






























Data-Oriented Designкіј мң лӢҲнӢ° DOTS
- 1. 2020-05-09 м ң 540нҡҢ Dev-Rookie л°ңн‘ңмһҗ мқҙм„қмҡ° Data-Oriented Design and Unity DOTS
- 2. DODмқҳ кё°мӣҗмқ„ м„ӨлӘ…н•ҳкё° мң„н•ҙм„ лЁјм Җ м»ҙн“Ён„° н•ҳл“ңмӣЁм–ҙм—җ лҢҖн•ң мқҙн•ҙк°Җ н•„мҡ”н•ҳлӢӨ.
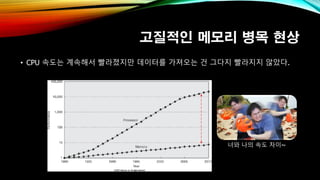
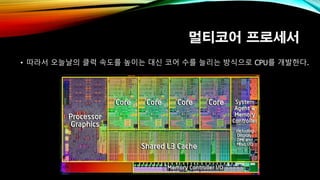
- 3. кі м§Ҳм Ғмқё л©”лӘЁлҰ¬ лі‘лӘ© нҳ„мғҒ вҖў CPU мҶҚлҸ„лҠ” кі„мҶҚн•ҙм„ң л№ЁлқјмЎҢм§Җл§Ң лҚ°мқҙн„°лҘј к°Җм ёмҳӨлҠ” кұҙ к·ёлӢӨм§Җ л№Ёлқјм§Җм§Җ м•Ҡм•ҳлӢӨ. л„ҲмҷҖ лӮҳмқҳ мҶҚлҸ„ м°Ёмқҙ~
- 4. м§Җм—ӯм„ұмқҳ мӣҗлҰ¬(Principle of Locality) вҖў мӢңк°„м Ғ м§Җм—ӯм„ұ : мөңк·ј м°ёмЎ°лҗң л©”лӘЁлҰ¬ мЈјмҶҢлҠ” к°Җк№Ңмҡҙ лҜёлһҳм—җ лӢӨмӢң н•ңлІҲ м°ёмЎ°лҗҳлҠ” кІҪн–Ҙ вҖў ex) л°ҳліөл¬ё, л°©кёҲ мӮ¬мҡ©н•ң лӘ…л №м–ҙмҷҖ лҚ°мқҙн„°м—җ л°ҳліөн•ҙм„ң м ‘к·ј вҖў кіөк°„м Ғ м§Җм—ӯм„ұ : мөңк·ј м°ёмЎ°лҗң л©”лӘЁлҰ¬ мЈјмҶҢмқҳ мқҙмӣғмқҙ к°Җк№Ңмҡҙ лҜёлһҳм—җ м°ёмЎ°лҗҳлҠ” кІҪн–Ҙ вҖў ex) л°°м—ҙ мҲңнҡҢ вҖў мҳӨлҠҳлӮ мқҳ м»ҙн“Ён„°лҠ” мқҙ м§Җм—ӯм„ұмқ„ кі л Өн•ҳм—¬ л©”лӘЁлҰ¬ лі‘лӘ© нҳ„мғҒмқ„ мөңмҶҢнҷ” н•ңлӢӨ.
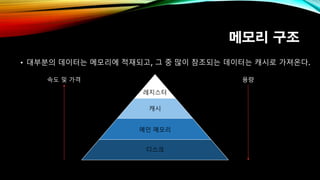
- 5. л©”лӘЁлҰ¬ кө¬мЎ° вҖў лҢҖл¶Җ분мқҳ лҚ°мқҙн„°лҠ” л©”лӘЁлҰ¬м—җ м Ғмһ¬лҗҳкі , к·ё мӨ‘ л§Һмқҙ м°ёмЎ°лҗҳлҠ” лҚ°мқҙн„°лҠ” мәҗмӢңлЎң к°Җм ёмҳЁлӢӨ. л Ҳм§ҖмҠӨн„° мәҗмӢң л©”мқё л©”лӘЁлҰ¬ л””мҠӨнҒ¬ мҶҚлҸ„ л°Ҹ к°ҖкІ© мҡ©лҹү
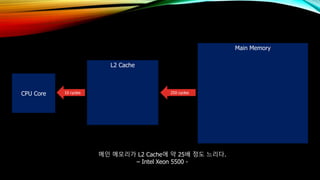
- 6. CPU Core L2 Cache Main Memory 10 cycles 250 cycles л©”мқё л©”лӘЁлҰ¬к°Җ L2 Cacheм—җ м•Ҫ 25л°° м •лҸ„ лҠҗлҰ¬лӢӨ. вҖ“ Intel Xeon 5500 -
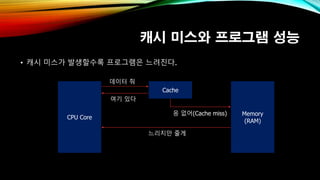
- 7. мәҗмӢң лҜёмҠӨмҷҖ н”„лЎңк·ёлһЁ м„ұлҠҘ вҖў мәҗмӢң лҜёмҠӨк°Җ л°ңмғқн• мҲҳлЎқ н”„лЎңк·ёлһЁмқҖ лҠҗл Ө진лӢӨ. CPU Core Cache Memory (RAM) лҚ°мқҙн„° мӨҳ м—¬кё° мһҲлӢӨ мқ‘ м—Ҷм–ҙ(Cache miss) лҠҗлҰ¬м§Җл§Ң мӨ„кІҢ
- 8. мәҗмӢң лҜёмҠӨлҘј мөңмҶҢнҷ”н•ҳкё° мң„н•ҙм„ м–ҙл–»кІҢ мҪ”л“ңлҘј м§ңм•ј н• к№Ң?
