






![12/50
•–•Æ•Û•∞§Œ’`≤Ó‘uÅ˝
Ãÿ§À’`≤Ó§Œ∆Ωæ˘§¨ 0 §«üoœ‡Èv§«§¢§Î£¨§π§ §Ô§¡
E [¶≈m (x)] = 0 (14.12)
cov (¶≈m (x) , ¶≈ (x)) = E [¶≈m (x) ¶≈ (x)] = 0, m = (14.13)
§¨≥…§Í¡¢§ƒ§ §È§– 1
ECOM = E
?
? 1
M
M
m=1
¶≈m (x)
2
?
?
=
1
M2
E
M
m=1
(¶≈m (x))
2
=
1
M
EAV (14.14)
§»§ §Í£¨’`≤Ó§Œ∆⁄¥˝Ç駨¥Û∑˘§ÀµÕúp§µ§Ï§Î£Æ
1 Õ¨§∏§Ë§¶§ •‚•«•Î§Ú£¨Õ¨§∏§Ë§¶§ ”ñæö•«©`•ø§«—ߡ淋§ª§∆§§§Î§Œ§¿§´§È£¨§≥§Û§ §≥§»§œ
∆⁄¥˝§«§≠§ §§£Æ](https://image.slidesharecdn.com/prml14-150925085543-lva1-app6892/85/PRML-14-12-320.jpg)






![22/50
•÷©`•π•∆•£•Û•∞§Œ§ø§·§Œ’`≤ÓÈv ˝
“‘œ¬§Œ÷∏ ˝’`≤Ó§Úøº§®§Î£Æ
E [exp (?ty (x))] =
t° {?1,1}
exp (?ty (x)) p (t|x) p (x) dx (14.27)
â‰∑÷∑®§Ú π§√§∆ y §À§ƒ§§§∆…œ Ω§Ú◊Ó–°ªØ§π§Î£Æ
?t (y) := exp (?ty (x)) p (t|x) p (x) §»§π§Î£ÆÕ£¡Ùµ„§œ“‘œ¬§Œ§Ë§¶§À«Û§·
§È§Ï§Î£Æ
t° {?1,1}
Dy?t (y) = 0
exp (y (x)) p (t = ?1|x) ? exp (?y (x)) p (t = 1|x) = 0
y (x) =
1
2
log
p (t = 1|x)
p (t = ?1|x)
(14.28)
§ƒ§fi§Í AdaBoost §œ÷¥Œµƒ§À p (t = 1|x) §» (t = ?1|x) §Œ±»§Œåù ˝§ŒΩ¸
À∆§Ú«Û§·§∆§§§Î£Æ§≥§Ï§¨◊ÓΩKµƒ§À (14.19) §«∑˚∫≈Èv ˝§Ú π§√§∆∑÷Óê∆˜§Ú
◊˜§√§ø¿Ì”…§»§ §√§∆§§§Î£Æ](https://image.slidesharecdn.com/prml14-150925085543-lva1-app6892/85/PRML-14-22-320.jpg)

















PRML µ⁄14’¬
- 1. 1/50 PRML µ⁄ 14 ’¬ åmù…°°±Ú æt∫œ—–æø¥Û—ß‘∫¥Û—ß ≤© ø«∞∆⁄ miyazawa-a@nii.ac.jp September 25, 2015 (modi?ed: October 4, 2015)
- 2. 2/50 §œ§∏§·§À §≥§Œ•π•È•§•…§Œ LuaLATEX §Œ•Ω©`•π•≥©`•…§œ https://github.com/pecorarista/documents §À§¢§Í§fi§π£Æ ΩÃø∆ﯧ»§œ»Ù∏…Æê§ §Î±Ì”õ§Ú§∑§∆§§§Îàˆ∫œ§¨§¢§Í§fi§π£Æ á̧œ TikZ §«√˧§§ø§‚§Œ§Ú≥˝§≠£¨Bishop (2006) §Œ•µ•›©`•»•⁄©` •∏ http://research.microsoft.com/en-us/um/people/ cmbishop/prml/ §fi§ø§œ Murphy (2012) §Œ•µ•›©`•»•⁄©`•∏ http://www.cs.ubc.ca/~murphyk/MLbook/ §´§È“˝”√§∑§∆§§§fi§π£Æ Ègfl`§√§ø”õ ˆ§Ú“䧃§±§ø∑Ω§œflBΩj§Ø§¿§µ§§£Æ
- 3. 3/50 ΩÒ»’§‰§Î§≥§» 1. •Ÿ•§•∫•‚•«•Î∆Ωæ˘ªØ 2. •≥•fl•√•∆•£ 3. •÷©`•π•∆•£•Û•∞ (AdaBoost) ∑÷Óê ªÿé¢ 4. ƒæòã‘Ï•‚•«•Î (CART) ªÿé¢ ∑÷Óê 5. Ãıº˛∏∂§≠ªÏ∫œ•‚•«•Î
- 5. 5/50 •‚•«•Î§ŒΩY∫œ •‚•«•Î§ŒΩY∫œ§»•Ÿ•§•∫•‚•«•Î∆Ωæ˘ªØ§ÚªÏÕ¨§∑§ §§§Ë§¶§À◊¢“‚§π§Î£Æ §fi§∫§œ•‚•«•ÎΩY∫œ§Œ¿˝§»§∑§∆£¨ªÏ∫œ•¨•¶•π∑÷≤º§Œ√‹∂»Õ∆∂®§Úøº§®§Î£Æ•‚ •«•Î§œ£¨•«©`•ø§¨§…§ŒªÏ∫œ“™Àÿ§´§È…˙≥…§µ§Ï§ø§´§Ú æ§π«±‘⁄≠˝ z §Ú π§√§∆£¨Õ¨ïr¥_¬ p (x, z) §«”Χ®§È§Ï§Î£Æ”Qúy≠˝ x §Œ√‹∂»§œ p (x) = z p (x, z) (14.3) = K k=1 ¶–kN (x|?k, ¶≤k) (14.4) §»§ §Î£Æ•«©`•ø X = (x1, . . . , xN ) §ÀÈv§π§Î÷‹fix∑÷≤º§œ p (X) = N n=1 p (xn) = N n=1 zn p (xn, zn) (14.5) §«§¢§Í£¨∏˜ xn §Àåù§∑§∆ zn §¨¥Ê‘⁄§∑§∆§§§Î§≥§»§¨§Ô§´§Î£Æ
