


![ÄŸ€ÎșB„ł„č„È
? ÄŸ€ÎÔìTĄąm·ŹÄż€Î„ż©`„ß„Ê„ë„Ω`„É? ? Ąą ? ? ÖĐ€ÎÀęî}Êę
??
? ? ? €Ë€Ș€€€ÆĄą„é„Ù„ë€Źg€Ë€Ê€ëŽ_ÂÊ
1
? ?,? = ?[? ? = ?]
? ?
? ? ? €Ë€Ș€±€ë„é„Ù„ë€ÎÓèy
?(m) = argmax ? ? ?,?
? T€Ë€Ș€±€ë„Ω`„Ém€Î„ł„č„È? ? (?)
1. „ž„ËSÊę ? ? ? = ? ?,? ? ?,?Ąä = ? ?,? (1 ? ? ?,? )
?
2. „š„ó„È„í„Ô©` ? ? ? = ?=1 ? ?,? ???? ?,?
6](https://image.slidesharecdn.com/10-130303234805-phpapp02/85/10-6-320.jpg)


![Ÿö¶šÄŸ in R
library(rpart) ; library(mlbench)
data(Glass)
nrow(Glass) # Ąú 214
head(Glass) # 9€Ä€Î„Ç©`„ż€È7€Ä€ÎType
table(Glass$Type) # žśType€ÎÊę
set.seed(1) # ÂÒÊę€Î·N€òÖž¶š
# ѧÁ„Ç©`„ż
tra.index <- sample(nrow(Glass), nrow(Glass)*0.7) # „é„ó„À„à„”„ó„Ś„ê„ó„°
# „ž„ËSÊę€ÇѧÁ split= Ą°informationĄ± €Ç„š„ó„È„í„Ô©`
res <- rpart(Type~., Glass[tra.index,], method=Ą°classĄ±, parms=list(split=Ą°giniĄ±))
pred <- predict(res,Glass,type=Ą°classĄ±) # „é„Ù„ë€ÎÓèy
mean(pred[tra.index]!=Glass$Type[tra.index]) # ÓŸŐ`Čî ĆĐeÆś€òłÉ€č€ëëH€ÎѧÁ„Ç©`„ż€ÎŐ`€êÂÊ
mean(pred[-tra.index]!=Glass$Type[-tra.index]) # ÓèyŐ`Čî ÎŽÖȘ€Î„Ç©`„ż€Ë€č€ëŐ`€êÂÊ
# Ÿö¶šÄŸ€Î±íÊŸ
plot(res);text(res)
9](https://image.slidesharecdn.com/10-130303234805-phpapp02/85/10-9-320.jpg)

![pʧĐĐÁĐ€ÈÊÂÇ°Ž_ÂÊ
? „Ż„é„耎€È€Î„”„ó„Ś„ëÊę€Ë€è€Ă€ÆŐ`ĆĐe€ÎÖŰ€”€Źź€Ê€ë
>table(Glass$Type) Glass€Î„Ç©`„ż€ÏŚó€Î€è€Š€Ë€Ê€Ă€Æ€€€ëĄŁ
1 2 3 5 6 7 €æ€š€ËĄą„”„ó„Ś„ëÊꀏÉـʀ€„Ż„é„č€Ç€ą€ë3,5,6
70 76 17 13 9 29 €òŐ`ĆĐe€č€ë„ł„č„È€ÏĐĄ€”€€ĄŁ
[,1] [,2] [,3] [,4] [,5] [,6]
[1,] 0 1 100 100 100 1
[2,] 1 0 100 100 100 1
€œ€ł€ÇĄąŚóí€Î€è€Š€ÊpʧévÊę€ò§È뀷Ąą3,5,6
[3,] 1 1 0 100 100 1
[4,] 1 1 100 0 100 1 €ÎŐ`ĆĐe€Î„ł„č„È€ò100±¶€Ë€·€Æ€ß€ë
[5,] 1 1 100 100 0 1
[6,] 1 1 100 100 100 0
0.1666667 0.1666667 Ą
€Ț€ż„Ń„ż©`„óŐJŚR€Î±Ÿ€Ç€ÏÒ»·ÖČŒ€òą¶š€·€ż
·ÖÎö€âșπ€ÆĐĐ€Ă€Æ€€€ë
13](https://image.slidesharecdn.com/10-130303234805-phpapp02/85/10-13-320.jpg)
![pʧĐĐÁĐ€ÈÊÂÇ°Ž_ÂÊ in R
library(rpart) ; library(mlbench)
data(Glass)
set.seed(1)
tra.index <- sample(nrow(Glass),nrow(Glass)*0.7)
# pʧĐĐÁĐ
LOSS <- matrix(1,length(levels(Glass$Type)), length(levels(Glass$Type)))
LOSS[,c(3:5)] <- 100 ; diag(LOSS)<-0
# ѧÁ
res2 <- rpart(Type~., Glass[tra.index,], method="class", parms=list(loss=LOSS))
yhat2 <- predict(res2,Glass,type=Ą°classĄ±) # „é„Ù„ë€ÎÓèy
mean(yhat2[tra.index]!=Glass$Type[tra.index]) # ÓŸŐ`Čî
mean(yhat2[-tra.index]!=Glass$Type[-tra.index]) # ÓèyŐ`Čî
table(true=Glass$Type, prediction=yhat2) # ĆĐeœYčû
# Ò»·ÖČŒ€ÎöșÏĄúparms=list(prior=rep(1/6,6)
14](https://image.slidesharecdn.com/10-130303234805-phpapp02/85/10-14-320.jpg)