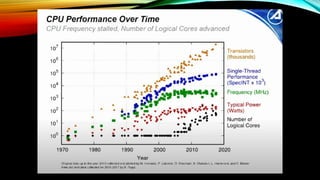
- 9. кіјкұ°мқҳ CPU к°ңл°ң вҖў мӢұкёҖ мҪ”м–ҙл§Ң мӮ¬мҡ©н•ҳм—¬ м„ұлҠҘмқ„ лҶ’мқҙкё° мң„н•ҙм„ң нҒҙлҹӯ мҶҚлҸ„лҘј лҶ’мқҙлҠ” л°©лІ•мқ„ мЈјлЎң мӮ¬мҡ© н–ҲлӢӨ. вҖў к·ёлҹ¬лӮҳ нҒҙлҹӯмқ„ лҶ’мқҙл©ҙ м „л Ҙ мҶҢлӘЁлҹүмқҙ л§Һм•„м§ҖлҠ” кІғмқҖ л¬јлЎ л°ңм—ҙк№Ңм§Җ мӢ¬н•ҙ진лӢӨ.
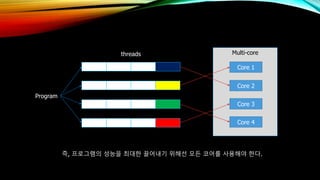
- 10. л©ҖнӢ°мҪ”м–ҙ н”„лЎңм„ём„ң вҖў л”°лқјм„ң мҳӨлҠҳлӮ мқҳ нҒҙлҹӯ мҶҚлҸ„лҘј лҶ’мқҙлҠ” лҢҖмӢ мҪ”м–ҙ мҲҳлҘј лҠҳлҰ¬лҠ” л°©мӢқмңјлЎң CPUлҘј к°ңл°ңн•ңлӢӨ.
- 11. Program Multi-core Core 1 Core 2 Core 3 Core 4 threads мҰү, н”„лЎңк·ёлһЁмқҳ м„ұлҠҘмқ„ мөңлҢҖн•ң лҒҢм–ҙлӮҙкё° мң„н•ҙм„ лӘЁл“ мҪ”м–ҙлҘј мӮ¬мҡ©н•ҙм•ј н•ңлӢӨ.
- 13. л©ҖнӢ°м“°л Ҳл”©мқҖ м–ҙл өлӢӨвҖҰ мқҙкІғмқ„ мүҪкі нҡЁмңЁм ҒмңјлЎң нҢЁн„ҙнҷ”мӢңнӮ¬ л°©лІ•мқҖ м—Ҷмқ„к№Ң?
- 14. Data-Oriented Design вҖў мҳӨлҠҳлӮ м»ҙн“Ён„° н•ҳл“ңмӣЁм–ҙм—җ мөңм Ғнҷ”лҗң л””мһҗмқё нҢЁн„ҙ вҖў мәҗмӢң лҜёмҠӨлҘј мөңмҶҢнҷ”н•ҳкі л©ҖнӢ°м“°л Ҳл”©мқ„ н•ҳкё° мүҪкІҢ мҪ”л“ңлҘј м§Ө мҲҳ мһҲлӢӨ.
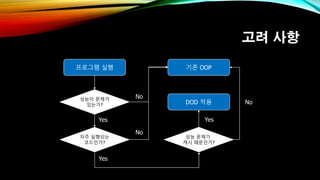
- 15. кі л Ө мӮ¬н•ӯ м„ұлҠҘмқҙ л¬ём ңк°Җ мһҲлҠ”к°Җ? н”„лЎңк·ёлһЁ мӢӨн–ү мһҗмЈј мӢӨн–үлҗҳлҠ” мҪ”л“ңмқёк°Җ? DOD м Ғмҡ© м„ұлҠҘ л¬ём ңк°Җ мәҗмӢң л•Ңл¬ёмқёк°Җ? Yes Yes Yes кё°мЎҙ OOP No No No
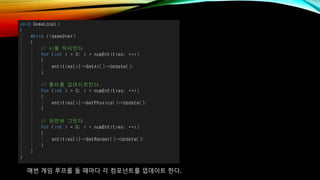
- 16. OOPлҘј мқҙмҡ©н•ң кІҢмһ„ лЎңм§Ғ кө¬нҳ„ вҖў кІҢмһ„ м—”нӢ°нӢ°лҠ” AI, л¬јлҰ¬, л ҢлҚ” м»ҙнҸ¬л„ҢнҠёлҘј к°Җ진лӢӨ.
- 17. к°Ғ м»ҙнҸ¬л„ҢнҠём—җлҠ” мғҒнғңлҘј м—…лҚ°мқҙнҠён•ҳкё° мң„н•ң л©”м„ңл“ңк°Җ л“Өм–ҙмһҲлӢӨ.
- 18. л§ӨлІҲ кІҢмһ„ лЈЁн”„лҘј лҸҢ л•Ңл§ҲлӢӨ к°Ғ м»ҙнҸ¬л„ҢнҠёлҘј м—…лҚ°мқҙнҠё н•ңлӢӨ.
