





![1. NLPにおけるNNの歴史的経緯①
? 系列変換モデルは再帰ニューラルネットに
依存してきた
? 再帰は並列計算を妨げる
? 対症療法の考案:
? Factorization Trick [1]やConditional Computation [2]
直接解決しているわけではない!
7
1. https://arxiv.org/abs/1703.10722
2. https://arxiv.org/abs/1511.06297
3. (image) https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/](https://image.slidesharecdn.com/transformerslideshare-190523043252/85/Transformer-7-320.jpg)















罢谤补苍蝉蹿辞谤尘别谤を雰囲気で理解する
- 2. Transformerとは? ? 系列変換モデルの一種 ?入力も出力も時系列データとなるモデル ? エンコーダ + デコーダの構造 ? Seq2Seqとかがその例 ? 再帰や畳み込みを一切使わないモデル ? 並列処理ができ,学習の高速化を実現 ? 話題のBERTで活用されているモデル 2
- 3. 論文情報 ? 論文名: Attention Is All You Need ? 要するに「必要なのはAttentionだけ」 ? 著者: A. Vaswani et al. (Google Brain) ? 出典: NIPS 2017 3
- 4. 本スライドの構成 雰囲気中速(爆速?♂?)理解を図るために, 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3. Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる という流れで見ていきます. 4
- 5. 本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3. Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 5
- 7. 1. NLPにおけるNNの歴史的経緯① ? 系列変換モデルは再帰ニューラルネットに 依存してきた ? 再帰は並列計算を妨げる ? 対症療法の考案: ? Factorization Trick [1]やConditional Computation [2] 直接解決しているわけではない! 7 1. https://arxiv.org/abs/1703.10722 2. https://arxiv.org/abs/1511.06297 3. (image) https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
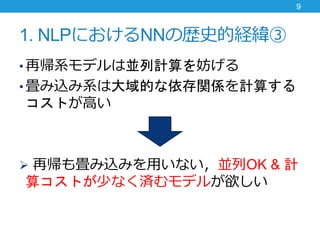
- 8. 1. NLPにおけるNNの歴史的経緯② ? 系列変換モデルではCNNも代替的に使われて きた ? 計算を並列化できるため ? 距離に応じた依存関係の計算コストがかかる ? ConvS2S: O(n), ByteNet: O(log n) 長文だと大域的な依存関係をつかみにくい! 8 * より広い文脈を考慮できれば,より広い単語間の関係性が見られるメリット
- 9. 1. NLPにおけるNNの歴史的経緯③ ? 再帰系モデルは並列計算を妨げる ? 畳み込み系は大域的な依存関係を計算する コストが高い ? 再帰も畳み込みを用いない,並列OK & 計 算コストが少なく済むモデルが欲しい 9
- 10. 本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3. Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 10
- 11. 2. ATTENTION 1. Attentionとは? 2. Attentionのバリエーション 3. Self Attentionとは? 4. Attentionの利点?欠点 11
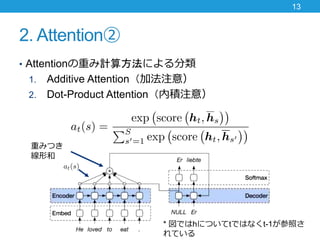
- 12. 2. Attention① ? そもそもAttentionとは? ? 距離に関係なく依存関係をモデリングできる手法 ? 系列変換モデルやエンコーダモデルにも適用される ? 注意機構とも呼ばれる 12 「どの単語にどの程度注意を払うべきか?」 Image: https://www.quora.com/How-does-an-attention- mechanism-work-in-deep-learning
- 13. 2. Attention② ? Attentionの重み計算方法による分類 1. Additive Attention(加法注意) 2. Dot-Product Attention(内積注意) 13 重みつき 線形和 * 図ではhについてtではなくt-1が参照さ れている
- 14. 2. Attention③ ? Attentionの重み計算方法による分類 14 ここの求め方! ? 内積注意 ? 「時刻tのデコーダの隠れ 層の状態と,位置sでのエ ンコーダの隠れ層の状態」 との内積 ? 加法注意 ? 隠れ層を1層設けて計算 ? が となるパ ターンが2つくらいある *Attentionの重み計算手法は色々とありすぎるので,深く考える必要なし?
