°Ъ¶ЩіўВЦХi»бұХ1ҙОҪьЛЖПөІСҙЎІСіўӨИӨҪӨОАнВЫөДұіҫ°
3 likes2,587 views

2019/04/12 Deep Learning JP: http://deeplearning.jp/seminar-2/


















![ҘбҘҝ№ҙЕдӨОПтӨӯ
? gi_barӨОЖҪҫщ
ЁC Ўә? AvgGradЎ»·ҪПтӨПjoint trainingӨЛПаөұӨ·ӨЖӨӨӨл
? ЎёҰХ1ӨтӨЙӨГӨБӨЛёьРВӨ№ӨмӨРlossӨ¬РЎӨөӨҜӨКӨГӨҝӨОӨ«Ў№
? ӨҪӨмӨ¬ҘБҘе©`ҘЛҘуҘ°Ө·ӨдӨ№ӨӨӨ«ӨПҝј‘]ӨөӨмӨЖӨКӨӨ
20](https://image.slidesharecdn.com/20190412kondo-190412002418/85/DL-1-MAML-20-320.jpg)







°Ъ¶ЩіўВЦХi»бұХ1ҙОҪьЛЖПөІСҙЎІСіўӨИӨҪӨОАнВЫөДұіҫ°
- 2. ұіҫ° 2 ? ҘбҘҝС§Б•ӨОБчРР ЁC С}КэӨОЛЖӨҝҶ–о}ӨЛҢқӨ·ӨЖҡшУГөДӨКДЬБҰӨтөГӨЖӨЫӨ·ӨӨ ЁC ӨЗӨвЎўббӨЗМШ¶ЁӨОҘҝҘ№ҘҜӨЛӨПМШ»ҜӨЗӨӯӨЖӨЫӨ·ӨӨ ? MAMLӨОБчРР(?) ЁC ҘбҘҝС§Б•ӨИӨӨӨЁӨРӨЮӨәӨПMAML ? ҘҝҘ№ҘҜЖХұйӨКЎўИ«ҘСҘйҘбҘҝӨОБјӨӨіхЖЪӮҺӨтЗуӨбӨл ЁC Ө№ӨҙӨҜЧФИ»ӨК°kПл ? MAMLӨПУӢЛгҘіҘ№ҘИӨ¬ёЯӨ№Ө®ӨлӨОӨЗ1ҙОҪьЛЖӨ№ӨлКЦ·ЁӨ¬іцӨЖӨӨӨл ЁC ЎоёоӨИҙуКВӨКУӢЛгӨт’ОӨЖӨЖӨКӨјӨҰӨЮӨҜӨӨӨҜӨОӨ« ЁC ЎоҘбҘҝөДӨЛТҠӨЖБјӨӨҘн©`Ҙ«ҘлӨОёьРВӨИӨПәОӨ« ЁC (ӮҖИЛөДҪвбӢ)»щұҫ1ҙОҪьЛЖПөӨтК№ӨГӨИӨӨӨҝ·ҪӨ¬БјӨөӨҪӨҰ
- 3. °kұнДЪИЭ 3 ? Х“ОД ЁC On First-Order Meta-Learning Algorithms(OpenAI, 2018) ? https://arxiv.org/abs/1803.02999 ЁC MAMLӨОТ»ҙОҪьЛЖКЦ·ЁFOMAMLӨт’ҲҸҲӨ·ӨҝЎәReptileЎ»ӨтМб°ё ЁC Т»ҙОҪьЛЖПөMAMLӨтҪвОцөД/ҢgтYөДӨЛФuҒэ ЁC ббҫAСРҫҝӨ¬ЖаӨҪӨҰ(·ҪПтРФӨПӨҪӨмӨҫӨмЙЩӨ·Я`ӨҰ) ? Transferring Knowledge across Learning Processes(ICLR 2019 oral) ? Bayesian Model-Agnostic Meta-Learning(NeurIPS 