run Keras model on opencv
5 likes13,773 views

Ą┌50╗žź│ź¾źįźÕ®`ź┐źėźĖźńź¾├ŃŪ┐╗߯└ķvČ½ĪĖ░õ│šżŪ╩╣ż©żļź─®`źļ│ó░š┤¾╗߯▓Ī╣░k▒Ēū╩┴ŽżŪż╣ĪŻ
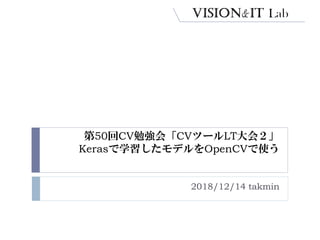






![1. KerasżŪč¦┴ĢźŌźŪźļż“śŗ║B/č¦┴Ģ
10
Tmodel = Sequential()
Tmodel.add(Conv2D(32,kernel_size=(5,5),input_shape=input_shape))
Tmodel.add(MaxPooling2D(pool_size=(2,2)))
Tmodel.add(Conv2D(64,kernel_size=(5,5),input_shape=input_shape))
Tmodel.add(MaxPooling2D(pool_size=(2,2)))
Tmodel.add(Flatten())
Tmodel.add(Dense(1024, activation=tf.nn.relu))
Tmodel.add(Dropout(0.2))
Tmodel.add(Dense(10,activation=tf.nn.softmax))
Tmodel.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
č¦┴ĢźŌźŪźļśŗ║B Kerasż╬Sequential
Model
Conv x2
Max Pooling x2
Full Connected
Layer
Drop Out
č¦┴ĢĘĮĘ©ż“ųĖČ©żĘżŲź│ź¾źčźżźļ](https://image.slidesharecdn.com/kerasopencv-181215010457/85/run-Keras-model-on-opencv-10-320.jpg)
![1. KerasżŪč¦┴ĢźŌźŪźļż“śŗ║B/č¦┴Ģ
11
from tensorflow.python.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test= x_test.reshape(x_test.shape[0], 28, 28, 1)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
Tmodel.fit(x=x_train,y=y_train,epochs=10,batch_size=128,validation_
data=(x_test,y_test))
Tmodel.save("trained_model.h5")
MNISTżŪč¦┴Ģż╣żļ└²
MNISTż╬šiż▀▐z
ż▀ż╚źŪ®`ź┐š¹ą╬
č¦┴Ģ
č¦┴ĢĮY╣¹
ż“▒Ż┤µ](https://image.slidesharecdn.com/kerasopencv-181215010457/85/run-Keras-model-on-opencv-11-320.jpg)

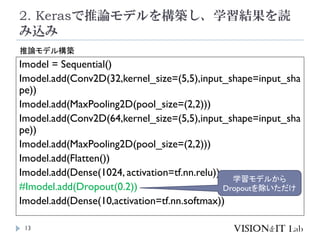
![2. KerasżŪ═ŲšōźŌźŪźļż“śŗ║BżĘĪóč¦┴ĢĮY╣¹ż“ši
ż▀▐zż▀
14
Imodel.load_weights("trained_model.h5")
Imodel.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracyĪ»])
Imodel.save("inference_model.h5")
č¦┴ĢĮY╣¹šiż▀▐zż▀
č¦┴ĢźŌźŪźļż½żķźčźķ
źß®`ź┐ż“═ŲšōźŌźŪźļżž
šiż▀▐zż▀
ź│ź¾źčźżźļ
═ŲČ©źŌźŪźļż“▒Ż┤µ](https://image.slidesharecdn.com/kerasopencv-181215010457/85/run-Keras-model-on-opencv-14-320.jpg)

