贬补诲辞辞辫を用いた大规模ログ解析
37 likes8,091 views

this document is for #tokyowebmining held at 2011/04/10






















贬补诲辞辞辫を用いた大规模ログ解析
- 1. Analysis of Big Data via Hadoop 2011/04/10 #TokyoWebmining s_iida
- 2. Agenda ? About me ? What’s Hadoop ? Data 形式 ? Data 収集 ? Data 集計 ? 最後に 2
- 3. About me ? DataMining部@DeNA – アフィリエイト広告 – データ解析 / ログ解析のための基盤作りなど ? 過去:数学で Ph.D. – 複素微分幾何学、Topology – ポスドク一年 (PD: 学術振興会研究員) ? 趣味:数学?ヨット?将棋 ? @s_iida 3
- 4. はじめに いかにして膨大な情報(アクセスログ)を 有効活用するか? 4
- 5. Solution ? 大規模データ分析基盤 – Hadoop, etc.. ? 大規模データマイニング – R, Mahout, etc.. 今日は前者についてのお話 5
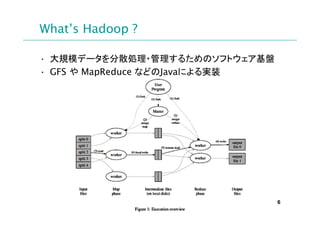
- 6. What’s Hadoop ? ? 大規模データを分散処理?管理するためのソフトウェア基盤 ? GFS や MapReduce などのJavaによる実装 6
- 7. 分析に必要なデータ
- 8. Case: 例えば… Casebook という架空SNSがあったとします… 写真投稿?日記投稿?コメント? 主要機能 友達申請?「まじで!」ボタン, etc.. 名前?性別?年齢?自己紹介文 開示情報 友達数?恋人有無, etc.. 8
- 9. いわゆる行動ログ ユーザが何か「action」する毎に吐かれるログ uid time Action Type hoge 100001 2011-03-01 20:30:11 comment **** 100031 2011-03-01 20:30:14 Post diary **** 100091 2011-03-01 20:30:16 Offer friend **** 100202 2011-03-01 20:30:17 Majide button **** ? どのユーザが何時、何をしたか、を記録. 9
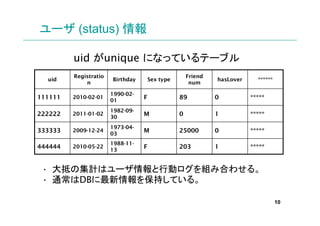
- 10. ユーザ (status) 情報 uid がunique になっているテーブル Registratio Friend uid Birthday Sex type hasLover * n num 1990-02- 111111 2010-02-01 01 F 89 0 1982-09- 222222 2011-01-02 30 M 0 1 1973-04- 333333 2009-12-24 03 M 25000 0 1988-11- 444444 2010-05-22 13 F 203 1 ? 大抵の集計はユーザ情報と行動ログを組み合わせる。 ? 通常はDBに最新情報を保持している。 10
- 11. 例(集計軸) ? 男女別コメント数 ? 年齢セグメント別写真投稿数 →行動ログと現在のステータス情報をuidでjoinして集計 ? 今月?先月の友達100人以上の人のコメント投稿数 ? 「恋人がいない→いる」変化時の写真投稿数変化 →過去のステータス情報を復元した上で集計する必要がある。 How ? 11
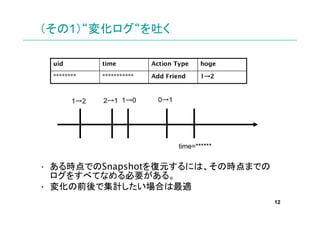
- 12. (その1)“変化ログ“を吐く uid time Action Type hoge *** * Add Friend → 1→2 1→2 2→1 1→0 0→1 time=* ? ある時点でのSnapshotを復元するには、その時点までの ログをすべてなめる必要がある。 ? 変化の前後で集計したい場合は最適 12
- 13. (その2) 非正規化 uid time Action Type Sex type age 1000222 * comment F 23 1022939 * comment M 35 ? joinしたい行動ログにあらかじめ追加しておく。 ? あらゆるステータス情報を追加するのは”無理”があるの で、必要なものを吟味して追加。 13
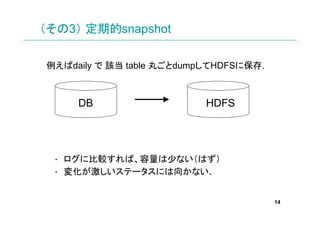
- 14. (その3) 定期的snapshot 例えばdaily で 該当 table 丸ごとdumpしてHDFSに保存. DB HDFS ? ログに比較すれば、容量は少ない(はず) ? 変化が激しいステータスには向かない. 14
- 15. ログをいかにして収集するか?