2018) ? Auto-Meta: Automated Gradient Based Meta Learner Search(NeurIPS 2018) ? ДЪИЭ ЁC З°МбЦӘЧR(ҘбҘҝС§Б•, joint training, MAML, FOMAML) ЁC Мб°ёКЦ·ЁReptile ЁC ҘбҘҝёьРВӨОҪвбӢ(ҘбҘҝ№ҙЕдӨОПтӨӯ, ҘСҘйҘбҘҝҝХйgДЪӨЗӨОХсӨлОиӨӨ) ЁC ҢgтY(Reptile v.s. MAML/FOMAML, ReptileӨОоBҪЎРФ)
- 4. ҘбҘҝС§Б• ? С}КэӨОЛЖӨҝҶ–о}ӨЛҢқӨ·ӨЖҡшУГөДӨКДЬБҰӨтөГӨЖӨЫӨ·ӨӨ ЁC ҳ”Ў©ӨКСФХZӨЗӨООДЧЦХJЧR ЁC ҸҠ»ҜС§Б•(ҳ”Ў©ӨКЙнМеөДҘСҘйҘбҘҝ/ҳ”Ў©ӨКӯhҫі/ҳ”Ў©ӨКҲуік(ҘҝҘ№ҘҜ)) ЁC (ҡшУГAIёР?) ? И«ҘҝҘ№ҘҜӨЗӨОҘЁҘй©`ӨОЖЪҙэӮҺӨтЧоРЎ»ҜӨ·ӨҝӨӨ 4omniglot/Guided Meta-Policy Search
- 5. ? ҝЦӨйӨҜТ»·¬…gјғӨКmeta-learningКЦ·Ё ? ӨЙӨуӨКҘҝҘ№ҘҜӨвңәұйӨКӨҜӨіӨКӨ»ӨлӨиӨҰЎўҘЁҘй©`ӨОЖЪҙэӮҺӨтЧоРЎ»Ҝ ЁC Ұі: И«train taskӨ«ӨйҘөҘуҘЧҘкҘуҘ° ЁC ФuҒэҘҝҘ№ҘҜӨЗӨПЎўС§Б•Ө·ӨҝҰИ or ЙЩӨ·ҘБҘе©`ҘЛҘуҘ°Ө·ӨҝҰИЎҜӨтК№ӨГӨЖҪвӨҜ ? ҘБҘе©`ҘЛҘуҘ°ӨЗҫ«¶ИӨ¬ЙПӨ¬ӨлұЈФ^ӨПИ«ӨҜҹoӨӨ ? 4ұҫЧгҡiРРRLӨОАэ(ӨўӨҜӨЮӨЗҘӨҘб©`Ҙё) ЁC ӨЙӨуӨКЫаөАӨЗӨвҡiӨұӨлӨиӨҰЎўҘ°Ҙн©`ҘРҘлӨЛБјӨӨҘкҘәҘаӨЗЧгӨтАRӨкіцӨ№ ЁC ҪYҫЦӨПЖҪҫщөДӨКөА(ЁPЖҪМ№ӨКөА)ӨЗӨ·ӨГӨ«ӨкҡiӨұӨлӨиӨҰӨЛӨ№ӨлӨАӨұ ? …gјғӨАӨұӨЙЎўMAMLӨв°л·Цjoint trainingЎЈ 5
- 6. joint trainingӨИӨОұИЭ^ӨтТвЧRӨ·ӨЖ•шӨҜӨИЎў ? ұҫөұӨЛӨдӨкӨҝӨӨӨОӨПЎўФuҒэ•rӨОҘЁҘй©`ӨОЖЪҙэӮҺӨОЧоРЎ»Ҝ ЁC С§Б••r(meta-train) ? Ұі_tr/Ұі_val: train taskӨ«ӨйҘөҘуҘЧҘкҘуҘ°Ө·ӨҝҰіӨтӨөӨйӨЛУ–ҫҡУГ/ФuҒэУГӨЛ·ЦӨұӨл ? inner_update & meta_updateӨтАRӨк·өӨ№ЎЈ ЁC ФuҒэ•r(meta-test) ? ҪвӨӯӨҝӨӨҘҝҘ№ҘҜӨОfew sample/few episodeӨЗҘБҘе©`ҘЛҘуҘ° ? ұШӨәБјӨӨҘБҘе©`ҘЛҘуҘ°Ө¬ӨЗӨӯӨл==БјӨӨіхЖЪӮҺӨ¬өГӨйӨмӨЖӨӨӨлЎЈ 6/YoonhoLee4/on-firstorder-metalearning-algorithms
