K-means hashing (CVPR'13) §»•œ•√•∑•Û•∞÷ЧÍ
15 likes10,731 views

K-means hashing (CVPR'13) §Œ’ìŒƒΩ‚’h§»°¢ÈvþB§π§Î iterative quantization §‰ optimized product quantization §ŒΩBΩÈ°¢◊ÓΩ¸§Œhashingœµ’쌃•Í•π•»°£








![Affinity preserving k-means (1)
•œ•þ•Û•∞æýÎx§«Ω¸À∆§π§Î§≥§»§Úøºë]§∑§øk-means
Õ®≥£§Œk-means§Œ•≥•π•»Èv ˝
Affinity§ÀÈv§π§ÎÌó§Ú◊∑º”
Affinity preserving k-means§Œ•≥•π•»Èv ˝
£®¶À = 0 §«Õ®≥£§Œk-means£©
ni: ¥˙±Ì•Ÿ•Ø•»•Î ci §À∏ӧ͵±§∆§È§Ï§ø
”ñæö•Ÿ•Ø•»•Î§Œ ˝](https://image.slidesharecdn.com/k-meanshashingup-130727220445-phpapp01/85/K-means-hashing-CVPR-13-10-320.jpg)










![[DLðÜ’iª·]Unsupervised Learning by Predicting Noise](https://cdn.slidesharecdn.com/ss_thumbnails/dlrinkonat-170512005324-thumbnail.jpg?width=560&fit=bounds)

















![SSII2021 [SS1] Transformer x Computer Vision§Œ ågªÓ”√ø…ƒÐ–‘§»’πÕ˚ ? Transformer§ŒCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=560&fit=bounds)



![[DLðÜ’iª·]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=560&fit=bounds)






More Related Content
What's hot (20)
Similar to K-means hashing (CVPR'13) §»•œ•√•∑•Û•∞÷Ð§Í (20)















![[DL Hacks] code_representation](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackscoderepresentation-190509074441-thumbnail.jpg?width=560&fit=bounds)

![[DLðÜ’iª·]RobustNet: Improving Domain Generalization in Urban- Scene Segmentatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20210625robustnetlin-210625020332-thumbnail.jpg?width=560&fit=bounds)
More from Yusuke Uchida (20)




















Recently uploaded (11)











