.js
import instantsearch from "instantsearch.js";
import { searchBox, hits } from "instantsearch.js/es/widgets";
import TypesenseInstantSearchAdapter from "typesense-instantsearch-adapter";
const typesenseInstantsearchAdapter = new TypesenseInstantSearchAdapter({
server: {
apiKey: "S6Af42wX9HmxF5Ar36ajNNawNywAYwGr",
nodes: [
{
host: "search-api-typesense.ddev.site",
port: "8108",
protocol: "https",
},
],
},
additionalSearchParameters: {
query_by: "body",
},
});
const searchClient = typesenseInstantsearchAdapter.searchClient;
37](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-37-320.jpg)

![LLPhant
foreach ($attachments as $attachment) {
$file = $this->getPdfFileEntity
(
$field_storage
,
$attachment['target_id'],
);
if ($file === NULL) {
continue;
}
$reader = new FileDataReader(
DRUPAL_ROOT . $file->createFileUrl()
);
$documents = EmbeddingFormatter::formatEmbeddings(
$reader->getDocuments()
);
}
42
https://github.com/theodo-group/LLPhant
Ō×ö FileDataReader, ci aiuta a
leggere il contenuto da ’¼üle .pdf,
.docx e di testo.
Ō×ö EmbeddingFormatter, ti
consente di aggiungere
informazioni preziose
nell'intestazione (come ad
esempio l'autore del documento,
la data del documento, ecc.)](https://image.slidesharecdn.com/tomm2024-aietypesensecomeintegrarelaricercasemanticaindrupal-241122090702-37d0d65f/85/Talks-on-my-machine-Drupal-AI-e-Typesense-come-integrare-la-ricerca-semantica-42-320.jpg)


Talks on my machine: Drupal: AI e Typesense come integrare la ricerca semantica
- 1. AI e Typesense Come integrare la ricerca semantica in Drupal 1
- 2. About me Drupal / PHP developer @ SparkFabrik Drupal contributor (Search API Typesense, Iubenda Integration, DDEV sqlsrv add-on) Drupal.org: https://www.drupal.org/u/robertoperuzzo LinkedIn: www.linkedin.com/in/robertoperuzzo Slack (drupal.slack.com): robertoperuzzo Mastodon: @robertoperuzzo@mastodon.social @robertoperuzzo
- 3. 3 Agenda 1. Ricerca Tradizionale vs. Ricerca Semantica 2. Introduzione a Retrieval-Augmented Generation (RAG) 3. Perch├® Typesense? 4. Il modulo Drupal Search API Typesense
- 4. Ricerca tradizionale 4 La ricerca tradizionale recupera rapidamente corrispondenze esatte per parole chiave, concentrandosi su efficienza e velocit├Ā per fornire risultati precisi facendo corrispondere direttamente i termini nei dati.
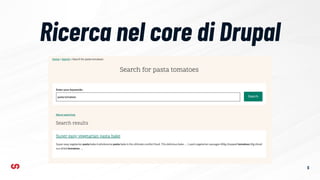
- 5. Ricerca nel core di Drupal 5
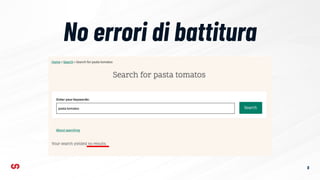
- 6. No errori di battitura 6
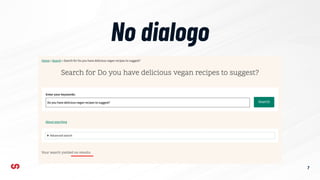
- 7. No dialogo 7
- 8. Ricerca Semantica 8 La ricerca semantica utilizza l'AI per interpretare l'intento e il contesto della query, fornendo risultati basati sul signi’¼ücato piuttosto che sulle parole chiave esatte.
