NIP2015ÕiĪßŧáĄļEnd-To-End Memory NetworksĄđ
30 likes11,525 views

NIPS2015ÕiĪßŧáĪĮÔĪ·ĪŋĄĒĄļEnd-To-End Memory NetworksĄđĪÎŲYÁÏĪĮĪđ






















![[DLÝÕiŧá]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=560&fit=bounds)
![[DLÝÕiŧá]Pay Attention to MLPs ĢĻgMLPĢĐ](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=560&fit=bounds)





![[DLÝÕiŧá]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=560&fit=bounds)






![[DLÝÕiŧá]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=560&fit=bounds)



![[DLÝÕiŧá]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [OS2-02] ÉîÓŅ§ÁĪËĪŠĪąĪëĨĮĐ`ĨŋĪÎÔĀíĪČŨîÐÂÓÏō](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=560&fit=bounds)




More Related Content
What's hot (20)
More from Yuya Unno (20)


















NIP2015ÕiĪßŧáĄļEnd-To-End Memory NetworksĄđ
- 1. NIPS2015ÕiĪßŧá End-To-End Memory Networks S. Sukhbaatar, A. Szlam, J. Weston, R. Fergus Preferred Infrastructure šĢŌ°?ĄĄÔĢŌēĢĻ@unnonounoĢĐ íĪÏĪđĪŲĪÆÔŠÕÎÄĪŦĪéŌýÓÃ 2016/01/20 NIPS2015ÕiĪßŧá@ĨÉĨïĨóĨī
- 2. Memory networks l?? 2013ÄęÄęÞxĪęĪŦĪéFacebookĪŽČĄĪę―MĪóĪĮĪĪĪë ĨÆĐ`ĨÞ l?? ?ŨÔČŧ?ÎÄĪĮÓëĪĻĪéĪėĪŋĘÂgĪōÓĪ·ĄĒŲ|ĪËĪ· ĪÆ?ŨÔČŧĪËīðĪĻĪëĨÕĨėĐ`ĨāĨïĐ`ĨŊĪōŋžĪĻĪÆĪĪĪë l?? ―ņŧØĪÎÔĪÏĄĒČŦĖåĪÎĘË―MĪßĪōend-to-endĪĮŅ§Á ĪđĪë 2