K-means hashing (CVPR'13) §»•œ•√•∑•Û•∞÷ЧÍ
- 1. K-means Hashing: an Affinity-Preserving Quantization Method for Learning Binary Compact Codes Yusuke Uchida (@yu4u) KDDI R&D Laboratories, Inc.
- 2. ±≥æ∞ ? ª≠œÒÃÿè’ ®C SIFT: 128¥Œ‘™, GIST: 960 (384) ¥Œ‘™, FV/VLAD: °´ ˝ÕÚ¥Œ‘™ ®C 1M°´1B√∂•Ï•Ÿ•Î§Œª≠œÒó À˜§»§´§∑§ø§§§™°≠ ®C §«§‚ª≠œÒ§ŒÃÿè’•Ÿ•Ø•»•Î§Ω§Œ§‚§Œ§Ú¿˚”√§π§Î§» •·•‚•Í§ÀÅ\§È§ §§§∑ÓêÀ∆ó À˜§‚§™§Ω§§§™°≠ ®C §¿§´§È•≥•Û•—•Ø•»§ •–•§• •Í•≥©`•…§Àâ‰ìQ§π§Î§™£°£®•∆•Û•◊•Ï£© £®√Ê∞◊§§§±§…èÍ”√§Úöð§À§∑§∆§§§Î»À§¨§¢§Û§Þ§§§ §§”°œÛ£© ? •–•§• •ÍªØ§Œ•·•Í•√•» ®C •≥•Û•—•Ø•»£´∏þÀŸó À˜ (e.g., SSE 4.2 POPCNT) £®≤Œøº£©•”•√•»§Ú ˝§®§Î http://www.slideshare.net/takesako/x86x64-sse42-popcnt ? ÖgºÉ§À•Ê©`•Ø•Í•√•…æýÎx§ÚΩ¸À∆§π§Î§≥§»§¨ƒøµƒ§Œ ÷∑®§» supervised§«•Ø•È•π∑÷Óê§Ú“‚◊R§∑æýÎx—ߡ蓼––§¶ ÷∑®§¨§¢§Î
- 3. Hashing "Similarity search in high dimensions via hashing," VLDB'99. (LSH) "Spectral Hashing," NIPS'08. (SH) "Learning to Hash with Binary Reconstructive Embeddings," NIPS'09. (BRE) "Locality Sensitive Binary Codes from Shift-Invariant Kernels," NIPS'09. (SIKH) "Kernelized Locality-Sensitive Hashing for Scalable Image Search," ICCV'09. (KLSH) "Sequential Projection Learning for Hashing with Compact Codes," ICML'10. (USPLH) "Self-Taught Hashing for Fast Similarity Search," SIGIR'10. "CARD: Compact And Real-time Descriptors," ICCV'11. "Complementary Hashing for Approximate Nearest Neighbor Search," ICCV'11. "Coherency Sensitive Hashing," ICCV'11. "Hashing with Graphs," ICML'11. (AGH) "Minimal Loss Hashing for Compact Binary Codes," ICML'11. "Random Maximum Margin Hashing," CVPR'11. "Iterative Quantization: A Procrustean Approach to Learning Binary Codes," CVPR'11. (ITQ) "LDAHash: Improved Matching with Smaller Descriptors," PAMI'12. (LDAH) "Isotropic Hashing," NIPS'12. "Supervised Hashing with Kernels," CVPR'12. "Spherical Hashing," CVPR'12. "Multidimensional