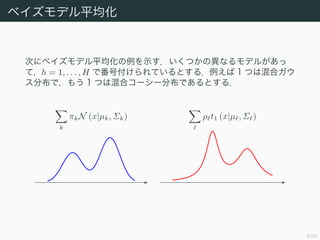
- 6. 6/50 •Ÿ•§•∫•‚•«•Î∆Ωæ˘ªØ ¥Œ§À•Ÿ•§•∫•‚•«•Î∆Ωæ˘ªØ§Œ¿˝§Ú æ§π£Æ§§§Ø§ƒ§´§ŒÆê§ §Î•‚•«•Î§¨§¢§√ §∆£¨h = 1, . . . , H §«∑¨∫≈∏∂§±§È§Ï§∆§§§Î§»§π§Î£Æ¿˝§®§– 1 §ƒ§œªÏ∫œ•¨•¶ •π∑÷≤º§«£¨§‚§¶ 1 §ƒ§œªÏ∫œ•≥©`•∑©`∑÷≤º§«§¢§Î§»§π§Î£Æ k ¶–kN (x|?k, ¶≤k) ¶— t1 (x|? , ¶≤ )
- 7. 7/50 •Ÿ•§•∫•‚•«•Î∆Ωæ˘ªØ •‚•«•Î§ÀÈv§π§Î ¬«∞¥_¬ §¨ p (h) §«”Χ®§È§Ï§∆§§§Î§ §È§–£¨•«©`•ø§ÀÈv §π§Î÷‹fix∑÷≤º§œ¥Œ Ω§««Û§·§È§Ï§Î£Æ p (X) = H h=1 p (X|h) p (h) (14.6) •‚•«•ÎΩY∫œ§»§Œfl`§§§œ£¨•«©`•ø§Ú…˙≥…§∑§∆§§§Î§Œ§œ•‚•«•Î h = 1, . . . , H §Œ§…§Ï§´ 1 §ƒ§¿§»§§§¶§≥§»§«§¢§Î£Æ
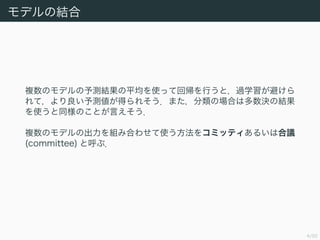
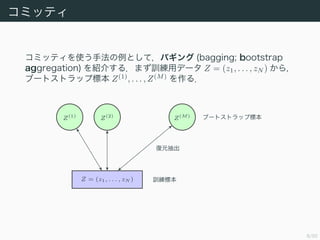
- 8. 8/50 •≥•fl•√•∆•£ •≥•fl•√•∆•£§Ú 𧶠÷∑®§Œ¿˝§»§∑§∆£¨•–•Æ•Û•∞ (bagging; bootstrap aggregation) §ÚΩBΩȧπ§Î£Æ§fi§∫”ñæö”√•«©`•ø Z = (z1, . . . , zN ) §´§È£¨ •÷©`•»•π•»•È•√•◊òÀ±æ Z(1) , . . . , Z(M) §Ú◊˜§Î£Æ Z(1) Z(2) Z(M) Z = (z1, . . . , zN ) èÕ‘™≥È≥ˆ •÷©`•»•π•»•È•√•◊òÀ±æ ”ñæöòÀ±æ
- 9. 9/50 •≥•fl•√•∆•£ •–•Æ•Û•∞§À§™§±§Î•≥•fl•√•∆•£§Œ”ËúyÇé yCOM (x) §œ£¨∏˜•÷©`•»•π•»•È•√ •◊ºØ∫œ Z(1) , . . . , Z(M) §«—ß¡ï§∑§ø•‚•«•Î§Œ”Ëúy y1 (x) , . . . , yM (x) §Ú π§√§∆ yCOM (x) = 1 M M m=1 ym (x) (14.7) §»§ §Î£Æ §≥§Ï§«ågÎH§À¡º§§ΩYπ˚§¨µ√§È§Ï§Î§Œ§´£¨’`≤Ó§Ú‘uÅ˝§∑§∆¥_’J§π§Î£Æ
- 10. 10/50 •–•Æ•Û•∞§Œ’`≤Ó‘uÅ˝ ”Ëúy§∑§ø§§ªÿé¢Èv ˝§Ú h (x) §»§∑£¨∏˜•‚•«•Î§Œ”ËúyÇé ym (x) §¨£¨h (x) §»º”∑®µƒ§ ’`≤Ó ¶≈m (x) §Ú π§√§∆ ym (x) = h (x) + ¶≈m (x) (14.8) §»±Ì§ª§Î§»Å¢∂®§π§Î£Æ§≥§Œ§»§≠£¨∂˛Å\’`≤Ó§œ E (ym (x) ? h (x)) 2 = E (¶≈m (x)) 2 (14.9) §»§ §Î§Œ§«£¨∆Ωæ˘∂˛Å\’`≤Ó§Œ∆⁄¥˝Çé EAV §œ EAV := E 1 M M m=1 (ym (x) ? h (x)) 2 = 1 M M m=1 E (¶≈m (x)) 2 (14.10) §««Û§·§È§Ï§Î£Æ
- 11. 11/50 •–•Æ•Û•∞§Œ’`≤Ó‘uÅ˝ “ª∑Ω£¨•≥•fl•√•∆•£§À§Ë§Î≥ˆ¡¶§À§ƒ§§§∆£¨’`≤Ó§Œ∆⁄¥˝Çé ECOM §œ ECOM := E ? ? 1 M M m=1 ym ? h (x) 2 ? ? = E ? ? 1 M M m=1 ¶≈m (x) 2 ? ? (14.11) §»«Û§·§È§Ï§Î£Æ•Ÿ•Ø•»•Î (1 °§ °§ °§ 1) ° RM §» (¶≈1 (x) °§ °§ °§ ¶≈m (x)) ° RM §Àåù§∑§∆ Cauchy-Schwarz §Œ≤ªµ» Ω§Ú”√§§§Î§» M m=1 ¶≈m (x) 2 °‹ M M m=1 (¶≈m (x)) 2 ECOM °‹ EAV §¨≥…§Í¡¢§ƒ£Æ§ƒ§fi§Í•≥•fl•√•∆•£§Ú π§¶àˆ∫œ§Œ’`≤Ó§Œ∆⁄¥˝Ç駜£¨òã≥…“™Àÿ §Œ’`≤Ó§Œ∆⁄¥˝Ç駌∫Õ§Ú≥¨§®§ §§£Æ
