What is jubatus? How it works for you?
Download as PPTX, PDF2 likes2,179 views

Jubatus is a distributed online machine learning framework that is distributed, fault tolerant, and allows for fixed time computation. It combines a machine learning model with a feature extractor. Jubatus uses a shared-everything architecture that allows it to be fast and fault tolerant. The architecture allows clients to access Jubatus through a single RPC interface even as the number of Jubatus servers scales out dynamically. Jubatus supports various machine learning algorithms including classification, recommendation, anomaly detection, clustering, and regression.










![Classifier
? Task: Classification of Datum
import sys
def fib(a):
if a == 1 or a == 0:
return 1
else:
return fib(a-1) + fib(a-2)
if __name__ == °∞__main__°±:
print(fib(int(sys.argv[1])))
def fib(a)
if a == 1 or a == 0
1
else
return fib(a-1) + fib(a-2)
end
end
if __FILE__ == $0
puts fib(ARGV[0].to_i)
end
Sample Task: Classify what programming language used
It°Øs It°Øs](https://image.slidesharecdn.com/whatisjubatus-140606023057-phpapp02/85/What-is-jubatus-How-it-works-for-you-12-320.jpg)
![Classifier
? Set configuration in the Jubatus server
ClassifierFreature
Extractor
"converter": {
"string_types": {
"bigram": {
"method": "ngram",
"char_num": "2"
}
},
"string_rules": [
{
"key": "*",
"type": "bigram",
"sample_weight": "tf",
"global_weight": "idf°∞
}
]
}
Feature Extractor](https://image.slidesharecdn.com/whatisjubatus-140606023057-phpapp02/85/What-is-jubatus-How-it-works-for-you-13-320.jpg)
![Classifier
? Configuration JSON
®C It does °∞feature vector design°±
®C very important step for machine learning
"converter": {
"string_types": {
"bigram": {
"method": "ngram",
"char_num": "2"
}
},
"string_rules": [
{
"key": "*",
"type": "bigram",
"sample_weight": "tf",
"global_weight": "idf°∞
}
]
}
setteings for extract feature from string
define function named °∞bigram°±
original embedded function °∞ngram°±
pass °∞2°± to °∞ngram°± to create °∞bigram°±
for all data
apply °∞bigram°±
feature weights based on tf/idf
see wikipedia/tf-idf](https://image.slidesharecdn.com/whatisjubatus-140606023057-phpapp02/85/What-is-jubatus-How-it-works-for-you-14-320.jpg)

![Feature Extractor
? What bigram extractor does?
bigram
extractor
import sys
def fib(a):
if a == 1 or a == 0:
return 1
else:
return fib(a-1) + fib(a-2)
if __name__ == °∞__main__°±:
print(fib(int(sys.argv[1])))
key value
im 1
mp 1
po 1
... ...
): 1
... ...
de 1
ef 1
... ...
Feature Vector](https://image.slidesharecdn.com/whatisjubatus-140606023057-phpapp02/85/What-is-jubatus-How-it-works-for-you-16-320.jpg)




![Via RPC
? call feature extraction and classification from
client via RPC
AROWbigram
extractor
lang = client.classify([sourcecode])
import sys
def fib(a):
if a == 1 or a == 0:
return 1
else:
return fib(a-1) + fib(a-2)
if __name__ == °∞__main__°±:
print(fib(int(sys.argv[1])))
key value
im 1
mp 1
po 1
... ...
): 1
... ...
de 1
ef 1
... ...
It may be](https://image.slidesharecdn.com/whatisjubatus-140606023057-phpapp02/85/What-is-jubatus-How-it-works-for-you-21-320.jpg)






















![[UniteKorea2013] The Unity Rendering Pipeline](https://cdn.slidesharecdn.com/ss_thumbnails/theunityrenderingpipelinekuba-130505193137-phpapp02-thumbnail.jpg?width=560&fit=bounds)


























More Related Content
Viewers also liked (13)
Similar to What is jubatus? How it works for you? (20)











Recently uploaded (20)




















What is jubatus? How it works for you?
