ICML2015ÕiĪßŧáĢšOptimal and Adaptive Algorithms for Online Boosting
Download as PPTX, PDF6 likes3,632 views
hoge
1 of 13
Downloaded 20 times







Recommended
ICPC Asia::Tokyo 2014
Problem J ĻC Exhibition
ICPC Asia::Tokyo 2014
Problem J ĻC Exhibitionirrrrr
?
This document summarizes a solution to Problem J from the ICPC Asia::Tokyo 2014 competition. The problem involves minimizing the cost of choosing products for an exhibition by considering the costs with and without choosing a specific product 1. The objective function can be computed in O(n5logn) time by considering combinations of points in XYZ-space and finding the minimum on the convex hull. For fixed parameters, the objective function can also be minimized by considering all combinations and sorting. The overall minimizer is found by trying all edges of the feasible domain cube [0,1]3.ICPC 2015, Tsukuba
: Unofficial Commentary
ICPC 2015, Tsukuba
: Unofficial Commentaryirrrrr
?
The document summarizes solutions to problems from an ICPC competition. It discusses solutions to 8 problems:
1. Problem B on squeezing cylinders can be solved in O(N2) time by moving cylinders from left to right using Pythagorean theorem.
2. Problem C on sibling rivalry can be solved in O(n3) time using matrix multiplication to track reachable vertices, and iterating to minimize/maximize number of turns.
3. Problem D on wall clocks can be solved greedily in O(n2) time by sorting interval positions and placing clocks at rightmost positions.
4. Problem K on the min-max distance game can be solved by binary searching the distance t and
ICPC Asia::Tokyo 2014
Problem K ĻC LĄÞ Jumps
ICPC Asia::Tokyo 2014
Problem K ĻC LĄÞ Jumpsirrrrr
?
The document discusses solving the LĄÞ Jumps problem, which involves assigning jump vectors between base vectors representing points to minimize the maximum distance traveled. It proposes sorting the base vectors clockwise, fixing the number of jump vectors in each direction, and using a greedy algorithm to assign jump vectors. The overall complexity is O(n5) due to considering all combinations of jump vector directions and offsets for the greedy assignment.

Testing Forest-Isomorphism
in the Adjacency List Model
Testing Forest-Isomorphism
in the Adjacency List Modelirrrrr
?
The document discusses testing forest isomorphism in the adjacency list model. It proposes a partitioning oracle that removes small fractions of edges to partition graphs into parts with good properties, like bounded degree trees. It then checks if each corresponding part in the two forests is isomorphic or far. This reduces the problem to poly(log n) queries by testing individual parts. The approach provides a general technique for testing any graph property on forests in poly(log n) queries. A lower bound of Ķļ(ĄĖlog n) queries is also shown.
2024 Trend Updates: What Really Works In SEO & Content Marketing
2024 Trend Updates: What Really Works In SEO & Content MarketingSearch Engine Journal
?
The future of SEO is trending toward a more human-first and user-centric approach, powered by AI intelligence and collaboration. Are you ready?
Watch as we explore which SEO trends to prioritize to achieve sustainable growth and deliver reliable results. WeĄŊll dive into best practices to adapt your strategy around industry-wide disruptions like SGE, how to navigate the top challenges SEO professionals are facing, and proven tactics for prioritizing quality and building trust.
YouĄŊll hear:
- The top SEO trends to prioritize in 2024 to achieve long-term success.
- Predictions for SGEĄŊs impact, and how to adapt.
- What E-E-A-T really means, and how to implement it holistically (hint: itĄŊs never been more important).
With Zack Kadish and Alex Carchietta, weĄŊll show you which SEO trends to ignore and which to focus on, along with the solution to overcoming rapid, significant and disruptive Google algorithm updates.
If youĄŊre looking to cut through the noise of constant SEO and content trends to drive success, you wonĄŊt want to miss this webinar.
Storytelling For The Web: Integrate Storytelling in your Design Process
Storytelling For The Web: Integrate Storytelling in your Design ProcessChiara Aliotta
?
In this slides I explain how I have used storytelling techniques to elevate websites and brands and create memorable user experiences. You can discover practical tips as I showcase the elements of good storytelling and its applied to some examples of diverse brands/projects..Artificial Intelligence, Data and Competition ĻC SCHREPEL ĻC June 2024 OECD dis...
Artificial Intelligence, Data and Competition ĻC SCHREPEL ĻC June 2024 OECD dis...OECD Directorate for Financial and Enterprise Affairs
?
This presentation by Thibault Schrepel, Associate Professor of Law at Vrije Universiteit Amsterdam University, was made during the discussion Ą°Artificial Intelligence, Data and CompetitionĄą held at the 143rd meeting of the OECD Competition Committee on 12 June 2024. More papers and presentations on the topic can be found at oe.cd/aicomp.
This presentation was uploaded with the authorĄŊs consent.
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...SocialHRCamp
?
Speaker: Lydia Di Francesco
In this workshop, participants will delve into the realm of AI and its profound potential to revolutionize employee wellness initiatives. From stress management to fostering work-life harmony, AI offers a myriad of innovative tools and strategies that can significantly enhance the wellbeing of employees in any organization. Attendees will learn how to effectively leverage AI technologies to cultivate a healthier, happier, and more productive workforce. Whether it's utilizing AI-powered chatbots for mental health support, implementing data analytics to identify internal, systemic risk factors, or deploying personalized wellness apps, this workshop will equip participants with actionable insights and best practices to harness the power of AI for boosting employee wellness. Join us and discover how AI can be a strategic partner towards a culture of wellbeing and resilience in the workplace.2024 State of Marketing Report ĻC by Hubspot
2024 State of Marketing Report ĻC by HubspotMarius Sescu
?
https://www.hubspot.com/state-of-marketing
ĄĪ Scaling relationships and proving ROI
ĄĪ Social media is the place for search, sales, and service
ĄĪ Authentic influencer partnerships fuel brand growth
ĄĪ The strongest connections happen via call, click, chat, and camera.
ĄĪ Time saved with AI leads to more creative work
ĄĪ Seeking: A single source of truth
ĄĪ TLDR; Get on social, try AI, and align your systems.
ĄĪ More human marketing, powered by robotsEverything You Need To Know About ChatGPT
Everything You Need To Know About ChatGPTExpeed Software
?
