Ž©ÄŪčįžä§Ž†ąŽďú Ž†ĆŽćĒŽßĀ (Multithreaded rendering)
3 likes2,141 views

Multithreaded RenderingÍ≥ľ Dynamic Instancingžóź ŽĆÄŪēīžĄú Žč§Ž£ĻŽčąŽč§.















































![[Ndc11 ŽįēŽĮľÍ∑ľ] deferred shading](https://cdn.slidesharecdn.com/ss_thumbnails/ndc11deferredshading-110602220043-phpapp01-thumbnail.jpg?width=560&fit=bounds)

![[NDC 2010] Í∑łŽüīŽďĮŪēú ŽěúŽć§ žÉĚžĄĪ žĽ®ŪÖźžł† ŽßĆŽď§Íłį](https://cdn.slidesharecdn.com/ss_thumbnails/hsf4fdvtjgcprbeczm9r-signature-8b01151cfddd883a338efa8a6603d585034336564338d911ab6e95aca4592fa0-poli-150122014503-conversion-gate02-thumbnail.jpg?width=560&fit=bounds)


![[IGC 2017] Ū饞ĖīŽĻĄžä§ ŽĮľÍ≤Ş̳ - MmorpgŽ•ľ žúĄŪēú voxel ÍłįŽįė ŽĄ§ŽĻĄÍ≤ĆžĚīžÖė ŽĚľžĚīŽłĆŽü¨Ž¶¨ ÍįúŽįúÍłį](https://cdn.slidesharecdn.com/ss_thumbnails/mmorpgvoxel-170905061528-thumbnail.jpg?width=560&fit=bounds)






![[KGC2014] DX9žóźžĄúDX11Ž°úžĚėžĚīŪĖČÍ≤ĹŪóėÍ≥Ķžú†](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2014dx9dx11-141108081701-conversion-gate01-thumbnail.jpg?width=560&fit=bounds)






![[NDC 2009] ŪĖČŽŹô Ū䳎¶¨Ž°ú ÍĶ¨ŪėĄŪēėŽäĒ žĚłÍ≥ĶžßÄŽä•](https://cdn.slidesharecdn.com/ss_thumbnails/sozq6jekqxsztuufax7q-signature-36c67eff9cc876072bc7cbb8cc904a6ded5de90832dee56b9f72b022c381012d-poli-150121233510-conversion-gate02-thumbnail.jpg?width=560&fit=bounds)





![[ŽįēŽĮľÍ∑ľ] 3 dŽ†ĆŽćĒŽßĀ žėĶŪčįŽßąžĚīžßē_2](https://cdn.slidesharecdn.com/ss_thumbnails/3d2-111117021812-phpapp01-thumbnail.jpg?width=560&fit=bounds)

More Related Content
What's hot (20)
Similar to Ž©ÄŪčįžä§Ž†ąŽďú Ž†ĆŽćĒŽßĀ (Multithreaded rendering) (20)




![[ž°įžßĄŪėĄ] [Kgc2011]direct x11 žĚīžēľÍłį](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2011directx11-111111212853-phpapp02-thumbnail.jpg?width=560&fit=bounds)




![[0602 ŽįēŽĮľÍ∑ľ] direct2 d](https://cdn.slidesharecdn.com/ss_thumbnails/0602direct2d-111117021734-phpapp01-thumbnail.jpg?width=560&fit=bounds)


![[NDC 2018] ŪÖĆŽĚľ žĹėžÜĒ ŪŹ¨ŪĆÖÍłį - ŪėĄžĄłŽĆÄ žĹėžÜĒ žĚīžč̞̥ žúĄŪēú Ž†ĆŽćĒŽßĀ žĶúž†ĀŪôĒ žó¨ž†ē](https://cdn.slidesharecdn.com/ss_thumbnails/ndcmultithreaded-renderingsanghyeokhong-180706143213-thumbnail.jpg?width=560&fit=bounds)

![[0602 ŽįēŽĮľÍ∑ľ] Direct2D](https://cdn.slidesharecdn.com/ss_thumbnails/0602direct2d-110602111737-phpapp01-thumbnail.jpg?width=560&fit=bounds)



More from Bongseok Cho (10)










Ž©ÄŪčįžä§Ž†ąŽďú Ž†ĆŽćĒŽßĀ (Multithreaded rendering)
- 2. Ž™©žį® ‚ÄĘ žčúžěĎŪēėŽ©į‚Ķ ‚ÄĘ Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? ‚ÄĘ Data Race ‚ÄĘ Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ ‚ÄĘ Code Reading ‚ÄĘ Rendering Command žÉĚžĄĪ ‚ÄĘ Direct3D11 Deferred Context ‚ÄĘ Code Reading ‚ÄĘ Dynamic Instancing ‚ÄĘ ŽŹôžĚľŪēú Ž¨ľž≤īžĚė ž†ēžĚė ‚ÄĘ DrawSnapshot ‚ÄĘ ŽćĒ žěźžĄłŪēú žĹĒŽďúŽ•ľ Ž≥īÍ≥† žč∂žúľžčúŽč§Ž©ī‚Ķ ‚ÄĘ žįłÍ≥†žěźŽ£Ć 2
- 3. žčúžěĎŪēėŽ©į‚Ķ žĚī pptŽäĒ Multithreaded RenderingÍ≥ľ Žć§žúľŽ°ú Dynamic Instancingžóź ŽĆÄŪēīžĄú Žč§Ž£ĻŽčąŽč§. žĚī ŪĒĄŽ°úž†ĚŪ䳎äĒ UE4žĚė žĹĒŽďúžôÄ Žč§žĚĆ ŽŹôžėĀžÉĀžóźžĄú žėĀÍįźžĚĄ ŽßéžĚī ŽįõžēėžúľŽ©į ŽŹôžėĀžÉĀžĚÄ ŪēúÍłÄ žěźŽßČŽŹĄ ž†úÍ≥ĶŪēėŽĮÄŽ°ú ŪēúŽ≤ą Ž≥īžčúŽäĒ ÍĪł ž∂Ēž≤úŪē©ŽčąŽč§. https://youtu.be/qx1c190aGhs 3
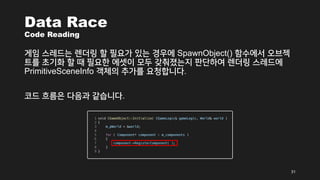