- 12. 12/50 •–•Æ•Û•∞§Œ’`≤Ó‘uÅ˝ Ãÿ§À’`≤Ó§Œ∆Ωæ˘§¨ 0 §«üoœ‡Èv§«§¢§Î£¨§π§ §Ô§¡ E [¶≈m (x)] = 0 (14.12) cov (¶≈m (x) , ¶≈ (x)) = E [¶≈m (x) ¶≈ (x)] = 0, m = (14.13) §¨≥…§Í¡¢§ƒ§ §È§– 1 ECOM = E ? ? 1 M M m=1 ¶≈m (x) 2 ? ? = 1 M2 E M m=1 (¶≈m (x)) 2 = 1 M EAV (14.14) §»§ §Í£¨’`≤Ó§Œ∆⁄¥˝Ç駨¥Û∑˘§ÀµÕúp§µ§Ï§Î£Æ 1 Õ¨§∏§Ë§¶§ •‚•«•Î§Ú£¨Õ¨§∏§Ë§¶§ ”ñæö•«©`•ø§«—ߡ淋§ª§∆§§§Î§Œ§¿§´§È£¨§≥§Û§ §≥§»§œ ∆⁄¥˝§«§≠§ §§£Æ
- 13. 13/50 •÷©`•π•∆•£•Û•∞ •≥•fl•√•∆•£§Ú 𧶠÷∑®§ŒÑe§ ¿˝§»§∑§∆£¨•÷©`•π•∆•£•Û•∞ (boosting) §» ∫Ù§–§Ï§Î ÷∑®§ÚΩBΩȧπ§Î£Æ•÷©`•π•∆•£•Û•∞§œ∑÷Ó꧌§ø§·§Œ•¢•Î•¥•Í•∫•‡ §»§∑§∆‘O”㧵§Ï§ø§¨£¨ªÿ颧À§‚íàè৫§≠§Î£Æ§»§Í§¢§®§∫∑÷Óê§À§ƒ§§§∆øº §®§Î£Æ •≥•fl•√•∆•£§Úòã≥…§π§ÎÇÄ°©§Œ∑÷Óê∆˜§œ•Ÿ©`•π—ß¡ï∆˜ (base learner) §fi §ø§œ»ı—ß¡ï∆˜ (weak learner) §»∫Ù§–§Ï§Î£Æ•÷©`•π•∆•£•Û•∞§œ£¨»ı—ß¡ï ∆˜§Ú£®ÅK¡–µƒ§À§«§œ§ §Ø£©÷¥Œµƒ§À£¨÷ÿ§fl∏∂§≠•«©`•ø§Ú π§√§∆—ß¡ï§ÚflM §·§Î∑Ω∑®§«§¢§Î£Æ÷ÿ§fl§Œ¥Û§≠§µ§œ£¨§Ω§Ï“‘«∞§À’`§√§∆∑÷Ó꧵§Ï§ø•«©`•ø §Àåù§∑§∆¥Û§≠§Ø§ §Î§Ë§¶§À∂®§·§Î£Æ •÷©`•π•∆•£•Û•∞§Œ÷–§«¥˙±Ìµƒ§ ÷∑®§«§¢§Î AdaBoost (adaptive boosting) §ÚΩBΩȧπ§Î£Æ
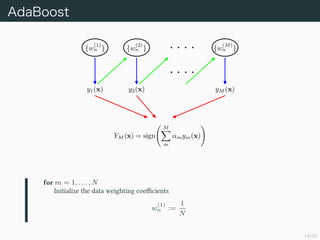
- 14. 14/50 AdaBoost {w (1) n } {w (2) n } {w (M) n } y1(x) y2(x) yM (x) YM (x) = sign M m ¶¡mym(x) for m = 1, . . . , N Initialize the data weighting coe?cients w (1) n := 1 N
- 15. 15/50 AdaBoost for m = 1, . . . , M Fit a classi?er ym (x) to the training data by minimizing Jm := N n=1 w (m) n 1{x | ym(x)=tn} (xn) . (14.15) Evaluate ¶¡m := log 1 ? ¶≈m ¶≈m (14.17) where ¶≈m := N n=1 w (m) n 1{x | ym(x)=tn} (xn) N n=1 w (m) n . (14.15) Update the data weighting coe?cients w (m+1) n := w (m) n exp ¶¡m1{x|ym(xn)=tn} (xn) . (14.18)
- 16. 16/50 AdaBoost Make predictions using the ?nal model, which is given by YM (x) := sign M m=1 ¶¡mym (x) . (14.19) §≥§Œ•¢•Î•¥•Í•∫•‡÷–§À¨F§Ï§Î Ω§œ£¨÷∏ ˝’`≤Ó§Œ÷¥Œµƒ§ ◊Ó–°ªØ§´§Èåߧ´ §Ï§Î£Æ
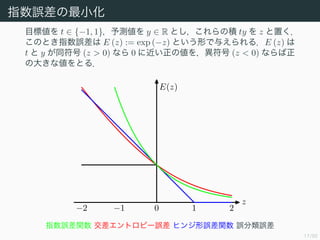
- 17. 17/50 ÷∏ ˝’`≤Ó§Œ◊Ó–°ªØ ƒøòÀÇé§Ú t ° {?1, 1}£¨”ËúyÇé§Ú y ° R §»§∑£¨§≥§Ï§È§Œ∑e ty §Ú z §»÷√§Ø£Æ §≥§Œ§»§≠÷∏ ˝’`≤Ó§œ E (z) := exp (?z) §»§§§¶–Œ§«”Χ®§È§Ï§Î£ÆE (z) §œ t §» y §¨Õ¨∑˚∫≈ (z > 0) § §È 0 §ÀΩ¸§§’˝§ŒÇé§Ú£¨Æê∑˚∫≈ (z < 0) § §È§–’˝ §Œ¥Û§≠§ Çé§Ú§»§Î£Æ ?2 ?1 0 1 2 z E(z) ÷∏ ˝’`≤ÓÈv ˝ Ωª≤Ó•®•Û•»•Ì•‘©`’`≤Ó •“•Û•∏–Œ’`≤ÓÈv ˝ ’`∑÷Óê’`≤Ó