- 7. (Ҷ–о}ФO¶ЁӨ¬ӨдӨдГжө№ӨКӨОӨЗКЎВФ) ? sinІЁРОЧҙНЖ¶Ё ЁC ҳ”Ў©ӨК(ҰЛ:Хс·щ, ҰИ:О»Па) == ҘҝҘ№ҘҜ ЁC •шӨҜҘҝҘ№ҘҜ10өгУлӨЁӨйӨмӨЖ(==train)ЎўИ«¶ЁБxУтӨЗУиңy(==test) ? joint trainingӨАӨИЎўҳ”Ў©ӨКҘҝҘ№ҘҜӨЗС§Б•Ө·ӨҝӨИӨіӨнӨЗ ¶ЁКэйvКэf(x)=0Ө¬ЧоЯmҪвЎЈfew sampleӨЗӨОҘБҘе©`ҘЛҘуҘ°ӨПҹoАнЎЈ ? joint trainingӨПҘАҘбЎЈЎәФuҒэ•rӨОҘЁҘй©`ӨОЖЪҙэӮҺӨОЧоРЎ»ҜЎ»Ө¬ҙуКВЎЈ 7
- 8. ? ҢgАыУГЙПӨОФ’Ўў MAMLӨПӨ«ӨКӨкӨОҘбҘвҘкӨтПыЩMӨ№ӨлӨіӨИӨ¬ЦӘӨйӨмӨЖӨӨӨлЎЈ ЁC ҪY№ыӨ«ӨйТҠӨмӨРҹoсjӨЛУӢЛгҘіҘ№ҘИӨ¬ёЯӨӨ ЁC inner_updateӨО»ШКэӨЛӨЫӨЬұИАэӨ·ӨЖҘбҘвҘкӨ¬іЦӨГӨЖӨ«ӨмӨл(ббКц) ? ӨҪӨОӨҝӨб¶аӨҜӨОMAMLҢgЧ°ӨЗӨПfew_stepӨКinner_updateӨ¬Т»°гөД(ЦчУQ) ? MAMLӨОmeta-train•rӨОКҪӨтТ»ҙОҪьЛЖӨ·ӨЖК№ӨҰӨИБјӨӨӨйӨ·ӨӨЎЈ ЁC (MAMLӨ¬іхӨбӨЛМб°ёӨөӨмӨҝХ“ОДӨЛӨвГьГы•шӨ«ӨмӨЖӨӨӨл) ЁC ббӨЛFOMAML(first-order MAML)ӨИГьГыӨөӨмӨл 8
- 9. ? іхЖЪҘСҘйҘбҘҝҰХӨОёьРВ ЁC ¶юҙО№ҙЕд(LЎҜЎҜ(ҰХ))Ө¬өЗҲцӨ№Өл ? lossӨтҘСҘйҘбҘҝКэnӨО2Ғ\»ШОў·Ц(?)ЎыЦШӨҝӨӨ ЁC L_i: iҘ№ҘЖҘГҘЧДҝӨЗӨОloss, 9 ббӨЗҮмӨГӨҝ Іҝ·ЦӨҪӨмӨҫ ӨмӨЗҰБ^2ТФ ЙПӨОн—Өтҹo Т•Ө·ӨЖӨЯӨл
- 10. ? ¶юҙО№ҙЕдИ«ІҝҹoТ•(Ui(ҰХi)=ҰХi, ЎъLkӨПҰХ1ӨЗ°kЙъ) ? Т»·¬ЧоббӨОloss == train taskӨОvalӨЗӨОlossӨОӨЯК№ӨҰ ЁC inner_update•rӨО№ҙЕдӨтұЈҙжӨ·ӨКӨӨЎЈҢgЧ°өДӨЛЧФИ»ӨК°kПлЎЈ ЁC ҝЦӨйӨҜfew stepӨКёьРВӨтЗ°МбӨЛӨ·ӨЖӨӨӨлӨОӨЗӨҰӨЮӨҜӨӨӨҜ 10 ҰХ1 ҰХ2 ҰХ3 ҰХ4 ҰХ5 ҰХ6