- 4. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? ŪėĄžčúŽĆĞ󟞥ú žĹĒžĖīÍįÄ ŪēėŽāėŽßĆ Žč¨Ž¶į CPUŽäĒ žįĺžēĄŽ≥īÍłį ŪěėŽď§Í≤Ć ŽźėžóąžäĶŽčąŽč§. CPUžĚė Žįúž†Ą Žį©ŪĖ•žĚī žĹĒžĖīžĚė ÍįúžąėŽ•ľ ŽäėŽ¶¨ŽäĒ Í≤ÉžúľŽ°ú ŽįĒŽÄź žĚīŪõĄŽ°ú Í≥†žĄĪŽä•žĚė ŪĒĄŽ°úÍ∑łŽě®žĚė Í≤Ĺžöį žä§Ž†ąŽďúŽ•ľ žā¨žö©ŪēėŽäĒ Í≤ÉžĚī ŪēĄžąėÍįÄ ŽźėžóąžäĶŽčąŽč§. žĚīŽäĒ Ž†ĆŽćĒŽßĀŽŹĄ žėąžôłÍįÄ žēĄŽčôŽčąŽč§. ‚ÄėÍ∑łŽüįŽćį Ž†ĆŽćĒŽßĀžĚÄ GPUžĚė žĄĪŽä•žóź žėĀŪĖ•žĚĄ ŽįõŽäĒ Í≤ÉžĚī žēĄŽčĆÍįÄ?‚Äô ŽĚľÍ≥† žÉĚÍįĀŪēėžč§ žąė žěąžĚĄ Í≤É ÍįôžĚÄŽćįžöĒ. žó¨ÍłįžĄúŽäĒ žä§Ž†ąŽďúŽ•ľ žā¨žö©ŪēėžßÄ žēäžĚÄ Í≤Ĺžöį žôú žā¨žö©Ž•†žĚī ŽĖ®žĖīžßÄŽäĒžßÄŽ•ľ žāīŪéīŽ≥īÍ≤†žäĶŽčą Žč§. 4
- 5. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? Direct3D11 žĚīž†ĄžĚė Í∑łŽěėŪĒĹ APIŽäĒ Žč®žĚľ žä§Ž†ąŽďúžóźžĄú žč§ŪĖČŽźėŽäĒ Í≤Éžóź ž§Ďž†źžĚĄ ŽĎźÍ≥† žĄ§Í≥ĄŽźėžóąžäĶŽčąŽč§. žēĒžčúž†ĀžĚł ŽŹôÍłįŪôĒ žßÄž†źžĚī ž°īžě¨ŪēīžĄú APIŽ•ľ Ūėłž∂úŪēėÍ≥† Žāú Žč§žĚĆ GPUžĚė ž≤ėŽ¶¨ÍįÄ žôĄŽ£Ć ŽźėžóąžĚĄ ŽēĆ žĚīŪõĄžĚė žĹĒŽďúÍįÄ žč§ŪĖČŽź©ŽčąŽč§. Žč§žĚĆžĚÄ Žč®žĚľ žä§Ž†ąŽďúžóźžĄú ŽŹôžěĎŪēėŽŹĄŽ°Ě žěĎžĄĪŽźú ŪĒĄŽ°úÍ∑łŽě®žĚė žč§ŪĖČ ŪĚźŽ¶ĄžĚĄ ÍįĄŽěĶŪēėÍ≤Ć ŽāėŪÉÄŽāł Í≤Éžě֎蹎č§. 5 ŪĒĄŽ°úÍ∑łŽě® žč§ŪĖČ ŪĚźŽ¶Ą N ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ N+1 ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N+1 ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ
- 6. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? Ž¨łž†úŽäĒ žĚīŽ†áÍ≤Ć žąúžĄúŽ•ľ Žßěž∂įžĄú žßĄŪĖČŪēėŽäĒ Žį©žčĚžĚī CPUžôÄ GPUŽ•ľ žĶúŽĆÄŽ°ú žā¨žö©ŪēėžßÄ Ž™ĽŪēúŽč§ŽäĒ ž†źžě֎蹎č§. CPU Í≥Ąžāį ž§Ďžóź GPUŽäĒ ž†úž∂úŽźú Ž™ÖŽ†ĻžĚī žóÜÍłį ŽēĆŽ¨łžóź žēĄŽ¨īŽüį žĚľŽŹĄ ŪēėžßÄ žēäÍ≥† CPU žĚė ž≤ėŽ¶¨Ž•ľ ÍłįŽč§Ž¶¨Í≤Ć ŽźėÍ≥† Ž†ĆŽćĒŽßĀ ž§ĎžóźŽäĒ ŽŹôÍłįŪôĒ žßÄž†źžúľŽ°ú žĚłŪēīžĄú CPUŽäĒ GPU žĚė ž≤ėŽ¶¨ÍįÄ ŽĀĚŽā† ŽēĆ ÍĻĆžßÄ ÍłįŽč§Ž¶¨Í≤Ć Žź©ŽčąŽč§. 6 ŪĒĄŽ°úÍ∑łŽě® žč§ŪĖČ ŪĚźŽ¶Ą N ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ N+1 ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N+1 ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ ŽĆÄÍłį ŽĆÄÍłį ŽĆÄÍłį
- 7. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? ŽĒįŽĚľžĄú žĚīŽ†áÍ≤Ć CPUžôÄ GPUÍįÄ ŽĻĄŪö®žú®ž†ĀžúľŽ°ú žā¨žö©ŽźėžßÄ žē䎏ĄŽ°Ě žä§Ž†ąŽďúŽ•ľ Ž∂ĄŽ¶¨Ūēė žó¨ Ž†ĆŽćĒŽßĀÍ≥ľ CPU Í≥ĄžāįžĚī ŽŹôžčúžóź žĚīŽ§ĄžßÄŽŹĄŽ°Ě Ūēīžēľ Ūē©ŽčąŽč§.(‚ÄĽ) Í∑łŽüįŽćį žĚīŽ†áÍ≤Ć žä§Ž†ąŽďú ŪēėŽāėŽ•ľ ž∂ĒÍįÄŪēėŽäĒ ž†ēŽŹĄŽ°úŽäĒ Ž©ÄŪčį žä§Ž†ąŽďúŽĚľÍ≥† Ž∂ÄŽ•īÍłįžóźŽäĒ Ž¨īŽ¶¨ÍįÄ žěąžĖī Ž≥īžĚīŽäĒŽćį žēĄžßĀ žó¨Žü¨ žä§Ž†ąŽďúŽ•ľ žā¨žö©Ūēėžó¨ žĄĪŽä•žĚĄ ÍįúžĄ†Ūē† žąė žěąŽäĒ Ž∂ÄŽ∂ĄžĚī žěąžäĶŽčąŽč§. 7 ŪĒĄŽ°úÍ∑łŽě® žč§ŪĖČ ŪĚźŽ¶Ą N ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N+1 ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N+1 ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ N ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ N+2 ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N+3 ŪĒĄŽ†ąžěĄ CPU Í≥Ąžāį N+2 ŪĒĄŽ†ąžěĄ Ž†ĆŽćĒŽßĀ ‚ÄĽ Ž¨ľŽ°† Direct3D12, VulkanÍ≥ľ ÍįôžĚÄ žĶúžč† Graphics APIžĚė Í≤ĹžöįžóźŽäĒ ŽĻĄŽŹôÍłįÍįÄ ÍłįŽ≥łžĚī ŽźėžóąÍłįžóź žÉĀŪô©žĚī Žč§Ž¶ÖŽčąŽč§.
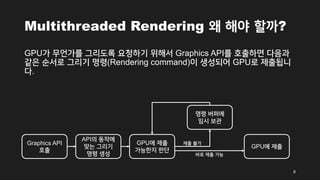
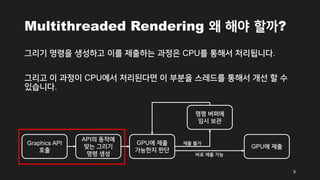
- 8. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? GPUÍįÄ Ž¨īžĖłÍįÄŽ•ľ Í∑łŽ¶¨ŽŹĄŽ°Ě žöĒž≤≠ŪēėÍłį žúĄŪēīžĄú Graphics APIŽ•ľ Ūėłž∂úŪēėŽ©ī Žč§žĚĆÍ≥ľ ÍįôžĚÄ žąúžĄúŽ°ú Í∑łŽ¶¨Íłį Ž™ÖŽ†Ļ(Rendering command)žĚī žÉĚžĄĪŽźėžĖī GPUŽ°ú ž†úž∂úŽź©Žčą Žč§. 8 Graphics API Ūėłž∂ú APIžĚė ŽŹôžěĎžóź ŽßěŽäĒ Í∑łŽ¶¨Íłį Ž™ÖŽ†Ļ žÉĚžĄĪ GPUžóź ž†úž∂ú GPUžóź ž†úž∂ú ÍįÄŽä•ŪēúžßÄ ŪĆźŽč® Ž™ÖŽ†Ļ Ž≤ĄŪćľžóź žěĄžčú Ž≥īÍīÄ ŽįĒŽ°ú ž†úž∂ú ÍįÄŽä• ž†úž∂ú Ž∂ąÍįÄ
