












![OLVQ1 -2
mi (t+1) = mi (t) + ?i (t)ŠÁi (t)(x(t)Ł ? ? (t))
= (1Ł?i (t)ŠÁi (t)) ? ? (t) + ?i (t)ŠÁi (t)x(t)
€”€é€ËŐčé_€·€Æ€€€Ż€ÈĄą
mi (t+1) = (1Ł?i (t)ŠÁi (t))(1Ł? ? (tŁ1)ŠÁi (tŁ1))? ? (t)
+ (1Ł?i (t)ŠÁi (t))? ? (tŁ1)ŠÁi (tŁ1)x(tŁ1)
+ ?i (t)ŠÁi (t) x(t)
?i (t)?i (tŁ1)=0€Î€È€Ąą x(tŁ1) €È x(t) €ÎSÊę€Îœ~€Ź”È€·
€€€È€·Ąą€”€é€ËĄą ?i =1, 0< ŠÁ <1 €òżŒ]€č€ë€ÈĄąŚîœK”Ä€Ë
ŠÁi(??1)
ŠÁi (?) =
1+si (?)ŠÁi (??1)
14](https://image.slidesharecdn.com/9-130303234135-phpapp02/85/9-14-320.jpg)

![ѧÁ„Ù„Ż„È„ë ŁÈëÁŠ„Ç©`„ż in R
library(class) ; library(mlbench)
dim <- 2 # ÈëÁŠżŐég€ÎŽÎÔȘ ; n <- 300 # ѧÁ„Ç©`„żÊę
smpl <- mlbench.corners(n, d=dim, sd=0.25)
x <- smpl$x ; y <- smpl$classes
size <- 8 # Žú±í„Ù„Ż„È„ë€ÎÊę ; k <- 1 # łőÆÚ»Ż
cd <- lvqinit(x,y, size=size, k=k) ; cd3 <- lvq3(x,y,cd)
# ѧÁÇ°áá€ÎĆĐeŸłœç
gsize <- 100 # „°„ê„Äɀ΄”„€„ș
x1 <- seq(min(x[,1]), max(x[,1]), length=gsize)
x2 <- seq(min(x[,2]), max(x[,2]), length=gsize)
xtest <- as.matrix(expand.grid(x1,x2))
yest <- lvqtest(cd, xtest)
yest3 <- lvqtest(cd3, xtest)
cntr <- matrix(match(yest, levels(factor(yest))), gsize, gsize)
cntr3 <- matrix(match(yest3, levels(factor(yest3))), gsize, gsize)
plot(x, col=y, pch=20+as.numeric(y), xlab="x1", ylab="x2",
main="Initial Codebook")
# Žú±í„Ù„Ż„È„ë
points(cd3$x, col=cd3$cl, bg=cd$cl,
pch=20+as.numeric(cd$cl),cex=2)
16](https://image.slidesharecdn.com/9-130303234135-phpapp02/85/9-16-320.jpg)




![[DLĘŐi»á]Deep Learning ”Ú15Ő ±íŹFѧÁ](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=560&fit=bounds)




















![[DLĘŐi»á]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)

![[DLĘŐi»á]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=560&fit=bounds)



More Related Content
What's hot (20)
Viewers also liked (20)


















Similar to „Ń„ż©`„óŐJŚR”Ú9Ő ѧÁ„Ù„Ż„È„ëÁżŚÓ»Ż (20)




















Recently uploaded (10)