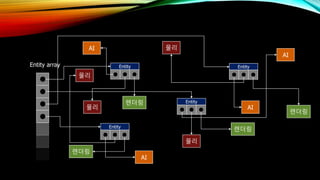
- 20. OOPмқҳ л¬ём ңм җ в‘ кІҢмһ„ м—”нӢ°нӢ°лҘј нҸ¬мқён„°лЎң м ‘к·ј пғҳмәҗмӢң лҜёмҠӨ л°ңмғқ в‘Ў кІҢмһ„ м—”нӢ°нӢ°мқҳ м»ҙнҸ¬л„ҢнҠёлҘј нҸ¬мқён„°лЎң м ‘к·ј пғҳмәҗмӢң лҜёмҠӨ л°ңмғқ в‘ў м»ҙнҸ¬л„ҢнҠёлҘј м—…лҚ°мқҙнҠён•ңлӢӨ. в‘Ј лӘЁл“ м—”нӢ°нӢ°м—җ лҢҖн•ҙ к°ҷмқҖ мһ‘м—…мқ„ л°ҳліөн•ңлӢӨ. л”°лқјм„ң мӮ¬мӢӨмғҒ мң„мҷҖ к°ҷмқҖ мқҳлҜёлҘј м§ҖлӢҢлӢӨ.
- 21. DOD м Ғмҡ© вҖў к°Ғ м»ҙнҸ¬л„ҢнҠё лі„лЎң л°°м—ҙмқ„ мғқм„ұн•ҳм—¬ к°қмІҙлҘј лӢҙлҠ”лӢӨ. AI л ҢлҚ”л§Ғ л¬јлҰ¬ AI AI AI л¬јлҰ¬ л¬јлҰ¬ л¬јлҰ¬ л ҢлҚ”л§Ғ л ҢлҚ”л§Ғ л ҢлҚ”л§Ғ к°Ғ м»ҙнҸ¬л„ҢнҠё к°қмІҙлҘј л°°м—ҙлЎң мғқм„ұн•ҳл©ҙ л©”лӘЁлҰ¬ мғҒм—җм„ң мқјл ¬лЎң мғқм„ұлҗңлӢӨ. лҚ°мқҙн„°лҘј мәҗмӢңлЎң мҳ®кёё л•Ң мЈјліҖ лҚ°мқҙн„°лҸ„ лё”лЎқ лӢЁмң„лЎң н•Ёк»ҳ мҳ®кІЁм§ҖлҜҖлЎң мәҗмӢң лҜёмҠӨк°Җ мӨ„м–ҙл“ лӢӨ.
- 22. DOD м Ғмҡ©
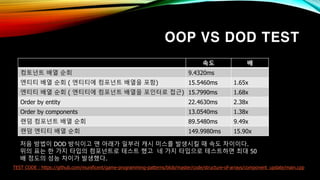
- 23. OOP VS DOD TEST вҖў DOD л°©мӢқ : 9.4320ms вҖў Entityм—җ м»ҙнҸ¬л„ҢнҠё л°°м—ҙмқ„ лҚ°мқҙн„°лЎң к°Җм§Җкі мһҲмқҢ : вҖў Entityк°Җ м»ҙнҸ¬л„ҢнҠё л°°м—ҙмқ„ нҸ¬мқён„°лЎң м ‘к·ј : TEST CODE : https://github.com/munificent/game-programming-patterns/blob/master/code/structure-of-arrays/component_update/main.cpp мҶҚлҸ„ л°° м»ҙнҶ л„ҢнҠё л°°м—ҙ мҲңнҡҢ 9.4320ms м—”нӢ°нӢ° л°°м—ҙ мҲңнҡҢ ( м—”нӢ°нӢ°м—җ м»ҙнҸ¬л„ҢнҠё л°°м—ҙмқ„ нҸ¬н•Ё) 15.5460ms 1.65x м—”нӢ°нӢ° л°°м—ҙ мҲңнҡҢ ( м—”нӢ°нӢ°м—җ м»ҙнҸ¬л„ҢнҠё л°°м—ҙмқ„ нҸ¬мқён„°лЎң м ‘к·ј) 15.7990ms 1.68x Order by entity 22.4630ms 2.38x Order by components 13.0540ms 1.38x лһңлҚӨ м»ҙнҸ¬л„ҢнҠё л°°м—ҙ мҲңнҡҢ 89.5480ms 9.49x лһңлҚӨ м—”нӢ°нӢ° л°°м—ҙ мҲңнҡҢ 149.9980ms 15.90x мІҳмқҢ л°©лІ•мқҙ DOD л°©мӢқмқҙкі л§Ё м•„лһҳк°Җ мқјл¶Җлҹ¬ мәҗмӢң лҜёмҠӨлҘј л°ңмғқмӢңнӮ¬ л•Ң мҶҚлҸ„ м°ЁмқҙмқҙлӢӨ. мң„мқҳ н‘ңлҠ” н•ң к°Җм§Җ нғҖмһ…мқҳ м»ҙнҸ¬л„ҢнҠёлЎң н…ҢмҠӨнҠё н–Ҳкі л„Ө к°Җм§Җ нғҖмһ…мңјлЎң н…ҢмҠӨнҠён•ҳл©ҙ мөңлҢҖ 50 л°° м •лҸ„мқҳ м„ұлҠҘ м°Ёмқҙк°Җ л°ңмғқн–ҲлӢӨ.
- 24. DOD м Ғмҡ© мӮ¬лЎҖ Parallelizing Conqueror's Blade Culling the Battlefield : Data Oriented Design in Practice Data-Oriented Design and C++
- 25. м Җкұ° лӢӨ м„ӨлӘ…н•ҳл Өл©ҙ мқјмЈјмқј лӮҙлӮҙ л°ңн‘ңн•ҙм•ј н•Ё. лҢҖ충 мң лӢҲнӢ°л§Ң м•Ңм•„лҙ…мӢңлӢӨ.