![[DLĘŐi»á]`»ŻŃ§Á€Î€ż€á€ÎŚŽB±íŹFѧÁ Ł€è€êÁŒ€€ĄžÊÀœç„â„Ç„ëĄč€Î«@”Ă€ËÏò€±€ÆŁ](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=560&fit=bounds)
![[DLĘŐi»á]Understanding Black-box Predictions via Influence Functions](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksinffunc-170822055634-thumbnail.jpg?width=560&fit=bounds)


![[DLĘŐi»á]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)














![[DLĘŐi»á]Deep Learning ”Ú15Ő ±íŹFѧÁ](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=560&fit=bounds)








More Related Content
What's hot (20)
Viewers also liked (20)



















Similar to „Ń„ż©`„óŐJŚR ”Ú10Ő Ÿö¶šÄŸ (20)















![[ICLR/ICML2019Ői€ß»á] Data Interpolating Prediction: Alternative Interpretation ...](https://cdn.slidesharecdn.com/ss_thumbnails/20190721shimada-190721024027-thumbnail.jpg?width=560&fit=bounds)

![[Ridge-i ŐÎÄŐi€ß»á] ICLR2019€Ë€Ș€±€ëČ»ÍêÈ«„é„Ù„ëѧÁ](https://cdn.slidesharecdn.com/ss_thumbnails/yomikaiiclr2019-190510070433-thumbnail.jpg?width=560&fit=bounds)