„Ń„ż©`„óŐJŚR”Ú9Ő ѧÁ„Ù„Ż„È„ëÁżŚÓ»Ż
- 1. Ń§Ï°„Ù„Ż„È„ë€ÎÁżŚÓ»Ż |Ÿ©Žóѧ ÈęșĂĐÛÒČ 1
- 2. €Ï€ž€á€Ë €«€Ê€êČÎżŒ€Ë€”€»€Æ퀀Ț€·€ż http://www.slideshare.net/sleipnir002/08-09-k-lvq î}€Ź€ą€ì€ĐÏśłę€·€Ț€č 2
- 3. ÁżŚÓ»Ż€È€Ï ? ÁżŚÓ»Ż(Quantization) ? €ą€ëßBŸAÁż€òĄą„Ç©`„żÁżÏśp€Î€ż€á€ËĄąŚî€âœü€€Č»ßBŸAŁšŽú±í„Ù„Ż„È „륹„»„ó„È„í„€„ÉŁ©€ËÖĂ€Q€š€ëŁšœüËÆĄąÇéóRżsŁ©€č€ë€ł€ÈĄŁŁšŸ«¶È€ÏÂä €Á€Ț€čĄŁŁ© ? »ÏńRżs€ËÓĂ€€€é€ì€ż€ê€č€ë€è€Š€Ç€čĄŁ 3
- 4. Ń§Ï°„Ù„Ż„È„ë€ÎÁżŚÓ»Ż€Î„€„á©`„ž 1 ? ÈëÁŠ„Ç©`„ż€òŽú±í„Ù„Ż„È„ë€Ë€è€Ă€Æ·ÖžîœüËÆ€č€ë€È€€€Š”ă€Ç €Ïk-means€ÈÄż”Ä€òÍŹ€ž€Ż€č€ëĄŁ ? ÈëÁŠ„Ç©`„ż€Ëœü€€Žú±í„Ù„Ż„È„ë€Ë€è€Ă€ÆĆĐe€òĐĐ€Š”ă€Ç€Ïk- œü°ű·š€ÈévßB€Ź€ą€ëĄŁ ? șÎ€Ï€È€â€ą€ìĄąŽú±í„Ù„Ż„È„ë€ò€€€«€ËĆäÖĂ€č€ë€«€ŹæI Žú±í„Ù„Ż„È„ë€Ë€è€ë ÈëÁŠ„Ç©`„ż€È„é„Ù„ë ÈëÁŠżŐég€Î·Öžî 4
- 5. Ń§Ï°„Ù„Ż„È„ë€ÎÁżŚÓ»Ż€Î„€„á©`„ž 2 ? ÈëÁŠ„Ç©`„ż€Ëœü€€Žú±í„Ù„Ż„È„ë€Ë€è€Ă€ÆĆĐe€òĐĐ€Š”ă€Ç€Ïk- œü°ű·š€ÈévßB€Ź€ą€ëĄŁ Žú±í„Ù„Ż„È„ë€Ë€è€ë ÈëÁŠ„Ç©`„ż€È„é„Ù„ë ÈëÁŠżŐég€Î·Öžî 5
- 6. Ń§Ï°„Ù„Ż„È„ë€ÎÁżŚÓ»Ż€ÎѧÁ„Ś„í„»„č Žú±í„Ç©`„ż€ÎłőÆÚ€ÎQ¶š„Ś„í„»„č 1. ѧÁ„Ç©`„ż€òk-œü°ű·š€Ë€è€Ă€ÆĆĐe 2. ĆĐe€ÎŐ`€ê€Î€Ê€€„Ç©`„ż€«€é„é„ó„À„à€Çßx€Ö ѧÁ„Ś„í„»„č 1. rżÌt€Ë€Ș€€€Æ1€Ä€Î„Ç©`„żŁš„Æ„č„È”ăŁ©€òßxk 2. Žú±í„Ù„Ż„È„ë€ÎžüĐ ? rżÌt€Çßx€Đ€ì€ż„Ç©`„ż (x(t),y(t)) ? xŁșÌŰŐÁżĄąyŁș„é„Ù„ë ? rżÌt€Ë€Ș€±€ëŽú±í„Ç©`„ż ?1 (t) ? Žú±í„Ç©`„ż€Î„é„Ù„ë ? ? (t), i=1,2,Ąk 6
- 7. ѧÁ„ą„ë„Ž„ê„ș„à ? ѧÁ„ą„ë„Ž„ê„ș„à€È€·€Æ€ÏÒÔÏ€΀â€Î€Ź€ą€ë 1. LVQ1 2. LVQ2.1 3. LVQ3 4. OLVQ1(Optimized-learning rate LVQ1) 7
- 8. LVQ1 -1 ? „Æ„č„È”ă(x(t),y(t))€ŹÈëÁŠ€”€ì€ë ? „Æ„č„È”ă€«€éŚî€âœü€€Žú±í„Ù„Ż„È„ë€ò c €È€č€ë c = ?????? ? ? ? ? ? ? €ł€Î€È€ y(t)= ? ? (t) Ąú ? ? (t+1) = ? ? (t) + ŠÁ(t)(x(t)Ł ? ? (t)) y(t)ĄÙ ? ? (t) Ąú ? ? (t+1) = ? ? (t)ŁŠÁ(t)(x(t)Ł ? ? (t)) €ż€À€·Ąą 0 < ŠÁ(t) < 1 iĄÙc Ąú ? ? (t+1) = ? ? (t) 8