![3. Kerasż╬═ŲšōźŌźŪźļż½żķTensorflowż╬źŌźŪźļ
ż“╚ĪĄ├żĘĪó▒Ż┤µ
16
from tensorflow.python.keras.models import load_model
import tensorflow as tf
from tensorflow.python.keras import backend as K
model = load_model('inference_model.h5')
sess = K.get_session()
outname = "output_node0"
tf.identity(model.outputs[0], name=outname)
constant_graph = graph_util.convert_variables_to_constants(sess,
sess.graph.as_graph_def(),[outname])
tf.train.write_graph(constant_graph, "./", "lenet.pb", as_text=False)
═ŲšōźŌźŪźļśŗ║B
Keras═ŲšōźŌźŪźļ
šiż▀▐zż▀
Kerasż╬źąź├ź»ź©ź¾ź╔(Tensorflow)
ż╬ź╗ź├źĘźńź¾╚ĪĄ├
Freeze
źūźĒź╚ź│źļźąź├źšźĪż“źąźż
ź╩źĻżŪ▒Ż┤µ(./lenet.pb)](https://image.slidesharecdn.com/kerasopencv-181215010457/85/run-Keras-model-on-opencv-16-320.jpg)




![[DL▌åši╗ß]Pay Attention to MLPs Ż©gMLPŻ®](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=560&fit=bounds)







![[DL▌åši╗ß]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=560&fit=bounds)

![[DL▌åši╗ß]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...](https://cdn.slidesharecdn.com/ss_thumbnails/dlu8f2au8aadu4f1av2-170407001546-thumbnail.jpg?width=560&fit=bounds)








![[DL▌åši╗ß]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=560&fit=bounds)








More Related Content
What's hot (20)
Similar to run Keras model on opencv (20)












ÖCąĄč¦┴Ģż╦żĶżļ═ŲČ©źµ®`źČ®`╩¶ąįż╬░▓Č©╣®Įoż╬ż┐żßż╬╩®▓▀Ż©Ą┌56╗ž Machine Learning 15minutes! BroadcastŻ®





More from Takuya Minagawa (20)




















Recently uploaded (15)