- 1. What is Jubatus? How it works for you? NTT SIC Hiroki Kumazaki
- 2. Jubatus is°≠ ? A Distributed Online Machine-Learning framework ? Distributed ®C Fault-Tolerance ®C Scale out ? Online ®C Fixed time computation ? Machine-Learning ®C More than °∞word count°±!
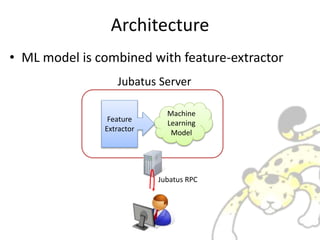
- 3. Architecture ? ML model is combined with feature-extractor Machine Learning Model Feature Extractor Jubatus Server Jubatus RPC
- 4. Architecture ? Distributed Computation ®C Shared-Everything Architecture ? It°Øs fast and fault-tolerant! Mix
- 5. Architecture ? It looks as if one server running. Client Jubatus RPC Proxy
- 6. Architecture ? It looks as if one server running ®C You can use single local Jubatus server for develop ®C Multiple Jubatus server cluster for production Client Jubatus RPC The same RPC£°
- 7. Architecture ? With heavy load°≠ Client Jubatus RPC Proxy
- 8. Architecture ? Dynamically scale-out! Client Jubatus RPC Proxy
- 9. Architecture ? Whenever servers break down ®C Proxy conceals failures, so the service will continue. Client Jubatus RPC Proxy
- 10. Architecture ? Multilanguage client library ®C gem, pip, cpan, maven Ready! ®C It essentially uses a messagepack-rpc. ? So you can use OCaml, Haskell, JavaScript, Go with your own risk. Client Jubatus RPC
- 11. Architecture ? Many ML algorithms ®C Classifier ®C Recommender ®C Anomaly Detection ®C Clustering ®C Regression ®C Graph Mining Useful!
- 12. Classifier ? Task: Classification of Datum import sys def fib(a): if a == 1 or a == 0: return 1 else: return fib(a-1) + fib(a-2) if __name__ == °∞__main__°±: print(fib(int(sys.argv[1]))) def fib(a) if a == 1 or a == 0 1 else return fib(a-1) + fib(a-2) end end if __FILE__ == $0 puts fib(ARGV[0].to_i) end Sample Task: Classify what programming language used It°Øs It°Øs
- 13. Classifier ? Set configuration in the Jubatus server ClassifierFreature Extractor "converter": { "string_types": { "bigram": { "method": "ngram", "char_num": "2" } }, "string_rules": [ { "key": "*", "type": "bigram", "sample_weight": "tf", "global_weight": "idf°∞ } ] } Feature Extractor
- 14. Classifier ? Configuration JSON ®C It does °∞feature vector design°± ®C very important step for machine learning "converter": { "string_types": { "bigram": { "method": "ngram", "char_num": "2" } }, "string_rules": [ { "key": "*", "type": "bigram", "sample_weight": "tf", "global_weight": "idf°∞ } ] } setteings for extract feature from string define function named °∞bigram°± original embedded function °∞ngram°± pass °∞2°± to °∞ngram°± to create °∞bigram°± for all data apply °∞bigram°± feature weights based on tf/idf see wikipedia/tf-idf
- 15. Classifier ? Feature Extractor becomes °∞bigram extractor°± Classifierbigram extractor
- 16. Feature Extractor ? What bigram extractor does? bigram extractor import sys def fib(a): if a == 1 or a == 0: return 1 else: return fib(a-1) + fib(a-2) if __name__ == °∞__main__°±: print(fib(int(sys.argv[1]))) key value im 1 mp 1 po 1 ... ... ): 1 ... ... de 1 ef 1 ... ... Feature Vector
- 17. Classifier ? Training model with feature vectors key value im 1 mp 1 po 1 ... ... ): 1 ... ... de 1 ef 1 ... ... Classifier key value pu 1 ut 1 ... ... {| ... |m 1 m| 1 {| 1 en 1 nd 1 key value @a 1 $_ 1 ... ... my ... su 1 ub 1 us 1 se 1 ... ...