- 9. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžĚĄ žÉĚžĄĪŪēėÍ≥† žĚīŽ•ľ ž†úž∂úŪēėŽäĒ Í≥ľž†ēžĚÄ CPUŽ•ľ ŪÜĶŪēīžĄú ž≤ėŽ¶¨Žź©ŽčąŽč§. Í∑łŽ¶¨Í≥† žĚī Í≥ľž†ēžĚī CPUžóźžĄú ž≤ėŽ¶¨ŽźúŽč§Ž©ī žĚī Ž∂ÄŽ∂ĄžĚĄ žä§Ž†ąŽďúŽ•ľ ŪÜĶŪēīžĄú ÍįúžĄ† Ūē† žąė žěąžäĶŽčąŽč§. 9 Graphics API Ūėłž∂ú APIžĚė ŽŹôžěĎžóź ŽßěŽäĒ Í∑łŽ¶¨Íłį Ž™ÖŽ†Ļ žÉĚžĄĪ GPUžóź ž†úž∂ú GPUžóź ž†úž∂ú ÍįÄŽä•ŪēúžßÄ ŪĆźŽč® Ž™ÖŽ†Ļ Ž≤ĄŪćľžóź žěĄžčú Ž≥īÍīÄ ŽįĒŽ°ú ž†úž∂ú ÍįÄŽä• ž†úž∂ú Ž∂ąÍįÄ
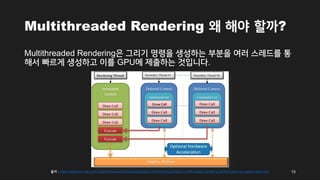
- 10. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? Multithreaded RenderingžĚÄ Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžĚĄ žÉĚžĄĪŪēėŽäĒ Ž∂ÄŽ∂ĄžĚĄ žó¨Žü¨ žä§Ž†ąŽďúŽ•ľ ŪÜĶ ŪēīžĄú ŽĻ†Ž•īÍ≤Ć žÉĚžĄĪŪēėÍ≥† žĚīŽ•ľ GPUžóź ž†úž∂úŪēėŽäĒ Í≤Éžě֎蹎č§. 10 ž∂úž≤ė : https://software.intel.com/content/www/us/en/develop/articles/understanding-directx-multithreaded-rendering-performance-by-experiments.html
- 11. Multithreaded Rendering žôú Ūēīžēľ Ūē†ÍĻĆ? ž†ēŽ¶¨ŪēėžěźŽ©ī Multithreaded RenderingžĚÄ CPUžôÄ GPUžĚė žā¨žö©Ž•†žĚĄ žĶúŽĆÄŽ°ú Ūēėžó¨ ŽÜížĚÄ žĄĪŽä•žĚĄ žĖĽžúľŽ†§ŽäĒ Žį©Ž≤ēžě֎蹎č§. ŪēėžßÄŽßĆ žä§Ž†ąŽďúŽ•ľ žā¨žö©ŪēúŽč§Ž©ī Í∑łžóź ŽĒįŽ•ł ŽĆÄÍįÄÍįÄ ŽĒįŽ¶ÖŽčąŽč§. žĚīž†ú Ž©ÄŪčį žä§Ž†ąŽďúžóźžĄú Ž†ĆŽćĒŽßĀžĚĄ ŪēėÍłį žúĄŪēī ž≤ėŽ¶¨Ūēīžēľ ŪēėŽäĒ žĚīžäąžóź ŽĆÄŪēīžĄú žēĆžēĄŽ≥ī ŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§. 11
- 12. Data Race ŽćįžĚīŪĄį Í≤ĹŪē©žĚÄ Ž©ÄŪčį žä§Ž†ąŽďú ŪĒĄŽ°úÍ∑łŽěėŽįćžóźžĄú ŪĒľŪē† žąė žóÜŽäĒ žĚīžäąžě֎蹎č§. Multithreaded Renderingžčú žä§Ž†ąŽďú ÍįĄžĚė Í≤ĹŪē©žóź ŽćĒŪēī GPUžôÄžĚė Í≤ĹŪē©ŽŹĄ ŽįúžÉĚŪē©ŽčąŽč§. ŽĒįŽĚľžĄú žĚīŽüį ŽćįžĚīŪĄį Í≤ĹŪē©žĚī ŽįúžÉĚŪēėžßÄ žē䎏ĄŽ°Ě ž†ĄŽěĶžĚĄ žĄłžõĆžēľ Ūē©ŽčąŽč§. žöįžĄ† Ž†ĆŽćĒŽßĀ žÉĀŪô©žóźžĄú žĚľžĖīŽā† žąė žěąŽäĒ ŽćįžĚīŪĄį Í≤ĹŪē©žĚė žėąžčúŽ•ľ Ž™áÍįÄžßÄ žÉĚÍįĀŪēīŽ≥īÍ≤† žäĶŽčąŽč§. 12
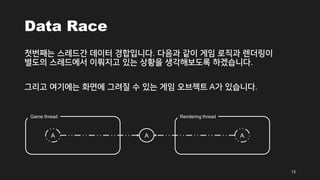
- 13. Data Race ž≤ęŽ≤ąžßłŽäĒ žä§Ž†ąŽďúÍįĄ ŽćįžĚīŪĄį Í≤ĹŪē©žě֎蹎č§. Žč§žĚĆÍ≥ľ ÍįôžĚī Í≤ĆžěĄ Ž°úžßĀÍ≥ľ Ž†ĆŽćĒŽßĀžĚī Ž≥ĄŽŹĄžĚė žä§Ž†ąŽďúžóźžĄú žĚīŽ§ĄžßÄÍ≥† žěąŽäĒ žÉĀŪô©žĚĄ žÉĚÍįĀŪēīŽ≥īŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§. Í∑łŽ¶¨Í≥† žó¨ÍłįžóźŽäĒ ŪôĒŽ©īžóź Í∑łŽ†§žßą žąė žěąŽäĒ Í≤ĆžěĄ žė§ŽłĆž†ĚŪäł AÍįÄ žěąžäĶŽčąŽč§. 13 Game thread Rendering thread A A A
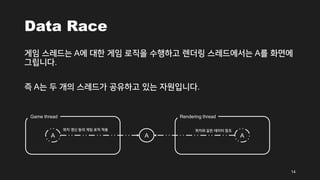
- 14. Data Race Í≤ĆžěĄ žä§Ž†ąŽďúŽäĒ Ažóź ŽĆÄŪēú Í≤ĆžěĄ Ž°úžßĀžĚĄ žąėŪĖČŪēėÍ≥† Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóźžĄúŽäĒ AŽ•ľ ŪôĒŽ©īžóź Í∑łŽ¶ĹŽčąŽč§. ž¶Č AŽäĒ ŽĎź ÍįúžĚė žä§Ž†ąŽďúÍįÄ Í≥Ķžú†ŪēėÍ≥† žěąŽäĒ žěźžõźžě֎蹎č§. 14 Game thread Rendering thread A A A žúĄžĻė ÍįĪžč† ŽďĪžĚė Í≤ĆžěĄ Ž°úžßĀ ž†Āžö© žúĄžĻėžôÄ ÍįôžĚÄ ŽćįžĚīŪĄį žįłž°į
- 15. Data Race ŽßĆžēĹ Í≤ĆžěĄ Ž°úžßĀžóź ŽĒįŽĚľžĄú AŽĚľŽäĒ žė§ŽłĆž†ĚŪäłÍįÄ žā≠ž†ú ŽźėŽäĒŽćį Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúÍįÄ AŽ•ľ žįłž°įŪēėÍ≥† žěąŽäĒ žÉĀŪô©žĚīŽĚľŽ©ī Í≤ĆžěĄ žä§Ž†ąŽďúÍįÄ AŽ•ľ ŽįĒŽ°ú žā≠ž†úŪēėŽäĒ Í≤ÉžĚÄ Ž¨łž†úÍįÄ Žź©ŽčąŽč§. ŽĒįŽĚľžĄú Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúÍįÄ AŽ•ľ žįłž°įŪēėžßÄ žēäžĚĄ ŽēĆ ÍĻĆžßÄ AžĚė žā≠ž†úŽäĒ žú†Ž≥īŽŹľžēľ Ūē©ŽčąŽč§. 15 Game thread Rendering thread A A A Ž™®žĘÖžĚė žĚīžú†Ž°ú AÍįÄ žā≠ž†ú žā≠ž†úŽźú ŽćįžĚīŪĄįžóź ž†ĎÍ∑ľŪē† ÍįÄŽä•žĄĪ
- 16. Data Race ŽĎźŽ≤ąžßłŽäĒ GPUžôÄžĚė Í≤ĹŪē©žě֎蹎č§. GPUžóźžĄú AŽ•ľ Í∑łŽ¶¨Íłį žúĄŪēú žÖįžĚīŽćĒ žĹĒŽďúÍįÄ žč§ŪĖČŽźėÍ≥† žěąŽäĒ Í≤ĹžöįŽ•ľ žÉĚÍįĀŪēīŽ≥īÍ≤†žäĶŽčąŽč§. GPUŽäĒ Í∑łŽěėŪĒĹ žĻīŽďú Ž©ĒŽ™®Ž¶¨Ž°ú ž†ĄžÜ°Žźú Ž¨ľž≤īžĚė žúĄžĻėŽāė žě¨žßąžĚĄ žįłž°įŪēėžó¨ Ž¨ľž≤īŽ•ľ žĖīŽĒĒžóź žĖīŽĖĽÍ≤Ć Í∑łŽ†§žēľ Ūē†žßÄŽ•ľ Í≤įž†ēŪē©ŽčąŽč§. 16 CPU GPU Ž¨ľž≤ī žúĄžĻė žĻīŽ©ĒŽĚľ žúĄžĻė žě¨žßą ETC A A