- 4. 4
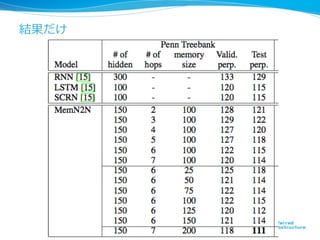
- 5. ―ņ?ČÕÔĪđĪïĪą l?? īšĪËChainerĪĮÔŲgŨ°Ī·ĪŋrĄĒĪÁĪãĪóĪČÓĪŦĪĘ ĪŦĪÃĪŋ l?? ÄęÄęÄĐĪËŨũĪęĪĘĪŠĪ·ĪŋĪéĄĒĪÁĪãĪóĪČÓĪĪĪŋĢĻĨĮĐ` ĨŋÕiĪāĪČĪģĪíĪÎĨÐĨ°ĪĀĪÃĪŋĢĐ l?? ĨČĐ`ĨŋĨëĪĮ300?ÐÐÐÐĪŊĪéĪĪ l?? ChainerÉÏĪĮĪÎęĪō―ŧĪĻĪĘĪŽĪé―âÕh 5
- 6. ÏóĪÎĨŋĨđĨŊĢšbAbI task l?? ?ČËĪŽēŋÎÝĪÎÖÐĪō?ÐÐÐÐÓĪ·ĪŋĘÂgĪŽøĪŦĪėĪÆĪĪĪÆĄĒÍūÖÐÍūÖÐ ĪĮš gĪĘŲ|ĪōĪĩĪėĪë l?? OĪáĪÆ?ČË?đĪĩÄĪĘĨŋĨđĨŊĪĮĄĒÕZĄĪâ?·ĮģĢĪËÏÞĪéĪėĪÆĪĪĪë ĢĻ177ÕZĄĢĐ 6
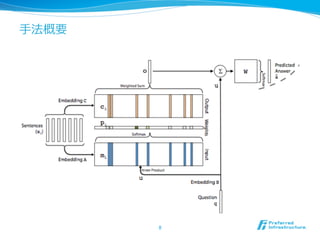
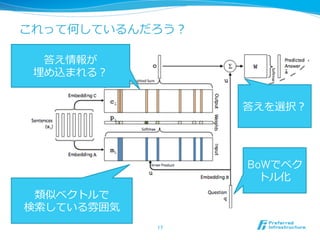
- 7. ķĻĘ―ŧŊ l?? ?Čë?ÁĶÁĶ l?? ÖŠŨRŨRÔī: {x1, x2, Ą , xn} l?? Ų|: q l?? Ī―ĪėĪūĪė?ŨÔČŧ?ÎÄĢĻČÎŌâ??éLĪÎ gÕZÁÐÁÐĢ―ÕûĘýÁÐÁÐĢĐ l?? ģö?ÁĶÁĶ l?? Ų|ĪØĪÎŧØīð: a ĢĻ g?ŌŧĪÎ gÕZĢ―ÕûĘýĢĐ l?? ĨŅĨéĨáĐ`Ĩŋ l?? ÂņĪáÞzĪßĨŲĨŊĨČĨë?ÐÐÐÐÁÐÁÐ: A, B, C ĢĻd x VīÎÔŠĢĐ l?? ŧØīð?ÓÃ?ÐÐÐÐÁÐÁÐ: W ĢĻV x dīÎÔŠĢĐ l?? d: ÂņĪáÞzĪßĨŲĨŊĨČĨëĪÎīÎÔŠĘýĄĒV: ÕZĄĘý 7
- 8. ?ĘÖ·ĻļÅŌŠ 8
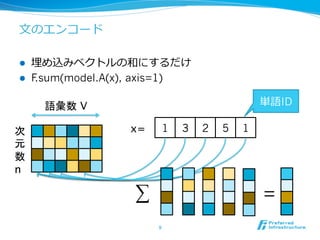
- 9. ?ÎÄĪÎĨĻĨóĨģĐ`ĨÉ l?? ÂņĪáÞzĪßĨŲĨŊĨČĨëĪΚÍĪËĪđĪëĪĀĪą l?? F.sum(model.A(x), axis=1) 9 ÕZĄĘý V īÎ ÔŠ Ęý n 1 3 2 5 1x= gÕZID ĄÆ =