- 18. Classifier ? Set configuration in the Jubatus server Classifier "method" : "AROW", "parameter" : { "regularization_weight" : 1.0 } Feature Extractor bigram extractor Classifier Algorithms ? Perceptron ? Passive Aggressive ? Confidence Weight ? Adaptive Regularization of Weights ? Normal He£Úd
- 19. Classifier ? Use model to classification task ®C Jubatus will find clue for classification AROW key value si 1 il 1 ... ... {| 1 ... ... It°Øs
- 20. Classifier ? Use model to classification task ®C Jubatus will find clue for classification AROW key value re 1 ): 1 ... ... s[ 1 ... ... It°Øs
- 21. Via RPC ? call feature extraction and classification from client via RPC AROWbigram extractor lang = client.classify([sourcecode]) import sys def fib(a): if a == 1 or a == 0: return 1 else: return fib(a-1) + fib(a-2) if __name__ == °∞__main__°±: print(fib(int(sys.argv[1]))) key value im 1 mp 1 po 1 ... ... ): 1 ... ... de 1 ef 1 ... ... It may be
- 22. What classifier can do? ? You can ®C estimate the topic of tweets ®C trash spam mail automatically ®C monitor server failure from syslog ®C estimate sentiment of user from blog post ®C detect malicious attack ®C find what feature is the best clue to classification
- 23. What classifier cannot do ? You cannot ®C train model from data without supervised answer ®C create a class without knowledge of the class ®C get fine model without correct feature designing
- 24. How to use? ? see examples in http://github.com/jubatus/jubatus-example ®C gender ®C shogun ®C malware classification ®C language detection
- 25. Recommender ? Task: what datum is similar to the datum? Name Star Wars Harry Potter Star Trek Titanic Frozen John 4 3 2 2 Bob 5 3 Erika 1 3 4 5 Jack 2 5 Ann 4 5 Emily 1 4 2 5 4 Which movie should we recommend Ann?
- 26. Recommender ? Do recommendation based on Nearest Neighbor Movie Rating(high-dimensional) Science Fiction Star Trek lover John Jack Love Romance Fantasy Erika Ann StarWars lover Bob Emily Near Far
- 27. Recommender ? Ann and Emily is near ®C we should recommend Flozen for Ann Name Star Wars Harry Potter Star Trek Titanic Frozen Ann 4 5 °Ô Emily 1 4 2 5 4 I bet Ann would like it!
- 28. Recommender with Feature Extractor ? Recommender server consist of Feature Extractor and Recommender engine. ®C Jubatus calculates distance between feature vectors RecommenderFeature Extractor Recommender Engine can use ? Minhash ? Locality Sensitive Hashing ? Euclid Locality Sensitive Hashing for defining distance.
- 29. Recommender with Feature Extractor ? Jubatus maps data in feature space ®C There are distances between data ? How are they near or far? key value pu 1 ut 1 ... ... {| ... |m 1 m| 1 {| 1 Feature Extractor key value im 1 mp 1 ... ... ... ... °∞{ 1 fo 1 ... ... key value Ma 1 ap 1 ... ... in 1 nt 1 te 1 er 1 Recommender Ruby Python Java
- 30. What Recommender can do? ? You can ®C create recommendation engine in e-commerce ®C calculate similarity of tweets ®C find similar directional NBA player ®C visualize distance between °∞Star Wars°± and °∞Star Trek°±
- 31. What Recommender cannot do? ? You cannot ®C Label data(use classifier!) ®C get decision tree ®C get a-priori based recommendation
- 32. Anomaly Detection ? Task: Which datum is far from the others?