- 17. Data Race žĚīŽüį žÉĀŪô©žóźžĄú CPUÍįÄ AžĚė žÉĀŪÉúŽ•ľ žóÖŽćįžĚīŪäłŪēėÍ≥† žĚī Í≤įÍ≥ľŽ•ľ Í∑łŽěėŪĒĹ žĻīŽďúŽ°ú Ž©ĒŽ™® Ž¶¨Ž°ú ž†ĄžÜ°ŪēėŽ©ī AŽ•ľ Í∑łŽ¶¨Í≥† žěąŽäĒ ŽŹĄž§Ďžóź žįłž°įŪēėÍ≥† žěąŽćė ŽćįžĚīŪĄįžĚė ÍįížĚī Ž≥ÄÍ≤ĹŽź† žąė žěąžäĶŽčąŽč§. 17 CPU GPU Ž¨ľž≤ī žúĄžĻė žĻīŽ©ĒŽĚľ žúĄžĻė žě¨žßą ETC A A Ž¨ľŽ¶¨ ž†Āžö© ŽďĪžúľŽ°ú žúĄžĻėÍįÄ ÍįĪžč†ŽźėžĖī žĚīŽ•ľ ž†Āžö© GPUžóźžĄú žįłž°įŪēėÍ≥† žěąŽäĒ žúĄžĻė Íį펏Ą ÍįĪžč†ŽźėžĖī Ž≤ĄŽ¶ľ
- 18. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ žä§Ž†ąŽďú ÍįĄžĚė ŽćįžĚīŪĄį Í≤ĹŪē© Í∑łŽ¶¨Í≥† CPUžôÄ GPU ÍįĄžĚė ŽćįžĚīŪĄį Í≤ĹŪē©žĚĄ ŪēīÍ≤įŪēėÍłį žúĄŪēú ž†ĄŽěĶžĚÄ Í≤ƞ쥞Ěė žĄłžÉĀžĚĄ 2ÍįÄžßÄŽ°ú ŽāėŽąĄŽäĒ Í≤Éžě֎蹎č§. Í≤ƞ쥞Ěė žĄłžÉĀžĚĄ Í≤ĆžěĄ žä§Ž†ąŽďúŽ•ľ žúĄŪēú WorldžôÄ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúŽ•ľ žúĄŪēú ScenežúľŽ°ú ŽāėŽąēŽčąŽč§. 18 Game World Scene
- 19. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ ScenežĚÄ WorldžĚė Ž≥Ķž†ú Ž≥łžĚłŽćį Ž†ĆŽćĒŽßĀžóź ÍīÄŽ†®Žźú ŽćįžĚīŪĄįžóźŽßĆ Ž≥Ķžā¨Ūēī žė® Ž†ĆŽćĒŽßĀžĚĄ žúĄŪēú žĄłžÉĀžě֎蹎č§. Í∑łŽ¶¨Í≥† Í≤ĆžěĄ žä§Ž†ąŽďúŽäĒ WorldŽßƞ̥ žąėž†ēŪēėÍ≥† Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúŽäĒ SceneŽßƞ̥ žąėž†ē ŪēėŽŹĄŽ°Ě žóĄÍ≤©ŪēėÍ≤Ć ž†úŪēúŪē©ŽčąŽč§. 19 Game World Scene Ž≥Ķž†ú A B C A B C
- 20. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ žĚīŽäĒ ŪĒĄŽ°úÍ∑łŽěėŽ®łÍįÄ žč†Í≤Ş̥ žć®žēľ Ūē† Ž∂ÄŽ∂ĄžĚīÍłį ŽēĆŽ¨łžóź žč§žąėŽ•ľ ž§ĄžĚīÍłį žúĄŪēīžĄú Žč§žĚĆ Í≥ľ ÍįôžĚÄ ŽŹĄÍĶ¨ÍįÄ žā¨žö©Žź† žąė žěąžäĶŽčąŽč§. Žč§žĚĆžĚÄ ŪäĻž†ē žä§Ž†ąŽďúžóźžĄúŽßĆ žąėŪĖČŽźėžēľ ŪēėŽäĒ žĹĒŽďúÍįÄ ŪēīŽčĻ žä§Ž†ąŽďúžóźžĄú žč§ŪĖČŽźėŽäĒžßÄ Í≤Äžā¨Ūēėžó¨ žĚīŽüį ž†úžēŞ̥ ž§ÄžąėŪē† žąė žěąŽŹĄŽ°Ě ŪēėŽäĒ žėąžčúžě֎蹎č§. 20
- 21. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ Žč§žĚĆÍ≥ľ ÍįôžĚī Í≤ĆžěĄ žä§Ž†ąŽďúÍįÄ žõĒŽďúžĚė AŽ•ľ žā≠ž†úŪēīŽŹĄ ScenežóźŽäĒ žėĀŪĖ•žĚī žóÜÍłį ŽēĆŽ¨łžóź žā≠ž†úŽźú žė§ŽłĆž†ĚŪäłžóź ž†ĎÍ∑ľŪēīžĄú Ž¨łž†úÍįÄ ŽįúžÉĚŪēėŽäĒ Í≤ĹžöįŽ•ľ Žį©žßÄŪē† žąė žěąžäĶŽčą Žč§. Í∑łŽüľ ScenežĚė AŽäĒ žĖīŽĖĽÍ≤Ć žā≠ž†úŪēīžēľ Ūē†ÍĻĆžöĒ? 21 Game World Scene Ž≥Ķž†ú A B C A B C
- 22. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ AŽäĒ Í≤ĆžěĄ Ž°úžßĀžóź ŽĒįŽĚľžĄú žā≠ž†úŽźėžóąžäĶŽčąŽč§. WorldŽäĒ Í≤ĆžěĄ žä§Ž†ąŽďúžóźžĄú žąėž†ēŪē† žąė žěąžúľŽčą žā≠ž†úÍįÄ ÍįÄŽä•ŪĖąžßÄŽßĆ ScenežĚÄ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóź žĚėŪēīžĄúŽßĆ žąėž†ēŽźėžēľ ŪēėÍłį ŽēĆŽ¨łžóź Í≤ĆžěĄ Ž°úžßĀžóźžĄú žĚīŽ•ľ žā≠ž†úŪē† žąė žóÜžäĶŽčąŽč§. Í∑łŽü¨ŽĮÄŽ°ú žä§Ž†ąŽďú ž†ĎÍ∑ľ ž†úŪēúžĚĄ ž§ÄžąėŪēėÍłį žúĄŪēīžĄú Í≤ĆžěĄ žä§Ž†ąŽďúŽäĒ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúÍįÄ AŽ•ľ žā≠ž†úŪēėŽŹĄŽ°Ě žöĒž≤≠Ūēīžēľ Ūē©ŽčąŽč§. 22 Game World Scene Ž≥Ķž†ú A B C A B C
- 23. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ žä§Ž†ąŽďúžóź ŽĆÄŪēú žöĒž≤≠žĚÄ žä§Ž†ąŽďúžĚė ž†Ąžö© ŪĀźŽ•ľ ŪÜĶŪēīžĄú žĚīŽ§Ąžßώ蹎č§. AÍįÄ žā≠ž†ú Žź† Í≤Ĺžöį Í≤ĆžěĄ žä§Ž†ąŽďúŽäĒ Ažóź ŽĆÄŪēú žā≠ž†ú žöĒž≤≠žĚĄ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďú ŪĀźžóź žßĎžĖī ŽĄ£Í≥† Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúŽäĒ ž†Āž†ąŪēú ŽēĆžóź ŪĀźžĚė žöĒž≤≠žĚĄ ž≤ėŽ¶¨ŪēėÍ≤Ć Žź©ŽčąŽč§. 23 Game World Scene Ž≥Ķž†ú A B C A B C AŽ•ľ ž†úÍĪįŪē† Í≤É Rendering Thread ž†Ąžö© Queue
- 24. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ žč§ž†ú žĹĒŽďúŽ•ľ ŪÜĶŪēīžĄú Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóź žė§ŽłĆž†ĚŪäłžĚė žā≠ž†úŽ•ľ žöĒž≤≠ŪēėŽäĒ žėąžčúŽ•ľ Ž≥īÍ≤†žäĶŽčąŽč§. 24 Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóźžĄú RemovePrimitiveSceneInfo() Ūē®žąėŽ•ľ Ūėłž∂úŪēėŽŹĄŽ°Ě žöĒž≤≠