- 9. LVQ1 -2 ? y(t)= ? ? (t) Ąú ? ? (t)€òx(t)€Ëœü€Ć€±€ë ? y(t)ĄÙ ? ? (t) Ąú ? ? (t)€òx(t)€«€éßh€¶€±€ë 9
- 10. LVQ2.1 -1 ? LVQ1€Ï1€Ä€ÎŽú±í„Ù„Ż„Ȅ뀷€«žüĐ€·€Ê€«€Ă€ż€ŹĄą2€Ä€ÎŽú±í „Ù„Ż„È„ë€Ë€·€ÆžüĐ€òĐĐ€Š„ą„ë„Ž„ê„ș„à€ŹLVQ2.1 žüĐ€ÎÏó ? „é„Ù„ë€Źß`€Š€Ź„Æ„č„È”ă€«€éŚî€âœü€€Žú±í„Ù„Ż„È„ë ? ? (t) ? „é„Ù„ë€ŹÍŹ€ž€Ç„Æ„č„È”ă€«€éŚî€âœü€€Žú±í„Ù„Ż„È„ë ? ? (t) 10
- 11. LVQ2.1 -2 1?? ?? ? ? ? s = €È€·Ąąmin( , ) > s €Ê€éĄąÒÔÏ€ΞüĐ€òĐĐ€Š 1+? ? ? ?? ? ? (t+1) = ? ? (t)ŁŠÁ(t)(x(t)Ł ? ? (t)) Ąú ßh€¶€±€ë ? ? (t+1) = ? ? (t) + ŠÁ(t)(x(t)Ł ? ? (t)) Ąú œü€Ć€±€ë ?? 1?? Śóí€ÎöșÏĄą >s= €È€Ê€ë ?? ?? 1+? ?? ?? ?? ?? ?? min( , )šQ1€Ç€ą€êĄą ? ? €È? ? €Źœü ?? ?? €€€Û€ÉĄąžüĐ€ŹĐĐ€ï€ì€ä€č€Ż€Ê€ëĄŁ 11
- 12. LVQ3 ? LVQ1€ÈLVQ2.1€òÈÚșÏ€·€ż€è€Š€Ê€â€Î ? „Æ„č„È”ă€«€éœü€€2€ÄŽú±í„Ù„Ż„È„ë€òí€Ë? ? (t), ? ? (t)€È€·ĄąÒÔ Ï€΀ɀÁ€é€«€ÎÌőŒț€òș€ż€·€żöșπ˞üĐ€òĐĐ€ŠĄŁ 1. li (t) , lj (t)€Ź€È€â€Ëy(t)€ÈÍŹ€ž ?? (t+1)= ?? (t)+ŠĆŠÁ(t)(x(t)Ł?? (t)) ,h=i,j Ąúœü€Ć€±€ë 2. li (t)ĄÙy(t), lj (t)=y(t)Ąą€«€ÄLVQ2.1€ÈÍŹ€žÌőŒțŁš„Æ„č„È”ă€Ź· €ËÈë€ëŁ©€ÎöșÏ ? ? (t+1) = ? ? (t)ŁŠÁ(t)(x(t)Ł ? ? (t)) Ąú ßh€¶€±€ë ? ? (t+1) = ? ? (t) + ŠÁ(t)(x(t)Ł ? ? (t)) Ąú œü€Ć€±€ë 12
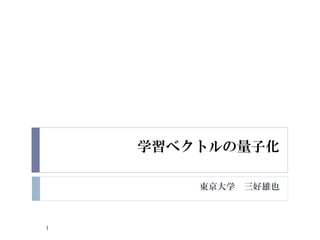
- 13. OLVQ1 -1 ? LVQ1€Ë€Ș€±€ë ŠÁ(t) €ÎŚîßm»Ż Ąú ѧÁ€Î §ÊűÌŰĐԀΞÄÉÆ ? y(t)€Èli (t)€È€ÎévS€òÊŸ€čäÊę€ò§Èë€č€ë +1, i=c €«€Ä y(t) = li (t) ?i (t) = Ł1, i=c €«€Ä y(t) ĄÙ li (t) 0, i ĄÙ c y(t)= ? ? (t) Ąú ? ? (t+1) = ? ? (t) + ŠÁ(t)(x(t)Ł ? ? (t)) y(t)ĄÙ ? ? (t) Ąú ? ? (t+1) = ? ? (t)ŁŠÁ(t)(x(t)Ł ? ? (t)) i ĄÙ c Ąú ? ? (t+1) = ? ? (t) ? mi (t+1) = mi (t) + ?i (t)ŠÁi (t)(x(t)Ł ? ? (t)) 13