- 18. 18/50 ÷∏ ˝’`≤Ó§Œ◊Ó–°ªØ “‘œ¬§Œ’`≤Ó E §Ú◊Ó–°ªØ§∑§ø§§£Æ E := N n=1 exp ?tn m =1 1 2 ¶¡ y (xn) ÷¥Œµƒ§À—ß¡ï§∑§∆§§§Ø§Œ§« ¶¡1, . . . , ¶¡m?1 §» y1 (x) , . . . , ym?1 (x) §œÀ˘”Î §»§∑§∆£¨¶¡m §» ym (x) §ÀÈv§∑§∆ E §Ú◊Ó–°ªØ§π§Î£ÆE §Ú E = N n=1 exp ?tn m?1 =1 1 2 ¶¡ y (xn) ? 1 2 tn¶¡mym (xn) = N n=1 w(m) n exp ? 1 2 tn¶¡mym (xn) (14.22) §»ï¯§≠ìQ§®§Î£Æ§≥§≥§«“‘œ¬§Œ§Ë§¶§À÷√§§§ø£Æ w(m) n := exp ?tn m?1 =1 1 2 ¶¡ y (xn) (14.22 )
- 19. 19/50 ÷∏ ˝’`≤Ó§Œ◊Ó–°ªØ ym : x °˙ {?1, 1} §À§Ë§√§∆’˝§∑§Ø∑÷Ó꧵§Ï§ø•«©`•øµ„§ŒÃÌ◊÷ºØ∫œ§Ú Tm£¨ ’`§√§∆∑÷Ó꧵§Ï§ø•«©`•ø§ŒÃÌ◊÷ºØ∫œ§Ú Mm §»§π§Î£Æ§≥§Œ§»§≠ E = e?¶¡m/2 n° Tm w(m) n + e¶¡m/2 n° Mm w(m) n = e¶¡m/2 ? e?¶¡m/2 N n=1 w(m) n 1{x|ym(xn)=tn} (xn) + e?¶¡m/2 N n=1 w(m) n (14.23) §¨≥…§Í¡¢§ƒ£Æ§≥§Ï§Ú ym (x) §À§ƒ§§§∆◊Ó–°ªØ§π§Î§≥§»§œ (14.15) §Ú◊Ó–°ªØ §π§Î§≥§»§»Õ¨Ç駫§¢§Î£Æ
- 20. 20/50 ÷∏ ˝’`≤Ó§Œ◊Ó–°ªØ §fi§ø ¶¡m §À§ƒ§§§∆Œ¢∑÷§∑§∆ 0 §»÷√§Ø§» e¶¡m/2 + e?¶¡m/2 N n=1 w(m) n 1{x|ym(xn)=tn} (xn) ? e?¶¡m/2 N n=1 w(m) n = 0 e¶¡m + 1 = N n=1 w(m) n N n=1 w(m) n 1{x|ym(xn)=tn} (xn) §»§ §Î£Æ(14.15) §»Õ¨§∏÷√§≠ìQ§®§Ú––§¶§≥§»§À§Ë§Í ¶¡m = log 1 ? ¶≈m ¶≈m §Úµ√§Î£Æ§≥§Ï§œ•¢•Î•¥•Í•∫•‡÷–§Œ (14.17) §Àµ»§∑§§£Æ
- 21. 21/50 ÷∏ ˝’`≤Ó§Œ◊Ó–°ªØ ÷ÿ§fl§œ (14.22 ) §Àè槧¥Œ§Œ§Ë§¶§À∏¸–¬§π§Î£Æ w(m+1) n = w(m) n exp ? 1 2 tn¶¡mym (xn) (14.24) §≥§≥§« tnym (xn) = 1 ? 21{x|ym(x)=tn} (xn) (14.25) §¨≥…§Í¡¢§ƒ§≥§»§Ú 𧶧» w(m+1) n = w(x) n exp ? 1 2 ¶¡m 1 ? 21{x|ym(x)=tn} (xn) = w(x) n exp ? ¶¡m 2 exp 1{x|ym(x)=tn} (xn) (14.26) §»ï¯§≠ìQ§®§È§Ï§Î£Æexp (?¶¡m/2) §œ§π§Ÿ§∆§Œ•«©`•ø§Àπ≤Õ®§ §Œ§«üo“ï§π §Î§» (14.18) §¨µ√§È§Ï§Î£Æ
- 22. 22/50 •÷©`•π•∆•£•Û•∞§Œ§ø§·§Œ’`≤ÓÈv ˝ “‘œ¬§Œ÷∏ ˝’`≤Ó§Úøº§®§Î£Æ E [exp (?ty (x))] = t° {?1,1} exp (?ty (x)) p (t|x) p (x) dx (14.27) â‰∑÷∑®§Ú π§√§∆ y §À§ƒ§§§∆…œ Ω§Ú◊Ó–°ªØ§π§Î£Æ ?t (y) := exp (?ty (x)) p (t|x) p (x) §»§π§Î£ÆÕ£¡Ùµ„§œ“‘œ¬§Œ§Ë§¶§À«Û§· §È§Ï§Î£Æ t° {?1,1} Dy?t (y) = 0 exp (y (x)) p (t = ?1|x) ? exp (?y (x)) p (t = 1|x) = 0 y (x) = 1 2 log p (t = 1|x) p (t = ?1|x) (14.28) §ƒ§fi§Í AdaBoost §œ÷¥Œµƒ§À p (t = 1|x) §» (t = ?1|x) §Œ±»§Œåù ˝§ŒΩ¸ À∆§Ú«Û§·§∆§§§Î£Æ§≥§Ï§¨◊ÓΩKµƒ§À (14.19) §«∑˚∫≈Èv ˝§Ú π§√§∆∑÷Óê∆˜§Ú ◊˜§√§ø¿Ì”…§»§ §√§∆§§§Î£Æ