- 26. м–ҳл“Өм•„ лӮҳ мң лӢҲнӢ° мҪ”нҺңн•ҳкІҗ к°”лӢӨмҷ”м–ҙ. кұ°кё°м„ң DOTS л°ңн‘ңн•ҳлҚ”лқјмҳ¬г…Ӣ к·ёлһҳлҙӨмһҗ мң лӢҲнӢ°вҖҰ лӢҲл“ӨмқҖ м–ёлҰ¬м–ј м„ұлӢҳ лӘ»л”°лқј к°„лӢӨ - нҸүнҷ”лЎңмҡҙ мҠӨн„°л”” мӨ‘ м–ҙлҠҗ лӮ -
- 27. - мҪ”лЎңлӮҳ мӮ¬нғңлЎң мү¬лҚҳ мӨ‘ - м•„ мӢ¬мӢ¬н•ҙ лӯҗн• кәј м—ҶлӮҳвҖҰ к·ёл•Ң м•ҢмҪңмҪ”лҚ”лӢҳмқҙ л§җм”Җн•ҳмӢ л°ңн‘ңлӮҳ ліјк№Ң? мқҙкұҙ л°ңн‘ң н•ҙм•јл§Ң н•ҙ н—җ?! мқҙлҹҙмҲҳк°Җ
- 28. Unity DOTS вҖў Data-Oriented Tech Stack пғјк·ёлғҘ DODлқј н•ҳл©ҙ м—Ҷм–ҙ ліҙмқҙмһ–м•„? вҖў н•өмӢ¬ кё°лҠҘ пғјECS Model пғјJob System пғјBurst Compiler
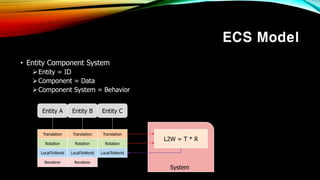
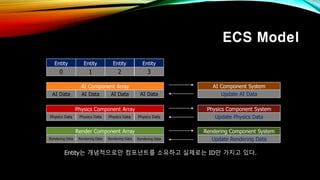
- 29. ECS Model вҖў Entity Component System пғҳEntity = ID пғҳComponent = Data пғҳComponent System = Behavior Entity A Entity B Entity C System Translation Rotation LocalToWorld Renderer Translation Rotation LocalToWorld Renderer Translation Rotation LocalToWorld L2W = T * R
- 30. ECS Model AI Data Rendering Data Physics Data Rendering Data Rendering Data Rendering Data AI Data Physics Data AI Data Physics Data AI Data Physics Data EntityлҠ” к°ңл…җм ҒмңјлЎңл§Ң м»ҙнҸ¬л„ҢнҠёлҘј мҶҢмң н•ҳкі мӢӨм ңлЎңлҠ” IDл§Ң к°Җм§Җкі мһҲлӢӨ. Entity 0 Entity 1 Entity 2 Entity 3 AI Component Array Physics Component Array Render Component Array Update AI Data AI Component System Update Physics Data Physics Component System Update Rendering Data Rendering Component System
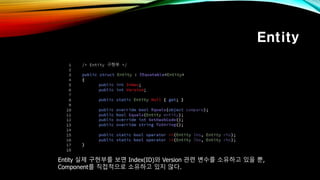
- 31. Entity Entity мӢӨм ң кө¬нҳ„л¶ҖлҘј ліҙл©ҙ Index(ID)мҷҖ Version кҙҖл Ё ліҖмҲҳлҘј мҶҢмң н•ҳкі мһҲмқ„ лҝҗ, ComponentлҘј м§Ғм ‘м ҒмңјлЎң мҶҢмң н•ҳкі мһҲм§Җ м•ҠлӢӨ.
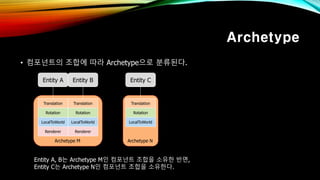
- 32. Archetype N Archetype вҖў м»ҙнҸ¬л„ҢнҠёмқҳ мЎ°н•©м—җ л”°лқј ArchetypeмңјлЎң 분лҘҳлҗңлӢӨ. Entity A, BлҠ” Archetype Mмқё м»ҙнҸ¬л„ҢнҠё мЎ°н•©мқ„ мҶҢмң н•ң л°ҳл©ҙ, Entity CлҠ” Archetype Nмқё м»ҙнҸ¬л„ҢнҠё мЎ°н•©мқ„ мҶҢмң н•ңлӢӨ. Entity A Entity B Entity C Translation Rotation LocalToWorld Renderer Translation Rotation LocalToWorld Renderer Translation Rotation LocalToWorld Archetype M
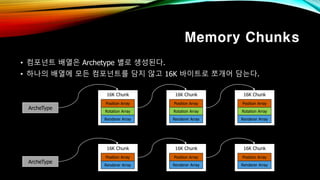
- 33. Memory Chunks вҖў м»ҙнҸ¬л„ҢнҠё л°°м—ҙмқҖ Archetype лі„лЎң мғқм„ұлҗңлӢӨ. вҖў н•ҳлӮҳмқҳ л°°м—ҙм—җ лӘЁл“ м»ҙнҸ¬л„ҢнҠёлҘј лӢҙм§Җ м•Ҡкі 16K л°”мқҙнҠёлЎң мӘјк°ңм–ҙ лӢҙлҠ”лӢӨ. ArcheType 16K Chunk Position Array Rotation Array Renderer Array 16K Chunk Position Array Rotation Array Renderer Array 16K Chunk Position Array Rotation Array Renderer Array ArcheType 16K Chunk Position Array Renderer Array 16K Chunk Position Array Renderer Array 16K Chunk Position Array Renderer Array