„Ń„ż©`„óŐJŚR ”Ú10Ő Ÿö¶šÄŸ
- 1. Ÿö¶šÄŸ |Ÿ©Žóѧ ÈęșĂĐÛÒČ 1
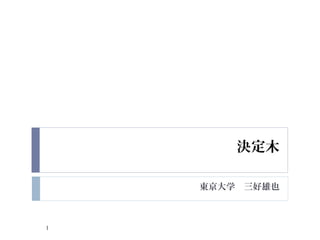
- 2. Ÿö¶šÄŸ ? Ÿö¶šÄŸ€È€ÏĄą„Ç©`„ż€ÎÌŰŐÁż€òÓĂ€€€żș g€Ê„ë©`„ë€Ç·ÖáȘ€ò Śś€êĄąÌŰŐżŐég€ò·Öžî€č€ë€ł€È€òÍš€ž€ÆĆĐe€ä»Űą€òĐĐ€Š„â „Ç„ë€Î€ł€È ? „â„Ç„ë€Î·NîŁșCART€äC4.5(C5.0) ? CART 1. ÄŸ€ÎșBŁșș΀逫€Î»ùÊ€òș€ż€č€Ț€ÇĄąÓè€á¶šÁx€·€Æ€Ș€€€ż„ł„č„Ȁ˻ù €Ć€€€ÆÌŰŐżŐég€ò2·Öžî€č€ëÊÖŸA€€òÀR€ê·”€č 2. Œô¶š(pruning)ŁșșB€”€ì€żÄŸ€ÎÉ€ŹÉ€Û€ÉŃ}ëj€Ê„Ç©`„ż€òQ€Š€ł €È€Ź€Ç€€ë€ŹĄąß^ѧÁ€ÎżÉÄÜĐÔ€Ź€ą€ëĄŁ€œ€ł€ÇĄąß^ѧÁ€ò·À€°€ż€áĄąÓè €á¶š€á€Æ€Ș€€€ż„Ń„é„á©`„ż€Ë€è€Ă€Æ„â„Ç„ë€ÎŃ}ëj¶È€òÖÆÓù€č€ë€ł€È ? Àû”ăŁșžßŽÎÔȘ€ÎĆĐe€ŹÈĘÒŚ€ËÒҔĀˎ_ŐJ€Ç€€ë 2
- 3. Ÿö¶šÄŸ€Î„€„á©`„ž „ë©`„ȄΩ`„É ŸĐλ۹ „ż©`„ß„Ê„ë„Ω`„É 3
- 4. ·Öî€ÎżŒ€š·œ ·Öî€ÎżŒ€š·œ ? Àꀚ€ĐĄą€ą€ëÉÌÆ·€òÙÈë€č€ë€«·ń€«€òŚî€âÁŒ€ŻŐhĂś€č€ë·Öî€òŚśłÉ€č €ë€È€č€ëĄŁ€ł€ÎrĄą·Ö€ì€ż„Ç©`„ż€ŹÙI€ŠĄąÙI€ï€Ê€€€Ç€€ì€€€Ë·Ö€± €é€ì€ì€ĐĄą€œ€ì€ÏĄžŒ»€Ç€ą€ëĄč€È€”€ì€ëĄŁ ? ·Öî€Ë€è€êĄąŒ»Ż€·€Æ€€€ŻŚśI€ŹŸö¶šÄŸ 4
- 5. Ÿö¶šÄŸ€ÎÊÖ·š ? CART(Classification And Regression Trees) ? Č»Œ¶È€ò±í€čGINISÊę€ò»ùʀ˷֞î ? „Ω`„É€ò·ÖáȘ€”€»€ë€ł€È€Ë€è€Ă€ÆĄąČ»Œ¶È€ŹpÉÙ€č€ëŁšŁœ·ÖáȘ áá€Î€œ€ì€Ÿ€ì€Î„Ω`„ɀΌ¶È€Ź€čŁ©€è€Š€Ê·ÖáȘ”ă€òÌœ€č ? ĄžŒ¶È€Ź€čĄčŁœĄž„Đ„é„Ä„€ŹÉـʀŻ€Ê€ëĄč ? C4.5(C5.0) ? „š„ó„È„í„Ô©`€Ë»ù€Ć€Ż„Č„€„ó±È€È€€€Š»ùʀǷ֞î 5
- 6. ÄŸ€ÎșB„ł„č„È ? ÄŸ€ÎÔìTĄąm·ŹÄż€Î„ż©`„ß„Ê„ë„Ω`„É? ? Ąą ? ? ÖĐ€ÎÀęî}Êę ?? ? ? ? €Ë€Ș€€€ÆĄą„é„Ù„ë€Źg€Ë€Ê€ëŽ_ÂÊ 1 ? ?,? = ?[? ? = ?] ? ? ? ? ? €Ë€Ș€±€ë„é„Ù„ë€ÎÓèy ?(m) = argmax ? ? ?,? ? T€Ë€Ș€±€ë„Ω`„Ém€Î„ł„č„È? ? (?) 1. „ž„ËSÊę ? ? ? = ? ?,? ? ?,?Ąä = ? ?,? (1 ? ? ?,? ) ? 2. „š„ó„È„í„Ô©` ? ? ? = ?=1 ? ?,? ???? ?,? 6
- 7. „ž„ËSÊę€È„š„ó„È„í„Ô©` ? „ž„ËSÊę€Ç·Öî ? Č»Æœ”È€”€òÊŸ€čÖžË 0~1€Îég€Î€òÈĄ€êĄą0€ÇÆœ”È ? „ž„ËSÊꀏŚî€â”ÍÏ€č€ë€è€Š€Ë·Öî€č€ëĄŁ ? „š„ó„È„í„Ô©`€Ë»ù€Ć€Ż„Č„€„óŁšÇéóÀû”ĂŁ©±È ? ÇéóÁż€òy€ë֞ˣšÎïÀí€Ç€Ïá€äÎïÙ|€ÎÉą¶È€òÊŸ€č֞ˣ© ? ÇéóÁżŁșŽ_ÂÊp€ÇÆđ€ł€ëÊÂÏó€ÎÇéóÁż€Ï Ł???2 ? €Ç¶šÁx€”€ì€ë ? ???2 ?€Îœ~€ŹŽó€€€ŁœÇéóÁż€Ź¶à€€ ? „š„ó„È„í„Ô©`Łš Ł ? ? ?,? ???? ?,? Ł©€Ź”Í€€€Û€É„Ω`„ɀΌ¶È€Ïžß€€ ?=1 7