ChatGPT is a revolutionary addition to the world since its introduction in 2022. A big shift in the sector of information gathering and processing happened because of this chatbot. What is the story of ChatGPT? How is the bot responding to prompts and generating contents? Swipe through these slides prepared by Expeed Software, a web development company regarding the development and technical intricacies of ChatGPT!Product Design Trends in 2024 | Teenage Engineerings
Product Design Trends in 2024 | Teenage EngineeringsPixeldarts
?
The realm of product design is a constantly changing environment where technology and style intersect. Every year introduces fresh challenges and exciting trends that mold the future of this captivating art form. In this piece, we delve into the significant trends set to influence the look and functionality of product design in the year 2024.How Race, Age and Gender Shape Attitudes Towards Mental Health
How Race, Age and Gender Shape Attitudes Towards Mental HealthThinkNow
?
Mental health has been in the news quite a bit lately. Dozens of U.S. states are currently suing Meta for contributing to the youth mental health crisis by inserting addictive features into their products, while the U.S. Surgeon General is touring the nation to bring awareness to the growing epidemic of loneliness and isolation. The country has endured periods of low national morale, such as in the 1970s when high inflation and the energy crisis worsened public sentiment following the Vietnam War. The current mood, however, feels different. Gallup recently reported that national mental health is at an all-time low, with few bright spots to lift spirits.
To better understand how Americans are feeling and their attitudes towards mental health in general, ThinkNow conducted a nationally representative quantitative survey of 1,500 respondents and found some interesting differences among ethnic, age and gender groups.
Technology
For example, 52% agree that technology and social media have a negative impact on mental health, but when broken out by race, 61% of Whites felt technology had a negative effect, and only 48% of Hispanics thought it did.
While technology has helped us keep in touch with friends and family in faraway places, it appears to have degraded our ability to connect in person. Staying connected online is a double-edged sword since the same news feed that brings us pictures of the grandkids and fluffy kittens also feeds us news about the wars in Israel and Ukraine, the dysfunction in Washington, the latest mass shooting and the climate crisis.
Hispanics may have a built-in defense against the isolation technology breeds, owing to their large, multigenerational households, strong social support systems, and tendency to use social media to stay connected with relatives abroad.
Age and Gender
When asked how individuals rate their mental health, men rate it higher than women by 11 percentage points, and Baby Boomers rank it highest at 83%, saying itĄŊs good or excellent vs. 57% of Gen Z saying the same.
Gen Z spends the most amount of time on social media, so the notion that social media negatively affects mental health appears to be correlated. Unfortunately, Gen Z is also the generation thatĄŊs least comfortable discussing mental health concerns with healthcare professionals. Only 40% of them state theyĄŊre comfortable discussing their issues with a professional compared to 60% of Millennials and 65% of Boomers.
Race Affects Attitudes
As seen in previous research conducted by ThinkNow, Asian Americans lag other groups when it comes to awareness of mental health issues. Twenty-four percent of Asian Americans believe that having a mental health issue is a sign of weakness compared to the 16% average for all groups. Asians are also considerably less likely to be aware of mental health services in their communities (42% vs. 55%) and most likely to seek out information on social media (51% vs. 35%).AI Trends in Creative Operations 2024 by Artwork Flow.pdf
AI Trends in Creative Operations 2024 by Artwork Flow.pdfmarketingartwork
?
Creative operations teams expect increased AI use in 2024. Currently, over half of tasks are not AI-enabled, but this is expected to decrease in the coming year. ChatGPT is the most popular AI tool currently. Business leaders are more actively exploring AI benefits than individual contributors. Most respondents do not believe AI will impact workforce size in 2024. However, some inhibitions still exist around AI accuracy and lack of understanding. Creatives primarily want to use AI to save time on mundane tasks and boost productivity.Skeleton Culture Code
Skeleton Culture CodeSkeleton Technologies
?
Organizational culture includes values, norms, systems, symbols, language, assumptions, beliefs, and habits that influence employee behaviors and how people interpret those behaviors. It is important because culture can help or hinder a company's success. Some key aspects of Netflix's culture that help it achieve results include hiring smartly so every position has stars, focusing on attitude over just aptitude, and having a strict policy against peacocks, whiners, and jerks.PEPSICO Presentation to CAGNY Conference Feb 2024
PEPSICO Presentation to CAGNY Conference Feb 2024Neil Kimberley
?
PepsiCo provided a safe harbor statement noting that any forward-looking statements are based on currently available information and are subject to risks and uncertainties. It also provided information on non-GAAP measures and directing readers to its website for disclosure and reconciliation. The document then discussed PepsiCo's business overview, including that it is a global beverage and convenient food company with iconic brands, $91 billion in net revenue in 2023, and nearly $14 billion in core operating profit. It operates through a divisional structure with a focus on local consumers.Content Methodology: A Best Practices Report (Webinar)
Content Methodology: A Best Practices Report (Webinar)contently
?
This document provides an overview of content methodology best practices. It defines content methodology as establishing objectives, KPIs, and a culture of continuous learning and iteration. An effective methodology focuses on connecting with audiences, creating optimal content, and optimizing processes. It also discusses why a methodology is needed due to the competitive landscape, proliferation of channels, and opportunities for improvement. Components of an effective methodology include defining objectives and KPIs, audience analysis, identifying opportunities, and evaluating resources. The document concludes with recommendations around creating a content plan, testing and optimizing content over 90 days.How to Prepare For a Successful Job Search for 2024
How to Prepare For a Successful Job Search for 2024Albert Qian
?
The document provides guidance on preparing a job search for 2024. It discusses the state of the job market, focusing on growth in AI and healthcare but also continued layoffs. It recommends figuring out what you want to do by researching interests and skills, then conducting informational interviews. The job search should involve building a personal brand on LinkedIn, actively applying to jobs, tailoring resumes and interviews, maintaining job hunting as a habit, and continuing self-improvement. Once hired, the document advises setting new goals and keeping skills and networking active in case of future opportunities.Social Media Marketing Trends 2024 // The Global Indie Insights
Social Media Marketing Trends 2024 // The Global Indie InsightsKurio // The Social Media Age(ncy)
?
A report by thenetworkone and Kurio.