- 11. ? inner_update•rӨО№ҙЕдӨтИ«ІҝәПіЙӨ№Өл ЁC ӨіӨБӨйӨв¶юҙО№ҙЕдӨПҹoТ•ЎЈ ЁC ҘСҘйҘб©`ҘҝҝХйgЙПӨО„УӨӯӨтТҠӨлӨИ ӨіӨБӨйӨО·ҪӨ¬ЧФИ»ЎЈ ЁC FOMAMLӨИұИӨЩӨЖУӢЛгҘіҘ№ҘИӨПӨЫӨЬүҲӨЁӨКӨӨ ЁC stepКэӨ¬үҲӨЁӨЖӨвҶ–о}ӨКӨӨ ? „eӨОҪвбӢ ЁC ЧоббӨЛӨҝӨЙӨкЧЕӨӨӨҝҘСҘйҘбҘҝӨИӨОІоӨО·ҪПтӨЛЯMӨа ? MAMLӨОЦұҪУөДӨКҪьЛЖӨЗӨПӨКӨӨ(ӨИЛјӨҰ) 11
- 15. ҘбҘҝ№ҙЕдӨОПтӨӯ ? ӨЮӨәЎўg_i ЁC LossйvКэӨЛТАҙжӨ№ӨлӨ¬ЎўҰХ1ЦЬӨкӨЗҘЖҘӨҘй©`Х№й_Ө·ӨЖ ҰБ^2ТФЙПӨОн—ӨтҹoТ•Ө·ӨЖӨ№ӨЩӨЖҰХ1ЦЬӨкӨО№ҙЕдӨЗұнӨ№ ? И«ІҝҰХ1ЦЬӨкӨтУӢЛгӨ№ӨмӨРёчөШөгӨЗӨО№ҙЕдӨтјҜӨбӨЖ„IАнӨ·ӨдӨ№ӨҜӨКӨл 15
- 17. ҘбҘҝ№ҙЕдӨОПтӨӯ ? ӨіӨіӨ«ӨйТ»ө©k=2ӨЮӨЗ(inner_update1»Ш+ФuҒэ1»Ш)ӨтҝјӨЁӨлЎЈ ? FOMAML/ReptileӨЛӨДӨӨӨЖӨвЎў ? Ө«ӨйН¬ҳ”ӨЛ ЁC ӨҝӨАӨ· 17 ( )
- 19. ҘбҘҝ№ҙЕдӨОПтӨӯ ? g_barӨОЖҪҫщ ? H_bar gӨОЖҪҫщ 19
- 20. ҘбҘҝ№ҙЕдӨОПтӨӯ ? gi_barӨОЖҪҫщ ЁC Ўә? AvgGradЎ»·ҪПтӨПjoint trainingӨЛПаөұӨ·ӨЖӨӨӨл ? ЎёҰХ1ӨтӨЙӨГӨБӨЛёьРВӨ№ӨмӨРlossӨ¬РЎӨөӨҜӨКӨГӨҝӨОӨ«Ў№ ? ӨҪӨмӨ¬ҘБҘе©`ҘЛҘуҘ°Ө·ӨдӨ№ӨӨӨ«ӨПҝј‘]ӨөӨмӨЖӨКӨӨ 20
- 21. ҘбҘҝ№ҙЕдӨОПтӨӯ ? Hi_bar gjӨОЖҪҫщ ЁC ЎәAvgGradInnerЎ»·ҪПтӨПЎўёчinner_update•rӨО(ёчҘЯҘЛҘРҘГҘБйgӨО)№ҙЕдӨОДЪ·eӨОӮҺ ӨтЙПӨІӨЖӨӨӨл ? Н¬ӨёҘҝҘ№ҘҜӨКӨОӨЛЯ`ӨҰ·ҪПтӨЛёьРВӨ№ӨлӨіӨИӨПЯ^ЯmәПӨ·ӨЖӨӨӨлФ^(ӨҝӨЦӨу) ? ҘҝҘ№ҘҜӨЛ№ІНЁӨКҡш»ҜРФДЬӨОПтЙПӨЛјДУлӨ№Өл 21
- 22. ҘбҘҝ№ҙЕдӨОПтӨӯ ? ЖҪҫщӨтИЎӨлӨИЎў ? FOMAMLӨ¬MAMLӨ«Өй’ОӨЖӨҝӨОӨПAvgGradInnerТ»»Ш·Ц ЁC Н¬Өёiter»ШКэӨКӨйӨҪӨО·ЦӨАӨұРФДЬӨ¬ВдӨБӨл ? ReptileӨПMAMLӨЛAvgGradӨт+1»ШЎўAvgGradInnerӨт-1»Ш ЁC ReptileӨП…—ГЬӨЛӨПMAMLӨОТ»ҙОҪьЛЖӨЗӨПӨКӨӨӨОӨЗБјӨ·җҷӨ·ӨПЧФГчӨЗӨКӨӨЎЈ ЁC AvgGradInnerӨтүҲӨдӨ№ӨЛӨПЎӯЎъinner_updateКэӨтүҲӨдӨ№ 22