- 9. 9
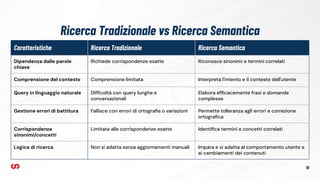
- 10. 10 Caratteristiche Ricerca Tradizionale Ricerca Semantica Dipendenza dalle parole chiave Richiede corrispondenze esatte Riconosce sinonimi e termini correlati Comprensione del contesto Comprensione limitata Interpreta l'intento e il contesto dell'utente Query in linguaggio naturale Dif’¼ücolt├Ā con query lunghe e conversazionali Elabora ef’¼ücacemente frasi e domande complesse Gestione errori di battitura Fallisce con errori di ortogra’¼üa o variazioni Permette tolleranza agli errori e correzione ortogra’¼üca Corrispondenza sinonimi/concetti Limitata alle corrispondenze esatte Identi’¼üca termini e concetti correlati Logica di ricerca Non si adatta senza aggiornamenti manuali Impara e si adatta al comportamento utente e ai cambiamenti dei contenuti Ricerca Tradizionale vs Ricerca Semantica
- 11. Alcune applicazioni pratiche 11 Ō×ö Ricerca e raccomandazioni prodotti Ō×ö Ricerca documenti Ō×ö Chatbot per supporto clienti Ō×ö Personalizzazione dei risultati
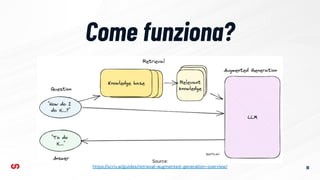
- 13. RAG ├© il processo di ottimizzazione dell'output di un modello linguistico di grandi dimensioni, in modo che faccia riferimento a una base di conoscenza autorevole al di fuori delle sue fonti di dati di addestramento prima di generare una risposta. 13 Source: https://aws.amazon.com/it/what-is/retrieval-augmented-generation/
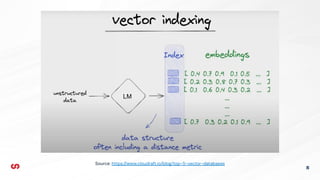
- 14. Vector Databases 14 Ō×ö Memorizzano il signi’¼ücato semantico del testo Ō×ö Cattura astratta non solo di 3 dimensioni, ma migliaia: es. emozione, sentimento, tono, dimensione, ecc. Ō×ö Suddivisione in ŌĆ£chunksŌĆØ per catturare signi’¼ücati ancora pi├╣ speci’¼üci
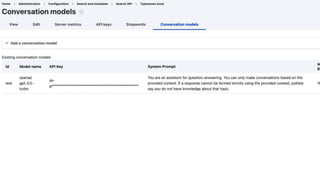
- 17. 17 Cosa serve? Ō×ö Contenuti per la ŌĆ£Base di conoscenzaŌĆØ Ō×ö Vector database Ō×ö LLM
- 18. Typesense 18 Open Source Alternative to Algolia + Pinecone
- 19. 19 ŌĆ£Il nostro obiettivo ├© ridurre il time-to-market per creare un'esperienza eccezionale di ricerca istantanea che fornisca risultati pertinenti ’¼ün da subito.ŌĆØ Source: https://typesense.org/docs/overview/why-typesense.html
- 20. 20 "Abbiamo anche fornito valori prede’¼üniti sensati per ogni parametro di con’¼ügurazione, in modo che il motore funzioni immediatamente per la maggior parte dei casi d'uso. Questo ├© ci├▓ che intendiamo con 'batterie incluse'." Source: https://typesense.org/docs/overview/why-typesense.html
- 22. 22 C++ +20k stelle su Github Self-hosted o SaaS Semplice da impostare
- 23. Ō×ö La versione corrente ├© v27.1 Ō×ö Una nuova release ogni 2-3 mesi Roadmap pubblica https://github.com/orgs/typesense/projects/1/views/1 23
- 24. Esistono integrazioni per molte piattaforme 24 Source: https://typesense.org Tristemente manca Drupal quiŌĆ”
- 25. Search API Typesense ThereŌĆÖs a module for thatŌäó https://www.drupal.org/project/search_api_typesense 25
- 26. Try Typesense on DDEV 26 https://github.com/kevinquillen/ddev-typesense
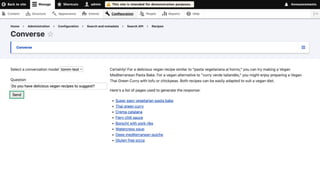
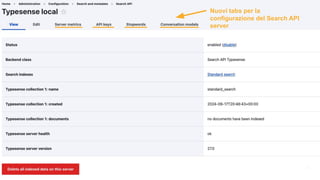
- 27. Ō×ö La chiave API di amministrazione viene impostata all'avvio del server Typesense Ō×ö Typesense ├© distribuito, qui puoi impostare tutti i nodi disponibili Ō×ö Il nodo pi├╣ vicino ├© quello per sfruttare Search Delivery Network in Typesense Cloud Ō×ö La con’¼ügurazione mostrata ├© quella per connettersi a un server Typesense gestito da DDEV 27 Connettiti al server
- 28. 28 Nuovi tabs per la configurazione del Search API server
- 29. 29 Con’¼ügurazione dei campi Ō×ö Search API Typesense de’¼ünisce un set di nuovi tipi di campo, ├© obbligatorio utilizzarli quando si indicizzano i dati su Typesense Ō×ö I tipi di campo supportati da Typesense sono: ŌŚå string ŌŚå string[] ŌŚå int32 ŌŚå int32[] ŌŚå int64 ŌŚå int64[] ŌŚå ’¼éoat ŌŚå ’¼éoat[] ŌŚå bool ŌŚå bool[]