- 34. World вҖў WorldлҠ” н•ҳлӮҳмқҳ EntityManager к°қмІҙмҷҖ System Groupмқ„ нҸ¬н•Ён•ҳлҠ” к°ңл…җмқҙлӢӨ. World Entity Manager System Group World Entity Manager System Group World Entity Manager System Group
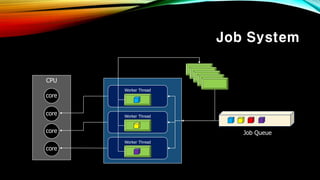
- 35. Job System вҖў мӮ¬мҡ©мһҗк°Җ м“°кё° мүҪлҸ„лЎқ кө¬нҳ„лҗң л©ҖнӢ°м“°л Ҳл”© лқјмқҙлёҢлҹ¬лҰ¬ Parallelizing the Naughty Dog Engine Using Fibers(2015) - GDC Vault
- 36. Job System : Terms Job : мӢӨн–үн• мһ‘м—… Worker Thread Fiber : Jobмқ„ мӢӨн–үн•ҳкё° мң„н•ң Context ( User provided stack, register) Worker Thread Worker Thread : Jobмқ„ мӢӨн–үн• мң лӢӣ Worker Thread
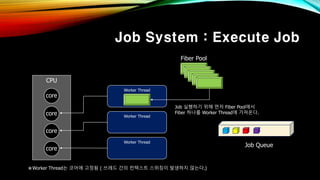
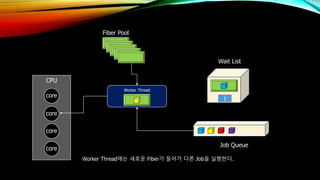
- 37. Job System : Execute Job CPU core core core core Worker Thread Worker Thread Worker Thread Fiber Pool Job Queue вҖ»Worker ThreadлҠ” мҪ”м–ҙм—җ кі м •лҗЁ ( м“°л Ҳл“ң к°„мқҳ м»Ён…ҚмҠӨнҠё мҠӨмң„м№ӯмқҙ л°ңмғқн•ҳм§Җ м•ҠлҠ”лӢӨ.) Job мӢӨн–үн•ҳкё° мң„н•ҙ лЁјм Җ Fiber Poolм—җм„ң Fiber н•ҳлӮҳлҘј Worker Threadм—җ к°Җм ёмҳЁлӢӨ.
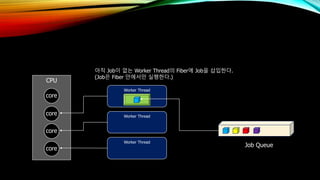
- 38. CPU core core core core Worker Thread Worker Thread Worker Thread Job Queue м•„м§Ғ Jobмқҙ м—ҶлҠ” Worker Threadмқҳ Fiberм—җ Jobмқ„ мӮҪмһ…н•ңлӢӨ. (JobмқҖ Fiber м•Ҳм—җм„ңл§Ң мӢӨн–үн•ңлӢӨ.)
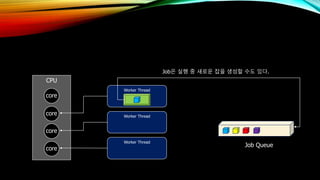
- 39. CPU core core core core Worker Thread Worker Thread Worker Thread Job Queue JobмқҖ мӢӨн–ү мӨ‘ мғҲлЎңмҡҙ мһЎмқ„ мғқм„ұн• мҲҳлҸ„ мһҲлӢӨ.
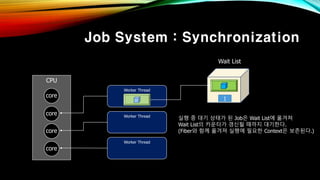
- 40. Job System : Synchronization CPU core core core core Worker Thread Worker Thread Worker Thread Wait List 1 мӢӨн–ү мӨ‘ лҢҖкё° мғҒнғңк°Җ лҗң JobмқҖ Wait Listм—җ мҳ®кІЁм ё Wait Listмқҳ м№ҙмҡҙн„°к°Җ к°ұмӢ лҗ л•Ңк№Ңм§Җ лҢҖкё°н•ңлӢӨ. (FiberмҷҖ н•Ёк»ҳ мҳ®кІЁм ё мӢӨн–үм—җ н•„мҡ”н•ң ContextмқҖ ліҙмЎҙлҗңлӢӨ.)
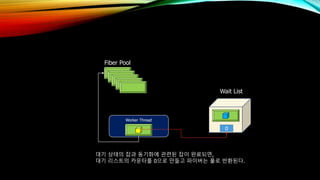
- 41. CPU core core core core Worker Thread Wait List 1 Worker Threadм—җлҠ” мғҲлЎңмҡҙ Fiberк°Җ л“Өм–ҙк°Җ лӢӨлҘё Jobмқ„ мӢӨн–үн•ңлӢӨ. Fiber Pool Job Queue
- 42. Worker Thread Wait List 0 лҢҖкё° мғҒнғңмқҳ мһЎкіј лҸҷкё°нҷ”м—җ кҙҖл Ёлҗң мһЎмқҙ мҷ„лЈҢлҗҳл©ҙ, лҢҖкё° лҰ¬мҠӨнҠёмқҳ м№ҙмҡҙн„°лҘј 0мңјлЎң л§Ңл“Өкі нҢҢмқҙлІ„лҠ” н’ҖлЎң л°ҳнҷҳлҗңлӢӨ. Fiber Pool
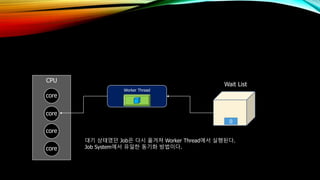
- 43. CPU core core core core Worker Thread Wait List 0 лҢҖкё° мғҒнғңмҳҖлҚҳ JobмқҖ лӢӨмӢң мҳ®кІЁм ё Worker Threadм—җм„ң мӢӨн–үлҗңлӢӨ. Job Systemм—җм„ң мң мқјн•ң лҸҷкё°нҷ” л°©лІ•мқҙлӢӨ.
