







![Ĺū»ŕ °Ń ôC–Ķ—ßŃē §őņߎy§Ķ§»“™’ą
10
ņߎy§Ķ
∑«∂®≥£§ ∑÷≤ľ
•Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ
•«©`•Ņ§ő…Ŕ§ §Ķ
“™’ą ∆∑Ŕ|§őĶ£Ī£
»ňťg§» ML •‚•«•Ž§őťg§ň§Ō«ťąůłŮ≤Ó§¨§Ę§Ž
‘≠ņŪ…Ō•«©`•Ņ§ÚČą§š§∑§Ň§ť§§
•«©`•Ņ§ő–‘Ŕ|§Ō≥£§ňČšĽĮ§∑§∆§§§Į
ĆgĄ’ľ“§¨ŌŽ∂®§Ļ§Ž
°ł•‚•«•Ž§¨úļ§Ņ§∑§∆§Ř§∑§§–‘Ŕ|°Ļ§Ú
ŅľĎ]§Ļ§ŽĪō“™§¨§Ę§Ž
°ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-10-320.jpg)
![Īĺ»’§ő•∆©`•ř
11
ņߎy§Ķ
∑«∂®≥£§ ∑÷≤ľ
•Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ
•«©`•Ņ§ő…Ŕ§ §Ķ
“™’ą ∆∑Ŕ|§őĶ£Ī£
»ňťg§» ML •‚•«•Ž§őťg§ň§Ō«ťąůłŮ≤Ó§¨§Ę§Ž
‘≠ņŪ…Ō•«©`•Ņ§ÚČą§š§∑§Ň§ť§§
•«©`•Ņ§ő–‘Ŕ|§Ō≥£§ňČšĽĮ§∑§∆§§§Į
ĆgĄ’ľ“§¨ŌŽ∂®§Ļ§Ž
°ł•‚•«•Ž§¨úļ§Ņ§∑§∆§Ř§∑§§–‘Ŕ|°Ļ§Ú
ŅľĎ]§Ļ§ŽĪō“™§¨§Ę§Ž
°ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ
Ĺū»ŕ °Ń ôC–Ķ—ßŃē§ő
ņߎy§Ķ§ő§‚§»§«
«ů§Š§ť§ž§Ž“™’ą?∆∑Ŕ|§»§Ō£Ņ
Īĺ»’§ő•∆©`•ř](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-11-320.jpg)

![§Ĺ§ő•‚•«•Ž°Ę§…§¶ Ļ§¶£Ņ
13
[Lai+ FAccT19]
»ňťg§¨“‚ňľõQ∂® •‚•«•Ž§«“‚ňľõQ∂®
Human-AI Collaboration
•‚•«•Ž §ő≥ŲѶ§» »ňťg §őŇ–∂Ō§Ú ĹM§Ŗ§Ę§Ô§Ľ§∆
◊ÓĹKĶń§ “‚ňľõQ∂®](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-13-320.jpg)

![»ňľš§őŇ–∂Ō§Ú«įŐŠ§ň§∑§Ņ•‚•«•Í•ů•į
15
[Bansal+ HCOMP19]
•‚•«•ŽÖgŐŚ§ő•—•’•©©`•ř•ů•ĻŌÚ…Ō
Human-AI Team §ő•—•’•©©`•ř•ů•ĻŌÚ…Ō
÷ō“™§ “™ňō£ļMental Model §¨Ŗm«–§ňėčļB§«§≠§Ž§ę£Ņ
®P•‚•«•Ž§ő•®•ť©`ĺ≥ĹÁ§ň§ń§§§∆»ňťg§¨≥÷§ń•‚•«•Ž
”Ťúy§¨’ż§∑§§ÓI”Ú
”Ťúy§Ú’`§ŽÓI”Ú
•‚•«•Ž§ő•®•ť©`ĺ≥ĹÁ
Mental Model](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-15-320.jpg)
![•‚•«•Ž§ő”Ťúy§ő“Ľōě–‘
16
[Bansal+ AAAI19]
•‚•«•Ž§Ō£ĪĽō◊ų§ž§–ĹK§Ô§Í£Ņ
NO! ňśērłŁ–¬§Ķ§ž§Ž§ő§¨∆’Õ®
Acc:
95%
Decision Making
& Feedback
Age>70 § §ť
•‚•«•Ž§Ú–ҧł§∆§Ť§Ķ§Ĺ§¶
ĺ…•‚•«•Ž
•«©`•Ņ§¨Čą§®§Ņ§ő§«
•‚•«•Ž§ÚłŁ–¬§∑§ř§Ļ
’żĹ‚¬ §‚…Ō§¨§Í§ř§∑§Ņ£°£°
Age>70 §őēr§ő’żĹ‚¬ §Ō
Ō¬§¨§√§Ņ§Ī§…°≠
Acc:
98%
–¬•‚•«•Ž
£°£Ņ£°£°£Ņ](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-16-320.jpg)
![Human-AI Collaboration£ļ•‚•«•Ž§ō§ő“™ľĢ
17
[Bansal+ HCOMP19]
1 Parsimonious Error Boundaries
2 Small Stochasticity of System Errors
3 Low Task Dimensionality
4 Backward Compatibility of Error Boundaries
•®•ť©`ĺ≥ĹÁ§¨ÖgľÉ§«§Ę§Ž§≥§»
•®•ť©`ĺ≥ĹÁ§ň≤Ľī_Ćg–‘§¨§ §§§≥§»
•Ņ•Ļ•Į§őīő‘™§¨ĶÕ§§§≥§»
•‚•«•ŽłŁ–¬ēr§ň•®•ť©`ĺ≥ĹÁ§¨īů§≠§ĮČšĽĮ§∑§ §§§≥§»](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-17-320.jpg)