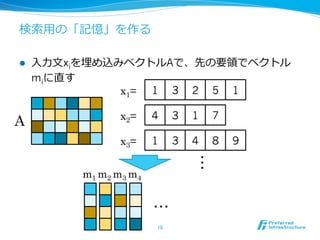
- 10. ĘËũËũ?ÓÃĪÎĄļÓĄđĪōŨũĪë l?? ?Čë?ÁĶÁĶ?ÎÄxiĪōÂņĪáÞzĪßĨŲĨŊĨČĨëAĪĮĄĒÏČĪÎŌŠîIîIĪĮĨŲĨŊĨČĨë miĪËÖąĪđ 10 1 3 2 5 1x1= 4 3 1 7x2= 1 3 4 8 9x3= m1 m2 m3 m4 ??? A
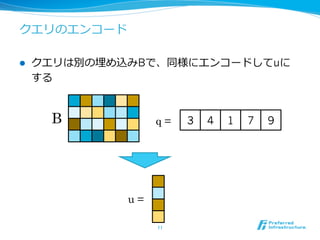
- 11. ĨŊĨĻĨęĪÎĨĻĨóĨģĐ`ĨÉ l?? ĨŊĨĻĨęĪÏeĪÎÂņĪáÞzĪßBĪĮĄĒÍŽĪËĨĻĨóĨģĐ`ĨÉĪ·ĪÆuĪË ĪđĪë 11 B 3 4 1 7 9q = u =
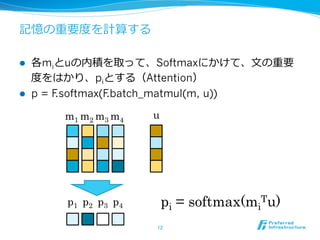
- 12. ÓĪÎÖØŌŠķČķČĪōÓËãĪđĪë l?? ļũmiĪČuĪÎÄÚ·eĪōČĄĪÃĪÆĄĒSoftmaxĪËĪŦĪąĪÆĄĒ?ÎÄĪÎÖØŌŠ ķČķČĪōĪÏĪŦĪęĄĒpiĪČĪđĪëĢĻAttentionĢĐ l?? p = F.softmax(F.batch_matmul(m, u)) 12 m1 m2 m3 m4 u p1 p2 p3 p4 pi = softmax(mi Tu)
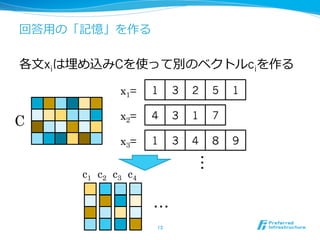
- 13. ŧØīð?ÓÃĪÎĄļÓĄđĪōŨũĪë ļũ?ÎÄxiĪÏÂņĪáÞzĪßCĪōĘđĪÃĪÆeĪÎĨŲĨŊĨČĨëciĪōŨũĪë 13 1 3 2 5 1x1= 4 3 1 7x2= 1 3 4 8 9x3= c1 c2 c3 c4 ??? C
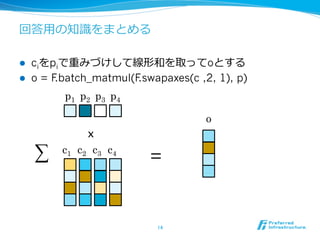
- 14. ŧØīð?ÓÃĪÎÖŠŨRŨRĪōĪÞĪČĪáĪë l?? ciĪōpiĪĮÖØĪßĪÅĪąĪ·ĪÆūÐΚÍĪōČĄĪÃĪÆoĪČĪđĪë l?? o = F.batch_matmul(F.swapaxes(c ,2, 1), p) 14 p1 p2 p3 p4 c1 c2 c3 c4 x ĄÆ = o
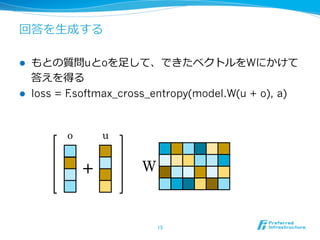
- 15. ŧØīðĪō?ÉúģÉĪđĪë l?? ĪâĪČĪÎŲ|uĪČoĪō?ŨãĪ·ĪÆĄĒĪĮĪĪŋĨŲĨŊĨČĨëĪōWĪËĪŦĪąĪÆ īðĪĻĪōĩÃĪë l?? loss = F.softmax_cross_entropy(model.W(u + o), a) 15 o u + W