The contributing experts and agencies are (in an alphabetical order): Sylwia Rytel, Social Media Supervisor, 180heartbeats + JUNG v MATT (PL), Sharlene Jenner, Vice President - Director of Engagement Strategy, Abelson Taylor (USA), Alex Casanovas, Digital Director, Atrevia (ES), Dora Beilin, Senior Social Strategist, Barrett Hoffher (USA), Min Seo, Campaign Director, Brand New Agency (KR), DeshĻĶ M. Gully, Associate Strategist, Day One Agency (USA), Francesca Trevisan, Strategist, Different (IT), Trevor Crossman, CX and Digital Transformation Director; Olivia Hussey, Strategic Planner; Simi Srinarula, Social Media Manager, The Hallway (AUS), James Hebbert, Managing Director, Hylink (CN / UK), Mundy ?lvarez, Planning Director; Pedro Rojas, Social Media Manager; Pancho GonzĻĒlez, CCO, Inbrax (CH), Oana Oprea, Head of Digital Planning, Jam Session Agency (RO), Amy Bottrill, Social Account Director, Launch (UK), Gaby Arriaga, Founder, Leonardo1452 (MX), Shantesh S Row, Creative Director, Liwa (UAE), Rajesh Mehta, Chief Strategy Officer; Dhruv Gaur, Digital Planning Lead; Leonie Mergulhao, Account Supervisor - Social Media & PR, Medulla (IN), Aurelija Plioplyt?, Head of Digital & Social, Not Perfect (LI), Daiana Khaidargaliyeva, Account Manager, Osaka Labs (UK / USA), Stefanie So?hnchen, Vice President Digital, PIABO Communications (DE), Elisabeth Winiartati, Managing Consultant, Head of Global Integrated Communications; Lydia Aprina, Account Manager, Integrated Marketing and Communications; Nita Prabowo, Account Manager, Integrated Marketing and Communications; Okhi, Web Developer, PNTR Group (ID), Kei Obusan, Insights Director; Daffi Ranandi, Insights Manager, Radarr (SG), Gautam Reghunath, Co-founder & CEO, Talented (IN), Donagh Humphreys, Head of Social and Digital Innovation, THINKHOUSE (IRE), Sarah Yim, Strategy Director, Zulu Alpha Kilo (CA).Trends In Paid Search: Navigating The Digital Landscape In 2024
Trends In Paid Search: Navigating The Digital Landscape In 2024Search Engine Journal
?
The search marketing landscape is evolving rapidly with new technologies, and professionals, like you, rely on innovative paid search strategies to meet changing demands.
ItĄŊs important that youĄŊre ready to implement new strategies in 2024.
Check this out and learn the top trends in paid search advertising that are expected to gain traction, so you can drive higher ROI more efficiently in 2024.
YouĄŊll learn:
- The latest trends in AI and automation, and what this means for an evolving paid search ecosystem.
- New developments in privacy and data regulation.
- Emerging ad formats that are expected to make an impact next year.
Watch Sreekant Lanka from iQuanti and Irina Klein from OneMain Financial as they dive into the future of paid search and explore the trends, strategies, and technologies that will shape the search marketing landscape.
If youĄŊre looking to assess your paid search strategy and design an industry-aligned plan for 2024, then this webinar is for you.5 Public speaking tips from TED - Visualized summary
5 Public speaking tips from TED - Visualized summarySpeakerHub
?
From their humble beginnings in 1984, TED has grown into the worldĄŊs most powerful amplifier for speakers and thought-leaders to share their ideas. They have over 2,400 filmed talks (not including the 30,000+ TEDx videos) freely available online, and have hosted over 17,500 events around the world.
With over one billion views in a year, itĄŊs no wonder that so many speakers are looking to TED for ideas on how to share their message more effectively.
The article Ą°5 Public-Speaking Tips TED Gives Its SpeakersĄą, by Carmine Gallo for Forbes, gives speakers five practical ways to connect with their audience, and effectively share their ideas on stage.
Whether you are gearing up to get on a TED stage yourself, or just want to master the skills that so many of their speakers possess, these tips and quotes from Chris Anderson, the TED Talks Curator, will encourage you to make the most impactful impression on your audience.
See the full article and more summaries like this on SpeakerHub here: https://speakerhub.com/blog/5-presentation-tips-ted-gives-its-speakers
See the original article on Forbes here:
http://www.forbes.com/forbes/welcome/?toURL=http://www.forbes.com/sites/carminegallo/2016/05/06/5-public-speaking-tips-ted-gives-its-speakers/&refURL=&referrer=#5c07a8221d9bChatGPT and the Future of Work - Clark Boyd 
ChatGPT and the Future of Work - Clark Boyd Clark Boyd
?
Everyone is in agreement that ChatGPT (and other generative AI tools) will shape the future of work. Yet there is little consensus on exactly how, when, and to what extent this technology will change our world.
Businesses that extract maximum value from ChatGPT will use it as a collaborative tool for everything from brainstorming to technical maintenance.
For individuals, now is the time to pinpoint the skills the future professional will need to thrive in the AI age.
Check out this presentation to understand what ChatGPT is, how it will shape the future of work, and how you can prepare to take advantage. Getting into the tech field. what next 
Getting into the tech field. what next Tessa Mero
?
The document provides career advice for getting into the tech field, including:
- Doing projects and internships in college to build a portfolio.
- Learning about different roles and technologies through industry research.
- Contributing to open source projects to build experience and network.
- Developing a personal brand through a website and social media presence.
- Networking through events, communities, and finding a mentor.
- Practicing interviews through mock interviews and whiteboarding coding questions.Google's Just Not That Into You: Understanding Core Updates & Search Intent
Google's Just Not That Into You: Understanding Core Updates & Search IntentLily Ray
?
1. Core updates from Google periodically change how its algorithms assess and rank websites and pages. This can impact rankings through shifts in user intent, site quality issues being caught up to, world events influencing queries, and overhauls to search like the E-A-T framework.
2. There are many possible user intents beyond just transactional, navigational and informational. Identifying intent shifts is important during core updates. Sites may need to optimize for new intents through different content types and sections.
3. Responding effectively to core updates requires analyzing "before and after" data to understand changes, identifying new intents or page types, and ensuring content matches appropriate intents across video, images, knowledge graphs and more.How to have difficult conversations 
How to have difficult conversations Rajiv Jayarajah, MAppComm, ACC
?
