



贬产补蝉别性能测试文档
- 1. 文档名称:HBase benchmark HBase benchmark -1-
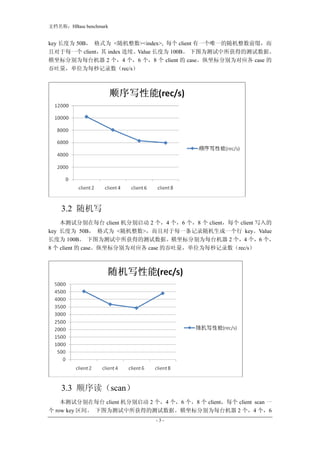
- 2. 文档名称:HBase benchmark 1. 测试目的 本测试的目的是确定 hbase 各项性能指标,包括随机读写,顺序读写的性能。 由于本版本 hdfs(cdh3b2)引入了 sync 的功能,并且默认情况下会对 meta/root region 每条记录 sync 一次,以保证 meta/root region 在其所在机器 down 机情况下的数 据安全,其带来的开销就是写入性能的下降,因此在测试中我们还会对比 hbase 的顺 序导入性能。 2. 环境 2.1 软硬件 Hbase 集群规模为 12 台机器,其中 1 台 HMaster,11 台 region server,物理内存 48G, 处在同一机房 测试用 client 为 5 台机器 ,物理内存为 16G Hbase:hbase 0.20.6,hadoop:cdh3b2 (对比测试中老基线指 hbase 0.20.4 + hadoop 0.20.2, 新基线指 hbase 0.20.6, hadoop: cdh3b2) 功能上包括多线程 compaction,sync 功能的支持 日志级别:regionserver 为 INFO 2.3 表结构 5 个 column family,每个 column family 有 5 个 qualifier 2.4 写入的数据 KeyLen : 50 B , ValueLen: 100 B 2.5 配置参数的修改 dfs.replication = 2 hbase.regions.nobalancing.count = 10 hbase.client.scanner.caching = 100 hbase.regionserver.hlog.splitlog.reader.threads = 10 hbase.regionserver.hlog.splitlog.writer.threads = 20 3. 测试方法 3.1 顺序写 本测试分别在每台 client 机分别启动 2 个,4 个,6 个,8 个 client,每个 client 写入的 -2-
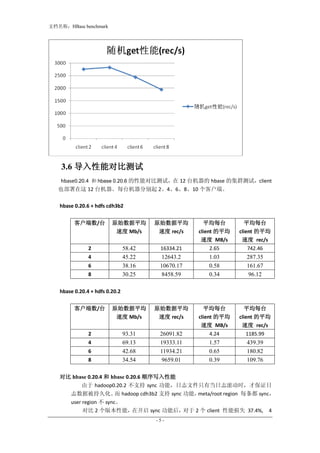
- 3. 文档名称:HBase benchmark key 长度为 50B, 格式为 <随机整数><index>, 每个 client 有一个唯一的随机整数前缀,而 且对于每一个 client, index 连续。 其 Value 长度为 100B。 下图为测试中所获得的测试数据。 横坐标分别为每台机器 2 个,4 个,6 个,8 个 client 的 case。纵坐标分别为对应各 case 的 吞吐量,单位为每秒记录数(rec/s) 3.2 随机写 本测试分别在每台 client 机分别启动 2 个,4 个,6 个,8 个 client,每个 client 写入的 key 长度为 50B, 格式为 <随机整数>,而且对于每一条记录随机生成一个行 key。Value 长度为 100B。 下图为测试中所获得的测试数据。横坐标分别为每台机器 2 个,4 个,6 个, 8 个 client 的 case。纵坐标分别为对应各 case 的吞吐量,单位为每秒记录数(rec/s) 3.3 顺序读(scan) 本测试分别在每台 client 机分别启动 2 个,4 个,6 个,8 个 client,每个 client scan 一 个 row key 区间。 下图为测试中所获得的测试数据。横坐标分别为每台机器 2 个,4 个,6 -3-
- 4. 文档名称:HBase benchmark 个,8 个 client 的 case。纵坐标分别为对应各 case 的吞吐量,单位为每秒记录数(rec/s) 3.4 顺序读(get) 本测试分别在每台 client 机分别启动 2 个,4 个,6 个,8 个 client,每个 client scan 一个 row key 区间,获取一个 row key 样本,然后顺序的 get 每一个 key 并统计性能。 下图为测 试中所获得的测试数据。横坐标分别为每台机器 2 个,4 个,6 个,8 个 client 的 case。纵坐 标分别为对应各 case 的吞吐量,单位为每秒记录数(rec/s) 3.5 随机读 本测试分别在每台 client 机分别启动 2 个,4 个,6 个,8 个 client,每个 client scan 一个 row key 区间,获取一个 row key 样本,然后随机的 get 每一个 key 并统计性能。 下图为测 试中所获得的测试数据。横坐标分别为每台机器 2 个,4 个,6 个,8 个 client 的 case。纵坐 标分别为对应各 case 的吞吐量,单位为每秒记录数(rec/s) -4-
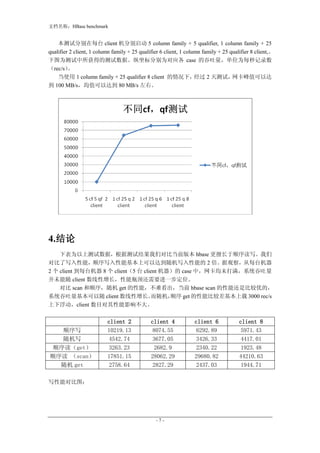