- 8. „ž„ËSÊę€È„š„ó„È„í„Ô©`ŁșœÌżÆű€ÎÀę È«Ìć€Ç200€ÎÀęî}€ŹŽæÔÚĄą€œ€ì€Ÿ€ì„Ż„é„耏2€Ä ·Öžî1 ?1 €Ë„Ż„é„č1€Ź75Ąą„Ż„é„č2€Ź25 ?2 €Ë„Ż„é„č1€Ź75Ąą„Ż„é„č2€Ź25 ·Öžî2 ?1 €Ë„Ż„é„č1€Ź50Ąą„Ż„é„č2€Ź100 ?2 €Ë„Ż„é„č1€Ź50Ąą„Ż„é„č2€Ź0 100 75 75 „ž„ËSÊę ·Öžî1 (1? ) ĄÁ2 = 0.1875 200 100 100 150 50 50 50 50 50 ·Öžî2 (1? ) + (1? ) = 0.1666 200 150 150 200 50 50 100 75 75 „š„ó„È„í„Ô©` ·Öžî1 ĄÁlog( ) ĄÁ2 = Ł1.5 200 100 100 150 50 50 50 50 50 ·Öžî2 ĄÁlog( ) + ĄÁlog( ) = Ł0.3962 200 150 100 200 50 50 ŚąÒâŁșC4.5€Ê€É€Ï„š„ó„È„í„Ô©`€Ë»ù€Ć€Ż„Č„€„óŁšÇéóÀû”ĂŁ©±È€òÓĂ€€€ë 8
- 9. Ÿö¶šÄŸ in R library(rpart) ; library(mlbench) data(Glass) nrow(Glass) # Ąú 214 head(Glass) # 9€Ä€Î„Ç©`„ż€È7€Ä€ÎType table(Glass$Type) # žśType€ÎÊę set.seed(1) # ÂÒÊę€Î·N€òÖž¶š # ѧÁ„Ç©`„ż tra.index <- sample(nrow(Glass), nrow(Glass)*0.7) # „é„ó„À„à„”„ó„Ś„ê„ó„° # „ž„ËSÊę€ÇѧÁ split= Ą°informationĄ± €Ç„š„ó„È„í„Ô©` res <- rpart(Type~., Glass[tra.index,], method=Ą°classĄ±, parms=list(split=Ą°giniĄ±)) pred <- predict(res,Glass,type=Ą°classĄ±) # „é„Ù„ë€ÎÓèy mean(pred[tra.index]!=Glass$Type[tra.index]) # ÓŸŐ`Čî ĆĐeÆś€òłÉ€č€ëëH€ÎѧÁ„Ç©`„ż€ÎŐ`€êÂÊ mean(pred[-tra.index]!=Glass$Type[-tra.index]) # ÓèyŐ`Čî ÎŽÖȘ€Î„Ç©`„ż€Ë€č€ëŐ`€êÂÊ # Ÿö¶šÄŸ€Î±íÊŸ plot(res);text(res) 9
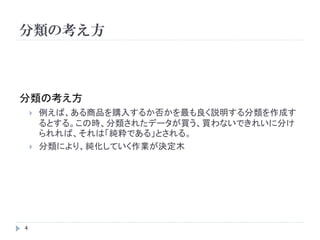
- 10. ÄŸ€ÎŒô¶š(pruning) ? ÄŸTĄŻ€òșB€·€żrĄąT?TĄŻ€òTĄŻ€òŒô¶š€č€ë€ł€È€Ç”Ă€é€ì€ëČż·Ö ÄŸ(subtree)€È€č€ë ? ? Čż·ÖÄŸT€Î„ł„č„È ?ŠÁ (T) = ?=1 ? ? ? ? (?) + ŠÁ ? ? Łș„ż©`„ß„Ê„ë„Ω`„É€ÎÊę ŠÁŁșŒô¶š€òÖÆÓù€č€ë„Ń„é„á©`„ż ? ѧÁ„Ç©`„ż€Îßmê¶È€ÈŠÁ€ÎŽó€€”€Ï„È„ì©`„É„Ș„Ő ? ?0 (T)€Ű€ÎŒÄÓ뀏Х€”€Ê„Ω`„É€«€éí€ËŒô¶š€òĐĐ€Š Ąú ?ŠÁ (T)€òŚîĐĄ€Ë€č€ëČż·ÖÄŸ?ŠÁ €òÌœËś€č€ë ? R€Ç€ÏŠÁ€Ç€Ï€Ê€Ż„Ș„Ś„·„ç„ócp€òÓĂ€€€ë ? ?? (T) = ?0 (T) + cp ? ?0 (?0 ), 0šQ c šQ 1 10