Stop putting off having difficult conversations. Seven practical tips to ensure your next difficult conversation go smoothly. More Related Content
Featured (20)
2024 Trend Updates: What Really Works In SEO & Content Marketing
2024 Trend Updates: What Really Works In SEO & Content MarketingSearch Engine Journal
?
The future of SEO is trending toward a more human-first and user-centric approach, powered by AI intelligence and collaboration. Are you ready?
Watch as we explore which SEO trends to prioritize to achieve sustainable growth and deliver reliable results. WeĄŊll dive into best practices to adapt your strategy around industry-wide disruptions like SGE, how to navigate the top challenges SEO professionals are facing, and proven tactics for prioritizing quality and building trust.
YouĄŊll hear:
- The top SEO trends to prioritize in 2024 to achieve long-term success.
- Predictions for SGEĄŊs impact, and how to adapt.
- What E-E-A-T really means, and how to implement it holistically (hint: itĄŊs never been more important).
With Zack Kadish and Alex Carchietta, weĄŊll show you which SEO trends to ignore and which to focus on, along with the solution to overcoming rapid, significant and disruptive Google algorithm updates.
If youĄŊre looking to cut through the noise of constant SEO and content trends to drive success, you wonĄŊt want to miss this webinar.
Storytelling For The Web: Integrate Storytelling in your Design Process
Storytelling For The Web: Integrate Storytelling in your Design ProcessChiara Aliotta
?
In this slides I explain how I have used storytelling techniques to elevate websites and brands and create memorable user experiences. You can discover practical tips as I showcase the elements of good storytelling and its applied to some examples of diverse brands/projects..Artificial Intelligence, Data and Competition ĻC SCHREPEL ĻC June 2024 OECD dis...
Artificial Intelligence, Data and Competition ĻC SCHREPEL ĻC June 2024 OECD dis...OECD Directorate for Financial and Enterprise Affairs
?
This presentation by Thibault Schrepel, Associate Professor of Law at Vrije Universiteit Amsterdam University, was made during the discussion Ą°Artificial Intelligence, Data and CompetitionĄą held at the 143rd meeting of the OECD Competition Committee on 12 June 2024. More papers and presentations on the topic can be found at oe.cd/aicomp.
This presentation was uploaded with the authorĄŊs consent.
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...
How to Leverage AI to Boost Employee Wellness - Lydia Di Francesco - SocialHR...SocialHRCamp
?
Speaker: Lydia Di Francesco
In this workshop, participants will delve into the realm of AI and its profound potential to revolutionize employee wellness initiatives. From stress management to fostering work-life harmony, AI offers a myriad of innovative tools and strategies that can significantly enhance the wellbeing of employees in any organization. Attendees will learn how to effectively leverage AI technologies to cultivate a healthier, happier, and more productive workforce. Whether it's utilizing AI-powered chatbots for mental health support, implementing data analytics to identify internal, systemic risk factors, or deploying personalized wellness apps, this workshop will equip participants with actionable insights and best practices to harness the power of AI for boosting employee wellness. Join us and discover how AI can be a strategic partner towards a culture of wellbeing and resilience in the workplace.2024 State of Marketing Report ĻC by Hubspot
2024 State of Marketing Report ĻC by HubspotMarius Sescu
?
https://www.hubspot.com/state-of-marketing
ĄĪ Scaling relationships and proving ROI
ĄĪ Social media is the place for search, sales, and service
ĄĪ Authentic influencer partnerships fuel brand growth
ĄĪ The strongest connections happen via call, click, chat, and camera.
ĄĪ Time saved with AI leads to more creative work
ĄĪ Seeking: A single source of truth
ĄĪ TLDR; Get on social, try AI, and align your systems.
ĄĪ More human marketing, powered by robotsEverything You Need To Know About ChatGPT
Everything You Need To Know About ChatGPTExpeed Software
?
ChatGPT is a revolutionary addition to the world since its introduction in 2022. A big shift in the sector of information gathering and processing happened because of this chatbot. What is the story of ChatGPT? How is the bot responding to prompts and generating contents? Swipe through these slides prepared by Expeed Software, a web development company regarding the development and technical intricacies of ChatGPT!Product Design Trends in 2024 | Teenage Engineerings
Product Design Trends in 2024 | Teenage EngineeringsPixeldarts
?
The realm of product design is a constantly changing environment where technology and style intersect. Every year introduces fresh challenges and exciting trends that mold the future of this captivating art form. In this piece, we delve into the significant trends set to influence the look and functionality of product design in the year 2024.How Race, Age and Gender Shape Attitudes Towards Mental Health
How Race, Age and Gender Shape Attitudes Towards Mental HealthThinkNow
?
Mental health has been in the news quite a bit lately. Dozens of U.S. states are currently suing Meta for contributing to the youth mental health crisis by inserting addictive features into their products, while the U.S. Surgeon General is touring the nation to bring awareness to the growing epidemic of loneliness and isolation. The country has endured periods of low national morale, such as in the 1970s when high inflation and the energy crisis worsened public sentiment following the Vietnam War. The current mood, however, feels different. Gallup recently reported that national mental health is at an all-time low, with few bright spots to lift spirits.
To better understand how Americans are feeling and their attitudes towards mental health in general, ThinkNow conducted a nationally representative quantitative survey of 1,500 respondents and found some interesting differences among ethnic, age and gender groups.
Technology
For example, 52% agree that technology and social media have a negative impact on mental health, but when broken out by race, 61% of Whites felt technology had a negative effect, and only 48% of Hispanics thought it did.
While technology has helped us keep in touch with friends and family in faraway places, it appears to have degraded our ability to connect in person. Staying connected online is a double-edged sword since the same news feed that brings us pictures of the grandkids and fluffy kittens also feeds us news about the wars in Israel and Ukraine, the dysfunction in Washington, the latest mass shooting and the climate crisis.
Hispanics may have a built-in defense against the isolation technology breeds, owing to their large, multigenerational households, strong social support systems, and tendency to use social media to stay connected with relatives abroad.
Age and Gender
When asked how individuals rate their mental health, men rate it higher than women by 11 percentage points, and Baby Boomers rank it highest at 83%, saying itĄŊs good or excellent vs. 57% of Gen Z saying the same.
Gen Z spends the most amount of time on social media, so the notion that social media negatively affects mental health appears to be correlated. Unfortunately, Gen Z is also the generation thatĄŊs least comfortable discussing mental health concerns with healthcare professionals. Only 40% of them state theyĄŊre comfortable discussing their issues with a professional compared to 60% of Millennials and 65% of Boomers.