- 33. Anomaly Detection ? Task: Which datum is far from the others? This One!
- 34. Anomaly Detection ? Distance based detection is not good ®C We cannot decide appropriate threshold of distance Distance is equal!
- 35. Anomaly Detection with Feature Extractor ? Anomaly detection server consist of Feature Extractor and anomaly detection engine. ®C Jubatus finds outlier from feature vectors Anomaly Detection Feature Extractor Anomaly Detection Engine can use ? Minhash ? Locality Sensitive Hashing ? Euclid Locality Sensitive Hashing for defining distance.
- 36. Anomaly Detection ? jubaanomaly can do it! ®C It base on local outlier factor algorithm key value pu 1 ut 1 ... ... {| ... |m 1 m| 1 {| 1 Feature Extractor key value im 1 mp 1 ... ... ... ... °∞{ 1 fo 1 ... ... key value Ma 1 ap 1 ... ... in 1 nt 1 te 1 er 1 Anomaly Detection Outlier!
- 37. What Anomaly Detection can do? ? You (might) can ®C find outlier ®C grasp the trend and overview of current data stream ®C detect or predict server's failure ®C protect Web services from zero-day attacks
- 38. What Anomaly Detection cannot do? ? You cannot ®C know the cluster distribution of data ®C find any kinds of outliers with 100% accuracy ®C easily understand how each outlier occurs ®C know why a datum is assigned high outlier score
- 39. Conclusion ? Jubatus have embedded feature extractor with algorithms. ? User should configure both feature extractor and algorithm properly ? Client use configured machine learning via Jubatus-RPC ? Classifier and Recommender and Anomaly may be useful for your task.
- 40. DEMO ? I try to run the jubatus-example.
Editor's Notes
- #2: Hello, I°Øll speak about Jubatus. You may heard about jubatus, but I°Øm afraid you don°Øt know jubatus well. In this speak, I wish you°Ød realize what jubatus can do, or how to use it for your task.
- #3: Jubatus has 3 feature. Jubatus is a distributed online machine-learning framework. Distributed means resilient to machine failure. And Jubatus can increase its performance for your task by coordinate multi-machine cluster. Online means fixed time computation. Jubatus developer carefully designed Jubatus API so that users can balance between performance and computation time. Machine-Learning is key factor of Big Data age. You°Øll need more than °∞word count°±
- #4: This is a overview of Jubatus process. This red rectangle is one Jubatus process. Inside process, there is two component exists. Feature Extractor and Machine-Learning-Model. You can connect your program with jubatus via Jubatus RPC. So you can do machine learning with client-server model.
- #5: You can combine this process in cluster each other. Jubatus in cluster communicate and make more fast and reliable machine learning. Whole model is shared and resilient to machine failure.
- #6: If there are many Jubatus servers running and continue to mixing User can communicate with cluster via jubatus proxy as if it is single jubatus server.
- #7: The communication protocol between Jubatus server and client is completely the same with that of Jubatus proxy and client. It is useful for developers because they can run jubatus in local machine for developing environment, and deploy the client code for production clusters.
- #8: A big benefit of distributed system, Jubatus can scale performance out. In your production environment, if there is too heavy RPC request for the throughput of clusters
- #9: You can append machine to cluster, cluster will increase its performance. It is suitable for Cloud Computing era.
- #10: And jubatus cluster is resilient for cluster failure. Whenever servers break down, the proxy server conceal the machine failure so the service will continue. So you can append or remove cluster machine dynamically.
- #11: And Jubatus client library is implemented in many language. you can get jubatus client library via gem, pip, cpan, maven. If you want to use it in other language, you can use messagepack-rpc client with your own risk. It will work! (I tried Javascript
- #12: And Jubatus has many kind of machine-learning module. You can use these machine learning rapidly. Among 6 machine learning modules, Classsifier and Recommender and Anomaly Detection will be great help of you. I°Øll introduce these 3 machine learning modules.
- #13: classifier can classify data. A sample task, you may want to detect programming language of source code. In this case, you can classify language from sequence of text.