- 25. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ EnqueueRenderTask() Ūē®žąėŽäĒ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóź ŪÉúžä§ŪĀ¨Ž•ľ ž†úž∂úŪēėŽäĒ Ūē®žąėžĚīŽ©į Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóźžĄú Ūėłž∂úŪēú Í≤ĹžöįžóźŽäĒ ŪēīŽčĻ ŪÉúžä§ŪĀ¨Ž•ľ ŽįĒŽ°ú žč§ŪĖČŪē©ŽčąŽč§. 25 Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóźžĄú Ūėłž∂úŪēú Í≤Ĺžöį ŽįĒŽ°ú žč§ŪĖČ ž†Ąžö© žä§Ž†ąŽďú ŪĀźžóź ž†ĎÍ∑ľ
- 26. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ ž†Ąžö© ŪĀźŽäĒ ÍįĀ žä§Ž†ąŽďúŽčĻ ŪēėŽāėŽ°ú ž†úŪēúŪēėžėÄŽäĒŽćį žĚīŽäĒ Žč§Ž•ł žä§Ž†ąŽďúžĚė žöĒž≤≠žĚī žąúžĄúŽ•ľ žßÄžľú žč§ŪĖČŽŹľžēľ ŪēėÍłį ŽēĆŽ¨łžě֎蹎č§. ‚ÄėA Ž¨ľž≤īžĚė žúĄžĻė žóÖŽćįžĚīŪäł -> Í≤ĆžěĄ žě•Ž©ī Í∑łŽ¶¨Íłį -> A Ž¨ľž≤īžĚė žā≠ž†ú‚Äô žôÄ ÍįôžĚÄ žöĒž≤≠žĚī žąúžĄúÍįÄ Ž≥īžě•ŽźėžßÄ žēäžēĄ ‚ÄėA Ž¨ľž≤īžĚė žā≠ž†ú -> A Ž¨ľž≤īžĚė žúĄžĻė žóÖŽćįžĚīŪäł -> Í≤ĆžěĄ žě•Ž©ī Í∑łŽ¶¨Íłį‚Äô žôÄ ÍįôžĚÄ žąúžĄúŽ°ú žč§ŪĖČŽźėŽ©ī žĚėŽŹĄŪēėžßÄ žēäžĚÄ ŽŹôžěĎžĚīÍłį ŽēĆŽ¨łžě֎蹎č§. 26
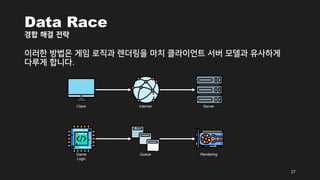
- 27. Data Race Í≤ĹŪē© ŪēīÍ≤į ž†ĄŽěĶ žĚīŽü¨Ūēú Žį©Ž≤ēžĚÄ Í≤ĆžěĄ Ž°úžßĀÍ≥ľ Ž†ĆŽćĒŽßĀžĚĄ ŽßąžĻė ŪĀīŽĚľžĚīžĖłŪäł žĄúŽ≤Ą Ž™®ŽćłÍ≥ľ žú†žā¨ŪēėÍ≤Ć Žč§Ž£®Í≤Ć Ūē©ŽčąŽč§. 27 Client Internet Server Game Logic Queue Rendering
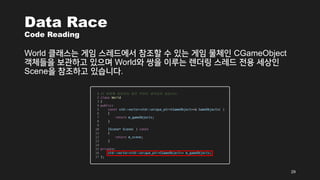
- 28. Data Race Code Reading žĚīž†ú Í≤ĆžěĄ Ž¨ľž≤īÍįÄ ž∂ĒÍįÄŽź† ŽēĆ žč§ŪĖČŽźėŽäĒ žĹĒŽďúŽ•ľ Ž≥īŽ©īžĄú žßÄÍłąÍĻĆžßÄ žĚīžēľÍłįŪēú Žāīžö©žĚĄ ž†ēŽ¶¨ŪēėŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§. žÉąŽ°ú žÉĚžĄĪŽźú Í≤ĆžěĄ Ž¨ľž≤īŽäĒ World ŪĀīŽěėžä§žĚė SpawnObject() Ūē®žąėŽ•ľ ŪÜĶŪēīžĄú Í≤ĆžěĄ žĄłžÉĀžóź ž∂ĒÍįÄŽź©ŽčąŽč§. 28
- 29. Data Race Code Reading World ŪĀīŽěėžä§ŽäĒ Í≤ĆžěĄ žä§Ž†ąŽďúžóźžĄú žįłž°įŪē† žąė žěąŽäĒ Í≤ĆžěĄ Ž¨ľž≤īžĚł CGameObject ÍįĚž≤īŽď§žĚĄ Ž≥īÍīÄŪēėÍ≥† žěąžúľŽ©į WorldžôÄ žĆćžĚĄ žĚīŽ£®ŽäĒ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďú ž†Ąžö© žĄłžÉĀžĚł ScenežĚĄ žįłž°įŪēėÍ≥† žěąžäĶŽčąŽč§. 29
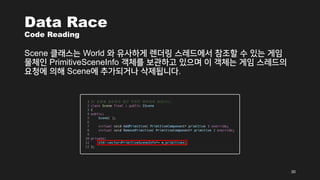
- 30. Data Race Code Reading Scene ŪĀīŽěėžä§ŽäĒ World žôÄ žú†žā¨ŪēėÍ≤Ć Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóźžĄú žįłž°įŪē† žąė žěąŽäĒ Í≤ĆžěĄ Ž¨ľž≤īžĚł PrimitiveSceneInfo ÍįĚž≤īŽ•ľ Ž≥īÍīÄŪēėÍ≥† žěąžúľŽ©į žĚī ÍįĚž≤īŽäĒ Í≤ĆžěĄ žä§Ž†ąŽďúžĚė žöĒž≤≠žóź žĚėŪēī Scenežóź ž∂ĒÍįÄŽźėÍĪįŽāė žā≠ž†úŽź©ŽčąŽč§. 30
- 31. Data Race Code Reading Í≤ĆžěĄ žä§Ž†ąŽďúŽäĒ Ž†ĆŽćĒŽßĀ Ūē† ŪēĄžöĒÍįÄ žěąŽäĒ Í≤Ĺžöįžóź SpawnObject() Ūē®žąėžóźžĄú žė§ŽłĆž†Ě Ū䳎•ľ žīąÍłįŪôĒ Ūē† ŽēĆ ŪēĄžöĒŪēú žóźžÖčžĚī Ž™®ŽĎź ÍįĖž∂įž°ĆŽäĒžßÄ ŪĆźŽč®Ūēėžó¨ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóź PrimitiveSceneInfo ÍįĚž≤īžĚė ž∂ĒÍįÄŽ•ľ žöĒž≤≠Ūē©ŽčąŽč§. žĹĒŽďú ŪĚźŽ¶ĄžĚÄ Žč§žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. 31
- 33. Rendering Command žÉĚžĄĪ Í∑łŽ¶¨Íłį žěĎžóÖžĚÄ ŽēĆŽēĆŽ°ú žąúžĄúÍįÄ ž§ĎžöĒŪēú Í≤ĹžöįÍįÄ žěąžäĶŽčąŽč§. žėąŽ•ľ Žď§Ž©ī ŽįėŪą¨Ž™Ö Ž¨ľž≤īžôÄ ÍįôžĚī žĻīŽ©ĒŽĚľžóź Ž®ľ žąúžĄúŽ∂ÄŪĄį Ž¨ľž≤īŽ•ľ Í∑łŽ†§žēľ ŪēėŽäĒ Í≤Ĺžöį (Z Sorting)Ž°ú žąúžĄúŽ•ľ Ž≥īžě•ŪēėÍłį žúĄŪēīžĄú žĖīŽĖĽÍ≤Ć Ž≥ĎŽ†¨ŪôĒŽ•ľ ŪēėŽäĒ Í≤ÉžĚī žĘčžĚĄžßÄ Í≥†Ž†§ Ūēīžēľ Ūē©ŽčąŽč§. 33 ž∂úž≤ė : http://www.opengl-tutorial.org/intermediate-tutorials/tutorial-10-transparency/ 50% Ūą¨Ž™ÖŽŹĄŽ•ľ ÍįĞߥ ŽĎź Ž¨ľž≤īŽ•ľ žĄúŽ°ú Žč§Ž•ł žąúžĄúŽ°ú Í∑łŽ†łžĚĄ ŽēĆ žĶúžĘÖ žÉČžÉĀžĚī Žč¨ŽĚľžßÄŽäĒ Í≤ɞ̥ ŪôēžĚłŪē† žąė žěąžĚĆ.