![§Ĺ§ő•‚•«•Ž°Ę§…§¶ Ļ§¶£Ņ£≠ĺŖŐŚņż£®1/2£©
18
£™ •‚•«•Ž§ő≥ŲѶ§Ú§‚§»§ň»ňťg§¨Ň–∂Ō
£≠ »ňťg§¨»ęľĢ“䧎§¨≤őŅľ«ťąů§»§∑§∆•‚•«•Ž§ÚņŻ”√
[Mozannar+ ICML20]
ŔYģb
100
ōďāý 50
ľÉŔYģb 50 PD=10% OK£°
ŔYģb
100
ōďāý 90
ľÉŔYģb 10
PD=90% NG£°
«įŪď§ř§«§ő‘í§Ō§≥§ő◊īõr§ÚńÓÓ^§ň÷√§§§∆§§§Ņ](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-18-320.jpg)
![§Ĺ§ő•‚•«•Ž°Ę§…§¶ Ļ§¶£Ņ£≠ĺŖŐŚņż£®2/2£©
19
£™ ”Ťúy§őī_–Ň∂»§¨ĶÕ§§§»§≠§ő§Ŗ»ňťg§¨Ň–∂Ō
[Mozannar+ ICML20]
ŔYģb
100
ōďāý 50
ľÉŔYģb 50 ??? OK£°
ŔYģb
100
ōďāý 90
ľÉŔYģb 10
ĶĻ§ž§Ž£°
NG£°
£≠ ī_–Ň∂»§¨łŖ§§•Ķ•ů•◊•Ž§Ō•‚•«•Ž§ő≥ŲѶ§ÚņŻ”√](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-19-320.jpg)
![”Ťúy§őī_–Ň∂»§¨ĶÕ§§§»§≠§ő§Ŗ»ňťg§¨Ň–∂Ō§Ļ§Ž•Ī©`•Ļ
20
£™ Learning to Defer
Classifier Rejector »ňťg§ő”Ťúy Defer §∑§ §§ Defer §Ļ§Ž
•‚•«•Ž§ő•≥•Ļ•» »ňťg§ő•≥•Ļ•»
£™ °ł»ňťg§ő•≥•Ļ•»°Ļ§¨∂® ż§ő§»§≠ °įLearning with Rejection°Ī
£≠ °ł»ňťg§ő•≥•Ļ•»°Ļ£Ĺ°ł’`Ň–Ąeēr§ő•≥•Ļ•»°Ļ£ę°ł»ňťg§Ú Ļ§¶•≥•Ļ•»°Ļ
£™ Learning to Defer §Ō »ňťg§ő’`Ň–Ąe§š•–•§•Ę•Ļ§ÚŅľĎ] §∑§Ņ∂® ĹĽĮ
[Madras+ NeurIPS18] [Mozannar+ ICML20]](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-20-320.jpg)

![§…§ő§Ť§¶§ňó ‘^§Ú––§¶§Ŕ§≠§ę£Ņ
23
£™ Õ∂ŔYĎť¬‘§ő•–•√•Į•∆•Ļ•»§ő§Ņ§Š§ő—–ĺŅ•◊•Ū•»•≥•Ž [Arnott+ 18]](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-23-320.jpg)
![§…§ő§Ť§¶§ňó ‘^§Ú––§¶§Ŕ§≠§ę£Ņ
24
£™ Õ∂ŔYĎť¬‘§ő•–•√•Į•∆•Ļ•»§ő§Ņ§Š§ő—–ĺŅ•◊•Ū•»•≥•Ž [Arnott+ 18]
°ý∂ŗ…Ŕ“‚‘U§∑§∆§ř§Ļ
ļŌņŪĶń§ ĀĘ’h§Ú•Ŕ©`•Ļ§ň•‚•«•Í•ů•į§Ľ§Ť
Õ¨“Ľ•∆•Ļ•»•«©`•Ņ§«ļő∂»§‚ó ‘^§Ļ§ŽąŲļŌ§Ō◊Ę“‚
•«©`•Ņ§ő§»§Í∑ŧňŃŰ“‚
CV §Ō’ś§ő Out-of-sample ó ‘^§«§ §§§ő§«◊Ę“‚
∑«∂®≥£–‘§őīś‘ŕ§ň◊Ę“‚§Ľ§Ť
•∑•ů•◊•Ž§ •‚•«•Ž§ő∑ŧ¨ļ√§ř§∑§§
Ďť¬‘§¨ĄŔ§∆§Ž§ę∑٧ꧫ§ §Į—–ĺŅ§őŔ|§Ú÷ō“ē§Ľ§Ť](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-24-320.jpg)
![Ĺū»ŕôCťv§ő•Ļ•»•ž•Ļ•∆•Ļ•»
25
£™ •Ļ•»•ž•Ļ•∑• •Í•™ §ÚŌŽ∂®§∑
[≥ō…≠, 18]
£™ §Ĺ§őąŲļŌ§ő •ņ•Š©`•ł§Ú•∑•Ŗ•Ś•ž©`•∑•Á•ů §∑§∆
£™ •Ę•Į•∑•Á•ů•◊•ť•ů §Ú§Ę§ť§ę§ł§Š◊h’ď§∑§∆§™§Į
? ĺįö›§őīů∑ý§ źôĽĮ
? ŔYģbĀżłŮ§őľĪ¬š
? Ĺū»ŕ –ąŲ§őŃųĄ”–‘Ņ›úf
? ďp ߧőįk…ķ
? ŔYĹūņR§Í§őźôĽĮ
•›•§•ů•»§Ō
“Ľ∂»§‚”Qúy§Ķ§ž§∆§§§ §§•∑• •Í•™§Ú
•∑•Ŗ•Ś•ž©`•∑•Á•ů§«◊ų§Ž§≥§»
•Í•Ļ•ĮĻ‹ņŪŐŚ÷∆§ő≤Ľāš§Ú•ę•–©`§Ļ§Ž§Ņ§Š§őó ‘^](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-25-320.jpg)
![•Ļ•»•ž•Ļ•∑• •Í•™§«§őó ‘^
26
£™ •Ļ•»•ž•Ļ•∑• •Í•™£Ĺ∑« IID •«©`•Ņ§ÚĽÓ”√