- 16. 何故ログ収集? ? Webサーバは複数。ログも分散している。 – 一箇所に集めないと集計出来ない(出来る場合もある) ? 集めるなんて scp するだけじゃん! – ログが膨大だと、ネットワークへの負荷などに気を使う。 いかにしてログを一箇所に 安全に いかにしてログを一箇所に「安全に」集めるか? ログ めるか 16
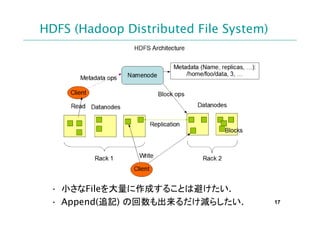
- 17. HDFS (Hadoop Distributed File System) ? 小さなFileを大量に作成することは避けたい. ? Append(追記) の回数も出来るだけ減らしたい. 17
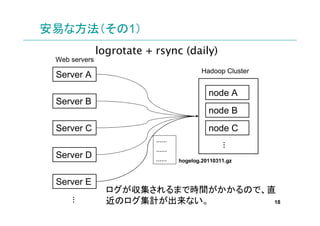
- 18. 安易な方法(その1) logrotate + rsync (daily) Web servers Hadoop Cluster Server A node A Server B node B Server C node C …… … …… Server D …… hogelog.20110311.gz Server E ログが収集されるまで時間がかかるので、直 近のログ集計が出来ない。 … 18
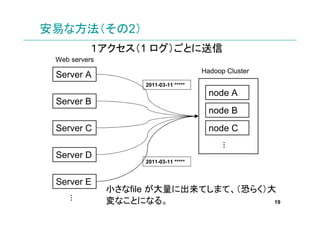
- 19. 安易な方法(その2) 1アクセス(1 ログ)ごとに送信 Web servers Hadoop Cluster Server A 2011-03-11 node A Server B node B Server C node C … Server D 2011-03-11 Server E 小さなfile が大量に出来てしまて、(恐らく)大 … 変なことになる。 19
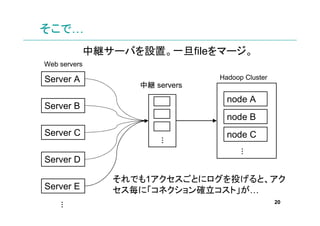
- 20. そこで… 中継サーバを設置。一旦fileをマージ。 Web servers Server A Hadoop Cluster 中継 servers node A Server B node B Server C node C … … Server D それでも1アクセスごとにログを投げると、アク Server E セス毎に「コネクション確立コスト」が… 20 …
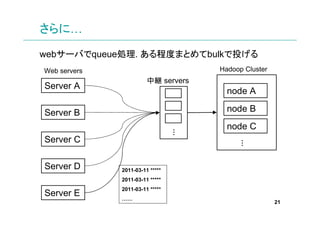
- 21. さらに… webサーバでqueue処理. ある程度まとめてbulkで投げる Web servers Hadoop Cluster 中継 servers Server A node A Server B node B node C … Server C … Server D 2011-03-11 2011-03-11 2011-03-11 Server E …… 21
- 22. まとめ(ログ収集) ? HDFSは小さなFileが“苦手”なので、ログを収集す る過程で何度かに分けてマージする. ? 各webサーバで、中継サーバで、HDFS上で… 22
- 23. いかにしてログを集計するか? いかにしてログを集計するか? ログ するか
- 24. ログ集計 ? ログが小さければ集計なんてナントでもなる。 – awk, perl, shell script, Excel…お好きなように。 ? いかにして膨大な量のログを集計するか? MapReduce Pig, Hive… 24
- 25. Apache Pig ? MapReduceを行うためのDSL. ? 手続き型言語. ? JavaでMapReduceを実装するのに比較すれば遥 かに効率的. ? 対話的操作も可能 (Pig Latin). ? UDF (user-defined function) を自由に作成可能. 25
- 26. Pig script の例 2011-04-01の男女/年齢別UU/PV Reducerの数を の 指定出来る 指定出来る 26
- 27. 【あるある その1】 HDFS上にある大量のログのフォーマット変換 ほぼ同時に大量の「変換後ログ」が書き出されるが… ? HDFSにおける 書き出しは必然的にネットワークの負荷を伴う (replication 数が1より大きい場合) ? 小分けにして変換するなど場合によっては工夫が必要。 27
- 28. 【あるある その2】 一ヶ月分のログの日付分割. 大量の size 0のファイルが生成されてしまう(何故でしょう ? ) ? MultipleOutputFormat を使ったほうが良い。 ? IF (SIZE(A)) STORE A; みたいな書き方が出来れば良いが …。 28
- 29. 最後に ? 集計するところまでが、ある意味スタート地点。 ? 集計結果から何を読み取るか、どう利用するか (data mining) が重要。 ? どのような分析をしたいか、そのためにどのような集 計が必要か、そのためにどのようなログが必要か、 と逆算することが大事。 ? 「とりあえず適当なフォーマットでログを吐く」は止め ましょう。 29
- 30. Thanks !!
- 31. Question ?