- 44. Job System CPU core core core core Worker Thread Worker Thread Worker Thread Job Queue
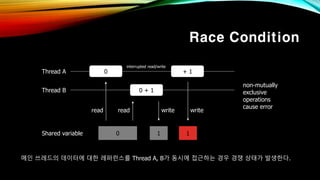
- 45. Race Condition 0Thread A + 1 0 + 1Thread B 0Shared variable 1 1 read read write write л©”мқё м“°л Ҳл“ңмқҳ лҚ°мқҙн„°м—җ лҢҖн•ң л ҲнҚјлҹ°мҠӨлҘј Thread A, Bк°Җ лҸҷмӢңм—җ м ‘к·јн•ҳлҠ” кІҪмҡ° кІҪмҹҒ мғҒнғңк°Җ л°ңмғқн•ңлӢӨ. non-mutually exclusive operations cause error interrupted read/write
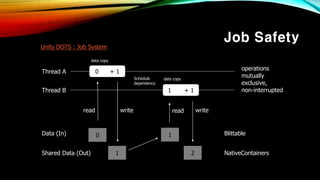
- 46. Job Safety Unity DOTS : Job System 0 + 1Thread A 1 + 1Thread B Data (In) 1 read read writewrite operations mutually exclusive, non-interrupted Shared Data (Out) 1 0 2 Schedule dependency Blittable NativeContainers data copy data copy
- 47. Job Safety вҖў мһЎ мӢңмҠӨн…ңмқҖ л©”мқё мҠӨл Ҳл“ңмқҳ лҚ°мқҙн„°м—җ лҢҖн•ң л ҲнҚјлҹ°мҠӨлҘј мһЎм—җ ліҙлӮҙм§Җ м•Ҡкі , лҚ°мқҙн„°мқҳ ліө мӮ¬ліёмқ„ ліҙлӮёлӢӨ. вҖў мқҙ ліөмӮ¬ліёмқҖ н•ҙлӢ№ мһЎ м•Ҳм—җм„ңл§Ң мӮ¬мҡ©н•ҳлҜҖлЎң кІҪмҹҒ мғҒнғңк°Җ л°ңмғқн•ҳм§Җ м•ҠлҠ”лӢӨ. вҖў мһЎмқҖ NativeContainerм—җ кІ°кіјлҘј м ҖмһҘн•ҳм—¬ лҚ°мқҙн„°лҘј кіөмң н• мҲҳ мһҲлӢӨ. вҖў мһЎ к°„мқҳ мӢӨн–ү мҲңм„ңлҠ” мӢӨн–ү мҳҲм•Ҫ(schedule)мқ„ нҶөн•ҙ м •н•ңлӢӨ. (Schedule dependency)
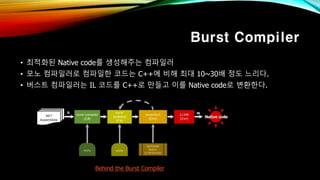
- 48. Burst Compiler вҖў мөңм Ғнҷ”лҗң Native codeлҘј мғқм„ұн•ҙмЈјлҠ” м»ҙнҢҢмқјлҹ¬ вҖў лӘЁл…ё м»ҙнҢҢмқјлҹ¬лЎң м»ҙнҢҢмқјн•ң мҪ”л“ңлҠ” C++м—җ 비н•ҙ мөңлҢҖ 10~30л°° м •лҸ„ лҠҗлҰ¬лӢӨ. вҖў лІ„мҠӨнҠё м»ҙнҢҢмқјлҹ¬лҠ” IL мҪ”л“ңлҘј C++лЎң л§Ңл“Өкі мқҙлҘј Native codeлЎң ліҖнҷҳн•ңлӢӨ. Behind the Burst Compiler
- 49. Burst Compilerмқҳ м ңм•Ҫ вҖў Job System лӮҙм—җм„ңл§Ң мӮ¬мҡ©н• мҲҳ мһҲлӢӨ. вҖў Managed к°қмІҙ(C# нҒҙлһҳмҠӨ)лҘј мӮ¬мҡ©н• мҲҳ м—ҶлӢӨ.
- 50. кё°мЎҙ мң лӢҲнӢ° л°©мӢқ вҖў MonoBehavior кё°л°ҳ нҒҙлһҳмҠӨм—җ лҚ°мқҙн„°мҷҖ н–үлҸҷмқ„ м •мқҳ MonoBehaviour вҖў Data вҖў Behavior MonoBehaviour вҖў Data вҖў Behavior MonoBehaviour вҖў Data вҖў Behavior MonoBehaviour вҖў Data вҖў Behavior
- 51. Pure ECS вҖў мҲңмҲҳ ECSлҠ” ComponentData кө¬мЎ°мІҙм—җ лҚ°мқҙн„°лҘј м •мқҳн•ҳкі мӢңмҠӨн…ңм—җм„ң н–үлҸҷмқ„ м •мқҳ IComponentData вҖў Data IComponentData вҖў Data IComponentData вҖў Data IComponentData вҖў Data ComponentSytem вҖў Behaviour