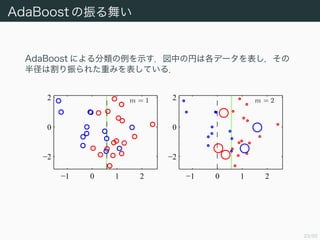
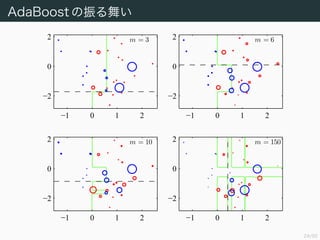
- 23. 23/50 AdaBoost §Œ’ҧΌ˧§ AdaBoost §À§Ë§Î∑÷Ó꧌¿˝§Ú æ§π£ÆáÌ÷–§ŒÉ“§œ∏˜•«©`•ø§Ú±Ì§∑£¨§Ω§Œ ∞Îæ∂§œ∏ӧ͒ҧȧϧø÷ÿ§fl§Ú±Ì§∑§∆§§§Î£Æ m = 1 ?1 0 1 2 ?2 0 2 m = 2 ?1 0 1 2 ?2 0 2
- 24. 24/50 AdaBoost §Œ’ҧΌ˧§ m = 3 ?1 0 1 2 ?2 0 2 m = 6 ?1 0 1 2 ?2 0 2 m = 10 ?1 0 1 2 ?2 0 2 m = 150 ?1 0 1 2 ?2 0 2
- 25. 25/50 AdaBoost §Œíàèà AdaBoost §œ Freund and Schapire (1996) §«å߻Χµ§Ï§ø§¨£¨÷∏ ˝ ’`≤Ó§Œ÷¥Œµƒ◊Ó–°ªØ§»§∑§∆§ŒΩ‚·ã§œ Friedman et al. (2000) §«”Χ®§È §Ï§ø£Æ§≥§Ï“‘Ωµ£¨’`≤ÓÈv ˝§Œâ‰∏¸§À§Ë§Íòî°©§ íàè২––§Ô§Ï§Î§Ë§¶§À § §√§ø£Æ
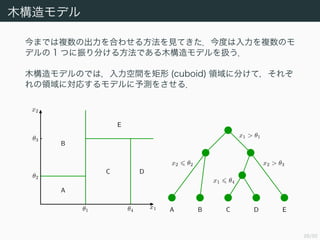
- 26. 26/50 ƒæòã‘Ï•‚•«•Î ΩÒ§fi§«§œ—} ˝§Œ≥ˆ¡¶§Ú∫œ§Ô§ª§Î∑Ω∑®§Ú“ä§∆§≠§ø£ÆΩÒ∂»§œ»Î¡¶§Ú—} ˝§Œ•‚ •«•Î§Œ 1 §ƒ§À’Ò§Í∑÷§±§Î∑Ω∑®§«§¢§Îƒæòã‘Ï•‚•«•Î§ÚíQ§¶£Æ ƒæòã‘Ï•‚•«•Î§Œ§«§œ£¨»Î¡¶ø’Èg§Úæÿ–Œ (cuboid) ÓI”Ú§À∑÷§±§∆£¨§Ω§Ï§æ §Ï§ŒÓI”Ú§Àåùèͧπ§Î•‚•«•Î§À”Ëúy§Ú§µ§ª§Î£Æ A B C D E ¶»1 ¶»4 ¶»2 ¶»3 x1 x2 x1 > ¶»1 x2 > ¶»3 x1 ¶»4 x2 ¶»2 A B C D E
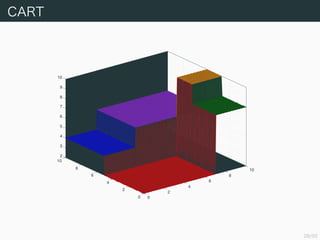
- 27. 27/50 CART “‘œ¬§«§œƒæòã‘Ï•‚•«•Î§Œ 1 §ƒ§«§¢§Î CART (classi?cation and regression tree) §ÚíQ§¶£ÆCART §œ√˚«∞§ŒÕ®§Í∑÷Óê§À§‚ªÿ颧À§‚ 𧶠§≥§»§¨§«§≠§Î§¨£¨§fi§∫§œªÿ颧ÀΩg§√§∆’h√˜§π§Î£Æ »Î¡¶§»ƒøòÀÇ駌ΩM D = (x1, tn) , . . . , (xN , tN ) ° RD °¡ R §¨”Χ®§È§Ï§∆ §§§Î§»§π§Î£Æ»Î¡¶§Àåù§π§Î∑÷∏Ó§¨ R1, . . . , RM §»§ §√§∆§§§Î§»§≠£¨”Ëúy Çé§Ú¥Œ§Œ§Ë§¶§À∂®¡x§π§Î£Æ f (x) := M m=1 cm1Rm (x)
- 29. 29/50 ∑÷∏Ó§¨”Χ®§È§Ï§∆§§§Î§»§≠§Œ◊Óflm§ ”ËúyÇé ∏˜ÓI”Ú§«∂˛Å\∫Õ’`≤Ó§Ú◊Ó–°ªØ§π§Î”ËúyÇé§Ú«Û§·§Ë§¶£Æ Im := {n ; xn ° Rm} §»±Ì§π§»’`≤Ó§œ“‘œ¬§Œ§Ë§¶§À§ §Î£Æ N n=1 (tn ? f (xn)) 2 = N n=1 tn ? M m=1 cm1Rm (xn) 2 = M m=1 n° Im (cm ? tn) 2 ∏˜ cm §À§ƒ§§§∆Œ¢∑÷§∑§∆ 0 §»÷√§Ø§»£¨◊Óflm§ ”ËúyÇ駜 ?cm = 1 |Im| n° Im tn §»§ §Î§≥§»§¨∑÷§´§Î£Æ§ø§¿§∑∂˛Å\∫Õ’`≤Ó§Ú◊Ó–°ªØ§π§Î§Ë§¶§ ∑÷∏Ó§ÚõQ§· §Ë§¶§»§π§Î§»”ãÀ„¡ø§¨¥Û§≠§Ø§ §Î£Æ§Ω§≥§«ÿù”˚∑®§Ú π§√§∆ƒæ§Œòã‘ϧÚ∂® §·§Î£Æ
- 30. 30/50 ∑÷∏Óª˘ú ∏˜ªÿ§ŒÓI”Ú§Œ∑÷∏Óª˘ú §Úøº§®§Î£Æ≠˝§Ú±Ì§πÃÌ◊÷§Ú j ° {1, . . . , D}£¨Èì Çé§Ú ¶» §»§∑§∆£¨2 §ƒ§ŒÓI”Ú R1 (j, ¶») §» R2 (j, ¶») §Ú¥Œ§«∂®§·§Î£Æ R1 (j, ¶») = {x ; xj °‹ ¶»} , R2 (j, ¶») = {x ; xj > ¶»} Ii (j, ¶») := {n ; xn ° Ri (j, ¶»)} §»§π§Î£Æ∑÷∏Ó§Œª˘ú §»§ §Î (j, ¶») §œ¥Œ§Ú Ω‚§§§∆µ√§È§Ï§Î£Æ min j° {1,...,D} min ¶» ? ? ? min c1 n° I1(j,¶») (c1 ? tn) 2 + min c2 n° I2(j,¶») (c2 ? tn) 2 ? ? ? . ƒ⁄Ç»§Œ∫Õ§Ú◊Ó–°ªØ§π§Î c1 §» c2 §œ£¨§Ω§Ï§æ§Ï ?c1 = 1 |I1 (j, ¶»)| n° I1(j,¶») tn, ?c2 = 1 |I2 (j, ¶»)| n° I2(j,¶») tn §»§ §Î£Æ§¢§»§œ∏˜ j §À§ƒ§§§∆◊Óflm§ ¶» §Ú”ãÀ„§∑£¨§Ω§Œ§¢§»§«◊Óflm§ j §Ú «Û§·§Ï§–§Ë§§£Æ