- 14. OLVQ1 -2 mi (t+1) = mi (t) + ?i (t)ŠÁi (t)(x(t)Ł ? ? (t)) = (1Ł?i (t)ŠÁi (t)) ? ? (t) + ?i (t)ŠÁi (t)x(t) €”€é€ËŐčé_€·€Æ€€€Ż€ÈĄą mi (t+1) = (1Ł?i (t)ŠÁi (t))(1Ł? ? (tŁ1)ŠÁi (tŁ1))? ? (t) + (1Ł?i (t)ŠÁi (t))? ? (tŁ1)ŠÁi (tŁ1)x(tŁ1) + ?i (t)ŠÁi (t) x(t) ?i (t)?i (tŁ1)=0€Î€È€Ąą x(tŁ1) €È x(t) €ÎSÊę€Îœ~€Ź”È€· €€€È€·Ąą€”€é€ËĄą ?i =1, 0< ŠÁ <1 €òżŒ]€č€ë€ÈĄąŚîœK”Ä€Ë ŠÁi(??1) ŠÁi (?) = 1+si (?)ŠÁi (??1) 14
- 15. î}”ă 1. łőÆÚÒÀŽæ 2. ѧÁ„Ç©`„ż€Ë€è€ëѧÁ€Îí·Ź€Ë€âœYčû€ŹÒÀŽæ€č€ë 15
- 16. ѧÁ„Ù„Ż„È„ë ŁÈëÁŠ„Ç©`„ż in R library(class) ; library(mlbench) dim <- 2 # ÈëÁŠżŐég€ÎŽÎÔȘ ; n <- 300 # ѧÁ„Ç©`„żÊę smpl <- mlbench.corners(n, d=dim, sd=0.25) x <- smpl$x ; y <- smpl$classes size <- 8 # Žú±í„Ù„Ż„È„ë€ÎÊę ; k <- 1 # łőÆÚ»Ż cd <- lvqinit(x,y, size=size, k=k) ; cd3 <- lvq3(x,y,cd) # ѧÁÇ°áá€ÎĆĐeŸłœç gsize <- 100 # „°„ê„Äɀ΄”„€„ș x1 <- seq(min(x[,1]), max(x[,1]), length=gsize) x2 <- seq(min(x[,2]), max(x[,2]), length=gsize) xtest <- as.matrix(expand.grid(x1,x2)) yest <- lvqtest(cd, xtest) yest3 <- lvqtest(cd3, xtest) cntr <- matrix(match(yest, levels(factor(yest))), gsize, gsize) cntr3 <- matrix(match(yest3, levels(factor(yest3))), gsize, gsize) plot(x, col=y, pch=20+as.numeric(y), xlab="x1", ylab="x2", main="Initial Codebook") # Žú±í„Ù„Ż„È„ë points(cd3$x, col=cd3$cl, bg=cd$cl, pch=20+as.numeric(cd$cl),cex=2) 16
- 17. ѧÁ„Ù„Ż„È„ë ŁŃ§ÁÇ°€ÈѧÁáá # ѧÁÇ°€ÎŸłœç€ò±íÊŸ # ѧÁáá for(i in 1:max(cntr)) contour(x1, x2, cntr==i, plot(x, col=y, pch=20+as.numeric(y), xlab="x1", levels=0.5, lwd=2, lty=1, drawlabels=F, add=TRUE) ylab="x2", main="LVQ3") points(cd3$x, col=cd3$cl, bg=cd$cl, pch=20+as.numeric(cd$cl),cex=2) for(i in 1:max(cntr3))contour(x1,x2,cntr==i,levels=0.5,l 17 wd=2,lty=1, drawlabels=F, add=TRUE)