- 52. Hybrid ECS вҖў Hybrid ECSлҠ” MonoBehavior кё°л°ҳ нҒҙлһҳмҠӨм—җ лҚ°мқҙн„°л§Ң м •мқҳн•ҳкі мӢңмҠӨн…ңм—җм„ң н–үлҸҷмқ„ м •мқҳ MonoBehaviour вҖў Data MonoBehaviour вҖў Data MonoBehaviour вҖў Data MonoBehaviour вҖў Data ComponentSytem вҖў Behaviour
- 53. Component System мӢӨн–ү мҲңм„ң вҖў Component SystemмқҖ Initialization, Simulation, Presentation лӢЁкі„ мӨ‘ м–ҙл””м—җ мң„м№ҳн• м§Җ м„ нғқн• мҲҳ мһҲлӢӨ. (Default : Simulation) к°Ғ лӢЁкі„ лі„лЎң System Groupмқ„ мҶҢмң н•ҳкі мһҲмңјл©°, к°ңл°ңмһҗк°Җ м •мқҳн•ң Systemмқҳ мӢӨн–ү мҲңм„ңлҠ” мӣҗн•ҳлҠ” лҢҖлЎң м§Җм •н• мҲҳ мһҲлӢӨ. к·ёлҹ¬л©ҙ к·ём—җ л§һкІҢ Component Systemмқҳ OnUpdate н•ЁмҲҳк°Җ нҳём¶ң лҗңлӢӨ. Initialization Simulation Presentation
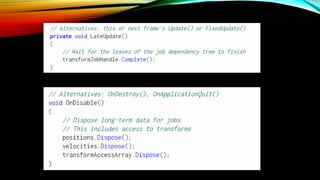
- 54. Component System мӢӨн–ү мҲңм„ң м°ёкі лЎң Monobehavior к°қмІҙмқҳ Update н•ЁмҲҳ нҳём¶ң мӢңкё°лҠ” мң„мҷҖ к°ҷлӢӨ. Initialization Simulation Presentation FixedUpdate() Update() LateUpdate()
- 55. м •лҰ¬ вҖў Data Oriented-DesignмқҖ нҳ„лҢҖ н•ҳл“ңмӣЁм–ҙм—җ м№ңнҷ”м Ғмқё л””мһҗмқё нҢЁн„ҙ вҖў мң лӢҲнӢ°лҠ” DODлҘј м Ғмҡ©н•ҳкё° мң„н•ҙ Dots лҸ„мһ… пғјECS пғјJobsystem пғјBurst Compiler вҖў м•„м§ҒмқҖ кіјлҸ„кё°мқҙкі м Ғмҡ© мӮ¬лЎҖк°Җ л№Ҳм•Ҫн•ҳм§Җл§Ң н–Ҙнӣ„ кё°лҢҖ
- 56. ECS Example нҒҗлёҢлҘј л§Ңл“Өм–ҙ RotatorлқјлҠ” мҠӨнҒ¬лҰҪнҠёлҘј 추к°Җн•ҳкі мҪ”л“ңлҘј м—°лӢӨ.
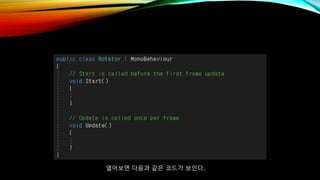
- 57. м—ҙм–ҙліҙл©ҙ лӢӨмқҢкіј к°ҷмқҖ мҪ”л“ңк°Җ ліҙмқёлӢӨ.
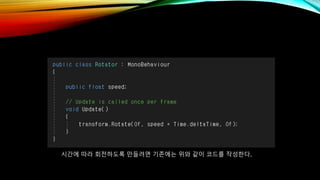
- 58. мӢңк°„м—җ л”°лқј нҡҢм „н•ҳлҸ„лЎқ л§Ңл“Өл Өл©ҙ кё°мЎҙм—җлҠ” мң„мҷҖ к°ҷмқҙ мҪ”л“ңлҘј мһ‘м„ұн•ңлӢӨ.
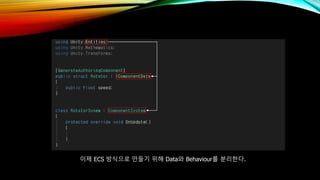
- 59. мқҙм ң ECS л°©мӢқмңјлЎң л§Ңл“Өкё° мң„н•ҙ DataмҷҖ BehaviourлҘј 분лҰ¬н•ңлӢӨ.
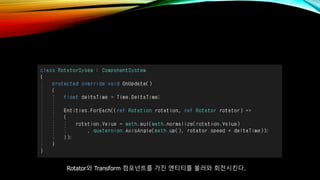
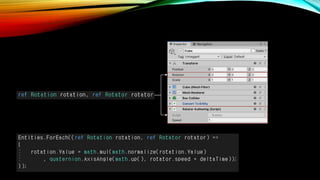
- 60. RotatorмҷҖ Transform м»ҙнҸ¬л„ҢнҠёлҘј к°Җ진 м—”нӢ°нӢ°лҘј л¶Ҳлҹ¬мҷҖ нҡҢм „мӢңнӮЁлӢӨ.
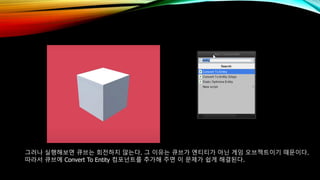
- 62. к·ёлҹ¬лӮҳ мӢӨн–үн•ҙліҙл©ҙ нҒҗлёҢлҠ” нҡҢм „н•ҳм§Җ м•ҠлҠ”лӢӨ. к·ё мқҙмң лҠ” нҒҗлёҢк°Җ м—”нӢ°нӢ°к°Җ м•„лӢҢ кІҢмһ„ мҳӨлёҢм қнҠёмқҙкё° л•Ңл¬ёмқҙлӢӨ. л”°лқјм„ң нҒҗлёҢм—җ Convert To Entity м»ҙнҸ¬л„ҢнҠёлҘј 추к°Җн•ҙ мЈјл©ҙ мқҙ л¬ём ңк°Җ мүҪкІҢ н•ҙкІ°лҗңлӢӨ.
- 63. Job System : Define Job JobмқҖ кө¬мЎ°мІҙлЎң IJobмқ„ мғҒмҶҚ л°ӣм•„ м •мқҳн•ңлӢӨ.