- 23. ҘбҘҝ№ҙЕдӨОПтӨӯ ? kҘ№ҘЖҘГҘЧПИӨЮӨЗЙмӨРӨ№ӨИЎў ? ӨЙӨОКЦ·ЁӨвЙмӨРӨ»ӨРЙмӨРӨ№ӨЫӨЙAvgGradInnerӨО ёоәПӨ¬ёЯӨҜӨКӨл ЁC ЙмӨРӨ·ӨЖӨӘӨұӨРҡш»ҜРФӨ¬ӨўӨ¬ӨлӨИҝјӨЁӨйӨмӨл ? ReptileӨПҘЁҘй©`ӨОЖЪҙэӮҺӨтёЯЛЩӨЛПВӨІӨл„ҝ№ыӨв ӨіӨОКҪӨ«ӨйЖЪҙэӨЗӨӯӨлЎЈ 23
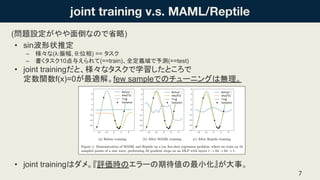
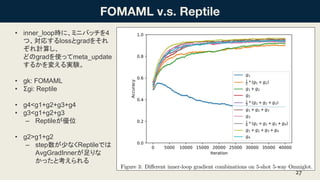
- 24. ҘСҘйҘбҘҝҝХйgДЪӨЗӨОМҪЛч•rӨОХсӨлОиӨӨ ? ReptileӨПЎўҘСҘйҘбҘҝҝХйgДЪӨЗҘж©`ҘҜҘкҘГҘЙҫалxөДӨЛЧоЯmӨКҲцЛщӨШРРӨҜӨіӨИӨ¬ КҫӨ»Өл ? ReptileӨП°өьaөДӨЛТФПВӨтРРӨГӨЖӨӨӨл(ҫалxӨОЖЪҙэӮҺӨОЧоРЎ»Ҝ) ЁC WҰУ: ӨўӨлҘҝҘ№ҘҜҰУӨОЧоЯmӨКҘСҘйҘбҘҝӨОҘкҘ№ҘИ(¶аҳ”Ме?) ? ЧоЯmӨКҘСҘйҘбҘҝӨПҹoКэӨЛӨўӨл(ИлӨмМжӨЁҝЙДЬӨКҘСҘйҘбҘҝӨПӨҝӨҜӨөӨуӨўӨлӨОӨЗ) 24 W1 W2
- 25. ҘСҘйҘбҘҝҝХйgДЪӨЗӨОМҪЛч•rӨОХсӨлОиӨӨ ? ¬FФЪӨОіхЖЪӮҺҰХӨЛЧоӨвҪьӨӨWҰУДЪӨОҘСҘйҘбҘҝӨтP_WҰУӨИӨ№ӨлӨИ ? Т»ӨДТ»ӨДӨОҘҝҘ№ҘҜӨЛЧўДҝӨ№ӨлӨИЎў ? ҢgлHӨЛӨПP_WҰУӨПӨпӨ«ӨйӨКӨӨӨОӨЗЎў ӨіӨмӨтҰХkӨЛЦГӨӯ“QӨЁӨл ? ӨіӨмӨПReptileӨОmeta_updateӨОКҪӨИН¬Өё ? MAML/FOMAMLӨЛӨПҹoӨӨБјӨө 25
- 26. 26 ҢgтY
- 27. ? inner_loop•rӨЛЎўҘЯҘЛҘРҘГҘБӨт4 ӨДЎўҢқҸкӨ№ӨлlossӨИgradӨтӨҪӨм ӨҫӨмУӢЛгӨ·Ўў ӨЙӨОgradӨтК№ӨГӨЖmeta_update Ө№ӨлӨ«ӨтүдӨЁӨлҢgтYЎЈ ? gk: FOMAML ? ҰІgi: Reptile ? g4<g1+g2+g3+g4 ? g3<g1+g2+g3 ЁC ReptileӨ¬ғһО» ? g2>g1+g2 ЁC stepКэӨ¬ЙЩӨКӨҜReptileӨЗӨП AvgGradInnerӨ¬ЧгӨкӨК Ө«ӨГӨҝӨИҝјӨЁӨйӨмӨл 27