Spectral Hashing," ECCV'12. "Double-Bit Quantization for Hashing," AAAI'13. "Variable Bit Quantisation for LSH," ACL'13. "Hash Bit Selection: a Unified Solution for Selection Problems in Hashing," CVPR'13. "Compressed Hashing," CVPR'13. "Inductive Hashing on Manifolds," CVPR'13. "Learning Binary Codes for High-Dimensional Data Using Bilinear Projections," CVPR'13. "K-means Hashing: an Affinity-Preserving Quantization Method for Learning Binary Compact Codes," CVPR'13. °˝∫√§≠§ •≠©`•Ô©`•…§Ú»Î§Ï§∆§Õ£°
- 4. Hashing§Œª˘±æ "Semi-Supervised Hashing for Large Scale Search," TPAMI'12. sgn(Wx - t) §À§Ë§Í b-bit •–•§• •Í•≥©`•…§Ú«Û§·§Î ÷∑®§¨∂ý§§ d¥Œ‘™»Î¡¶•Ÿ•Ø•»•Î …‰”∞––¡– (b x d) ∂® ˝Ìó °¸§≥§Œ…‰”∞––¡–§Ú§§§´§À«Û§·§Î§´§Àé¢◊≈ ª˘±æëȬ‘§œâ‰ìQ··§Œ•–•§• •Í•≥©`•…Èg§Œ•œ•þ•Û•∞æýÎx§À ‘™§ŒÃÿè’•Ÿ•Ø•»•ÎÈg§ŒæýÎx§Ú∑¥”≥§µ§ª§Î °˘SH§Œ§Ë§¶§Àlaplacian eigenmapsµ»§« …‰”∞§∑§øø’Èg§«Hashing§π§Î§‚§Œ§‚∂ý§§ e.g., AGH http://www.slideshare.net/beam2d/rinko2011-web
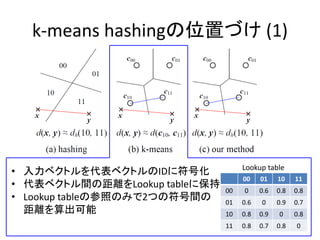
- 5. k-means hashing§ŒŒª÷√§≈§± (1) 00 01 10 11 00 0 0.6 0.8 0.8 01 0.6 0 0.9 0.7 10 0.8 0.9 0 0.8 11 0.8 0.7 0.8 0 ? »Î¡¶•Ÿ•Ø•»•Î§Ú¥˙±Ì•Ÿ•Ø•»•Î§ŒID§À∑˚∫≈ªØ ? ¥˙±Ì•Ÿ•Ø•»•ÎÈg§ŒæýÎx§ÚLookup table§À±£≥÷ ? Lookup table§Œ≤Œ’’§Œ§þ§«2§ƒ§Œ∑˚∫≈Èg§Œ æýÎx§ÚÀ„≥ˆø…ƒÐ Lookup table
- 6. k-means hashing§ŒŒª÷√§≈§± (2) ? •Ÿ•Ø•»•Î¡ø◊”ªØ§»Õ¨òî§À»Î¡¶•Ÿ•Ø•»•Î§Ú¥˙±Ì•Ÿ•Ø•»•Î§À∏ӧ͵±§∆ ? ∏˜¥˙±Ì•Ÿ•Ø•»•Î§À•–•§• •Í•≥©`•…§¨∏ӧ͵±§∆§È§Ï§∆§™§Í°¢ §Ω§Œ•–•§• •Í•≥©`•…§À∑˚∫≈ªØ§π§Î ? •Ø•®•Í•Ÿ•Ø•»•Î§‚Õ¨òî§À•–•§• •ÍªØ°¢•œ•þ•Û•∞æýÎx§«ÓêÀ∆ÃΩÀ˜ ? •Ÿ•Ø•»•Î¡ø◊”ªØ§œ¡ø◊”ªØ’`≤Ó§Œ”Qµ„§«Éû–„£¶POPCNT∏þÀŸÃΩÀ˜ ∑˚∫≈ªØÑø¬ æýÎx”ãÀ„ÀŸ∂»
- 7. ”ý’Ñ£∫¡ø◊”ªØ§¢§Ï§≥§Ï ? •Ÿ•Ø•»•Î¡ø◊”ªØ ? ÎA唡ø◊”ªØ ? ≤–≤Ó¡ø◊”ªØ ? ÷±∑e¡ø◊”ªØ ? •π•´•È¡ø◊”ªØ£®•œ•√•∑•Û•∞£© ∑˚∫≈ªØÑø¬ Lookup tableµ»§«¨Fågµƒ§ÀæýÎx”ãÀ„§¨§«§≠§Î