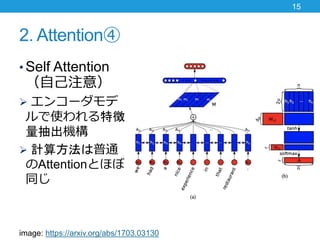
- 15. 2. Attention④ ? Self Attention (自己注意) ? エンコーダモデ ルで使われる特徴 量抽出機構 ? 計算方法は普通 のAttentionとほぼ 同じ 15 image: https://arxiv.org/abs/1703.03130
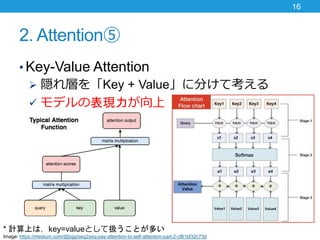
- 16. 2. Attention⑤ ? Key-Value Attention ? 隠れ層を「Key + Value」に分けて考える ? モデルの表現力が向上 16 * 計算上は,key=valueとして扱うことが多い Image: https://medium.com/@bgg/seq2seq-pay-attention-to-self-attention-part-2-cf81bf32c73d
- 17. 2. Attention⑥ ? Attentionの利点 ? 位置に関わらず依存関係をO(1)で捉えられる ? LSTMやGRU等は長期記憶に弱い ? Attentionの欠点 ? スコアの重み計算コストが通常O(n^2)以上になる ? Attentionはあくまでもモデルの補助的な役割 ? CNNベースのモデルも計算量の問題あり Attentionだけでモデルを作れば良いのでは? 17
- 18. 本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3. Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 18
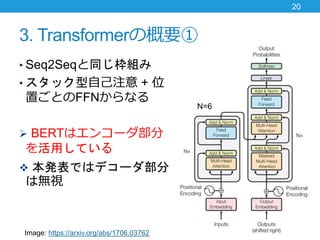
- 20. 3. Transformerの概要① ? Seq2Seqと同じ枠組み ? スタック型自己注意 + 位 置ごとのFFNからなる ? BERTはエンコーダ部分 を活用している ? 本発表ではデコーダ部分 は無視 20 Image: https://arxiv.org/abs/1706.03762 N=6
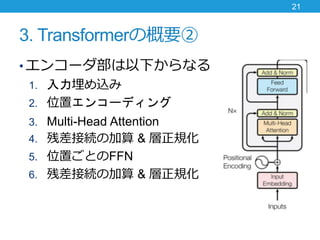
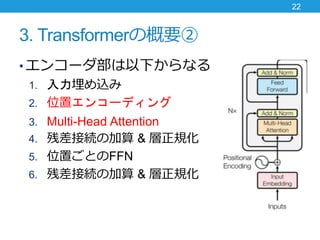
- 21. 3. Transformerの概要② ? エンコーダ部は以下からなる 1. 入力埋め込み 2. 位置エンコーディング 3. Multi-Head Attention 4. 残差接続の加算 & 層正規化 5. 位置ごとのFFN 6. 残差接続の加算 & 層正規化 21
- 22. 3. Transformerの概要② ? エンコーダ部は以下からなる 1. 入力埋め込み 2. 位置エンコーディング 3. Multi-Head Attention 4. 残差接続の加算 & 層正規化 5. 位置ごとのFFN 6. 残差接続の加算 & 層正規化 22
- 23. 本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3. Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 23
- 24. 4. TRANSFORMERのキモ 1. スケール化内積注意 2. Multi-Head Attention 3. 位置エンコーディング 24
- 25. 4. Transformerのキモ① ? スケール化内積注意 ? 隠れ層の次元が大きくなると,内積が大きく なる ? 勾配が小さくなり,学習が進まない ? スコアを で除算してあげることで解決 25