- 5. 文档名称:HBase benchmark 3.6 导入性能对比测试 hbase0.20.4 和 hbase 0.20.6 的性能对比测试,在 12 台机器的 hbase 的集群测试,client 也部署在这 12 台机器。每台机器分别起 2、4、6、8、10 个客户端。 hbase 0.20.6 + hdfs cdh3b2 客户端数/台 原始数据平均 原始数据平均 平均每台 平均每台 速度 Mb/s 速度 rec/s client 的平均 client 的平均 速度 MB/s 速度 rec/s 2 58.42 16334.21 2.65 742.46 4 45.22 12643.2 1.03 287.35 6 38.16 10670.17 0.58 161.67 8 30.25 8458.59 0.34 96.12 hbase 0.20.4 + hdfs 0.20.2 客户端数/台 原始数据平均 原始数据平均 平均每台 平均每台 速度 Mb/s 速度 rec/s client 的平均 client 的平均 速度 MB/s 速度 rec/s 2 93.31 26091.82 4.24 1185.99 4 69.13 19333.11 1.57 439.39 6 42.68 11934.21 0.65 180.82 8 34.54 9659.01 0.39 109.76 对比 hbase 0.20.4 和 hbase 0.20.6 顺序写入性能 由于 hadoop0.20.2 不支持 sync 功能,日志文件只有当日志滚动时,才保证日 志数据被持久化。 hadoop cdh3b2 支持 sync 功能, 而 meta/root region 每条都 sync, user region 不 sync。 对比 2 个版本性能, 在开启 sync 功能后,对于 2 个 client 性能损失 37.4%, 4 -5-
- 6. 文档名称:HBase benchmark 个 client 性能损失 34.6%, 6 个 client 性能损失 10.59 %, 8 个 client 性能损失 12.43%。 使用 hbase0.20.6 + hadoop cdh3b2 最高时可以保证 58.42 MB/s 的原始数据导 入。据推算,每小时能够导入原始数据 205.38 G。 对比 2 个版本,以上几项分别为每台机器 2 client,4 client, 6 client,8 client 的性 能。纵坐标为整个集群的吞吐量(rec/s) 此外, 当前 HBase 中对于 user region 提供不同安全级别, wal 打开的情况下, region 当 user 每 hbase.regionserver.flushlogentries ( 默 认 为 100 ) 条 记 录 sync 一 次 , 每 hbase.regionserver.optionallogflushinterval (默认 10 s),将未 sync 的记录 sync 到 hdfs。 因此,我们针对 hbase.regionserver.flushlogentries 的条目进行了对比测试。我们选择了 12 台 client 机,每台机器 6 个 client 进行顺序导入测试。hbase.regionserver.flushlogentries 分 别选择 100,1000, 10000 以及关闭 user region sync 功能。性能指标如下: 测试 sync 的性能,以上几项分别为 user region 每 100 条,每 1000 条,每 10000 条,以及 user region 不写日志的性能。纵坐标为整个集群的吞吐量(rec/s) 3.7 不同 column family 和 qualifier 的情况下对比测试 -6-
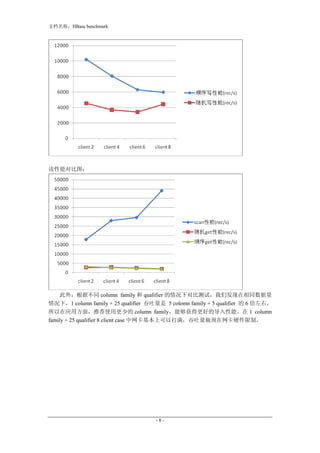
- 7. 文档名称:HBase benchmark 本测试分别在每台 client 机分别启动 5 column family + 5 qualifier, 1 column family + 25 qualifier 2 client, 1 column family + 25 qualifier 6 client, 1 column family + 25 qualifier 8 client,。 下图为测试中所获得的测试数据。纵坐标分别为对应各 case 的吞吐量,单位为每秒记录数 (rec/s) 。 当使用 1 column family + 25 qualifier 8 client 的情况下, 经过 2 天测试, 网卡峰值可以达 到 100 MB/s,均值可以达到 80 MB/s 左右。 4.结论 下表为以上测试数据,根据测试结果我们对比当前版本 hbase 更擅长于顺序读写。我们 对比了写入性能,顺序写入性能基本上可以达到随机写入性能的 2 倍。据观察,从每台机器 2 个 client 到每台机器 8 个 client(5 台 client 机器)的 case 中,网卡均未打满,系统吞吐量 并未能随 client 数线性增长,性能瓶颈还需要进一步定位。 对比 scan 和顺序,随机 get 的性能,不难看出,当前 hbase scan 的性能还是比较优的, 系统吞吐量基本可以随 client 数线性增长。 而随机, 顺序 get 的性能比较差基本上载 3000 rec/s 上下浮动,client 数目对其性能影响不大。 client 2 client 4 client 6 client 8 顺序写 10219.13 8074.55 6292.89 5971.43 随机写 4542.74 3677.05 3426.33 4417.01 顺序读(get) 3263.23 2682.9 2340.22 1923.48 顺序读 (scan) 17851.15 28062.29 29680.82 44210.63 随机 get 2758.64 2827.29 2437.03 1944.71 写性能对比图: -7-
- 8. 文档名称:HBase benchmark 读性能对比图: 此外,根据不同 column family 和 qualifier 的情况下对比测试,我们发现在相同数据量 情况下,1 column family + 25 qualifier 吞吐量是 5 colomn family + 5 qualifier 的 6 倍左右, 所以在应用方面,推荐使用更少的 column family,能够获得更好的导入性能。在 1 column family + 25 qualifier 8 client case 中网卡基本上可以打满,吞吐量瓶颈在网卡硬件限制。 -8-