Race Affects Attitudes
As seen in previous research conducted by ThinkNow, Asian Americans lag other groups when it comes to awareness of mental health issues. Twenty-four percent of Asian Americans believe that having a mental health issue is a sign of weakness compared to the 16% average for all groups. Asians are also considerably less likely to be aware of mental health services in their communities (42% vs. 55%) and most likely to seek out information on social media (51% vs. 35%).AI Trends in Creative Operations 2024 by Artwork Flow.pdf
AI Trends in Creative Operations 2024 by Artwork Flow.pdfmarketingartwork
?
Creative operations teams expect increased AI use in 2024. Currently, over half of tasks are not AI-enabled, but this is expected to decrease in the coming year. ChatGPT is the most popular AI tool currently. Business leaders are more actively exploring AI benefits than individual contributors. Most respondents do not believe AI will impact workforce size in 2024. However, some inhibitions still exist around AI accuracy and lack of understanding. Creatives primarily want to use AI to save time on mundane tasks and boost productivity.Skeleton Culture Code
Skeleton Culture CodeSkeleton Technologies
?
Organizational culture includes values, norms, systems, symbols, language, assumptions, beliefs, and habits that influence employee behaviors and how people interpret those behaviors. It is important because culture can help or hinder a company's success. Some key aspects of Netflix's culture that help it achieve results include hiring smartly so every position has stars, focusing on attitude over just aptitude, and having a strict policy against peacocks, whiners, and jerks.PEPSICO Presentation to CAGNY Conference Feb 2024
PEPSICO Presentation to CAGNY Conference Feb 2024Neil Kimberley
?
PepsiCo provided a safe harbor statement noting that any forward-looking statements are based on currently available information and are subject to risks and uncertainties. It also provided information on non-GAAP measures and directing readers to its website for disclosure and reconciliation. The document then discussed PepsiCo's business overview, including that it is a global beverage and convenient food company with iconic brands, $91 billion in net revenue in 2023, and nearly $14 billion in core operating profit. It operates through a divisional structure with a focus on local consumers.Content Methodology: A Best Practices Report (Webinar)
Content Methodology: A Best Practices Report (Webinar)contently
?
This document provides an overview of content methodology best practices. It defines content methodology as establishing objectives, KPIs, and a culture of continuous learning and iteration. An effective methodology focuses on connecting with audiences, creating optimal content, and optimizing processes. It also discusses why a methodology is needed due to the competitive landscape, proliferation of channels, and opportunities for improvement. Components of an effective methodology include defining objectives and KPIs, audience analysis, identifying opportunities, and evaluating resources. The document concludes with recommendations around creating a content plan, testing and optimizing content over 90 days.How to Prepare For a Successful Job Search for 2024
How to Prepare For a Successful Job Search for 2024Albert Qian
?
The document provides guidance on preparing a job search for 2024. It discusses the state of the job market, focusing on growth in AI and healthcare but also continued layoffs. It recommends figuring out what you want to do by researching interests and skills, then conducting informational interviews. The job search should involve building a personal brand on LinkedIn, actively applying to jobs, tailoring resumes and interviews, maintaining job hunting as a habit, and continuing self-improvement. Once hired, the document advises setting new goals and keeping skills and networking active in case of future opportunities.Social Media Marketing Trends 2024 // The Global Indie Insights
Social Media Marketing Trends 2024 // The Global Indie InsightsKurio // The Social Media Age(ncy)
?
A report by thenetworkone and Kurio.
The contributing experts and agencies are (in an alphabetical order): Sylwia Rytel, Social Media Supervisor, 180heartbeats + JUNG v MATT (PL), Sharlene Jenner, Vice President - Director of Engagement Strategy, Abelson Taylor (USA), Alex Casanovas, Digital Director, Atrevia (ES), Dora Beilin, Senior Social Strategist, Barrett Hoffher (USA), Min Seo, Campaign Director, Brand New Agency (KR), DeshĻĶ M. Gully, Associate Strategist, Day One Agency (USA), Francesca Trevisan, Strategist, Different (IT), Trevor Crossman, CX and Digital Transformation Director; Olivia Hussey, Strategic Planner; Simi Srinarula, Social Media Manager, The Hallway (AUS), James Hebbert, Managing Director, Hylink (CN / UK), Mundy ?lvarez, Planning Director; Pedro Rojas, Social Media Manager; Pancho GonzĻĒlez, CCO, Inbrax (CH), Oana Oprea, Head of Digital Planning, Jam Session Agency (RO), Amy Bottrill, Social Account Director, Launch (UK), Gaby Arriaga, Founder, Leonardo1452 (MX), Shantesh S Row, Creative Director, Liwa (UAE), Rajesh Mehta, Chief Strategy Officer; Dhruv Gaur, Digital Planning Lead; Leonie Mergulhao, Account Supervisor - Social Media & PR, Medulla (IN), Aurelija Plioplyt?, Head of Digital & Social, Not Perfect (LI), Daiana Khaidargaliyeva, Account Manager, Osaka Labs (UK / USA), Stefanie So?hnchen, Vice President Digital, PIABO Communications (DE), Elisabeth Winiartati, Managing Consultant, Head of Global Integrated Communications; Lydia Aprina, Account Manager, Integrated Marketing and Communications; Nita Prabowo, Account Manager, Integrated Marketing and Communications; Okhi, Web Developer, PNTR Group (ID), Kei Obusan, Insights Director; Daffi Ranandi, Insights Manager, Radarr (SG), Gautam Reghunath, Co-founder & CEO, Talented (IN), Donagh Humphreys, Head of Social and Digital Innovation, THINKHOUSE (IRE), Sarah Yim, Strategy Director, Zulu Alpha Kilo (CA).Trends In Paid Search: Navigating The Digital Landscape In 2024
Trends In Paid Search: Navigating The Digital Landscape In 2024Search Engine Journal
?
The search marketing landscape is evolving rapidly with new technologies, and professionals, like you, rely on innovative paid search strategies to meet changing demands.
ItĄŊs important that youĄŊre ready to implement new strategies in 2024.
Check this out and learn the top trends in paid search advertising that are expected to gain traction, so you can drive higher ROI more efficiently in 2024.