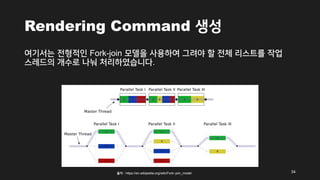
- 34. Rendering Command žÉĚžĄĪ žó¨ÍłįžĄúŽäĒ ž†ĄŪėēž†ĀžĚł Fork-join Ž™®ŽćłžĚĄ žā¨žö©Ūēėžó¨ Í∑łŽ†§žēľ Ūē† ž†Ąž≤ī Ž¶¨žä§Ū䳎•ľ žěĎžóÖ žä§Ž†ąŽďúžĚė ÍįúžąėŽ°ú ŽāėŽą† ž≤ėŽ¶¨ŪēėžėÄžäĶŽčąŽč§. 34 ž∂úž≤ė : https://en.wikipedia.org/wiki/Fork‚Äďjoin_model
- 35. Rendering Command žÉĚžĄĪ ÍĻäžĚī Ž†ĆŽćĒŽßĀžĚīŽāė Í∑łŽ¶ľžěź ŽßĶ Ž†ĆŽćĒŽßĀÍ≥ľ ÍįôžĚī Z Ž≤ĄŪ澎•ľ žā¨žö©Ūē† žąė žěąŽäĒ žÉĀŪô©žóźžĄúŽäĒ Í∑łŽ¶¨Íłį žąúžĄúÍįÄ Í∑łŽ¶¨ ž§ĎžöĒŪēėžßÄ žēäÍłį ŽēĆŽ¨łžóź Žč§Ž•ł Ž≥ĎŽ†¨ŪôĒ ž†ĄŽěĶžĚĄ ž∑®Ūē† žąė žěąžäĶŽčąŽč§. žėąŽ•ľ Žď§Ž©ī Joinžčú Ž™®Žď† ŪÉúžä§ŪĀ¨žĚė žôĄŽ£ĆŽ•ľ ÍłįŽč§Ž¶¨žßÄ žēäÍ≥† žôĄŽ£ĆŽźú ŪÉúžä§ŪĀ¨Ž∂ÄŪĄį GPU žóź Ž™ÖŽ†ĻžĚĄ ž†úž∂úŪē† žąėŽŹĄ žěąžäĶŽčąŽč§. ŪėĄžě¨ žĹĒŽďúŽäĒ Ž™®Žď† žä§Ž†ąŽďúŽ•ľ ÍłįŽč§Ž¶¨ŽŹĄŽ°Ě ÍĶ¨ŪėĄŽźėžĖī žěąžßÄŽßĆ Ž™®Žď† žÉĀŪô©žóź žēĆŽßěžĚÄ Žį©Ž≤ēžĚÄ žēĄŽčąŽĚľŽäĒ ž†źžĚĄ žĖłÍłČŪēėÍ≥† žč∂žäĶŽčąŽč§. 35
- 36. Rendering Command žÉĚžĄĪ Direct3D11 Deferred Context žč§ž†ú žĹĒŽďúŽ•ľ Ž≥īÍłį ž†Ąžóź Direct3D11žĚė Deferred Contextžóź ŽĆÄŪēú Ūēú ÍįÄžßÄ ŪäĻžĚīž†ź žĚĄ žĖłÍłČŪēėÍ≥†žěź Ūē©ŽčąŽč§. GPUžóź Ž™ÖŽ†ĻžĚĄ ž¶Čžčú ž†úž∂úŪēėŽäĒ Immediate ContextŽäĒ žĚľžĘÖžĚė žÉĀŪÉú Ž®łžč†Í≥ľ ÍįôžēĄ Ž†ĆŽćĒŽßĀ ŪĆĆžĚīŪĒĄŽĚľžĚłžĚė žÉĀŪÉúŽ•ľ ŽįĒÍ峎äĒ Ž™ÖŽ†Ļ( RSSetState, OMSetBlendState ŽďĪ ) žĚĄ ŪÜĶŪēī žÉĀŪÉúÍįÄ Ž≥ÄÍ≤ĹŽźėŽ©ī ŪēīŽčĻ žÉĀŪÉúÍįÄ Í≥ĄžÜć žú†žßÄŽźėžóąžäĶŽčąŽč§. žėąŽ•ľ Žď§žĖī ÍĻäžĚī ŪÖĆžä§Ū䳎•ľ ŽĀĄŽŹĄŽ°Ě ŪĖąŽč§Ž©ī Žč§žčú ÍĻäžĚī ŪÖĆžä§Ū䳎•ľ Ūā§ŽäĒ Ž™ÖŽ†ĻžĚĄ ž†úž∂úŪēė Íłį ž†ĄÍĻĆžßÄ ŪēīŽčĻ žÉĀŪÉúÍįÄ žú†žßÄŽźėžĖī Žč§žĚĆ Í∑łŽ¶¨ÍłįžóźŽŹĄ žėĀŪĖ•žĚĄ ŽĮłžĻ©ŽčąŽč§. 36
- 37. Rendering Command žÉĚžĄĪ Direct3D11 Deferred Context ŪēėžßÄŽßĆ Deferred ContextžĚė Í≤ĹžöįŽäĒ žÉĚžĄĪžčú Immediate ContextžĚė ŪĆĆžĚīŪĒĄŽĚľžĚł žÉĀŪÉúžôÄ žÉĀÍīÄ žóÜŽäĒ ÍłįŽ≥ł žÉĀŪÉúŽ°ú žÉĚžĄĪŽźėÍ≥† Immediate Contextžóź ž†úž∂úŪēīŽŹĄ ŪĆĆžĚīŪĒĄ ŽĚľžĚł žÉĀŪÉúŽ•ľ Ž≥ÄÍ≤ĹžčúŪā§žßÄ žēäžäĶŽčąŽč§. žě†žčú Žč§žĚĆ žßąŽ¨łžĚĄ žÉĚÍįĀŪēī Ž≥īžčúÍłį ŽįĒŽěćŽčąŽč§. Q. žĚīž†Ą Í∑łŽ¶¨ÍłįžóźžĄú Immediate ContextŽ•ľ ŪÜĶŪēī Ž∑įŪŹ¨Ū䳎•ľ žĄ§ž†ēŪēú Žč§žĚĆžóź Deferred ContextŽ•ľ ŪÜĶŪēī ÍłįŽ°ĚŽźú Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžĚĄ Immediate Contextžóź ž†úž∂úŪĖą žĚĄ ŽēĆ ŪēīŽčĻ Ž™ÖŽ†ĻŽď§žĚÄ Immediate Contextžóź žĄ§ž†ēŽźú Ž∑įŪŹ¨ŪäłžĚė žėĀŪĖ•žĚĄ ŽįõžĚĄÍĻĆžöĒ? 37
- 38. Rendering Command žÉĚžĄĪ Direct3D11 Deferred Context A. žėĀŪĖ•žĚĄ ŽįõžßÄ žēäžäĶŽčąŽč§. Í∑łŽ¶¨Í≥† Deferred Contextžóź Ž∑įŪŹ¨Ū䳎•ľ žĄ§ž†ēŪēėŽäĒ Ž™ÖŽ†Ļ žĚĄ ÍłįŽ°ĚŪēėžßÄ žēäžēėŽč§Ž©ī Deferred ContextŽäĒ ÍłįŽ≥ł žĄ§ž†ēžúľŽ°ú žÉĚžĄĪŽźėÍłį ŽēĆŽ¨łžóź ž†ēžÉĀž†ĀžúľŽ°ú Ž†ĆŽćĒŽßĀžĚī žĚīŽ§ĄžßÄžßÄ žēäžäĶŽčąŽč§. Í∑łŽüľ Žč§žĚĆÍ≥ľ ÍįôžĚÄ Í≤ĹžöįŽäĒ žĖīŽĖ®ÍĻĆžöĒ? Q. Deferred Context 2Íįú D1, D2žóź ÍįĀÍįĀ Ž™ÖŽ†ĻžĚĄ ÍłįŽ°ĚŪēėÍ≥† D1 -> D2žĚė žąúžĄúŽ°ú Immediate Contextžóź ž†úž∂úŪēėžėÄžäĶŽčąŽč§. D1žĚė ŪĆĆžĚīŪĒĄŽĚľžĚł žÉĀŪÉúŽäĒ D2žóź žėĀŪĖ•žĚĄ ŽĮłžĻ†ÍĻĆžöĒ? 38
- 39. Rendering Command žÉĚžĄĪ Direct3D11 Deferred Context A. žėĀŪĖ•žĚĄ ŽĮłžĻėžßÄ žēäžäĶŽčąŽč§. D2žóź ÍłįŽ°ĚŽźú Ž™ÖŽ†ĻŽď§žĚÄ D2žĚė žÉĀŪÉúžóźŽßĆ žėĀŪĖ•žĚĄ ŽįõžäĶ ŽčąŽč§. žĶúžĘÖž†ĀžúľŽ°ú ž†ēŽ¶¨ŪēīŽ≥īŽ©ī Deferred Contextžóź Ž™ÖŽ†ĻžĚĄ ÍłįŽ°ĚŪē† ŽēĆŽäĒ Viewport, Scissor rectangle, Render Target View žôÄ ÍįôžĚÄ žÉĀŪÉúŽ•ľ Žß§Ž≤ą žĄ§ž†ēŪēī ž§ėžēľ Ūē©ŽčąŽč§. Žč§žĚĆÍ≥ľ ÍįôžĚī žĚľŽ∂Ä žĄ§ž†ēžĚĄ ŽąĄŽĚĹŪēėŽ©ī‚Ķ 39
- 40. Rendering Command žÉĚžĄĪ Direct3D11 Deferred Context žĘĆžł° Í∑łŽ¶ľÍ≥ľ ÍįôžĚī ŽĻĄž†ēžÉĀž†ĀžĚł ŪôĒŽ©īžĚĄ žĖĽÍ≤Ć Žź©ŽčąŽč§. 40