£™ •‚•«•Ž§¨–ŇÓm§ň◊„§Ž§ę?ĪĺŔ|Ķń§ ėč‘ž§Ú•®•ů•≥©`•…§∑§∆§§§Ž§ęó ‘^
1 Stratified Performance Evaluation
2 Shifted Performance Evaluation
3 Contrastive Evaluation
Subgroup §«ó ‘^
∑÷≤ľ§Ú•∑•’•»§Ķ§Ľ§∆ó ‘^
Őō∂®•Ķ•ů•◊•Ž§ňḈ∑§∆Őō∂®§őČšďQ§Ú ©§∑≥ŲѶ§Úó ‘^
[D'Amour+ 20]](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-26-320.jpg)
![Stratified Performance Evaluation
27
1
[Oakden-Rayner+ 19]
£™ •ť•Ŕ•Žł∂§Ī§Ķ§ž§Ņłų•Į•ť•Ļ§Ō
—} ż§ő•Ķ•÷•Ľ•√•»§ę§ťėč≥…§Ķ§ž§Ž
£™ »ęŐŚ§ő’żĹ‚¬ §ņ§Ī§Ú“ä§∆§§§Ž§»
–‘ń‹§¨Ń”§Ž…Ŕ ż§ő•Ķ•÷•Ľ•√•»§š
Spurious Correlation §Ú“䬚§»§Ļ
•Ŕ•ů•¨•Ž
•∑•„•ŗ
•ŕ•Ž•∑•„
•ť•Ŕ•Ž£ļ√®
2% 38% 60%
ChestXray14 §őņż£ļ
£™ ö›–ō§ő•ť•Ŕ•Ž§¨§ń§§§ŅĽ≠Ō٧ő§¶§ŃīůįŽ§Ō–ō«Ľ•Ń•Ś©`•÷§Ę§Í
£®ö›–ō§ő÷őĮü§»§∑§∆”√§§§ť§ž§Ž§‚§ő£©
£™ §ŗ§∑§Ū–ō«Ľ•Ń•Ś©`•÷§ő–ī§√§∆§§§ §§Ľ≠ŌŮ §Ú’ż§∑§Į”Ťúy§∑§ §§§»…ķňņ§ňťv§Ô§Ž](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-27-320.jpg)
![Shifted Performance Evaluation
28
2
”Ėĺö•«©`•Ņ§ő∑÷≤ľ§»ģź§ §Ž∑÷≤ľ§Ú◊ų§Ž
£™ •ť•Ŕ•Ž§ÚČš§®§ §§§Ť§¶§ň»ŽŃ¶§ÚČšďQ§Ķ§Ľ§Ž
ImageNet §őĽ≠Ō٧ÚČšďQ§∑§Ņ ImageNetC § §…
£™ •«©`•Ņ§őÖßľĮ§ő∑Ĺ∑®§ÚČš§®§Ž
ImageNet §ňļ¨§ř§ž§ §§§Ť§¶§ •§•ž•ģ•Ś•ť©`§
•Ī©`•Ļ§ÚľĮ§Š§ŅObjectNet § §…
[Hendrycks+ 19]
[Barbu+ 19]
§…§ů§ ČšďQ§¨Ņľ§®§ť§ž§Ž§ę/§…§¶§š§√§∆•«©`•Ņ§ÚľĮ§Š§ §™§Ļ§ę§Ō
¨FĆgĶń§ň§Ōīů§≠§ ÜĖÓ}](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-28-320.jpg)
![Contrastive Evaluation
29
3
āÄĄe•Ķ•ů•◊•Ž§ī§»§ňČšďQ§Ú ©§∑”Ťúyāé§őí§Ą”§Úī_’J
£™ Fairness §ň•’•©©`•ę•Ļ§∑§Ņ—–ĺŅ§¨∂ŗ ż
£™ NLP §ň§™§§§∆§‚§§§Į§ń§ę•∆•Ļ•»§¨ŐŠįł§Ķ§ž§∆§§§Ž
•Ķ•ů•◊•Ž§ī§»§ň•ť•Ŕ•Ž§ÚĪ£≥÷§Ļ§Ž/∑ī‹ě§Ķ§Ľ§ŽČšďQ§¨◊ų§ž§ž§–§Ĺ§ž§Ú§‚§»§ň•«©`•ŅíąŹą§∑§∆—ßŃē§«§≠§Ž
Sensitive attribute §ő§Ŗ§¨Čš§Ô§√§∆§‚•‚•«•Ž§ő≥ŲѶ§ŌČš§Ô§√§∆§Ř§∑§Į§ §§
Ęŕ£ļ∑÷≤ľ§Ú•∑•’•»§Ķ§Ľ§Ņ•«©`•Ņ•Ľ•√•»»ęŐŚ§őĺę∂»§ň•’•©©`•ę•Ļ
ĘŘ£ļāÄ°©§ő•Ķ•ů•◊•Ž§ő”Ťúyā駨∆ŕīżÕ®§ÍČš§Ô§Ž§ę§ň•’•©©`•ę•Ļ
őń’¬÷–§őĶō√Ż§¨Čš§Ô§√§∆§‚•Ľ•ů•Ń•Š•ů•»§ŌČš§Ô§√§∆§Ř§∑§Į§ §§
[Kaushik+ 20]
[Ribeiro+ 20]
[Kusner+ 17]](https://image.slidesharecdn.com/20210313-210313070054/85/xAI-29-320.jpg)


Ĺū»ŕ°Ńī°Īű§«Ĺ‚§Į§Ŕ§≠ő Ő‚§Ōļő§ę£Ņ
- 1. Ĺū»ŕ °Ń AI §«Ĺ‚§Į§Ŕ§≠ÜĖÓ}§Ōļő§ę£Ņ §Ŗ§ļ§ŘĶŕ“Ľ•’•£• •ů•∑•„•Ž•∆•Į•ő•Ū•ł©`/Ė|ĺ©īů—ß ”ņ…Ĺļ„—Ś