- 30. 30 Ō×ö Per ogni campo aggiunto alla Search API dobbiamo con’¼ügurare come verr├Ā esposto a Typesense Ō×ö Una collection verr├Ā creata nel server Typesense solo al salvataggio dello schema Con’¼ügurazione dello schema
- 31. Ō×ö Gli Embeds vengono generati utilizzando un LLM (sia localmente che con un provider remoto, come OpenAI) Ō×ö Gli Embeds vengono salvati in un campo ’¼éoat[] denominato embedding Ō×ö Il contenuto dei campi embedding viene concatenato insieme e poi suddiviso in blocchi detti chunks Ō×ö ├ł possibile con’¼ügurare la dimensione dei chunks e la sovrapposizione tra chunks consecutivi Abilitare la ricerca Semantica 31
- 32. Ricerca Semantica curl 'http://localhost:8108/multi_search' -H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" -X POST -d '{ "searches": [ { "q": "device to type things on", "query_by": "embedding", "collection": "products", "prefix": "false", "exclude_fields": "embedding", "per_page": 1 } ] }' 32 Ō×ö Typesense generer├Ā lŌĆÖembedding per la chiave di ricerca e utilizzer├Ā la similarit├Ā del coseno per trovare documenti simili Ō×ö Di solito vogliamo escludere il campo di embedding dai risultati perch├® ├© solo un enorme vettore di numeri ’¼éoat
- 33. 33
- 34. 34
- 35. search_api_typesense module doesnŌĆÖt have an integration with ViewsŌĆ” ŌĆ”and probably never will. 35 Source: https://typesense.org/docs/overview/why-typesense.html
- 36. 36 InstantSearch.js ├© una libreria UI open source per Vanilla JS che consente di creare un'interfaccia di ricerca nella tua app frontend Source: https://www.algolia.com/doc/guides/building-search-ui/widgets/showcase/js/
- 37. Ō×ö Il team di Typesense ha sviluppato un adattatore per rendere le chiamate API di instantsearch compatibili con il server Typesense Ō×ö Con Instantsearch, un client (esempio un browser) comunica direttamente con Typesense, senza Drupal nel mezzo Ō×ö Importante: la chiave API deve essere una che consenta solo l'azione documents:search sulle collections desiderate instantsearch.js import instantsearch from "instantsearch.js"; import { searchBox, hits } from "instantsearch.js/es/widgets"; import TypesenseInstantSearchAdapter from "typesense-instantsearch-adapter"; const typesenseInstantsearchAdapter = new TypesenseInstantSearchAdapter({ server: { apiKey: "S6Af42wX9HmxF5Ar36ajNNawNywAYwGr", nodes: [ { host: "search-api-typesense.ddev.site", port: "8108", protocol: "https", }, ], }, additionalSearchParameters: { query_by: "body", }, }); const searchClient = typesenseInstantsearchAdapter.searchClient; 37
- 41. 41
- 42. LLPhant foreach ($attachments as $attachment) { $file = $this->getPdfFileEntity ( $field_storage , $attachment['target_id'], ); if ($file === NULL) { continue; } $reader = new FileDataReader( DRUPAL_ROOT . $file->createFileUrl() ); $documents = EmbeddingFormatter::formatEmbeddings( $reader->getDocuments() ); } 42 https://github.com/theodo-group/LLPhant Ō×ö FileDataReader, ci aiuta a leggere il contenuto da ’¼üle .pdf, .docx e di testo. Ō×ö EmbeddingFormatter, ti consente di aggiungere informazioni preziose nell'intestazione (come ad esempio l'autore del documento, la data del documento, ecc.)
- 44. With Cohere re-ranking 44 Image Embeddings
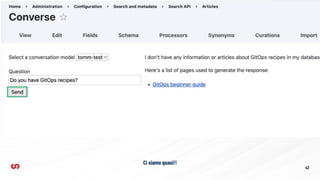
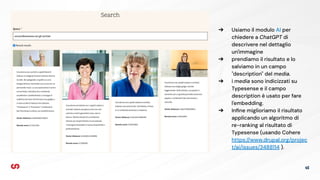
- 45. 45 Ō×ö Usiamo il modulo AI per chiedere a ChatGPT di descrivere nel dettaglio un'immagine Ō×ö prendiamo il risultato e lo salviamo in un campo "description" del media. Ō×ö i media sono indicizzati su Typesense e il campo description ├© usato per fare l'embedding. Ō×ö In’¼üne miglioriamo il risultato applicando un algoritmo di re-ranking al risultato di Typesense (usando Cohere https://www.drupal.org/projec t/ai/issues/3488114 ).
- 46. GRAZIE E CIAO!