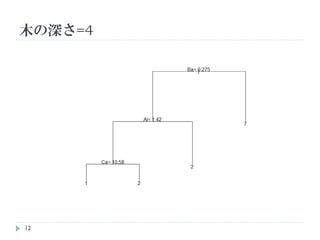
- 11. ÄŸ€ÎŒô¶š€ÈÄŸ€ÎÉ 4 ѧÁ„Ç©`„ż€Îßmê¶È €ż€À€·ĄągëH€Ë€ÏcpšR2€Ç1€Ä€À€±€Î·ÖáȘ€È€Ê€ë 11
- 12. ÄŸ€ÎÉ=4 12
- 13. pʧĐĐÁĐ€ÈÊÂÇ°Ž_ÂÊ ? „Ż„é„耎€È€Î„”„ó„Ś„ëÊę€Ë€è€Ă€ÆŐ`ĆĐe€ÎÖŰ€”€Źź€Ê€ë >table(Glass$Type) Glass€Î„Ç©`„ż€ÏŚó€Î€è€Š€Ë€Ê€Ă€Æ€€€ëĄŁ 1 2 3 5 6 7 €æ€š€ËĄą„”„ó„Ś„ëÊꀏÉـʀ€„Ż„é„č€Ç€ą€ë3,5,6 70 76 17 13 9 29 €òŐ`ĆĐe€č€ë„ł„č„È€ÏĐĄ€”€€ĄŁ [,1] [,2] [,3] [,4] [,5] [,6] [1,] 0 1 100 100 100 1 [2,] 1 0 100 100 100 1 €œ€ł€ÇĄąŚóí€Î€è€Š€ÊpʧévÊę€ò§È뀷Ąą3,5,6 [3,] 1 1 0 100 100 1 [4,] 1 1 100 0 100 1 €ÎŐ`ĆĐe€Î„ł„č„È€ò100±¶€Ë€·€Æ€ß€ë [5,] 1 1 100 100 0 1 [6,] 1 1 100 100 100 0 0.1666667 0.1666667 Ą €Ț€ż„Ń„ż©`„óŐJŚR€Î±Ÿ€Ç€ÏÒ»·ÖČŒ€òą¶š€·€ż ·ÖÎö€âșπ€ÆĐĐ€Ă€Æ€€€ë 13
- 14. pʧĐĐÁĐ€ÈÊÂÇ°Ž_ÂÊ in R library(rpart) ; library(mlbench) data(Glass) set.seed(1) tra.index <- sample(nrow(Glass),nrow(Glass)*0.7) # pʧĐĐÁĐ LOSS <- matrix(1,length(levels(Glass$Type)), length(levels(Glass$Type))) LOSS[,c(3:5)] <- 100 ; diag(LOSS)<-0 # ѧÁ res2 <- rpart(Type~., Glass[tra.index,], method="class", parms=list(loss=LOSS)) yhat2 <- predict(res2,Glass,type=Ą°classĄ±) # „é„Ù„ë€ÎÓèy mean(yhat2[tra.index]!=Glass$Type[tra.index]) # ÓŸŐ`Čî mean(yhat2[-tra.index]!=Glass$Type[-tra.index]) # ÓèyŐ`Čî table(true=Glass$Type, prediction=yhat2) # ĆĐeœYčû # Ò»·ÖČŒ€ÎöșÏĄúparms=list(prior=rep(1/6,6) 14
- 16. Ÿö¶šÄŸ€ÎČ»°Č¶šĐÔ ? Ÿö¶šÄŸ€Îî}”ă ? ĆĐeœYčû€Î·ÖÉą€ŹŽó€€ŻĄą„Ç©`„ż€ŹÉÙ€·ä€ï€Ă€ż€À€±€ÇșB€”€ì€ë ÄŸ€ÎÔì€äĆĐe„ë©`„뀏Žó€€Żä€ï€Ă€Æ€·€Ț€ŠĄŁ ? 14Ő€ÇQ€Š„Đ„ź„󄰔ȀÇÄŸ€Î°Č¶šĐÔ€òy€Ă€Æ€€€ëĄŁ 16