- 3. ◊‘ľļĹBĹť 3 ”ņ…Ĺ ļ„—Ś §Ŗ§ļ§ŘĶŕ“Ľ•’•£• •ů•∑•„•Ž•∆•Į•ő•Ū•ł©` •«©`•Ņ•Ę• •Í•∆•£•Į•Ļľľ–gť_įk≤Ņ Ė|ĺ©īů—ß ? 2016ńÍ4‘¬ §Ŗ§ļ§Ř„y––»Ž–– ? 2016ńÍ11‘¬°ę §Ŗ§ļ§ŘĶŕ“Ľ•’•£• •ů•∑•„•Ž•∆•Į•ő•Ū•ł©`§««ŕĄ’ ? Õ∂ŔY÷ķ—‘§ň§™§Ī§Ž•ň•Ś©`•Ļ•«©`•ŅĽÓ”√§ő§Ņ§Š§ő•‚•«•Žť_įk ? •»•ť•ů•∂•Į•∑•Á•ů•«©`•Ņ§ÚĽÓ”√§∑§Ņ•Ļ•≥•Ę•Í•ů•į•‚•«•Žť_įk ? ôC–Ķ—ßŃē◊‘Ą”ĽĮ•Ę•◊•Í•Ī©`•∑•Á•ů§őť_įk§»§Ĺ§ž§ÚĽÓ”√§∑§Ņ•≥•ů•Ķ•Ž•∆•£•ů•į ? Ĺū»ŕőńēÝ£®•Ę• •Í•Ļ•»•ž•›©`•»?”–Āż‘^»Įąůłśēݧ §…£©§őĽÓ”√§ő§Ņ§Š§őĆg‘^∑÷őŲ ? ôC–Ķ—ßŃē§őľľ–g’{Ėň ? 2020ńÍ9‘¬°ę ≤© Ņ’n≥Ő»Ž—ß
- 6. Ĺū»ŕ °Ń ôC–Ķ—ßŃē §őņߎy§Ķ 6 •Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ •«©`•Ņ§ő…Ŕ§ §Ķ ∑«∂®≥£§ ∑÷≤ľ °ł“Ľį„Ķń§ ôC–Ķ—ßŃē§ő•Ņ•Ļ•Į°Ļ§»°łĹū»ŕ§«Ĺ‚§≠§Ņ§§ÜĖÓ}°Ļ§ő•ģ•„•√•◊
- 7. Ĺū»ŕ °Ń ôC–Ķ—ßŃē §őņߎy§Ķ 7 •Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ •«©`•Ņ§ő…Ŕ§ §Ķ ∑«∂®≥£§ ∑÷≤ľ °ł»ģ§»√®§ő∑÷Óź°Ļ?°ł•«•’•©•Ž•»”Ťúy°Ļ »ģ √® »ģ ŔYģb 100 ōďāý 50 ľÉŔYģb 50 •«•’•©•Ž•»§Ļ§Ž°≠£Ņ °ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ °ł“Ľį„Ķń§ ôC–Ķ—ßŃē§ő•Ņ•Ļ•Į°Ļ§»°łĹū»ŕ§«Ĺ‚§≠§Ņ§§ÜĖÓ}°Ļ§ő•ģ•„•√•◊
- 8. Ĺū»ŕ °Ń ôC–Ķ—ßŃē §őņߎy§Ķ 8 ∑«∂®≥£§ ∑÷≤ľ # …ŌąŲ∆ůėI ? 4,000 √®§ő–ī’ś§ŌČą§š§Ľ§Ž ? ŔJ≥Ų ż§ŌČą§š§Ľ§ §§ •Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ •«©`•Ņ§ő…Ŕ§ §Ķ °ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ # √® # •ę•Š•ť•ř•ů £Ĺ §Ņ§Į§Ķ§ů £Ĺ §Ņ§Į§Ķ§ů °ł“Ľį„Ķń§ ôC–Ķ—ßŃē§ő•Ņ•Ļ•Į°Ļ§»°łĹū»ŕ§«Ĺ‚§≠§Ņ§§ÜĖÓ}°Ļ§ő•ģ•„•√•◊
- 9. Ĺū»ŕ °Ń ôC–Ķ—ßŃē §őņߎy§Ķ 9 ∑«∂®≥£§ ∑÷≤ľ √®§őŐōŹ’§Ōőۧ‚Ĺ٧‚Õ¨§ł ? ĹUúg≠hĺ≥§Ō≥£§ňČšĽĮ§Ļ§Ž •Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ •«©`•Ņ§ő…Ŕ§ §Ķ °ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ °ł“Ľį„Ķń§ ôC–Ķ—ßŃē§ő•Ņ•Ļ•Į°Ļ§»°łĹū»ŕ§«Ĺ‚§≠§Ņ§§ÜĖÓ}°Ļ§ő•ģ•„•√•◊
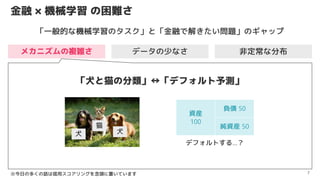
- 10. Ĺū»ŕ °Ń ôC–Ķ—ßŃē §őņߎy§Ķ§»“™’ą 10 ņߎy§Ķ ∑«∂®≥£§ ∑÷≤ľ •Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ •«©`•Ņ§ő…Ŕ§ §Ķ “™’ą ∆∑Ŕ|§őĶ£Ī£ »ňťg§» ML •‚•«•Ž§őťg§ň§Ō«ťąůłŮ≤Ó§¨§Ę§Ž ‘≠ņŪ…Ō•«©`•Ņ§ÚČą§š§∑§Ň§ť§§ •«©`•Ņ§ő–‘Ŕ|§Ō≥£§ňČšĽĮ§∑§∆§§§Į ĆgĄ’ľ“§¨ŌŽ∂®§Ļ§Ž °ł•‚•«•Ž§¨úļ§Ņ§∑§∆§Ř§∑§§–‘Ŕ|°Ļ§Ú ŅľĎ]§Ļ§ŽĪō“™§¨§Ę§Ž °ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ
- 11. Īĺ»’§ő•∆©`•ř 11 ņߎy§Ķ ∑«∂®≥£§ ∑÷≤ľ •Š•ę•ň•ļ•ŗ§ő—}Žj§Ķ •«©`•Ņ§ő…Ŕ§ §Ķ “™’ą ∆∑Ŕ|§őĶ£Ī£ »ňťg§» ML •‚•«•Ž§őťg§ň§Ō«ťąůłŮ≤Ó§¨§Ę§Ž ‘≠ņŪ…Ō•«©`•Ņ§ÚČą§š§∑§Ň§ť§§ •«©`•Ņ§ő–‘Ŕ|§Ō≥£§ňČšĽĮ§∑§∆§§§Į ĆgĄ’ľ“§¨ŌŽ∂®§Ļ§Ž °ł•‚•«•Ž§¨úļ§Ņ§∑§∆§Ř§∑§§–‘Ŕ|°Ļ§Ú ŅľĎ]§Ļ§ŽĪō“™§¨§Ę§Ž °ýĹŮ»’§ő∂ŗ§Į§ő‘í§Ō–Ň”√•Ļ•≥•Ę•Í•ů•į§ÚńÓÓ^§ň÷√§§§∆§§§ř§Ļ Ĺū»ŕ °Ń ôC–Ķ—ßŃē§ő ņߎy§Ķ§ő§‚§»§« «ů§Š§ť§ž§Ž“™’ą?∆∑Ŕ|§»§Ō£Ņ Īĺ»’§ő•∆©`•ř