- 41. Rendering Command žÉĚžĄĪ Code Reading žĚīž†ú ÍīÄŽ†® žĹĒŽďúŽ•ľ Ž≥īŽŹĄŽ°Ě ŪēėÍ≤†žäĶŽčąŽč§. Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžĚĄ Ž≥ĎŽ†¨Ž°ú ž†úž∂úŪēėŽäĒ ParallelCommitDrawSnapshot() Ūē®žąėžě֎蹎č§. 41
- 42. Rendering Command žÉĚžĄĪ Code Reading 42
- 43. Rendering Command žÉĚžĄĪ Code Reading žč§ž†úŽ°ú Ž™ÖŽ†ĻžĚĄ ÍłįŽ°ĚŪēėŽäĒ CommitDrawSnapshotTaskŽäĒ žĚīŽ†ážäĶŽčąŽč§. 43
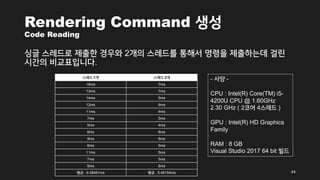
- 44. Rendering Command žÉĚžĄĪ Code Reading žčĪÍłÄ žä§Ž†ąŽďúŽ°ú ž†úž∂úŪēú Í≤ĹžöįžôÄ 2ÍįúžĚė žä§Ž†ąŽďúŽ•ľ ŪÜĶŪēīžĄú Ž™ÖŽ†ĻžĚĄ ž†úž∂úŪēėŽäĒŽćį ÍĪłŽ¶į žčúÍįĄžĚė ŽĻĄÍĶźŪĎúžě֎蹎č§. 44 žä§Ž†ąŽďú 1Íįú žä§Ž†ąŽďú 2Íįú 16ms 7ms 13ms 7ms 14ms 5ms 12ms 6ms 11ms 4ms 7ms 5ms 5ms 4ms 6ms 6ms 9ms 6ms 6ms 5ms 11ms 5ms 7ms 5ms 5ms 6ms ŪŹČÍ∑† : 9.38461ms ŪŹČÍ∑† : 5.46154ms - žā¨žĖĎ - CPU : Intel(R) Core(TM) i5- 4200U CPU @ 1.60GHz 2.30 GHz ( 2žĹĒžĖī 4žä§Ž†ąŽďú ) GPU : Intel(R) HD Graphics Family RAM : 8 GB Visual Studio 2017 64 bit ŽĻĆŽďú
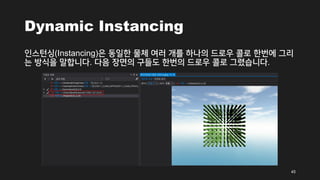
- 45. Dynamic Instancing žĚłžä§ŪĄīžčĪ(Instancing)žĚÄ ŽŹôžĚľŪēú Ž¨ľž≤ī žó¨Žü¨ ÍįúŽ•ľ ŪēėŽāėžĚė ŽďúŽ°úžöį žĹúŽ°ú ŪēúŽ≤ąžóź Í∑łŽ¶¨ ŽäĒ Žį©žč̞̥ ŽßźŪē©ŽčąŽč§. Žč§žĚĆ žě•Ž©īžĚė ÍĶ¨Žď§ŽŹĄ ŪēúŽ≤ąžĚė ŽďúŽ°úžöį žĹúŽ°ú Í∑łŽ†łžäĶŽčąŽč§. 45
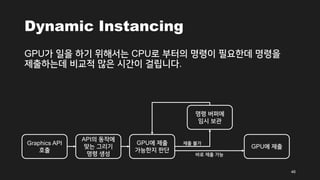
- 46. Dynamic Instancing GPUÍįÄ žĚľžĚĄ ŪēėÍłį žúĄŪēīžĄúŽäĒ CPUŽ°ú Ž∂ÄŪĄįžĚė Ž™ÖŽ†ĻžĚī ŪēĄžöĒŪēúŽćį Ž™ÖŽ†ĻžĚĄ ž†úž∂úŪēėŽäĒŽćį ŽĻĄÍĶźž†Ā ŽßéžĚÄ žčúÍįĄžĚī ÍĪłŽ¶ĹŽčąŽč§. 46 Graphics API Ūėłž∂ú APIžĚė ŽŹôžěĎžóź ŽßěŽäĒ Í∑łŽ¶¨Íłį Ž™ÖŽ†Ļ žÉĚžĄĪ GPUžóź ž†úž∂ú GPUžóź ž†úž∂ú ÍįÄŽä•ŪēúžßÄ ŪĆźŽč® Ž™ÖŽ†Ļ Ž≤ĄŪćľžóź žěĄžčú Ž≥īÍīÄ ŽįĒŽ°ú ž†úž∂ú ÍįÄŽä• ž†úž∂ú Ž∂ąÍįÄ
- 47. Dynamic Instancing žó¨Žü¨ Ž¨ľž≤īŽ•ľ Í∑łŽ¶¨ŽäĒ žÉĀŪô©žĚĄ ÍįĄŽč®ŪēėÍ≤Ć ŪĎúŪėĄŪēīŽ≥īŽ©ī Žč§žĚĆÍ≥ľ ÍįôžĚī žė§Ž≤Ą Ūó§Žďú ÍįÄ Žß§ ŽďúŽ°úžöį žĹúŽßąŽč§ ŽįúžÉĚŪē©ŽčąŽč§. žĚłžä§ŪĄīžčĪžĚÄ ŽŹôžĚľŪēú Ž¨ľž≤īŽď§žĚĄ ŪēúŽ≤ąžóź Í∑łŽ†§ ŽďúŽ°úžöį žĹú ŽßąŽč§ ŽįúžÉĚŪēėŽäĒ žė§Ž≤Ą Ūó§ŽďúŽ•ľ ž§ĄžĚīÍ≤Ć Žź©ŽčąŽč§. 47 overhead dp call
- 48. Dynamic Instancing Žč§žĚīŽāėŽĮĻ žĚłžä§ŪĄīžčĪžĚÄ žě•Ž©īžóź ž∂ĒÍįÄŽźú Ž¨ľž≤īŽ•ľ žěźŽŹôžúľŽ°ú Ž∂ĄŽ•ėŪēīžĄú ŽŹôžĚľŪēú Ž¨ľž≤īÍįÄ žó¨Žü¨ Íįú žěąŽäĒ Í≤Ĺžöį žěźŽŹôžúľŽ°ú žĚłžä§ŪĄīžčĪžĚĄ ŪÜĶŪēī Ž¨ľž≤īŽ•ľ Í∑łŽ¶¨ŽäĒ Žį© žčĚžúľŽ°ú ‚ÄėžčúžěĎŪēėŽ©į‚Ķ‚Äô žĪēŪĄįžóźžĄú žÜĆÍįúŪēú ‚ÄėRefactoring the Mesh Drawing Pipeline for Unreal Engine 4.22‚Äô ŽŹôžėĀžÉĀžóźžĄú žÜĆÍįúŽźú žö©žĖīžě֎蹎č§. Auto InstancingžĚīŽĚľÍ≥†ŽŹĄ ŪēėŽäĒ Í≤É ÍįôžäĶŽčąŽč§. žĚīž†úŽ∂ÄŪĄįŽäĒ žĚłžä§ŪĄīžčĪžĚĄ žěźŽŹôžúľŽ°ú žßÄžõźŪēėŽäĒ ŪôėÍ≤Ş̥ žúĄŪēīžĄú žĖīŽĖ§ žěĎžóÖžĚī ŪēĄžöĒŪĖąŽäĒžßÄ žāīŪéīŽ≥īÍ≤†žäĶŽčąŽč§. 48
- 49. Dynamic Instancing ŽŹôžĚľŪēú Ž¨ľž≤īžĚė ž†ēžĚė žöįžĄ† žĖīŽĒĒ ÍĻĆžßÄŽ•ľ ŽŹôžĚľŪēú Ž¨ľž≤īŽ°ú ž∑®ÍłČŪē† Í≤ɞ̳žßÄžóź ŽĆÄŪēú ž†ēžĚėÍįÄ ŪēĄžöĒŪē©Žčą Žč§. žēĄŽěė žä§ŪĀ¨Ž¶į žÉ∑ ž≤ėŽüľ ÍįôžĚÄ Ž™®žĖĎžĚė ÍĶ¨Žď§ŽŹĄ žĄúŽ°ú Žč§Ž•ł žúĄžĻėžóź Í∑łŽ†§žēľ ŪēėÍłį ŽēĆŽ¨łžóź ŪēúŽ≤ąžóź Í∑łŽ†§žßÄŽäĒ Ž¨ľž≤īžóźŽŹĄ žĄúŽ°ú Žč§Ž•ł Ž∂ÄŽ∂ĄžĚī ž°īžě¨Ūē©ŽčąŽč§. 49