- 8. k-means hashing§Œ•≥•Û•ª•◊•» •™•Í•∏• •Î•Ÿ•Ø•»•Î x, y Èg§ŒæýÎx x§Ú¡ø◊”ªØ§∑§ø •Ÿ•Ø•»•Î x§¨¡ø◊”ªØ§µ§Ï§ø ¥˙±Ì•Ÿ•Ø•»•Î§ŒID •Ÿ•Ø•»•Î¡ø◊”ªØ k-means hashing •π•±©`•Í•Û•∞∂® ˝ i, j∑¨ƒø§Œ¥˙±Ì•Ÿ•Ø•»•Î§À∏ӧ͵±§∆§È§Ï§ø •–•§• •Í•≥©`•…Èg§Œ•œ•þ•Û•∞æýÎx ¥˙±Ì•Ÿ•Ø•»•ÎID°˙•–•§• •Í•≥©`•…§ÿ§Œ∏ӧ͵±§∆ £®£Ωpermutation £©§Ú«Û§·§ÎÜñÓ}§ÿé¢◊≈
- 9. • •§©`•÷§ •¢•◊•Ì©`•¡ »´§∆§Œ¥˙±Ì•Ÿ•Ø•»•Î§ŒΩM§þ∫œ§Ô§ª§À§ƒ§§§∆ ¥˙±Ì•Ÿ•Ø•»•ÎÈg§ŒæýÎx§»∏ӧ͵±§∆§È§Ï§ø•–•§• •Í•≥©`•…§Ú ª˘§À§∑§øæýÎx§Œ∂˛Å\’`≤Ó§Ú◊Ó–°ªØ§»§π§Î §Ú«Û§·§Î 1) k-means§À§Ë§Í2bÇħŒ¥˙±Ì•Ÿ•Ø•»•Î§Ú◊˜≥… 2) ◊Óþm§ ¥˙±Ì•Ÿ•Ø•»•Î§ÿ§Œ•–•§• •Í•≥©`•…§Œ∏ӧ͵±§∆§Ú«Û§·§Î ? ”ãÀ„¡ø O((2b)!) °˙ b=4 §Œætµ±§Í§«1»’ ? ¥˙±Ì•Ÿ•Ø•»•ÎÈg§ŒæýÎx§¨»Œ“‚§ŒπÝáϧڧ»§Î £®•œ•þ•Û•∞æýÎx§«Ω¸À∆§π§Î§≥§»§Ú•±•¢§∑§∆§§§ §§£© °˙ ætµ±§Í§Œ◊ÓþmªØ§«§‚·· ˆ§Œ ÷∑®§Ë§ÍµÕ–‘ƒÐ Affinity matrix d(?,?) §» dh(?,?) §Œ •’•Ì•Ÿ•À•¶•π•Œ•Î•ý◊Ó–°ªØ
- 10. Affinity preserving k-means (1) •œ•þ•Û•∞æýÎx§«Ω¸À∆§π§Î§≥§»§Úøºë]§∑§øk-means Õ®≥£§Œk-means§Œ•≥•π•»Èv ˝ Affinity§ÀÈv§π§ÎÌó§Ú◊∑º” Affinity preserving k-means§Œ•≥•π•»Èv ˝ £®¶À = 0 §«Õ®≥£§Œk-means£© ni: ¥˙±Ì•Ÿ•Ø•»•Î ci §À∏ӧ͵±§∆§È§Ï§ø ”ñæö•Ÿ•Ø•»•Î§Œ ˝
- 11. Affinity preserving k-means (2) 1) Assignment step: {ci} §ÚπÃ∂®§∑°¢i(x) §Ú◊ÓþmªØ k-means§»Õ¨òî§À◊ÓΩ¸∞¯§Œ¥˙±Ì•Ÿ•Ø•»•Î§À∏ӧ͵±§∆ 2) Update step: i(x) §ÚπÃ∂®§∑°¢{ci} §Ú◊ÓþmªØ AffinityÌó§œ {ci} §¨œýª•§ÀÈvÇS§∑§∆§§§Î§Œ§«Ìò§À◊ÓþmªØ {ci}, i(x), s §Œ≥ı∆⁄ªØ§œPCA-Hashing§Ú”√§§§Î ÷∆ºs§ §∑◊ÓþmªØ°¢ú •À•Â©`•»•Û∑®§«Ω‚§Ø£®matlab§«fminunc£°£© 50°´200 ¿R§Í∑µ§∑ GIST, b=8 §«20∑÷ ¨Fågµƒ§À§œ b®Q8°¢§Ω§Ï“‘…œ§Œ•≥©`•…§œ÷±∑e¡ø◊”ªØ§Ú¿˚”√
- 12. ≤Œøº£∫Iterative quantization (ITQ) http://www.cs.illinois.edu/homes/slazebni/slides/similarity_preserving_binary_codes.pptx •–•§• •Í•œ•√•∑•Û•∞§Ú¡ø◊”ªØ§»◊Ω§®§Î ¡ø◊”ªØ’`≤Ó§¨◊Ó–°§»§ §ÎªÿÐû§Ú«Û§·§Î °˙ ÷±Ωª•◊•Ì•Ø•È•π•∆•πÜñÓ} ITQ§«§œ•π•±©`•Í•Û•∞ÇS ˝s§œ◊ÓþmªØ§À”∞Ìë§∑§ §§ PCAH ITQ •≥©`•…•÷•√•Ø£∫ £®‘Ÿí˜£©
- 13. ågÚY ? •™•Í•∏• •Î§ŒÃÿè’•Ÿ•Ø•»•Î§ŒKΩ¸∞¯§Ú’˝Ω‚§»§π§Î ? •–•§• •Í•≥©`•…§Œ•œ•þ•Û•∞æýÎx§«Ω¸∞¯ÃΩÀ˜§Ú––§§ …œŒªXº˛§À’˝Ω‚§¨∫Œ∏Ó•´•–©`§µ§Ï§∆§§§Î§´ £Ω‘Ÿ¨F¬ (recall) §«‘uÅ˝ ? •«©`•ø•ª•√•»£∫SIFT1M, GIST1M ®C À˚§À§Ë§Ø π§Ô§Ï§Î§Œ§œ ? CIFAR•«©`•ø•ª•√•» http://www.cs.toronto.edu/~kriz/cifar.html ? MNIST•«©`•ø•ª•√•» http://yann.lecun.com/exdb/mnist/ ®C Ω¸∞¯ÃΩÀ˜··°¢•È•Ÿ•Î§Ú’˝Ω‚§»§∑§∆MAP§«‘uÅ˝§π§Î§≥§»§‚