- 12. Ĺū»ŕ °Ń AI£ļ•—•Ô©`•…•Ļ©`•ń–Õ AI §»§∑§∆§őôC–Ķ—ßŃē§őĽÓ”√ 12 https://www.rieti.go.jp/jp/publications/pdp/17p033.pdf £™ »ň÷™§ő AI §ň§Ť§ŽŹäĽĮ •Į•ž•ł•√•»•ę©`•…§ő•ś©`•∂§ő÷ßíB§§§¨÷Õ§Ž•—•Ņ©`•ů§Ú AI §«ļY§ň§ę§Ī§Ž ļY§ň§ę§Ī§ť§ž§Ņ•«©`•Ņ§Ú»ňťg§¨•Ń•ß•√•Į§∑§∆ő£Íď§ •ś©`•∂§Ú“ä§ń§Ī≥Ų§Ļ ? ’`Ň–Ąeēr§ő•≥•Ļ•»£®»ň§Ú Ļ§√§Ņ∑ŧ¨ĹYĻŻĶń§ňĄŅ¬ Ķń£© ? ’h√ųōü»ő?āźņŪĶń§ ÜĖÓ}£®°ł§…§¶§∑§∆ňŧŌ»ŕŔY§Ú ‹§Ī§ť§ž§ §§§ů§«§Ļ§ę£Ņ°Ļ£© ? •«©`•ŅĽĮ§Ķ§ž§∆§§§ §§«ťąů§őĽÓ”√£®»ňťg§ő§Ŗ§¨≥÷§ń«ťąů§¨ĄŅ§Į£© ? ĺ÷√śČšĽĮ§ō§őĆĚŹÍ£®ôC–Ķ—ßŃē§őŌřĹÁ§Ú»ňťg§¨§…§¶§ň§ę—aÕͧĻ§Ž£©
- 13. §Ĺ§ő•‚•«•Ž°Ę§…§¶ Ļ§¶£Ņ 13 [Lai+ FAccT19] »ňťg§¨“‚ňľõQ∂® •‚•«•Ž§«“‚ňľõQ∂® Human-AI Collaboration •‚•«•Ž §ő≥ŲѶ§» »ňťg §őŇ–∂Ō§Ú ĹM§Ŗ§Ę§Ô§Ľ§∆ ◊ÓĹKĶń§ “‚ňľõQ∂®
- 14. Human-AI Collaboration£ļ•‚•«•Ž§ō§ő“™ľĢ 14 £™ •‚•«•Ž§ő”Ťúy§ő“Ľōě–‘ £™ »ňľš§őŇ–∂Ō§Ú«įŐŠ§ň§∑§Ņ•‚•«•Í•ů•į
- 15. »ňľš§őŇ–∂Ō§Ú«įŐŠ§ň§∑§Ņ•‚•«•Í•ů•į 15 [Bansal+ HCOMP19] •‚•«•ŽÖgŐŚ§ő•—•’•©©`•ř•ů•ĻŌÚ…Ō Human-AI Team §ő•—•’•©©`•ř•ů•ĻŌÚ…Ō ÷ō“™§ “™ňō£ļMental Model §¨Ŗm«–§ňėčļB§«§≠§Ž§ę£Ņ ®P•‚•«•Ž§ő•®•ť©`ĺ≥ĹÁ§ň§ń§§§∆»ňťg§¨≥÷§ń•‚•«•Ž ”Ťúy§¨’ż§∑§§ÓI”Ú ”Ťúy§Ú’`§ŽÓI”Ú •‚•«•Ž§ő•®•ť©`ĺ≥ĹÁ Mental Model
- 16. •‚•«•Ž§ő”Ťúy§ő“Ľōě–‘ 16 [Bansal+ AAAI19] •‚•«•Ž§Ō£ĪĽō◊ų§ž§–ĹK§Ô§Í£Ņ NO! ňśērłŁ–¬§Ķ§ž§Ž§ő§¨∆’Õ® Acc: 95% Decision Making & Feedback Age>70 § §ť •‚•«•Ž§Ú–ҧł§∆§Ť§Ķ§Ĺ§¶ ĺ…•‚•«•Ž •«©`•Ņ§¨Čą§®§Ņ§ő§« •‚•«•Ž§ÚłŁ–¬§∑§ř§Ļ ’żĹ‚¬ §‚…Ō§¨§Í§ř§∑§Ņ£°£° Age>70 §őēr§ő’żĹ‚¬ §Ō Ō¬§¨§√§Ņ§Ī§…°≠ Acc: 98% –¬•‚•«•Ž £°£Ņ£°£°£Ņ
- 17. Human-AI Collaboration£ļ•‚•«•Ž§ō§ő“™ľĢ 17 [Bansal+ HCOMP19] 1 Parsimonious Error Boundaries 2 Small Stochasticity of System Errors 3 Low Task Dimensionality 4 Backward Compatibility of Error Boundaries •®•ť©`ĺ≥ĹÁ§¨ÖgľÉ§«§Ę§Ž§≥§» •®•ť©`ĺ≥ĹÁ§ň≤Ľī_Ćg–‘§¨§ §§§≥§» •Ņ•Ļ•Į§őīő‘™§¨ĶÕ§§§≥§» •‚•«•ŽłŁ–¬ēr§ň•®•ť©`ĺ≥ĹÁ§¨īů§≠§ĮČšĽĮ§∑§ §§§≥§»
- 18. §Ĺ§ő•‚•«•Ž°Ę§…§¶ Ļ§¶£Ņ£≠ĺŖŐŚņż£®1/2£© 18 £™ •‚•«•Ž§ő≥ŲѶ§Ú§‚§»§ň»ňťg§¨Ň–∂Ō £≠ »ňťg§¨»ęľĢ“䧎§¨≤őŅľ«ťąů§»§∑§∆•‚•«•Ž§ÚņŻ”√ [Mozannar+ ICML20] ŔYģb 100 ōďāý 50 ľÉŔYģb 50 PD=10% OK£° ŔYģb 100 ōďāý 90 ľÉŔYģb 10 PD=90% NG£° «įŪď§ř§«§ő‘í§Ō§≥§ő◊īõr§ÚńÓÓ^§ň÷√§§§∆§§§Ņ
- 19. §Ĺ§ő•‚•«•Ž°Ę§…§¶ Ļ§¶£Ņ£≠ĺŖŐŚņż£®2/2£© 19 £™ ”Ťúy§őī_–Ň∂»§¨ĶÕ§§§»§≠§ő§Ŗ»ňťg§¨Ň–∂Ō [Mozannar+ ICML20] ŔYģb 100 ōďāý 50 ľÉŔYģb 50 ??? OK£° ŔYģb 100 ōďāý 90 ľÉŔYģb 10 ĶĻ§ž§Ž£° NG£° £≠ ī_–Ň∂»§¨łŖ§§•Ķ•ů•◊•Ž§Ō•‚•«•Ž§ő≥ŲѶ§ÚņŻ”√