- 50. Dynamic Instancing ŽŹôžĚľŪēú Ž¨ľž≤īžĚė ž†ēžĚė Ž¨ľž≤īžóź ŽĒįŽĚľžĄú Žč§Ž•ľ žąė žěąŽäĒ Ž∂ÄŽ∂ĄžĚÄ ŽĆÄŪĎúž†ĀžúľŽ°ú Ž¨ľž≤īžĚė žúĄžĻėÍįÄ žěąžĚĄ žąė žěąÍ≥† Ž≥ł žē†ŽčąŽ©ĒžĚīžÖėžĚī ŪēĄžöĒŪēú Ž©ĒžčúŽĚľŽ©ī Ž≥łžĚė ŪĖČŽ†¨ Íįí ŽďĪžĚī žěąÍ≤†žäĶŽčąŽč§. žĚīžôÄ ÍįôžĚī ŽŹôžĚľŪēú Ž¨ľž≤ī ÍįĄžóź žĖīŽĖ§ ÍįížĚī žĄúŽ°ú Žč§Ž•ľ žąė žěąŽäĒžßÄŽäĒ Í≤Ĺžöįžóź ŽĒįŽĚľ Žč§Ž•īÍ≤Ć Í∑úž†ēŪē† žąė žěąžäĶŽčąŽč§. ŪėĄžě¨ ŪĒĄŽ°úÍ∑łŽě®žóźŽäĒ Í≥†ž†ēŽźú Ž™®žĖĎžĚė žä§ŪÉúŪčĪ Ž©ĒžčúŽßĆ ž°īžě¨ŪēėŽäĒŽćį žúĄžĻė, ŪĀ¨Íłį, ŪöĆž†Ą Ž≥ÄŪôėžĚĄ ž†úžôłŪēėÍ≥† Ž™®Žď† ÍįížĚī ( žě¨žßą, Ž©Ēžčú Ž™®žĖĎ ŽďĪ ) ÍįôžēĄžēľ ŽŹôžĚľŪēú Ž¨ľž≤īŽ°ú ž∑®ÍłČŪēėÍ≥† žěąžäĶŽčąŽč§. 50
- 51. Dynamic Instancing ŽŹôžĚľŪēú Ž¨ľž≤īžĚė ž†ēžĚė Ž¨ľž≤īÍįĄ žĄúŽ°ú Žč§Ž•ł ž†ēŽ≥īŽäĒ žĚłžä§ŪĄīžčĪ ž§Ďžóź žįłž°įŪē† žąė žěąŽŹĄŽ°Ě ŽĮłŽ¶¨ Í∑łŽěėŪĒĹ Ž©ĒŽ™®Ž¶¨žóź ž†ĄžÜ°Ūēīžēľ Ūē©ŽčąŽč§. žĚī ž†ēŽ≥īŽäĒ Ž†ĆŽćĒŽßĀ žä§Ž†ąŽďúžóźžĄú Scenežóź Ž¨ľž≤īŽ•ľ ž∂ĒÍįÄŪē† ŽēĆŽāė ÍīÄŽ†® ŽćįžĚīŪĄį Ž≥ÄÍ≤Ĺ žčú Í∑łŽěėŪĒĹ Ž©ĒŽ™®Ž¶¨Ž°ú žóÖŽ°úŽďúŪēėÍ≥† žÖįžĚīŽćĒ žĹĒŽďúžóźžĄúŽäĒ žĚłŪíč žĖīžÖąŽłĒŽü¨ Ž•ľ ŪÜĶŪēī žĚłžä§ŪĄīžä§ ŽćįžĚīŪĄįŽ°ú ž†ĄŽč¨Žźú žĚłŽćĪžä§ ÍįížĚĄ ŪÜĶŪēīžĄú ž†ĎÍ∑ľŪēėŽŹĄŽ°Ě Ūē©Žčą Žč§. 51
- 52. Dynamic Instancing ŽŹôžĚľŪēú Ž¨ľž≤īžĚė ž†ēžĚė 52
- 53. Dynamic Instancing DrawSnapshot ŽŹôžĚľŪēú Ž¨ľž≤īžĚė Íłįž§ÄžĚĄ ž†ēŪĖąŽč§Ž©ī žĚīž†ú Ž¨ľž≤īŽ•ľ Ž∂ĄŽ•ėŪēėÍłį žúĄŪēú Ž™®Žď† ž†ēŽ≥īŽ•ľ Ž™®žēĄžēľ Ūē©ŽčąŽč§. DrawSnapshotžĚÄ Ž∂ĄŽ•ėŽ•ľ žúĄŪēú ŪĀīŽěėžä§Ž°ú žĖīŽĖ§ Ž¨ľž≤īŽ•ľ Í∑łŽ¶ī ŽēĆžĚė ŪĆĆžĚīŪĒĄ ŽĚľžĚł žÉĀŪÉúžóź ŽĆÄŪēú žä§ŽÉÖžÉ∑žě֎蹎č§. 53 Ž©ĒŽ™®Ž¶¨ Ž¶¨žÜĆžä§ (Ž≤ĄŪćľ, ŪÖćžä§ž≥ź ŽďĪ‚Ķ) Input Assembler Vertex Shader Hull Shader Domain Shader Geometry Shader Pixel Shader Tessellation Output Merger Rasterizer Í∑łŽ¶¨Íłįžóź ŪēĄžöĒŪēú ŪĆĆžĚīŪĒĄŽĚľžĚł žÉĀŪÉú
- 54. Dynamic Instancing DrawSnapshot žĹĒŽďúžóźžĄúŽäĒ Žč§žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. DrawSnapshotŽßĆ žěąžúľŽ©ī žĚīŽ•ľ ŪÜĶŪēīžĄú žĖłž†úŽď† Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžúľŽ°ú Ž≥ÄŪôėŪē† žąė žěąžäĶŽčąŽč§. 54
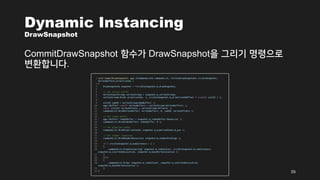
- 55. Dynamic Instancing DrawSnapshot CommitDrawSnapshot Ūē®žąėÍįÄ DrawSnapshotžĚĄ Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžúľŽ°ú Ž≥ÄŪôėŪē©ŽčąŽč§. 55
- 56. Dynamic Instancing DrawSnapshot žĚīž†ú ŽŹôžĚľ Ž¨ľž≤īŽĀľŽ¶¨ Ž∂ĄŽ•ėŪēėŽäĒ žěĎžóÖŽßĆžĚī Žā®žēėžäĶŽčąŽč§. žĚīÍ≤ÉžĚÄ DrawSnapshotžĚĄ ž†ēŽ†¨ŪēėŽäĒ Í≤ÉžúľŽ°ú ÍįĄŽč®ŪēėÍ≤Ć ŪēīÍ≤įŪē† žąė žěąžäĶŽčąŽč§. Žč§ŽßĆ DrawSnapshotžĚÄ Ž™®Žď† ž†ēŽ≥īŽ•ľ ŽčīÍ≥† žěąÍłį ŽēĆŽ¨łžóź ŪĀīŽěėžä§žĚė ŪĀ¨ÍłįÍįÄ Žß§žöį ŪĀŎ蹎č§. 64bitžóźžĄúŽäĒ ÍłįŽ≥ł ŪĀ¨ÍłįŽßĆ 520Bytežóź Žč¨Ūē©ŽčąŽč§. Í∑łŽ¶¨Í≥† žÖįžĚīŽćĒžóź žĄ§ž†ēŽź† Ž™®Žď† Ž¶¨žÜƞ䧞Ěė žįłž°įŽäĒ žÖįžĚīŽćĒžóź ŽĒįŽĚľ ÍįÄŽ≥Äž†ĀžĚľ žąė žěąÍłį ŽēĆŽ¨łžóź ŽćĒ ŽäėžĖī Žā† žąė žěąžäĶŽčąŽč§. ŽĒįŽĚľžĄú DrawSnapshot žěźž≤īŽ•ľ ž†ēŽ†¨ ž§Ďžóź ŽĻĄÍĶźŪēėŽäĒ Í≤ÉžĚÄ žĘčžßÄ žēäžäĶŽčąŽč§. 56
- 57. Dynamic Instancing DrawSnapshot žĚīŽ•ľ ŪēīÍ≤įŪēėÍłį žúĄŪēīžĄú DrawSnapshotžóź žēĄžĚīŽĒĒŽ•ľ Ž∂Äžó¨ŪēėžėÄžäĶŽčąŽč§. žēĄžĚīŽĒĒŽäĒ Žč§žĚĆÍ≥ľ ÍįôžĚÄ Ūēīžčú žěźŽ£ĆÍĶ¨ž°įŽ•ľ ŪÜĶŪēīžĄú Ž∂Äžó¨Ūē©ŽčąŽč§. 57
- 58. Dynamic Instancing DrawSnapshot žč§ž†ú DrawSnapshot ž†ēŽ†¨žĹĒŽďúŽäĒ Žč§žĚĆÍ≥ľ ÍįôžäĶŽčąŽč§. DrawSnapshotžĚĄ ž†ēŽ†¨ŪēėÍ≥† ŽāėŽ©ī žĚīž†ú ŽŹôžĚľŪēú žĘÖŽ•ėŽĀľŽ¶¨ Ž≥ĎŪē©Ūē©ŽčąŽč§. žĚīŽäĒ ŽĻĄÍĶź ŪõĄ žĚłžä§ŪĄīžä§ ÍįúžąėŽ•ľ ŽäėŽ¶¨ÍłįŽßĆ ŪēėŽ©ī Žź©ŽčąŽč§. 58
- 59. Dynamic Instancing DrawSnapshot žĚłžä§ŪĄīžčĪžúľŽ°ú Í∑łŽ¶ī ŽēĆŽäĒ ŪēīŽčĻ žĚłžä§ŪĄīžä§ ÍįúžąėŽßĆŪĀľ ŽįįžóīžĚĄ žĚīŽŹôŪēėŽ©īžĄú Í∑łŽ¶¨Íłį Ž™ÖŽ†ĻžúľŽ°ú Ž≥ÄŪôėŪēėŽ©ī Žź©ŽčąŽč§. 59
- 60. ŽćĒ žěźžĄłŪēú žĹĒŽďúŽ•ľ Ž≥īÍ≥† žč∂žúľžčúŽč§Ž©ī... ‚ÄĘ https://github.com/xtozero/SSR/tree/multi-thread 60