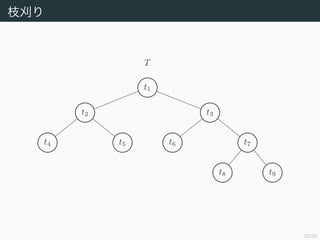
- 32. 32/50 ÷¶ÿ◊§Í T t1 t2 t3 t4 t5 t6 t7 t8 t9
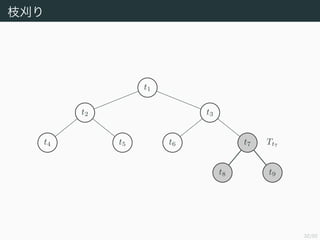
- 33. 32/50 ÷¶ÿ◊§Í t1 t2 t3 t4 t5 t6 Tt7t7 t8 t9
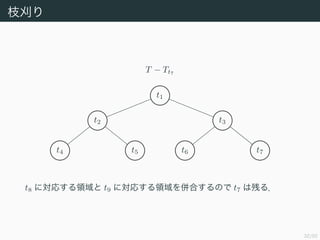
- 34. 32/50 ÷¶ÿ◊§Í T ? Tt7 t1 t2 t3 t4 t5 t6 t7 t8 §Àåùèͧπ§ÎÓI”Ú§» t9 §Àåùèͧπ§ÎÓI”Ú§ÚÅ„∫œ§π§Î§Œ§« t7 §œ≤–§Î£Æ
- 35. 33/50 ÷¶ÿ◊§Í§Œª˘ú «–§Í¬‰§»§πŒª÷√§œ£¨¥Œ§Œ error-complexity measure R¶¡ (T) = R (T) + ¶¡ T §¨“ª∑¨¥Û§≠§Øúp…Ÿ§π§Î§Ë§¶§ πùµ„ t §Úflx§÷£Æ§ø§¿§∑ T §œƒæ T §Œ»~»´Ã §ŒºØ∫œ£¨R (T) §œ’`≤Ó R (T) := T m=1 n° Im (?cm ? tn) 2 §«§¢§Î£Æ¶¡ °› 0 §œ÷¶§Œ ˝§Àåù§π§Î¡PÑt§Ú’{’˚§π§Î•—•È•·©`•ø§«§¢§Î£Æ§≥ §Œª˘ú §«§œ£¨ÿ◊§√§∆§‚£®Õ®≥£¥Û§≠§Ø§ §√§∆§∑§fi§¶£©’`≤Ó§¨§¢§fi§Í¥Û§≠§Ø § §È§∫£¨»~§Œ ˝§¨úp§Î§Ë§¶§ ÷¶ÿ◊§Í§¨Éûœ»§∑§∆––§Ô§Ï§Î£Æ
- 36. 34/50 ÷¶ÿ◊§Í§Œª˘ú ¶¡ §ÚÑ”§´§π§»¥Œ§Œ§Ë§¶§ §≥§»§¨§Ô§´§Î£Æ ¶¡ = 0 §Œ§»§≠ ∏˜•«©`•ø§À 1 §ƒ§Œ»~§Úåùèͧµ§ª§Î§Ë§¶§ ƒæ§¨◊Óflm§À§ §Î£Æ ¶¡ §¨¥Û§≠§§§»§≠ ∏˘ t1 §¿§±§´§È≥…§Îƒæ§¨◊Óflm§À§ §Î£Æ §¡§Á§¶§…§§§§ƒæ§œ§≥§ŒÈg§À§¢§Î£Æ
- 37. 35/50 ÷¶ÿ◊§Í ≤ø∑÷ƒæ Tt §»πùµ„ t §´§Èœ¬§Úÿ◊§√§∆§«§≠§Îƒæ ({t} , ?) §Œ error-complexity measure §œ§Ω§Ï§æ§Ï R¶¡ (Tt) = R (Tt) + ¶¡ Tt , R¶¡ (({t} , ?)) = R (({t} , ?)) + ¶¡ §«§¢§Î£ÆR¶¡ (Tt) > R¶¡(({t} , ?))£¨§π§ §Ô§¡ ¶¡ < R (Tt) ? R (({t} , ?)) Tt ? 1 §¨≥…§Í¡¢§ƒ§ §È§–ÿ◊§Í»°§√§ø§€§¶§¨§Ë§§£Æ§≥§Œ”“fix§Úÿ◊§Í»°§ÎÑøπ˚§Œ÷∏ òÀ§»§∑ g (t ; T) := R (Tt) ? R (({t} , ?)) Tt ? 1 §»∂®§·§Î£Æ
- 38. 36/50 ÷¶ÿ◊§Í ¥Œ§Œ◊Ó»ı•Í•Û•Ø÷¶ÿ◊§Í (weakest link pruning) §»∫Ù§–§Ï§Î•¢•Î•¥•Í•∫ •‡§À§Ë§Í T0 °§ °§ °§ TJ = ({t1} , ?) §»œ¡¡xÖg’{âດ¡– ¶¡0 < °§ °§ °§ < ¶¡J §Úµ√§Î£Æ 1: i °˚ 0 2: while Ti > 1 3: ¶¡i °˚ min t° V (T i)T i g t ; Ti 4: T i °˚ arg min t° V (T i)T i g t ; Ti 5: for t ° T i 6: Ti °˚ Ti ? Ti t 7: i °˚ i + 1
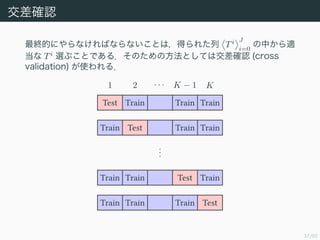
- 39. 37/50 Ωª≤Ó¥_’J ◊ÓΩKµƒ§À§‰§È§ §±§Ï§–§ §È§ §§§≥§»§œ£¨µ√§È§Ï§ø¡– Ti J i=0 §Œ÷–§´§Èflm µ±§ Ti flx§÷§≥§»§«§¢§Î£Æ§Ω§Œ§ø§·§Œ∑Ω∑®§»§∑§∆§œΩª≤Ó¥_’J (cross validation) §¨ π§Ô§Ï§Î£Æ Test Train Train Train Train Test Train Train ... Train Train Test Train Train Train Train Test 1 2 °§ °§ °§ K ? 1 K