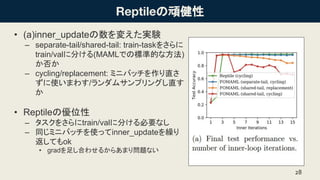
- 28. ӨОоBҪЎРФ ? (a)inner_updateӨОКэӨтүдӨЁӨҝҢgтY ЁC separate-tail/shared-tail: train-taskӨтӨөӨйӨЛ train/valӨЛ·ЦӨұӨл(MAMLӨЗӨОҳЛңКөДӨК·Ҫ·Ё) Ө«·сӨ« ЁC cycling/replacement: ҘЯҘЛҘРҘГҘБӨтЧчӨкЦұӨө ӨәӨЛК№ӨӨӨЮӨпӨ№/ҘйҘуҘАҘаҘөҘуҘЧҘкҘуҘ°Ө·ЦұӨ№ Ө« ? ReptileӨОғһО»РФ ЁC ҘҝҘ№ҘҜӨтӨөӨйӨЛtrain/valӨЛ·ЦӨұӨлұШТӘӨКӨ· ЁC Н¬ӨёҘЯҘЛҘРҘГҘБӨтК№ӨГӨЖinner_updateӨтАRӨк ·өӨ·ӨЖӨвok ? gradӨтЧгӨ·әПӨпӨ»ӨлӨ«ӨйӨўӨЮӨкҶ–о}ӨКӨӨ 28
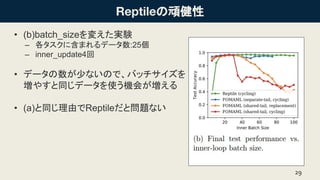
- 29. ӨОоBҪЎРФ ? (b)batch_sizeӨтүдӨЁӨҝҢgтY ЁC ёчҘҝҘ№ҘҜӨЛә¬ӨЮӨмӨлҘЗ©`ҘҝКэ:25ӮҖ ЁC inner_update4»Ш ? ҘЗ©`ҘҝӨОКэӨ¬ЙЩӨКӨӨӨОӨЗЎўҘРҘГҘБҘөҘӨҘәӨт үҲӨдӨ№ӨИН¬ӨёҘЗ©`ҘҝӨтК№ӨҰҷC»бӨ¬үҲӨЁӨл ? (a)ӨИН¬ӨёАнУЙӨЗReptileӨАӨИҶ–о}ӨКӨӨ 29
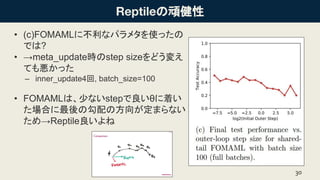
- 30. ӨОоBҪЎРФ ? (c)FOMAMLӨЛІ»АыӨКҘСҘйҘбҘҝӨтК№ӨГӨҝӨО ӨЗӨП? ? Ўъmeta_update•rӨОstep sizeӨтӨЙӨҰүдӨЁ ӨЖӨвҗҷӨ«ӨГӨҝ ЁC inner_update4»Ш, batch_size=100 ? FOMAMLӨПЎўЙЩӨКӨӨstepӨЗБјӨӨҰИӨЛЧЕӨӨ ӨҝҲцәПӨЛЧоббӨО№ҙЕдӨО·ҪПтӨ¬¶ЁӨЮӨйӨКӨӨ ӨҝӨбЎъReptileБјӨӨӨиӨН 30
- 31. ӨЮӨИӨб ? Т»ҙОҪьЛЖMAMLҘЩ©`Ҙ№ӨОКЦ·ЁReptileӨтМб°ё ЁC ЛЩӨӨ…§Кш&оBҪЎРФӨ¬ЖЪҙэӨЗӨӯӨл ? БјӨӨ(MAML/№ҙЕд·ЁҘЩ©`Ҙ№ӨО)ҘбҘҝС§Б•·ЁӨИӨПәОӨ«ӨтКҫӨ·Өҝ ЁC ҘЁҘй©`ЖЪҙэӮҺӨОЧоРЎ»Ҝ ЁC Ҙ№ҘЖҘГҘЧйgӨОДЪ·eӨОЧоҙу»Ҝ ЁC ҪвМҪЛч•rӨОХсӨлОиӨӨ ? MAMLӨтК№ӨҰлHӨПТ»ө©Т»ҙОҪьЛЖ°жӨтҝјӨЁӨЖӨЯӨлӨЩӨӯ 31