run Keras model on opencv
- 2. ūį╝║ĮBĮķ 2 ųĻ╩Į╗ß╔ńźėźĖźńź¾Ż”ITźķź▄ ┤·▒Ē╚ĪŠåę█ Įį┤© ū┐ę▓Ż©ż▀ż╩ż¼ż’ ż┐ż»żõŻ® ĪĖź│ź¾źįźÕ®`ź┐źėźĖźńź¾├ŃÅŖ╗߯└ķv¢|Ī╣ų„┤▀ ▓®╩┐Ż©╣żč¦Ż® http://visitlab.jp ┬įÜsŻ║ 1999-2003─Ļ ╚š▒ŠHPŻ©ßßż╦źóźĖźņź¾ź╚?źŲź»ź╬źĒźĖ®`żžĘų╔ńŻ®ż╦żŲĪóITź©ź¾źĖź╦źóż╚żĘżŲźĘź╣źŲźÓśŗ║BĪóźūźĻ ź╗®`źļź╣ĪóźūźĒźĖź¦ź»ź╚ź▐ź═źĖźßź¾ź╚Ī󟥟▌®`ź╚Ą╚ż╬śIäšż╦ÅŠ╩┬ 2004-2009─Ļ ź│ź¾źįźÕ®`ź┐źėźĖźńź¾ż“ė├żżż┐źĘź╣źŲźÓ/źóźūźĻ/źĄ®`źėź╣ķ_░kĄ╚ż╦ÅŠ╩┬ 2007-2010─Ļ æcæ¬┴x█ė┤¾č¦┤¾č¦į║ ßßŲ┌▓®╩┐šn│╠ż╦żŲĪóź│ź¾źįźÕ®`ź┐źėźĖźńź¾ż“ī¤╣ź ģg╬╗╚ĪĄ├═╦č¦ßßĪó▓®╩┐║┼╚ĪĄ├Ż©2014─ĻŻ® 2009─Ļ-¼Fį┌ źšźĻ®`źķź¾ź╣ż╚żĘżŲĪóź│ź¾źįźÕ®`ź┐źėźĖźńź¾ż╬ź│ź¾źĄźļ/蹊┐/ķ_░kĄ╚ż╦ÅŠ╩┬Ż©2018─ĻĘ©╚╦╗»Ż®
- 4. DNNźŌźĖźÕ®`źļż“╩╣ż”źŌź┴ź┘®`źĘźńź¾ 4 ? OpenCVżŪķ_░kżĘż┐╗ŁŽ±äI└ĒźūźĒź░ źķźÓż╬ę╗▓┐Ęųż╦CNNż“╩╣żżż┐żż ? źķźżźųźķźĻż“żżż»ż─żŌźżź¾ź╣ź╚®`źļżĘż┐ż» ż╩żż ? ║åģgż╦╩╣żżż┐żż ? C++żŪäėż½żĘż┐żż
- 5. OpenCV DNNźŌźĖźÕ®`źļ 5 ? ═Ųšōī¤ė├ ? č¦┴ĢżŽ╦¹ż╬Deep LearningźķźżźųźķźĻż“╩╣ė├ ? ź╔źŁźÕźßź¾ź╚żŽ╔┘ż╩żż ? ź┴źÕ®`ź╚źĻźóźļŻ║ https://docs.opencv.org/4.0.0/d2/d58/tutorial_table _of_content_dnn.html ? APIźĻźšźĪźņź¾ź╣Ż║ https://docs.opencv.org/4.0.0/d6/d0f/group__dnn.ht ml ? ╩╣ż├żŲżżżļ╚╦żŌżĮżņż█ż╔ČÓż»ż╩żĄżĮż”
- 6. č¦┴Ģż╦Kerasż“╩╣ż├ż┐└Ēė╔ 6 ? ųT░Ńż╬╩┬ŪķżŪKerasż“╩╣ż”▒žę¬ż¼żóż├ż┐ ? 3.4.4ż▐żŪżŽęįŽ┬ż╬źķźżźųźķźĻż╬źŌźŪźļż“źĄ ź▌®`ź╚żĘżŲż¬żĻĪóż│ż╬ųążŪę╗Ę¼CNNż╬ķ_░kż¼ ęūżĘżĮż”ż╩ż╬ż¼Keras + Tensorflowż╚┼ąČŽ ? Caffe ? Tensorflow ? Torch ? ż╩ż¬Īó4.0ż½żķżŽONNXżŌźĄź▌®`ź╚żĘżŲżļż╬żŪĪó ChainerżõPyTorchż½żķżŌżżż▒żļżŽż║
- 7. KerasżŪč¦┴ĢżĘżŲOpenCVżŪ═Ųšō 7 įćżĘż┐ŁhŠ│ ? Tensorflow 1.5 (Python) ? OpenCV 4.0 (C++) ? LeNETżŪMNISTż“č¦┴Ģ ? CPUżŪč¦┴Ģ/═Ųšō ? ź│®`ź╔żŽż│ż┴żķ ? https://github.com/takmin/Keras2OpenCV
- 8. KerasżŪč¦┴ĢżĘżŲOpenCVżŪ═Ųšō 8 ╩ųĒśŻ║ 1. KerasżŪč¦┴ĢźŌźŪźļż“śŗ║B/č¦┴Ģ 2. KerasżŪ═ŲšōźŌźŪźļż“śŗ║BżĘĪóč¦┴ĢĮY ╣¹ż“šiż▀▐zż▀ 3. Kerasż╬═ŲšōźŌźŪźļż½żķTensorflowż╬ źŌźŪźļż“╚ĪĄ├żĘĪó▒Ż┤µ 4. OpenCVżŪźŌźŪźļźšźĪźżźļż“šiż▀▐zż▀Īó ═Ųšōż“īgąą