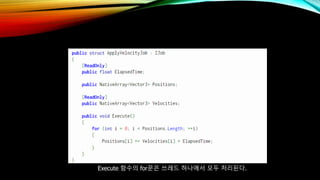
- 64. Execute н•ЁмҲҳмқҳ forл¬ёмқҖ м“°л Ҳл“ң н•ҳлӮҳм—җм„ң лӘЁл‘җ мІҳлҰ¬лҗңлӢӨ.
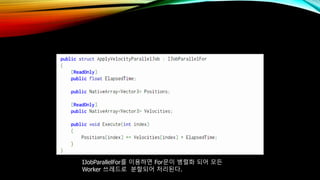
- 65. IJobParallelForлҘј мқҙмҡ©н•ҳл©ҙ Forл¬ёмқҙ лі‘л ¬нҷ” лҗҳм–ҙ лӘЁл“ Worker м“°л Ҳл“ңлЎң л¶„н• лҗҳм–ҙ мІҳлҰ¬лҗңлӢӨ.
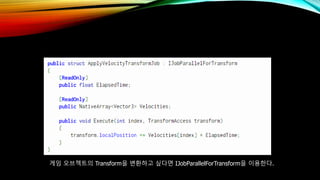
- 66. кІҢмһ„ мҳӨлёҢм қнҠёмқҳ Transformмқ„ ліҖнҷҳн•ҳкі мӢ¶лӢӨл©ҙ IJobParallelForTransformмқ„ мқҙмҡ©н•ңлӢӨ.
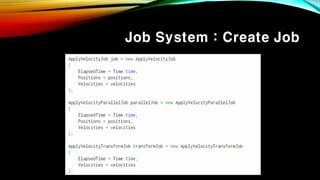
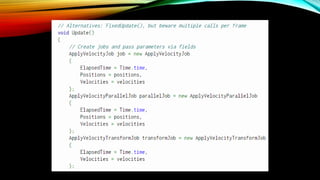
- 67. Job System : Create Job
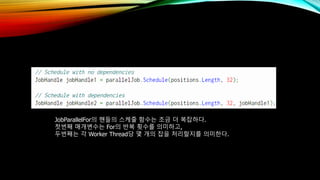
- 68. Start Job Jobмқҳ мӢӨн–үмқ„ мҳҲм•Ҫн•ҳл Өл©ҙ мң„мҷҖ к°ҷмқҙ м„ м–ён•ҳл©ҙ лҗңлӢӨ. мҠӨмјҖмӨ„ н•ЁмҲҳмқҳ л§Өк°ңліҖмҲҳлЎң мһЎн•ёл“Өмқ„ л„Јмңјл©ҙ к·ё н•ёл“Өмқҳ мһЎмқҙ мІҳлҰ¬лҗң нӣ„ мӢңмһ‘н•ҳлҸ„лЎқ мҳҲм•Ҫн•ңлӢӨ. - мҠӨмјҖмӨ„ мў…мҶҚм„ұ(Schedule dependency) -
- 69. JobParallelForмқҳ н•ёл“Өмқҳ мҠӨмјҖмӨ„ н•ЁмҲҳлҠ” мЎ°кёҲ лҚ” ліөмһЎн•ҳлӢӨ. мІ«лІҲм§ё л§Өк°ңліҖмҲҳлҠ” Forмқҳ л°ҳліө нҡҹмҲҳлҘј мқҳлҜён•ҳкі , л‘җлІҲм§ёлҠ” к°Ғ Worker ThreadлӢ№ лӘҮ к°ңмқҳ мһЎмқ„ мІҳлҰ¬н• м§ҖлҘј мқҳлҜён•ңлӢӨ.
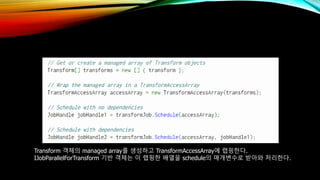
- 70. Transform к°қмІҙмқҳ managed arrayлҘј мғқм„ұн•ҳкі TransformAccessArrayм—җ лһ©н•‘н•ңлӢӨ. IJobParallelForTransform кё°л°ҳ к°қмІҙлҠ” мқҙ лһ©н•‘н•ң л°°м—ҙмқ„ scheduleмқҳ л§Өк°ңліҖмҲҳлЎң л°ӣм•„мҷҖ мІҳлҰ¬н•ңлӢӨ.
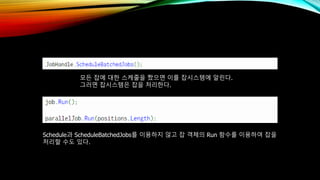
- 71. лӘЁл“ мһЎм—җ лҢҖн•ң мҠӨмјҖмӨ„мқ„ м§°мңјл©ҙ мқҙлҘј мһЎмӢңмҠӨн…ңм—җ м•ҢлҰ°лӢӨ. к·ёлҹ¬л©ҙ мһЎмӢңмҠӨн…ңмқҖ мһЎмқ„ мІҳлҰ¬н•ңлӢӨ. Scheduleкіј ScheduleBatchedJobsлҘј мқҙмҡ©н•ҳм§Җ м•Ҡкі мһЎ к°қмІҙмқҳ Run н•ЁмҲҳлҘј мқҙмҡ©н•ҳм—¬ мһЎмқ„ мІҳлҰ¬н• мҲҳлҸ„ мһҲлӢӨ.
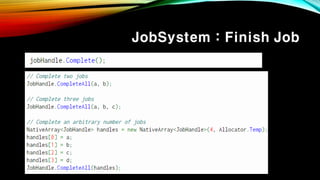
- 72. JobSystem : Finish Job
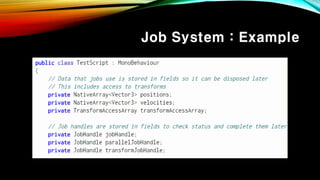
- 73. Job System : Example