- 16. ĪŠĪĩĪéĪĪ l?? ÖŠŨRŨRÔīxiĪÏAĪōĘđĪÃĪÆmiĪËĄĒCĪōĘđĪÃĪÆciĪË l?? Ų|qĪÏBĪōĘđĪÃĪÆuĪË l?? miĪČuĪÎÄÚ·eĪČsoftmaxĪōČĄĪÃĪÆĄĒļũÖŠŨRŨRĪËĪđ ĪëÖØĪßpiĪË l?? ciĪōpiĪĮÖØĪßļķĪšÍĪōČĄĪÃĪÆoĪË l?? o + uĪōWĪËĪŦĪąĪÆĄĒÆÚīýĪđĪëīðĪĻaĪČĪÎ softmax cross entropyĪōlossĪČĪđĪë 16
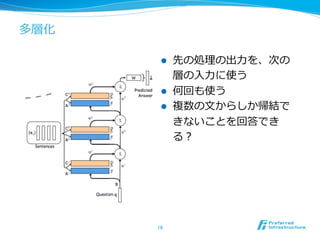
- 18. ķāÓŧŊ l?? ÏČĪÎIĀíĀíĪÎģö?ÁĶÁĶĪōĄĒīÎĪÎ ÓĪÎ?Čë?ÁĶÁĶĪËĘđĪĶ l?? šÎŧØĪâĘđĪĶ l?? Ņ}ĘýĪÎ?ÎÄĪŦĪéĪ·ĪŦĒ―YĪĮ ĪĪĘĪĪĪģĪČĪōŧØīðĪĮĪ ĪëĢŋ 18
- 20. ÖØĪßĪËĪđĪëÖÆžs l?? Adjacent l?? ÉÏÎŧëAÓĪČĪÎÖØĪßĨŲĨŊĨČĨëĪōđēÍĻĪËĪđĪë l?? Ak+t = Ck l?? B = A1 l?? ĪģĪėĪÏÖØĪßpiĪÎÓËãĪÎĪČĪĪËĄĒqĪâxĪâÍŽĪļĨĻĨó ĨģĐ`ĨÉĪōĪđĪëĪģĪČĪō?ŅÔĪÃĪÆĪĪĪë l?? Layer-wise l?? A1 = A2 = Ą l?? C1 = C2 = Ą 20 ŧųąūĄĒĪģĪÁĪéĪōĘđĪĶ
- 21. régĪËĪđĪëÕ{ÕûĢĻtemporal encodingĢĐ l?? ÐÂĪ·ĪĪÖŠŨRŨRĪōßxĪóĪĮÓûĪ·ĪĪĪÎĪĮĄĒrŋĖĪËĪ·ĪÆÖØĪßĪōĪÄ ĪąĪë l?? ĪĩĪéĪÃĪČøĪĪĪÆĪĒĪëĪŽĄĒĪģĪėĪŽĪĘĪĪĪČÐÂĪ·ĪĪĮéóĪŽÖØŌŠ ĪČĪĪĪĶĪģĪČĪŽĪïĪŦĪéĪĘĪĪĪÎĪĮĄĒļųąūĩÄĪË?īóĘÂĪĘĢĻĪ―Ī·ĪÆ ëjĪĘĢĐ?đĪ·ō 21 rŋĖĪËęĪļĪŋĨŲĨŊĨČĨëĪō?ŨãĪđ x1 = Sam walks into the kitchen x2 = Sam walks into the bedroom q = Where is Sam?
- 23. gÕZĪÎÎŧÖÃĪËĪđĪëÕ{ÕûĢĻposition encodingĢĐ l?? ÁũÁũ?ĘŊĪË gĪĘĪëÂņĪáÞzĪßĨŲĨŊĨČĨëĪÎūtšÍĪÏÝĪŽŌýĪąĪë l?? ?ÎÄÖÐĪÎÎŧÖÃĪËęĪļĪÆÖØĪßĪōĪŦĪĻĪë 23 gÕZĪīĪČĪÎÖØĪß ÎŧÖÃĪËŧųĪÅĪĪĪÆÓËã