- 9. 1. KerasżŪč¦┴ĢźŌźŪźļż“śŗ║B/č¦┴Ģ 9 ? źŌźŪźļŻ║ LeNet5 ? č¦┴ĢźŪ®`ź┐Ż║ MNIST
- 10. 1. KerasżŪč¦┴ĢźŌźŪźļż“śŗ║B/č¦┴Ģ 10 Tmodel = Sequential() Tmodel.add(Conv2D(32,kernel_size=(5,5),input_shape=input_shape)) Tmodel.add(MaxPooling2D(pool_size=(2,2))) Tmodel.add(Conv2D(64,kernel_size=(5,5),input_shape=input_shape)) Tmodel.add(MaxPooling2D(pool_size=(2,2))) Tmodel.add(Flatten()) Tmodel.add(Dense(1024, activation=tf.nn.relu)) Tmodel.add(Dropout(0.2)) Tmodel.add(Dense(10,activation=tf.nn.softmax)) Tmodel.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) č¦┴ĢźŌźŪźļśŗ║B Kerasż╬Sequential Model Conv x2 Max Pooling x2 Full Connected Layer Drop Out č¦┴ĢĘĮĘ©ż“ųĖČ©żĘżŲź│ź¾źčźżźļ
- 11. 1. KerasżŪč¦┴ĢźŌźŪźļż“śŗ║B/č¦┴Ģ 11 from tensorflow.python.keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(x_train.shape[0], 28, 28, 1) x_test= x_test.reshape(x_test.shape[0], 28, 28, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 Tmodel.fit(x=x_train,y=y_train,epochs=10,batch_size=128,validation_ data=(x_test,y_test)) Tmodel.save("trained_model.h5") MNISTżŪč¦┴Ģż╣żļ└² MNISTż╬šiż▀▐z ż▀ż╚źŪ®`ź┐š¹ą╬ č¦┴Ģ č¦┴ĢĮY╣¹ ż“▒Ż┤µ
- 12. 2. KerasżŪ═ŲšōźŌźŪźļż“śŗ║BżĘĪóč¦┴ĢĮY╣¹ż“ši ż▀▐zż▀ 12 ? OpenCVżŽ═Ųšōż╬ż▀źĄź▌®`ź╚żĘżŲżżżļż┐żßĪó└²ż©żą Dropoutż╬żĶż”ż╩č¦┴Ģė├ż╬źņźżźõ®`ż“šiż▀▐zżÓż│ż╚ż¼żŪ żŁż╩żż ? Tensorflowż╦żŽĪ▒optimize_for_inferenceĪ▒ż╚żżż”č¦┴Ģė├ż╬ źŌźŪźļż½żķ═Ųšōż╦▒žę¬ż╩▓┐Ęųż╬ż▀ż“ÆiżŁ│÷ż╣ź─®`źļ/źķ źżźųźķźĻż¼ė├ęŌżĄżņżŲżżżļż¼ĪóDropoutżŽ│²╚źżĘżŲż»żņż╩ żż ? ¼Fį┌pull requestż¼╔Žż¼ż├żŲżżżļż¼¼FĢrĄŃżŪżŽź▐®`źĖżĄżņżŲżż ż╩żż ? ═Ųšōė├ż╬źŌźŪźļż“śŗ║BżĘĪóč¦┴ĢżĘż┐źčźķźß®`ź┐ż“šiż▀▐z żÓż│ż╚żŪĮŌøQ
- 13. 2. KerasżŪ═ŲšōźŌźŪźļż“śŗ║BżĘĪóč¦┴ĢĮY╣¹ż“ši ż▀▐zż▀ 13 Imodel = Sequential() Imodel.add(Conv2D(32,kernel_size=(5,5),input_shape=input_sha pe)) Imodel.add(MaxPooling2D(pool_size=(2,2))) Imodel.add(Conv2D(64,kernel_size=(5,5),input_shape=input_sha pe)) Imodel.add(MaxPooling2D(pool_size=(2,2))) Imodel.add(Flatten()) Imodel.add(Dense(1024, activation=tf.nn.relu)) #Imodel.add(Dropout(0.2)) Imodel.add(Dense(10,activation=tf.nn.softmax)) ═ŲšōźŌźŪźļśŗ║B č¦┴ĢźŌźŪźļż½żķ Dropoutż“│²żżż┐ż└ż▒