- 40. 38/50 Ωª≤Ó¥_’J ÷Ìò§œ“‘œ¬§Œ§Ë§¶§À§ §Î£Æ 1: •«©`•ø D §Ú π§√§∆£¨ƒæ§Œ¡– Ti J i=0 §»•—•È•·©`•ø§Œ¡– ¶¡i J i=0 §Ú ◊˜§Î£Æ 2: •«©`•ø D §Ú D = K k=1 Dk §»∑÷∏Ó§π§Î£ÆòO¡¶£¨∏˜ |Dk| §¨Õ¨§∏¥Û§≠§µ §À§ §Î§Ë§¶§À§π§Î£Æ 3: ∏˜ D(k) := DDk §Ú 𧧣¨ƒæ§Œ¡– T(k)i ik i=0 §»•—•È•·©`•ø§Œ¡– ¶¡ (k) i ik i=0 §Ú◊˜§Î£Æ
- 41. 39/50 Ωª≤Ó¥_’J 4: ∏˜ ¶¡i := °Ã ¶¡i¶¡i+1 §Àåù§∑§∆ R¶¡i (T) §Ú◊Ó–°ªØ§π§Î§Ë§¶§ T(1) (¶¡i) , . . . , T(K) (¶¡i) §»§Ω§Ï§È§Àåùèͧπ§Î”Ëúy y (1) i , . . . , y (K) i §Ú«Û §·§Î£Æ§≥§≥§« ¶¡ ° ¶¡ (k) i , ¶¡ (k) i+1 § §È§– T(k) (¶¡) = T(k)i §»§ §Î§≥§» §À◊¢“‚§π§Î£Æ 5: ΩÒ§fi§«§ŒΩYπ˚§´§È“‘œ¬§Ú«Û§·§Î§≥§»§¨§«§≠§Î£Æ RCV Ti = 1 N K k=1 n° {n ; (xn,tn)° Dk} tn ? y (k) i (xn) 2 6: ’`≤Ó§¨“ª∑¨–°§µ§§ƒæ§Ú T?? := arg minT i R Ti §»§π§Î£Æ
- 42. 40/50 Ωª≤Ó¥_’J 7: òÀú ’`≤Ó (standard error) SE §Ú«Û§·§Î£Æ SE RCV Ti := s Ti / °Ã N, s Ti := 1 N N n=1 tn ? y (¶ (n)) i (xn) 2 ? RCV (Ti) 2 , ¶ (n) = K k=1 k1Dk ((xn, tn)) 8: “‘œ¬§Úú∫§ø§π T §Œ÷–§«◊Ó–°§Œƒæ T? §Ú◊ÓΩKµƒ§ ΩYπ˚§»§π§Î£Æ RCV (T) °‹ RCV (T?? ) + 1 °¡ SE (T?? ) §≥§Œ•“•Â©`•Í•π•∆•£•√•Ø§ õQ§·∑Ω§œ 1 SE rule §»∫Ù§–§Ï§Î£Æ
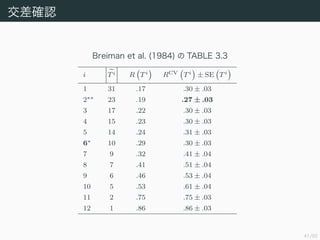
- 43. 41/50 Ωª≤Ó¥_’J Breiman et al. (1984) §Œ TABLE 3.3 i Ti R Ti RCV Ti °¿ SE Ti 1 31 .17 .30 °¿ .03 2?? 23 .19 .27 °¿ .03 3 17 .22 .30 °¿ .03 4 15 .23 .30 °¿ .03 5 14 .24 .31 °¿ .03 6? 10 .29 .30 °¿ .03 7 9 .32 .41 °¿ .04 8 7 .41 .51 °¿ .04 9 6 .46 .53 °¿ .04 10 5 .53 .61 °¿ .04 11 2 .75 .75 °¿ .03 12 1 .86 .86 °¿ .03
- 44. 42/50 CART §À§Ë§Î∑÷Óê ¥Œ§À∑÷Óê§ÚíQ§¶£Æ ÷Ìò§œªÿ颧»§€§‹Õ¨òî§ §Œ§«£¨∑÷∏Ó§Œª˘ú §¿§±íQ§¶£Æ C1, . . . , CK §Œ K •Ø•È•π§À∑÷Óê§π§ÎÜñÓ}§ÚΩ‚§≠§ø§§§»§π§Î£Æπùµ„ t §Ú Õ®§√§∆¡˜§Ï§∆§§§Ø•«©`•ø§Œ ˝§Ú N (t) §»§π§Î£Æ§fi§ø§Ω§Ï§È§Œ§¶§¡§« Ck §À Ù§π§Î§‚§Œ§Œ ˝§Ú Nk (t) §»±Ì§π£Æ§≥§Œ§»§≠ p (t|Ck) = Nk (t) Nk , p (Ck, t) = p (Ck) p (t|Ck) = Nk N Nk (t) Nk = Nk (t) N , p (t) = K k=1 p (Ck, t) = N (t) N §«§¢§Î£Æ§Ë§√§∆ ¬··¥_¬ p (Ck|t) §œ¥Œ§Œ§Ë§¶§À«Û§·§È§Ï§Î£Æ p (Ck|t) = p (Ck, t) p (t) = Nk (t) N (t)