- 14. SIFT1M dataset KMH: k-means hashing ITQ: iterative quantization MLH: minimal loss hashing SH: spectral hashing PCAH: PCA hashing LSH: locality sensitive hashing KMH PCAH MLH KMH LSH ? 32bit§«PCAH§¨¡º§§£®SH§‚£© ? 128bit§«§œITQ§»LSH§¨¡º§§ £®LSH§‰SKLSH§œ÷±ΩªÃıº˛§¨§ §§§Œ§« •”•√•»§Úâ৉§π§€§…æ´∂»œÚ…œ£© ITQ SH
- 15. GIST1M dataset KMH: k-means hashing ITQ: iterative quantization MLH: minimal loss hashing SH: spectral hashing PCAH: PCA hashing LSH: locality sensitive hashing ? KMH, MLH, ITQ§¨¡º§§ ? PCAH§¨32bit§«§‚êô§§ £®πÔ–Ç飮∑÷…¢£©§¨¥Û§≠§Øþ`§¶§ø§·£ø£© KMH MLH ITQ PCAH
- 16. ”ý’Ñ °∞Optimized Product Quantization for Approximate Nearest Neighbor Search,°± CVPR°Ø13. ITQ PCA··§À•È•Û•¿•ýªÿÐû ? PCA+•È•Û•¿•ýªÿÐû§«§‚ΩYò㡺§§
- 17. ≤Œøº£∫÷±∑eø’Èg§Œ∑÷∏Ó§Œ◊ÓþmªØ °∞Optimized Product Quantization for Approximate Nearest Neighbor Search,°± CVPR°Ø13. °∞Cartesian k-means,°± CVPR°Ø13. §…§¡§È§‚•¢•◊•Ì©`•¡§œ§€§ÐÕ¨§∏£®§…§¡§È§‚ITQ§Àinspire§µ§Ï§∆§§§Î£ø£© Ãÿè’•Ÿ•Ø•»•Î§Ú…‰”∞§π§ÎªÿÐû––¡–§»÷±∑e¡ø◊”ªØ•≥©`•…•÷•√•Ø§Ú◊ÓþmªØ 1) R§ÚπÃ∂®§∑§∆÷±∑e¡ø◊”ªØ§Œ•≥©`•…•÷•√•Ø§Ú◊ÓþmªØ 2) ÷±∑e¡ø◊”ªØ•≥©`•…•÷•√•Ø§ÚπÃ∂®§∑§∆R§Ú◊ÓþmªØ http://www.robots.ox.ac.uk/~vgg/rg/slides/ge__cvpr2013__optimizedpq.pdf
- 18. ≤Œøº£∫Asymmetric Hamming Distance ? •–•§• •Í•≥©`•…Èg§ŒæýÎx§Œ¥˙§Ô§Í§À •Ø•®•Í§Œ•™•Í•∏• •Î§ŒÃÿè’•Ÿ•Ø•»•Î£®¡ø◊”ªØ«∞£©§» DBƒ⁄§Œ•–•§• •Í•≥©`•…§ŒæýÎx§Ú”ãÀ„ ? ÷±∑e¡ø◊”ªØ§«§‚¿˚”√§µ§Ï§∆§§§Î£®§≥§¡§È§Œ§€§¶§¨◊‘»ª£© "Asymmetric Hamming Embedding," ICMR'11. "Asymmetric Distances for Binary Embeddings," CVPR'11. "Product Quantization for Nearest Neighbor Search," TPAMI'11.
- 19. §Þ§»§· ? k-means hashing: •Ÿ•Ø•»•Î¡ø◊”ªØ§Œ ∑˚∫≈ªØÑø¬ §»•–•§• •ÍÃÿè’§Œ∏þÀŸ§ ÓêÀ∆ÃΩÀ˜ ? PCA+•È•Û•¿•ýªÿÐû§Œ•œ•√•∑•Â§«§‚ΩYò㡺§§