- 15. 3. Kerasż╬═ŲšōźŌźŪźļż½żķTensorflowż╬źŌźŪźļ ż“╚ĪĄ├żĘĪó▒Ż┤µ 15 1. Kerasż½żķźąź├ź»ź©ź¾ź╔ż╬Tensorflowżž źóź»ź╗ź╣żĘĪóźŌźŪźļż“╚ĪĄ├ 2. Tensorflowż╬źŌźŪźļżŪżŽĪóź═ź├ź╚ź’®`ź» śŗįņż╚ųžż▀żŽäeĪ®ż╦ÆQż’żņżŲżżżļż┐żßĪó żĮżņżķż“Įy║ŽŻ©freezeŻ® ? ź═ź├ź╚ź’®`ź»─┌ż╬ēõ╩²ż“Č©╩²Ż©č¦┴ĢżĘż┐ųž ż▀Ż®ż╦ų├żŁōQż© 3. FreezeżĘż┐źŌźŪźļż“źšźĪźżźļżž▒Ż┤µ
- 16. 3. Kerasż╬═ŲšōźŌźŪźļż½żķTensorflowż╬źŌźŪźļ ż“╚ĪĄ├żĘĪó▒Ż┤µ 16 from tensorflow.python.keras.models import load_model import tensorflow as tf from tensorflow.python.keras import backend as K model = load_model('inference_model.h5') sess = K.get_session() outname = "output_node0" tf.identity(model.outputs[0], name=outname) constant_graph = graph_util.convert_variables_to_constants(sess, sess.graph.as_graph_def(),[outname]) tf.train.write_graph(constant_graph, "./", "lenet.pb", as_text=False) ═ŲšōźŌźŪźļśŗ║B Keras═ŲšōźŌźŪźļ šiż▀▐zż▀ Kerasż╬źąź├ź»ź©ź¾ź╔(Tensorflow) ż╬ź╗ź├źĘźńź¾╚ĪĄ├ Freeze źūźĒź╚ź│źļźąź├źšźĪż“źąźż ź╩źĻżŪ▒Ż┤µ(./lenet.pb)
- 17. 4. OpenCVżŪźŌźŪźļźšźĪźżźļż“šiż▀▐zż▀Īó═Ųšō ż“īgąą 17 dnn::Net net = dnn::readNet("./lenet.pb"); Mat img = imread(Ī░mnist0.png", 0); Mat blob = dnn::blobFromImage(img, 1.0 / 255); net.setInput(blob); Mat prob = net.forward(); Point classIdPoint; double confidence; minMaxLoc(prob.reshape(1, 1), 0, &confidence, 0, &classIdPoint); int classId = classIdPoint.x; C++ Tensorflow═Ųšō źŌźŪźļšiż▀▐zż▀ ėĶ£y
- 18. ż▐ż╚żß 18 ? KerasżŪč¦┴ĢżĘżŲOpenCVżŪ═Ųšō ? č¦┴ĢźŌźŪźļż╬╦¹ż╦═ŲšōźŌźŪźļż“ė├ęŌ ? Kerasż½żķźąź├ź»ź©ź¾ź╔ż╬Tensorflowż“║¶żė│÷żĘĪóFreezeżĘżŲ▒Ż ┤µ ? īgąąĢrķgżŽKerasżŪ╝s2.8msĪóOpenCVżŪ1.2ms (Celeron 1.8G) ? Į±ßßįćżĘż┐żżż│ż╚ ? Functional APIż“╩╣ż├żŲĪóż╔ż│ż▐żŪč}ļjż╩źŌźŪźļż╦īØÅĻżŪżŁżļ ż½┤_šJ ? Custom Layer ? ONNXż½żķż╬šiż▀▐zż▀