- 45. 43/50 CART §À§Ë§Î∑÷Óê ∑÷∏Ó§Œª˘ú §À§œ≤ªºÉ∂»Èv ˝ (impurity function) §»§§§¶§‚§Œ§Ú 𧶣Æ≤ª ºÉ∂»Èv ˝§»§œ£¨“‘œ¬§ŒÃıº˛§Úú∫§ø§πÈv ˝ ? : ?M °˙ R §Œ§≥§»§«§¢§Î£Æ 1. ? (p) §œ p = (1/M, °§ °§ °§ , 1/M) §Œ§»§≠§Àœfi§Í◊Ó¥Û§»§ §Î£Æ 2. ? (p) §œ p = (0, °§ °§ °§ , 0, i 1, 0, °§ °§ °§ , 0) §Œ§»§≠§Àœfi§Í◊Ó–°§»§ §Î£Æ 3. ?(p1, . . . , i pi, . . . , j pj, . . . , pM ) = ?(p1, . . . , i pj, . . . , j pi, . . . , pM )£Æ
- 46. 44/50 ≤ªºÉ∂» ≤ªºÉ∂»Èv ˝§Ú ? §»§π§Î§»£¨»Œ“‚§Œπùµ„ t §Œ≤ªºÉ∂» I (t) §œ I (t) := ? (p (C1|t) , . . . , p (CK|t)) §«∂®§·§È§Ï§Î£Æ πùµ„ t §Œ◊” tL §» tR §À§ƒ§§§∆£¨t §´§È§Ω§Ï§È§À¡˜§Ï§Î•«©`•ø§Œ∏Ó∫œ§Ú pL = p (tL) p (t) , pR = p (tR) p (t) §»§π§Î§»£¨t §À§™§§§∆ª˘ú s §«∑÷∏Ó§∑§ø§»§≠§Œ≤ªºÉ∂»§Œúp…Ÿ§œ ?I (s, t) = I (t) ? pRI (tR) ? pLI (tL) §»±Ì§µ§Ï§Î£Æ≤ªºÉ∂»§Œúp…Ÿ§¨◊Ó¥Û§À§ §Î§Ë§¶§ ∑÷∏Ó§Ú––§√§∆§§§±§–§Ë§§£Æ
- 47. 45/50 ≤ªºÉ∂»Èv ˝§Œ¿˝ ’`∑÷Óê¬ I (t) = 1 ? max k p (Ck|t) Ωª≤Ó•®•Û•»•Ì•‘©` I (t) = ? K k=1 p (Ck|t) log p (Ck|t) •∏•À÷∏ ˝ (Gini index) I (t) = K k=1 p (Ck|t) (1 ? p (Ck|t))
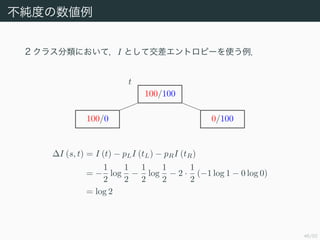
- 48. 46/50 ≤ªºÉ∂»§Œ ˝Çé¿˝ 2 •Ø•È•π∑÷Óê§À§™§§§∆£¨I §»§∑§∆Ωª≤Ó•®•Û•»•Ì•‘©`§Ú π§¶¿˝£Æ t 100/100 100/0 0/100 ?I (s, t) = I (t) ? pLI (tL) ? pRI (tR) = ? 1 2 log 1 2 ? 1 2 log 1 2 ? 2 °§ 1 2 (?1 log 1 ? 0 log 0) = log 2
- 49. 47/50 ≤ªºÉ∂»§Œ ˝Çé¿˝ Ñe§ ∑÷∏Ó s §Ú π§¶¿˝£Æ t 100/100 60/40 40/60 ?I (s , t) = I (t) ? pLI (tL) ? pRI (tR) = log 2 ? 2 °§ 1 2 ? 3 5 log 3 5 ? 2 5 log 2 5 < ?I (s, t) «∞§Œ∑÷∏Ó s §Œ§€§¶§¨∫√§fi§∑§§£Æ
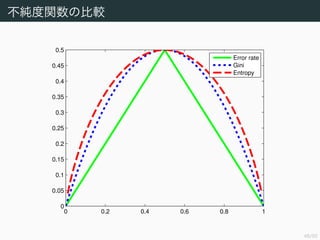
- 50. 48/50 ≤ªºÉ∂»Èv ˝§Œ±»›^ 0 0.2 0.4 0.6 0.8 1 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 Error rate Gini Entropy
- 52. 50/50 ≤ŒøºŒƒœ◊ Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. Breiman, L., Friedman, J., Stone, C. J., and Olshen, R. A. (1984). Classi?cation and regression trees. CRC press. Freund, Y. and Schapire, R. E. (1996). Experiments with a new boosting algorithm. Friedman, J., Hastie, T., Tibshirani, R., et al. (2000). Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). The annals of statistics. Hastie, T., Tibshirani, R., and Friedman, J. (2009). The Elements of Statistical Learning: data mining, inference and prediction. Springer, second edition. Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. ∆ΩæÆ”–»˝ (2012). §œ§∏§·§∆§Œ•—•ø©`•Û’J◊R. …≠±±≥ˆ∞Ê.