YouĄŊll learn:
- The latest trends in AI and automation, and what this means for an evolving paid search ecosystem.
- New developments in privacy and data regulation.
- Emerging ad formats that are expected to make an impact next year.
Watch Sreekant Lanka from iQuanti and Irina Klein from OneMain Financial as they dive into the future of paid search and explore the trends, strategies, and technologies that will shape the search marketing landscape.
If youĄŊre looking to assess your paid search strategy and design an industry-aligned plan for 2024, then this webinar is for you.5 Public speaking tips from TED - Visualized summary
5 Public speaking tips from TED - Visualized summarySpeakerHub
?
From their humble beginnings in 1984, TED has grown into the worldĄŊs most powerful amplifier for speakers and thought-leaders to share their ideas. They have over 2,400 filmed talks (not including the 30,000+ TEDx videos) freely available online, and have hosted over 17,500 events around the world.
With over one billion views in a year, itĄŊs no wonder that so many speakers are looking to TED for ideas on how to share their message more effectively.
The article Ą°5 Public-Speaking Tips TED Gives Its SpeakersĄą, by Carmine Gallo for Forbes, gives speakers five practical ways to connect with their audience, and effectively share their ideas on stage.
Whether you are gearing up to get on a TED stage yourself, or just want to master the skills that so many of their speakers possess, these tips and quotes from Chris Anderson, the TED Talks Curator, will encourage you to make the most impactful impression on your audience.
See the full article and more summaries like this on SpeakerHub here: https://speakerhub.com/blog/5-presentation-tips-ted-gives-its-speakers
See the original article on Forbes here:
http://www.forbes.com/forbes/welcome/?toURL=http://www.forbes.com/sites/carminegallo/2016/05/06/5-public-speaking-tips-ted-gives-its-speakers/&refURL=&referrer=#5c07a8221d9bChatGPT and the Future of Work - Clark Boyd
ChatGPT and the Future of Work - Clark Boyd Clark Boyd
?
Everyone is in agreement that ChatGPT (and other generative AI tools) will shape the future of work. Yet there is little consensus on exactly how, when, and to what extent this technology will change our world.
Businesses that extract maximum value from ChatGPT will use it as a collaborative tool for everything from brainstorming to technical maintenance.
For individuals, now is the time to pinpoint the skills the future professional will need to thrive in the AI age.
Check out this presentation to understand what ChatGPT is, how it will shape the future of work, and how you can prepare to take advantage. Getting into the tech field. what next
Getting into the tech field. what next Tessa Mero
?
The document provides career advice for getting into the tech field, including:
- Doing projects and internships in college to build a portfolio.
- Learning about different roles and technologies through industry research.
- Contributing to open source projects to build experience and network.
- Developing a personal brand through a website and social media presence.
- Networking through events, communities, and finding a mentor.
- Practicing interviews through mock interviews and whiteboarding coding questions.Google's Just Not That Into You: Understanding Core Updates & Search Intent
Google's Just Not That Into You: Understanding Core Updates & Search IntentLily Ray
?
1. Core updates from Google periodically change how its algorithms assess and rank websites and pages. This can impact rankings through shifts in user intent, site quality issues being caught up to, world events influencing queries, and overhauls to search like the E-A-T framework.
2. There are many possible user intents beyond just transactional, navigational and informational. Identifying intent shifts is important during core updates. Sites may need to optimize for new intents through different content types and sections.
3. Responding effectively to core updates requires analyzing "before and after" data to understand changes, identifying new intents or page types, and ensuring content matches appropriate intents across video, images, knowledge graphs and more.How to have difficult conversations
How to have difficult conversations Rajiv Jayarajah, MAppComm, ACC
?
Stop putting off having difficult conversations. Seven practical tips to ensure your next difficult conversation go smoothly. Artificial Intelligence, Data and Competition ĻC SCHREPEL ĻC June 2024 OECD dis...
Artificial Intelligence, Data and Competition ĻC SCHREPEL ĻC June 2024 OECD dis...OECD Directorate for Financial and Enterprise Affairs
?
ICML2015ÕiĪßŧáĢšOptimal and Adaptive Algorithms for Online Boosting
- 2. ÕÎÄļÅŌŠ Optimal and Adaptive Algorithms for Online Boosting (ICML2015 Best Paper) Alina Beygelzimer, Satyen Kale, and Haipeng Luo (Yahoo Lab & ĨŨĨęĨóĨđĨČĨóīó) ĨŠĨóĨéĨĪĨóĪÎĨÖĐ`ĨđĨÆĨĢĨóĨ°ĘÖ·ĻĪō2ĪÄĖá°ļĪđĪëĢŪ ? ĀíÕÉÏŨîßmĪĘĘÖ·Ļ ? Adaptive ĪĘĘÖ·Ļ ßxĪóĪĀĀíÓÉĢš ĀíÕžÄĪęĪÎÕÎÄĪĮ ICML ĪÎ Best paper ĪËßxĪÐĪėĪëĪčĪĶĪĘĪâĪÎĪŽ ĪÉĪóĪĘĪâĪÎĪŦÖŠĪęĪŋĪŦĪÃĪŋĪŋĪá ĪĘĪŠ―âÎöēŋ·ÖĪÏĘäĪđĪërégĪŽĪĘĪŦĪÃĪŋĪÎĪĮĪÛĪČĪóĪÉÕhÃũĪ·ĪÞĪŧĪóĄ
- 3. ÄŋīÎ ? ÍÁ ?ĨÖĐ`ĨđĨÆĨĢĨóĨ° ?ĨŠĨóĨéĨĪĨóŅ§Á ? î}ÔOķĻ ? Ėá°ļĘÖ·Ļ ? (ĪŠĪÞĪą)gōY―Yđû ? ļÐÏë Į°ÖÃĪĢš ĪģĪΰkąíĪĮĪÏ 2·ÖîĪĀĪąĪōQĪĪĪÞĪđ
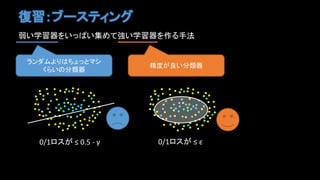
- 4. ÍÁĢšĨÖĐ`ĨđĨÆĨĢĨóĨ° ČõĪĪŅ§ÁÆũĪōĪĪĪÃĪŅĪĪžŊĪáĪÆĪĪŅ§ÁÆũĪōŨũĪëĘÖ·Ļ ĨéĨóĨĀĨāĪčĪęĪÏĪÁĪįĪÃĪČĨÞĨ· ĪŊĪéĪĪĪηÖîÆũ ūŦķČĪŽÁžĪĪ·ÖîÆũ 0/1ĨíĨđĪŽ ĄÜ 0.5 - Ķà 0/1ĨíĨđĪŽ ĄÜ ĶÅ
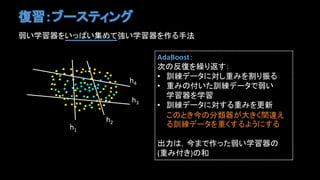
- 5. ÍÁĢšĨÖĐ`ĨđĨÆĨĢĨóĨ° ČõĪĪŅ§ÁÆũĪōĪĪĪÃĪŅĪĪžŊĪáĪÆĪĪŅ§ÁÆũĪōŨũĪëĘÖ·Ļ h1 h2 h3 h4 AdaBoostĢš īÎĪηīÍĪōĀRĪę·ĩĪđĢš ? ÓūĨĮĐ`ĨŋĪËĪ·ÖØĪßĪōļîĪęÕņĪë ? ÖØĪßĪÎļķĪĪĪŋÓūĨĮĐ`ĨŋĪĮČõĪĪ Ņ§ÁÆũĪōŅ§Á ? ÓūĨĮĐ`ĨŋĪËĪđĪëÖØĪßĪōļüРĪģĪÎĪČĪ―ņĪηÖîÆũĪŽīóĪĪŊégß`ĪĻ ĪëÓūĨĮĐ`ĨŋĪōÖØĪŊĪđĪëĪčĪĶĪËĪđĪë ģöÁĶĪÏĢŽ―ņĪÞĪĮŨũĪÃĪŋČõĪĪŅ§ÁÆũĪÎ (ÖØĪßļķĪ)ĪΚÍ