- #14: First of all, you have to set configuration in the jubatus server. The configuration is written in JSON.
- #15: In this case, you choose embedded ngram function, and passing number 2 to ngram. You can get bigram function. And set rule. In this rule, all data inserted will be handled with bigram. Regulating the weights of words with tf/idf scheme.
- #16: Now, the Feature Extractor becomes °∞bigram extractor°±
- #17: with this bigram extractor, all datum to be splited into two character words. °∞import°± will become °∞im°±, °∞mp°±, °∞po°±, °∞or°±, °∞rt°± with bigram scheme. This form of datum representation if Feature Vector. bigram extractor extracts bigram from datum and get Feature Vector.
- #18: You extracting feature vectors from many language source code. Jubatus Classifier learns from feature vectors and create model.
- #19: Next, the classifier algorithm should be configured. You can select Classifier Algorithm from Perceptron or Passive Aggressive or the others.
- #20: the trained model can classify datum from feature vector. In this case, Jubatus classifier finds a Ruby characteristic feature like "{|" and highly score for ruby, then Jubatus estimate this source code is Ruby.
- #21: Another datum, Jubatus find Python characteristic feature like °∞):°± Jubatus scores high for this feature and it estimate this source code should be python.
- #22: You can do these procedure via Jubatus RPC. On RPC, giving datum for classification, and Jubatus returns the classification result. All you have to do is write precise JSON configuration and client source code.
- #23: You can estimate the topic of a tweet trash spam mail automatically monitor server failure from syslog estimate sentiment from blog post detect attacking via network calculate what feature is the best clue to classification
- #24: You cannot train model from data without supervised answer create a class without knowledge of the class get fine model without correct feature designing
- #25: Other information for using classifier is available at jubatus official example repository. These 4 sample may be useful for study.
- #26: Next Jubatus algorithm is recommender. With this °∞movie and review rating matrix°± which movie should we recommend Ann? Jubatus can answer.
- #27: An imaginary field of highly dimensional rating space. Star Wars lover and Star Trek lover is relatively close. Both of them movie is a kind of Science Fiction. Ann and Emily is relatively close. These distance is useful for recommendation. Because Preferences of the human is tend to be similar.
- #28: In this case, Ann would like Frozen
- #29: Jubatus recommender server consists of Feature Extractor and recommender engine. Feature extractor is completely the same with classifier°Øs one. Jubatus calculates distance between feature vectors.
- #30: From former example, jubatus recommender extracts feature vector from source code, and recommender engine maps each vectors in feature space.
- #31: You can create recommendation engine calculate similarity of tweets find similar directional NBA player visualize distance between °∞Star Wars°± and °∞Star Trek notice that you can use recommender more than recommender.
- #32: Recommender is based on unsupervised algorithm. So that You cannot Labeling data(use classifier!) get decision tree And it is nearest-neighbor based recommendation so that get a-priori based recommendation
- #33: Another algorithm is Anomaly Detection It calculates °∞How this datum is far from others?°±
- #34: Jubatus can detect the outlier from mass of data.
- #35: In easy way, you may use recommender°Øs distance score for finding outlier Distance is not homogeneous, it can not be used to discover outliers.
- #36: anomaly detection server consists of Feature Extractor and anomaly detection engine. Feature extractor is completely the same with classifier and recommender°Øs one. Jubatus finds outlier from feature vectors
- #37: The same wit recommender, Jubatus detect anomaly from Feature Vector You should access this procedure via RPC too.
- #38: You (might) can find outlier detect or prediction of server°Øs failure protect service against zero-day attack know the trend of the entire data stream
- #39: You cannot get mostly common datum get cluster map of data give a diagnosis the outlier reason automatically
- #40: Jubatus have embedded feature extractor with algorithms. User should configure both feature extractor and algorithm properly Client use configured machine learning via Jubatus-RPC Classifier and Recommender and Anomaly may be useful for your task.
- #41: I try to run the jubatus-example.