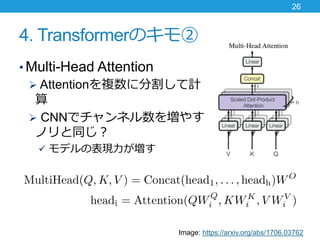
- 26. 4. Transformerのキモ② ? Multi-Head Attention ? Attentionを複数に分割して計 算 ? CNNでチャンネル数を増やす ノリと同じ? ? モデルの表現力が増す 26 Image: https://arxiv.org/abs/1706.03762
- 27. 4. Transformerのキモ③ ? 位置エンコー ディング ? Transformer単体 では時系列を考慮 できない ? 畳み込みや再帰 を使っていないた め ? 正弦波を入力の 埋め込みベクトル に足し合わせるこ とで解決! 27 モデルの次元: d_model 入力トークンの位置
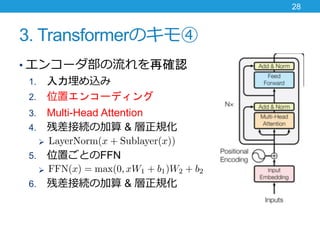
- 28. 3. Transformerのキモ④ ? エンコーダ部の流れを再確認 1. 入力埋め込み 2. 位置エンコーディング 3. Multi-Head Attention 4. 残差接続の加算 & 層正規化 ? 5. 位置ごとのFFN ? 6. 残差接続の加算 & 層正規化 28
- 29. 本スライドの構成 1. NLPにおけるNNの歴史的経緯を知る 2. Attentionについて知る 3. Transformerのモデル概要を知る 4. Transformerのキモを知る 5. 実験結果を見てみる 29
- 30. 5. 実験結果 1. 計算コスト比較 2. 翻訳性能比較 30
- 31. 5. 実験結果① 計算コスト比較 ? Self Attentionが優れている: n < dのとき 31 層あたり計算量 逐次処理を最小限にする 並列可能な計算量 依存関係の最大経路長計算コスト RecurrentとConvの算出方法がいまいちわからん?(誰か教えて)
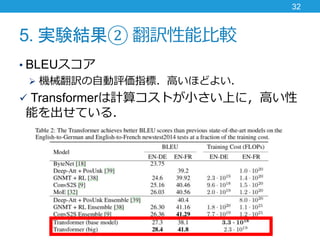
- 32. 5. 実験結果② 翻訳性能比較 ? BLEUスコア ? 機械翻訳の自動評価指標.高いほどよい. ? Transformerは計算コストが小さい上に,高い性 能を出せている. 32
- 33. まとめ 33
- 34. まとめ ? TransformerはAttention + もろもろで作ら れた系列変換モデル ? Positional Encoding ? 位置ごとのフィードフォワード ? 計算量が少ない?高性能なモデル ? BERTはエンコーダ部分を活用している 34
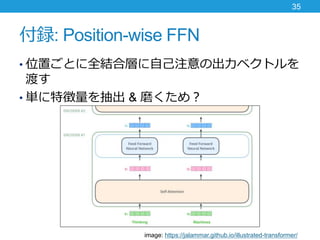
- 35. 付録: Position-wise FFN ? 位置ごとに全結合層に自己注意の出力ベクトルを 渡す ? 単に特徴量を抽出 & 磨くため? 35 image: https://jalammar.github.io/illustrated-transformer/
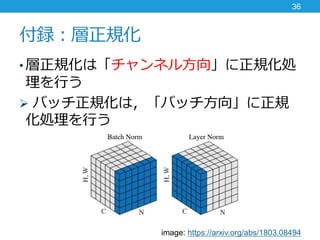
- 36. 付録:層正規化 36 ? 層正規化は「チャンネル方向」に正規化処 理を行う ? バッチ正規化は,「バッチ方向」に正規 化処理を行う image: https://arxiv.org/abs/1803.08494
- 37. 付録: BLEUスコア ? Bilingual Evaluation Understudyの略 ? スコアが高いほど自然な翻訳 37 ? BP: brevity Penalty 翻訳文が短文のとき, その文についてペナル ティを課す ? Nグラム精度 翻訳文とコーパスの参 照文がどれだけ一致し ているか