- 20. ”Ťúy§őī_–Ň∂»§¨ĶÕ§§§»§≠§ő§Ŗ»ňťg§¨Ň–∂Ō§Ļ§Ž•Ī©`•Ļ 20 £™ Learning to Defer Classifier Rejector »ňťg§ő”Ťúy Defer §∑§ §§ Defer §Ļ§Ž •‚•«•Ž§ő•≥•Ļ•» »ňťg§ő•≥•Ļ•» £™ °ł»ňťg§ő•≥•Ļ•»°Ļ§¨∂® ż§ő§»§≠ °įLearning with Rejection°Ī £≠ °ł»ňťg§ő•≥•Ļ•»°Ļ£Ĺ°ł’`Ň–Ąeēr§ő•≥•Ļ•»°Ļ£ę°ł»ňťg§Ú Ļ§¶•≥•Ļ•»°Ļ £™ Learning to Defer §Ō »ňťg§ő’`Ň–Ąe§š•–•§•Ę•Ļ§ÚŅľĎ] §∑§Ņ∂® ĹĽĮ [Madras+ NeurIPS18] [Mozannar+ ICML20]
- 21. Human-AI Collaboration£ļ§…§ő§Ť§¶§ňó ‘^§Ļ§Ž§ę£Ņ 21 ĆgŽH§ňó ‘^§Ú––§™§¶§»§Ļ§Ž§»Žy§∑§§ £™ ∂®ŃŅĽĮ§∑§Ň§ť§§“™ňō§¨§Ņ§Į§Ķ§ů £™ ¨FąŲ§ő“‚ňľõQ∂®•◊•Ū•Ľ•Ļ§ň•‚•«•Ž§ÚĹM§Ŗřz§Ŗ PDCA •Ķ•§•Į•Ž§ÚĽō§Ľ§ž§–ļő§»§ę§ §Ž§¨°≠£Ņ ? »ňťg§ő Mental Model §√§∆§…§¶§š§√§∆‘uĀż§Ļ§Ž§ő£Ņ £®°ý£© ? »ňťg§¨‘uĀż§Ļ§ŽŽH§ő•≥•Ļ•»§√§∆§…§¶§š§√§∆õQ§Š§Ž§ő£Ņ ? °≠ £®°ý£©’ďőń§«§ŌĆgÚY”√§ő•◊•ť•√•»•’•©©`•ŗ§Ú◊ų§Í»ňěťĶń§ň≠hĺ≥§Ú◊ų§Ž§≥§»§«§≥§őÜĖÓ}§Ú§¶§ř§ĮĽōĪ‹§∑§∆§§§Ž§Ť§¶§ ”°Ōů ? »ňťg§Ú”√§§§Ņ‘uĀż§ő•Ļ•≠©`•ŗ◊ų§Í§Ō§§§Ū§§§Ū§»īůČš ? ÷‘™§ő•«©`•Ņ§ņ§Ī§«ļő§»§ę§∑§Ņ§§
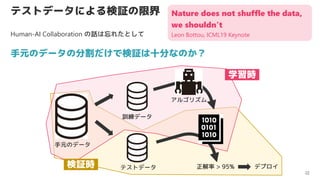
- 22. •∆•Ļ•»•«©`•Ņ§ň§Ť§Žó ‘^§őŌřĹÁ 22 ÷‘™§ő•«©`•Ņ§ő∑÷łÓ§ņ§Ī§«ó ‘^§Ō ģ∑÷§ §ő§ę£Ņ ÷‘™§ő•«©`•Ņ •∆•Ļ•»•«©`•Ņ ”Ėĺö•«©`•Ņ ’żĹ‚¬ > 95% •«•◊•Ū•§ —ßŃēēr ó ‘^ēr Nature does not shuffle the data, we shouldn°Įt Leon Bottou, ICML19 Keynote •Ę•Ž•ī•Í•ļ•ŗ Human-AI Collaboration §ő‘í§ŌÕŁ§ž§Ņ§»§∑§∆
- 24. §…§ő§Ť§¶§ňó ‘^§Ú––§¶§Ŕ§≠§ę£Ņ 24 £™ Õ∂ŔYĎť¬‘§ő•–•√•Į•∆•Ļ•»§ő§Ņ§Š§ő—–ĺŅ•◊•Ū•»•≥•Ž [Arnott+ 18] °ý∂ŗ…Ŕ“‚‘U§∑§∆§ř§Ļ ļŌņŪĶń§ ĀĘ’h§Ú•Ŕ©`•Ļ§ň•‚•«•Í•ů•į§Ľ§Ť Õ¨“Ľ•∆•Ļ•»•«©`•Ņ§«ļő∂»§‚ó ‘^§Ļ§ŽąŲļŌ§Ō◊Ę“‚ •«©`•Ņ§ő§»§Í∑ŧňŃŰ“‚ CV §Ō’ś§ő Out-of-sample ó ‘^§«§ §§§ő§«◊Ę“‚ ∑«∂®≥£–‘§őīś‘ŕ§ň◊Ę“‚§Ľ§Ť •∑•ů•◊•Ž§ •‚•«•Ž§ő∑ŧ¨ļ√§ř§∑§§ Ďť¬‘§¨ĄŔ§∆§Ž§ę∑٧ꧫ§ §Į—–ĺŅ§őŔ|§Ú÷ō“ē§Ľ§Ť
- 25. Ĺū»ŕôCťv§ő•Ļ•»•ž•Ļ•∆•Ļ•» 25 £™ •Ļ•»•ž•Ļ•∑• •Í•™ §ÚŌŽ∂®§∑ [≥ō…≠, 18] £™ §Ĺ§őąŲļŌ§ő •ņ•Š©`•ł§Ú•∑•Ŗ•Ś•ž©`•∑•Á•ů §∑§∆ £™ •Ę•Į•∑•Á•ů•◊•ť•ů §Ú§Ę§ť§ę§ł§Š◊h’ď§∑§∆§™§Į ? ĺįö›§őīů∑ý§ źôĽĮ ? ŔYģbĀżłŮ§őľĪ¬š ? Ĺū»ŕ –ąŲ§őŃųĄ”–‘Ņ›úf ? ďp ߧőįk…ķ ? ŔYĹūņR§Í§őźôĽĮ •›•§•ů•»§Ō “Ľ∂»§‚”Qúy§Ķ§ž§∆§§§ §§•∑• •Í•™§Ú •∑•Ŗ•Ś•ž©`•∑•Á•ů§«◊ų§Ž§≥§» •Í•Ļ•ĮĻ‹ņŪŐŚ÷∆§ő≤Ľāš§Ú•ę•–©`§Ļ§Ž§Ņ§Š§őó ‘^
- 26. •Ļ•»•ž•Ļ•∑• •Í•™§«§őó ‘^ 26 £™ •Ļ•»•ž•Ļ•∑• •Í•™£Ĺ∑« IID •«©`•Ņ§ÚĽÓ”√ £™ •‚•«•Ž§¨–ŇÓm§ň◊„§Ž§ę?ĪĺŔ|Ķń§ ėč‘ž§Ú•®•ů•≥©`•…§∑§∆§§§Ž§ęó ‘^ 1 Stratified Performance Evaluation 2 Shifted Performance Evaluation 3 Contrastive Evaluation Subgroup §«ó ‘^ ∑÷≤ľ§Ú•∑•’•»§Ķ§Ľ§∆ó ‘^ Őō∂®•Ķ•ů•◊•Ž§ňḈ∑§∆Őō∂®§őČšďQ§Ú ©§∑≥ŲѶ§Úó ‘^ [D'Amour+ 20]