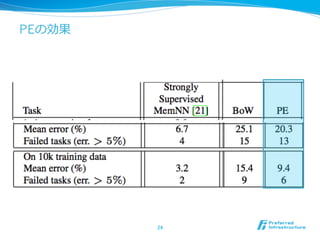
- 24. PEĪÎŋđû 24
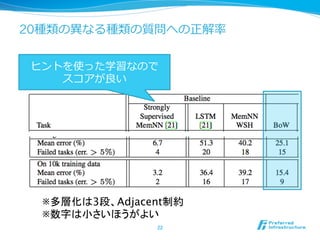
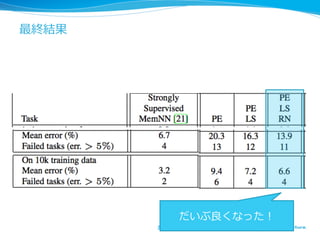
- 25. ĪĩĪéĪË?ÉŦĄĐ??? l??Linear start (LS) l?? Ņ§ÁģõÆÚĪÎķÎëAĪĮĪÏsoftmaxÓĪōiĪĪĪÆĄĒŅ§ ÁĪōÔįĪáĪë l?? Random noise (RN) l?? Ņ§ÁrĪË10%ĪÎŋÕĪÎÓĪōĪĪĪėĪë l?? ÕýtŧŊĪÎŋđûĪŽĪĒĪëĢŋ 25
- 27. ?ŅÔÕZĨâĨĮĨëĪËĪčĪëgōYĢĻĪŠĪÞĪąĢŋĢĐ l?? ?ÎÄĪÎīúĪïĪęĪËČŦēŋ?ÎÄŨÖĪĀĪČËžĪĶĢĻ g?ŌŧĪÎÂņĪáÞz ĪßĨŲĨŊĨČĨëĢĐ l?? Ų|ĪÏķĻĘýĨŲĨŊĨČĨë l?? ŧØīðĪÏīÎĪÎ gÕZ l?? ļÐŌĩÄĪËĪÏšÎ?ÎÄŨÖĮ°ĪÎ gÕZĪÎĄĒĪÉĪĶĪĪĪĶĮéóĪō ĘđĪÃĪÆīÎĪōÓčyĪđĪëĪŦŅ§ÁĪđĪë 27
- 28. ―YđûĪĀĪą 28
- 29. ËųļÐ l?? ĘÂgĪōŌĪĻĪÆŧØīðĪđĪëĄĒĪČĪĪĪĶÓ?Ų|?ŧØ īðĪÎ?ŌŧßBĪÎĨŨĨíĨŧĨđĪōend-to-endĪËĪäĪëĪČĪĪĪĶĄĒ ?·―ÏōÐÔĪō?ĘūĪ·ĪŋĪÎĪŽĨÝĨĪĨóĨČ l?? ĨŋĨđĨŊ?ŨÔĖåĪÏŌĀČŧĪČĪ·ĪÆĨČĨĪĨŋĨđĨŊĪĀĪŽĄĒÐėĄĐ ĪËŽFgĪÎĨŋĨđĨŊĪË―üĪÅĪąĪÆĪĪĪŊĪČËžĪïĪėĪë l?? ĨŌĨåĐ`ĨęĨđĨÆĨĢĨÃĨŊĪÏOĪáĪÆķāĪŊĄĒ?đĪ·ōĪÎĪ·ĪÉ ĪģĪíĪÏķāĪĪ 29
- 30. ĪÞĪČĪá l?? Ņ}ĘýĪÎ?ÎÄĪŦĪéĪĘĪëĘÂgĪŦĪéĄĒŲ|ĪËīðĪĻĪëĨŋĨđ ĨŊĪōĄĒend-to-endĪĮŅ§ÁĪđĪë?ĘÖ·ĻĪōĖá°ļĪ·Īŋ l?? gÕZĪÎÂņĪáÞzĪߥĒ?ÎÄĪÎĨĻĨóĨģĐ`ĨÉĄĒļũĘÂgĪË ĪđĪëattentionĄĒŧØīðĪÎ?ÉúģÉĪÞĪĮĪō g?ŌŧĪÎĨÍĨÃĨČ ĨïĐ`ĨŊĪËĪđĪë l?? ĨČĨĪĨŋĨđĨŊĪĀĪŽĄĒÆ―ūųĨĻĨéĐ`ÂĘÂĘÂĘ6%ģĖķČķČĪÞĪĮß_ģÉ Ī·Īŋ l?? ĨŌĨåĐ`ĨęĨđĨÆĨĢĨÃĨŊĪÏOĪáĪÆķāĪĪ 30