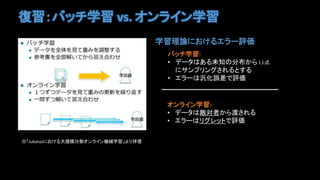
- 6. ÍÁĢšĨÐĨÃĨÁŅ§Á vs. ĨŠĨóĨéĨĪĨóŅ§Á ĄųĄļJubatusĪËĪŠĪąĪëīóŌÄĢ·ÖÉĒĨŠĨóĨéĨĪĨóCÐĩŅ§ÁĄđĪčĪę ―č Ņ§ÁĀíÕĪËĪŠĪąĪëĨĻĨéĐ`Ôuý ĨÐĨÃĨÁŅ§Á: ? ĨĮĐ`ĨŋĪÏĪĒĪëÎīÖŠĪηÖēžĪŦĪé i.i.d. ĪËĨĩĨóĨŨĨęĨóĨ°ĪĩĪėĪëĪČĪđĪë ? ĨĻĨéĐ`ĪÏøŧŊÕ`ēîĪĮÔuý ĨŠĨóĨéĨĪĨóŅ§Á: ? ĨĮĐ`ĨŋĪÏģÕßĪŦĪéķÉĪĩĪėĪë ? ĨĻĨéĐ`ĪÏĨęĨ°ĨėĨÃĨČĪĮÔuý
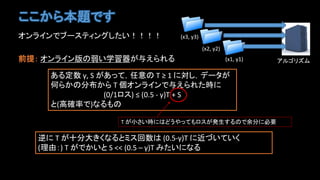
- 7. ĪģĪģĪŦĪéąūî}ĪĮĪđ ĨŠĨóĨéĨĪĨóĪĮĨÖĐ`ĨđĨÆĨĢĨóĨ°Ī·ĪŋĪĪĢĄĢĄĢĄĢĄ Į°ĖáĢš ĨŠĨóĨéĨĪĨó°æĪÎČõĪĪŅ§ÁÆũĪŽÓëĪĻĪéĪėĪë ĪĒĪëķĻĘý ĶÃ, S ĪŽĪĒĪÃĪÆĢŽČÎŌâĪÎ T ĄÝ 1 ĪËĪ·ĢŽĨĮĐ`ĨŋĪŽ šÎĪéĪŦĪηÖēžĪŦĪé T ĨŠĨóĨéĨĪĨóĪĮÓëĪĻĪéĪėĪŋrĪË (0/1ĨíĨđ) ĄÜ (0.5 - ĶÃ)T + S ĪČ(ļßī_ÂĘĪĮ)ĪĘĪëĪâĪÎ T ĪŽÐĄĪĩĪĪrĪËĪÏĪÉĪĶĪäĪÃĪÆĪâĨíĨđĪŽ°kÉúĪđĪëĪÎĪĮÓā·ÖĪËąØŌŠ ÄæĪË T ĪŽĘŪ·ÖīóĪĪŊĪĘĪëĪČĨßĨđŧØĘýĪÏ (0.5-ĶÃ)T ĪË―üĪÅĪĪĪÆĪĪĪŊ (ĀíÓÉĢš) T ĪŽĪĮĪŦĪĪĪČ S << (0.5 ĻC ĶÃ)T ĪßĪŋĪĪĪËĪĘĪë ĨĒĨëĨīĨęĨšĨā(x1, y1) (x2, y2) (x3, y3)
- 8. ĪģĪģĪŦĪéąūî}ĪĮĪđ ĨŠĨóĨéĨĪĨóĪĮĨÖĐ`ĨđĨÆĨĢĨóĨ°Ī·ĪŋĪĪĢĄĢĄĢĄĢĄ Į°ĖáĢš ĨŠĨóĨéĨĪĨó°æĪÎČõĪĪŅ§ÁÆũĪŽÓëĪĻĪéĪėĪë ÄŋË : ĨŠĨóĨéĨĪĨó°æĪÎĪĪŅ§ÁÆũĪōŨũĪęĪŋĪĪ ĨĒĨëĨīĨęĨšĨāĪÎÐÔÄÜĪÏĢŽĖõžþĪČÄŋË(ĶÃ, S, ĶÅ) ĪËĪ·ŌÔÏÂĪĮÔuýĪđĪë ? (N) ČõĪĪŅ§ÁÆũĪŽĪĪĪŊĪÄąØŌŠĪŦ ? (T) ĨĩĨóĨŨĨëĘýĪŽĪĪĪŊĪÄąØŌŠĪŦ ĪĒĪëķĻĘýĶÅ, SĄŊ ĪŽĪĒĪÃĪÆĢŽČÎŌâĪÎ T ĄÝ 1 ĪËĪ·ĢŽĨĮĐ`ĨŋĪŽ šÎĪéĪŦĪηÖēžĪŦĪé T ĨŠĨóĨéĨĪĨóĪĮÓëĪĻĪéĪėĪŋrĪË (0/1ĨíĨđ) ĄÜ ĶÅT + SĄŊ ĪČ(ļßī_ÂĘĪĮ)ĪĘĪëĪâĪÎ ĨĒĨëĨīĨęĨšĨā(x1, y1) (x2, y2) (x3, y3)
- 9. ĨŠĨóĨéĨĪĨóĨÖĐ`ĨđĨÆĨĢĨóĨ° ŧųąūĩÄĪËĪÏČõĪĪŅ§ÁÆũĪīĪČĪÎÖØĪß ĶÁ(t, i) ĪōÖðīÎđÜĀíĪ·ĪÆĪĪĪŊ ÖØĩãĨĩĨóĨŨĨęĨóĨ°Ģš ļũŅ§ÁÆũĪÎ update rĪËĢŽĪĒĪëī_ÂĘ p(t, i) ĪĮĪ·ĪŦÓūĨĮĐ`ĨŋĪōķÉĪĩĪĘĪĪĪčĪĶĪËĪđĪë ĨĒĨëĨīĨęĨšĨāĢš ļũ t = 1,Ą,T ĪËĪÄĪĪĪÆĢš ? Óčy = (Ķēi ĶÁ(t, i)?Ņ§ÁÆũi(xt) )ĪηûšÅ ? ļũŅ§ÁÆũĪČ ĶÁ Īō update (xi, yi) p(t, i) 1 - p(t, i)
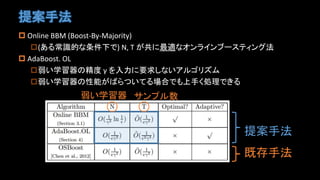
- 10. Ėá°ļĘÖ·Ļ ? Online BBM (Boost-By-Majority) ?(ĪĒĪëģĢŨRĩÄĪĘĖõžþÏÂĪĮ) N, T ĪŽđēĪËŨîßmĪĘĨŠĨóĨéĨĪĨóĨÖĐ`ĨđĨÆĨĢĨóĨ°·Ļ ? AdaBoost. OL ?ČõĪĪŅ§ÁÆũĪÎūŦķČ Ķà ĪōČëÁĶĪËŌŠĮóĪ·ĪĘĪĪĨĒĨëĨīĨęĨšĨā ?ČõĪĪŅ§ÁÆũĪÎÐÔÄÜĪŽĪÐĪéĪÄĪĪĪÆĪëöšÏĪĮĪâÉÏĘÖĪŊIĀíĪĮĪĪë Ėá°ļĘÖ·Ļ žČīæĘÖ·Ļ ČõĪĪŅ§ÁÆũ ĨĩĨóĨŨĨëĘý
- 11. Ėá°ļĘÖ·Ļ(Optimal ĪĘ·―) īóĩĻĪËĪâĢŽĶÁ = 1 ĪËĨŧĨÃĨČĪđĪëĢŪ ―âÎöĪÎĪÕĪóĪĪĪ īÎĪÎĨÝĨÆĨóĨ·ĨãĨëévĘý Ķĩi(s) ĪōŋžĪĻĪë(ĖÆÍŧ?) ĪģĪģĪĮ p(t, i) ĪōĪģĪÎĨÝĨÆĨóĨ·ĨãĨëévĘýĪōĘđĪÃĪÆQĪáĪë(Ę―ĪŽÉŲĪ·ĪäĪäĪģĪ·ĪĪĪÎĪĮÂÔ)ĪČĢŽ 0/1 ĨíĨđĪōŌÔÏÂĪÎĪčĪĶĪËŌÖĪĻĪéĪėĪë ĨĒĨëĨīĨęĨšĨā(ÔŲũ)Ģš ļũ t = 1,Ą,T ĪËĪÄĪĪĪÆĢš ? Óčy = (Ķēi ĶÁ(t, i)?Ņ§ÁÆũi(xt) )ĪηûšÅ ? ļũŅ§ÁÆũĪČ ĶÁ Īō update p(t, i) ĪËūĪĪÖØĩãĨĩĨóĨŨĨęĨóĨ°ĪđĪë ĶĩĪōĪĪĪĪļÐĪļĪËÔOÓĪđĪëĪČ ĪģĪÎíĪŽÐĄĪĩĪŊĪĘĪëĪģĪČĪŽ ŅÔĪĻĪë
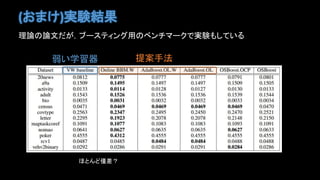
- 13. ĪÞĪČĪá&ļÐÏë ÕÎÄĪÎĪÞĪČĪá Online boosting ĪĮĀíÕĩÄĪËŨîßmĪĘĘÖ·ĻĪČĢŽadaptive ĪĘĘÖ·ĻĪÎ2ĪÄĪōĖá°ļ ÏÂ―įĪâÔ^ÃũĪ·ĪÆĪë ļÐÏë ? Online boosting ĪČĪĪĪĶ·ÖŌ°ĪÏĪģĪėĪĮĪÛĪÜĪäĪęūĄĪŊĪĩĪėĪŋĢŋ ? ĪÉĪģĪŦĪéĨĒĨĪĨĮĨĒĪŽģöĪÆĪĪŋĪÎĪŦËØČËĪËĪÏÖiĪĀĪÃĪŋ ?ħ·ĻĪÎÖØĪßĪŽÍŧČŧģöĪÆĪĪÆšÎđĘĪŦĪĪĪĪļÐĪļĪË―âÎöĪĮĪĪëĪßĪŋĪĪĪËŌĪĻĪë ?gëHĪÏĄĐĪĘÏČÐÐŅÐūŋĪËŧųĪĪĪÆĘÖ·ĻĪōŋžĪĻĪÆĪ―ĪĶ