- 27. Stratified Performance Evaluation 27 1 [Oakden-Rayner+ 19] £™ •ť•Ŕ•Žł∂§Ī§Ķ§ž§Ņłų•Į•ť•Ļ§Ō —} ż§ő•Ķ•÷•Ľ•√•»§ę§ťėč≥…§Ķ§ž§Ž £™ »ęŐŚ§ő’żĹ‚¬ §ņ§Ī§Ú“ä§∆§§§Ž§» –‘ń‹§¨Ń”§Ž…Ŕ ż§ő•Ķ•÷•Ľ•√•»§š Spurious Correlation §Ú“䬚§»§Ļ •Ŕ•ů•¨•Ž •∑•„•ŗ •ŕ•Ž•∑•„ •ť•Ŕ•Ž£ļ√® 2% 38% 60% ChestXray14 §őņż£ļ £™ ö›–ō§ő•ť•Ŕ•Ž§¨§ń§§§ŅĽ≠Ō٧ő§¶§ŃīůįŽ§Ō–ō«Ľ•Ń•Ś©`•÷§Ę§Í £®ö›–ō§ő÷őĮü§»§∑§∆”√§§§ť§ž§Ž§‚§ő£© £™ §ŗ§∑§Ū–ō«Ľ•Ń•Ś©`•÷§ő–ī§√§∆§§§ §§Ľ≠ŌŮ §Ú’ż§∑§Į”Ťúy§∑§ §§§»…ķňņ§ňťv§Ô§Ž
- 28. Shifted Performance Evaluation 28 2 ”Ėĺö•«©`•Ņ§ő∑÷≤ľ§»ģź§ §Ž∑÷≤ľ§Ú◊ų§Ž £™ •ť•Ŕ•Ž§ÚČš§®§ §§§Ť§¶§ň»ŽŃ¶§ÚČšďQ§Ķ§Ľ§Ž ImageNet §őĽ≠Ō٧ÚČšďQ§∑§Ņ ImageNetC § §… £™ •«©`•Ņ§őÖßľĮ§ő∑Ĺ∑®§ÚČš§®§Ž ImageNet §ňļ¨§ř§ž§ §§§Ť§¶§ •§•ž•ģ•Ś•ť©`§ •Ī©`•Ļ§ÚľĮ§Š§ŅObjectNet § §… [Hendrycks+ 19] [Barbu+ 19] §…§ů§ ČšďQ§¨Ņľ§®§ť§ž§Ž§ę/§…§¶§š§√§∆•«©`•Ņ§ÚľĮ§Š§ §™§Ļ§ę§Ō ¨FĆgĶń§ň§Ōīů§≠§ ÜĖÓ}
- 29. Contrastive Evaluation 29 3 āÄĄe•Ķ•ů•◊•Ž§ī§»§ňČšďQ§Ú ©§∑”Ťúyāé§őí§Ą”§Úī_’J £™ Fairness §ň•’•©©`•ę•Ļ§∑§Ņ—–ĺŅ§¨∂ŗ ż £™ NLP §ň§™§§§∆§‚§§§Į§ń§ę•∆•Ļ•»§¨ŐŠįł§Ķ§ž§∆§§§Ž •Ķ•ů•◊•Ž§ī§»§ň•ť•Ŕ•Ž§ÚĪ£≥÷§Ļ§Ž/∑ī‹ě§Ķ§Ľ§ŽČšďQ§¨◊ų§ž§ž§–§Ĺ§ž§Ú§‚§»§ň•«©`•ŅíąŹą§∑§∆—ßŃē§«§≠§Ž Sensitive attribute §ő§Ŗ§¨Čš§Ô§√§∆§‚•‚•«•Ž§ő≥ŲѶ§ŌČš§Ô§√§∆§Ř§∑§Į§ §§ Ęŕ£ļ∑÷≤ľ§Ú•∑•’•»§Ķ§Ľ§Ņ•«©`•Ņ•Ľ•√•»»ęŐŚ§őĺę∂»§ň•’•©©`•ę•Ļ ĘŘ£ļāÄ°©§ő•Ķ•ů•◊•Ž§ő”Ťúyā駨∆ŕīżÕ®§ÍČš§Ô§Ž§ę§ň•’•©©`•ę•Ļ őń’¬÷–§őĶō√Ż§¨Čš§Ô§√§∆§‚•Ľ•ů•Ń•Š•ů•»§ŌČš§Ô§√§∆§Ř§∑§Į§ §§ [Kaushik+ 20] [Ribeiro+ 20] [Kusner+ 17]
- 30. °ĺ§ř§»§Š°ŅĹū»ŕ °Ń ôC–Ķ—ßŃē§««ů§Š§ť§ž§Ž“™’ą?∆∑Ŕ|§»§Ō£Ņ 30 ? ∑«∂®≥£§ ∑÷≤ľ§Ú«įŐŠ§ň§∑§Ņ•‚•«•Ž§ő–ŇÓm–‘§¨Īō“™ ? Ŗm«–§ •Ļ•»•ž•Ļ•∑• •Í•™§Ú‘O∂®§∑§∆•‚•«•Ž§¨–ŇÓm§«§≠§Ĺ§¶§ęī_’J ? •‚•«•Ž§ň»ňťg§¨Ĺť‘ŕ§∑§Ņ“‚ňľõQ∂®§¨∂ŗ§Į ◊īõröį§ňėĒ°©§ “™ľĢ ? ó ‘^§ň§‚»ň ÷§¨Īō“™§ §ő§«ó ‘^§ŌłŖ•≥•Ļ•» ŔYģb 100 ōďāý 50 ľÉŔYģb 50 §≥§≥6•ę‘¬§ő»’ĹU∆Ĺĺý £Ņ
- 31. Reference ? Arnott, Robert D. and Harvey, Campbell R. and Markowitz, Harry, A Backtesting Protocol in the Era of Machine Learning (November 21, 2018). Available at SSRN: https://ssrn.com/abstract=3275654 or http://dx.doi.org/10.2139/ssrn.3275654 ? Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S. Lasecki, Daniel S. Weld, Eric HorvitzIn. Beyond Accuracy: The Role of Mental Models in Human-AI Team Performance. In Proceedings of the AAAI Conference on Human Computation and Crowdsourcing, 2019. ? Gagan Bansal, Besmira Nushi, Ece Kamar, Daniel S. Weld, Walter S. Lasecki and Eric Horvitz. Updates in Human-AI Teams: Understanding and Addressing the Performance/Compatibility Tradeoff. In AAAI, 2019. ? Andrei Barbu, David Mayo, Julian Alverio, William Luo, Christopher Wang, Dan Gutfreund, Josh Tenenbaum, Boris Katz. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. In NeurIPS, 2019. ? A. D°ĮAmour, K. Heller, D. Moldovan, B. Adlam, B. Alipanahi, A. Beutel, C. Chen, J. Deaton, J. Eisenstein, M. D. Hoffman, et al. Underspecification presents challenges for credibility in modern machine learning. arXiv preprint arXiv:2011.03395, 2020. ? Dan Hendrycks and Thomas Dietterich. Benchmarking Neural Network Robustness to Common Corruptions and Perturbations. In ICLR, 2019. ? Divyansh Kaushik, Eduard Hovy, Zachary Lipton. Learning The Difference That Makes A Difference With Counterfactually-Augmented Data. In ICLR, 2020. ? Matt J. Kusner, Joshua Loftus, Chris Russell, Ricardo Silva. Counterfactual Fairness. In NeurIPS, 2017. ? Vivian Lai and Chenhao Tan. On Human Predictions with Explanations and Predictions of Machine Learning Models: A Case Study on Deception Detection. In FAccT, 2019. ? David Madras, Toniann Pitassi & Richard Zemel. Predict Responsibly: Improving Fairness and Accuracy by Learning to Defer. In NeurIPS, 2018. ? Hussein Mozannar, David Sontag. Consistent Estimators for Learning to Defer to an Expert. In ICML, 2020. ? Luke Oakden-Rayner, Jared Dunnmon, Gustavo Carneiro, Christopher R®¶. Hidden Stratification Causes Clinically Meaningful Failures in Machine Learning for Medical Imaging. In Machine Learning for Health (ML4H) at NeurIPS, 2019. ? Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, Sameer Singh. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList. In ACL, 2020. ? ≥ō…≠ Ņ°őń. „y––ĹUÜ”§ő§Ņ§Š§ő żņŪĶńĖėĹM§Ŗ®DĹū»ŕ•Í•Ļ•Į§ő÷∆”ý. •◊•Ū•į•ž•Ļ£¨2018. £® į§√§∆§≠§ŅĽ≠ŌŮ£© ? https://press.share-wis.com/german-hyperinflation ? https://buzzap.jp/news/20140324-cantury-old-animal-photography/ 31