°ĺDL›Ü’iĽŠ°Ņ•ř•Ž•Ń•‚©`•ņ•Ž LLM
Download as pptx, pdf0 likes448 views

2023/8/16 Deep Learning JP http://deeplearning.jp/seminar-2/
![??MATSUO INSTITUTE, INC.
DEEP LEARNING JP
[DL Papers]
•ř•Ž•Ń•‚©`•ņ•Ž LLM
Takaomi Hasegawa
http://deeplearning.jp/](https://image.slidesharecdn.com/llm20230803-230816031643-032a1160/85/DL-LLM-1-320.jpg)







°ĺDL›Ü’iĽŠ°Ņ•ř•Ž•Ń•‚©`•ņ•Ž LLM
- 1. ??MATSUO INSTITUTE, INC. DEEP LEARNING JP [DL Papers] •ř•Ž•Ń•‚©`•ņ•Ž LLM Takaomi Hasegawa http://deeplearning.jp/
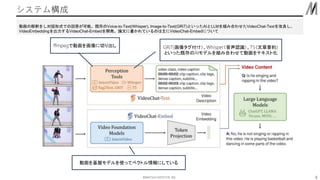
- 2. ??MATSUO INSTITUTE, INC. ◊‘ľļĹBĹť 2 https://www.denso.com/jp/ja/driven-base/tech-design/robot/ DENSO •™•¶•ů•…•Š•«•£•Ę DRIVEN BASE§Ť§Í“ż”√ ‹á›d≤Ņ∆∑•Š©`•ę§«•»•ř•»§ÚÖß∑ā§Ļ§Ž•Ū•‹•√•»§őAIĽ≠ŌŮ’J◊R§őľľ–gť_įk ň…ő≤—–§«AI§ő…ÁĽŠĆg◊į
- 3. ??MATSUO INSTITUTE, INC. ēÝ’I«ťąů VideoChat 3 ≥ŲĶš£© https://arxiv.org/abs/2305.06355 ?•Ņ•§•»•Ž VideoChat ?÷Ý’Ŗ OpenGVLab(Generalized vision-based AI) Shanghai AI Lab, ńŌĺ©īů—ß°ĘŌ„łŘīů—ß°Ę …ÓŘŕĶ» ?łŇ“™ - End-to-End§ő•Ń•„•√•»•Ŕ©`•Ļ§ő•”•«•™ņŪĹ‚•∑•Ļ•∆•ŗ - •«©`•Ņ•Ľ•√•»§‚ļŌ§Ô§Ľ§∆ŐŠįł - •≥©`•…§‚Ļęť_
- 5. ??MATSUO INSTITUTE, INC. ťvŖBįkĪŪ 5 https://deeplearning.jp/%e3%83%9e%e3%83%ab%e3%83%81%e3%83%a2%e3%83%bc%e3%83%80%e3% 83%ab-%e5%9f%ba%e7%9b%a4%e3%83%a2%e3%83%87%e3%83%ab/ •ř•Ž•Ń•‚©`•ņ•Ž ĽýĪP•‚•«•Ž£®‘≠ŐÔ§Ķ§ů£© Visual ChatGPT£®ĹŮĺģ§Ķ§ů£© https://deeplearning.jp/visual-chatgpt-talking-drawing-and-editing-with-visual-foundation-models/ ĹYėčĪĽ§√§∆§ř§∑§Ņ°≠ Ą”Ľ≠ + LLM§Ō≥ű§Š§∆§»§§§¶§≥§»§«§ī»›…‚§Ú
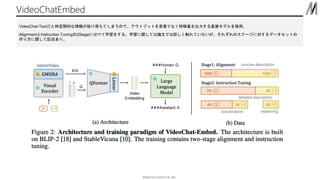
- 6. ??MATSUO INSTITUTE, INC. •∑•Ļ•∆•ŗėč≥… 6 Ą”Ľ≠§őĹ‚Šč§Ú§∑ĆĚ‘í–ő ŧ«§őĽōīū§¨Ņ…ń‹°£ľ»īś§őVoice-to-Text(Whisper), Image-to-Text(GRiT)§»§§§√§ŅAI§»LLM§ÚĹM§ŖļŌ§Ô§Ľ§ŅVideoChat-Text§ÚłńŃľ§∑°Ę VideoEmbedding§Ú≥ŲѶ§Ļ§ŽVideoChat-Embed§Úť_įk°£’ďőń§ňēݧ꧞§∆§§§Ž§ő§Ō÷ų§ňVideoChat-Embed§ň§ń§§§∆ GRiT(Ľ≠ŌŮ•Ņ•įł∂§Ī£©°ĘWhisper£®“Ű…ý’J◊R£©°ĘT5£®őń’¬“™ľs£© §»§§§√§Ņľ»īś§őAI•‚•«•Ž§ÚĹM§ŖļŌ§Ô§Ľ§∆Ą”Ľ≠§Ú•∆•≠•Ļ•»ĽĮ Ą”Ľ≠§ÚĽýĪP•‚•«•Ž§Ú Ļ§√§∆•Ŕ•Į•»•Ž«ťąů§ň§∑§∆§§§Ž ffmpeg§«Ą”Ľ≠§ÚĽ≠Ō٧ň«–§Í≥Ų§∑
- 8. ??MATSUO INSTITUTE, INC. VideoChatEmbed VideoChat-Text§ņ§»ērŅ’ťgĶń§ «ťąů§¨íi§Ī¬š§Ń§∆§∑§ř§¶§ő§«°Ę•Ę•¶•»•◊•√•»§Ú—‘»~§«§ §ĮŐōŹ’ŃŅ§Ú≥ŲѶ§Ļ§ŽĽýĪP•‚•«•Ž§Ú Ļ”√°£ Alignment§»Instruction Tuning§ő2Stage§ň∑÷§Ī§∆—ßŃē§Ú§Ļ§Ž°£—ßŃē§ňťv§∑§∆§Ō’ďőń§«§Ō‘Ē§∑§Įī•§ž§∆§§§ §§§¨°Ę§Ĺ§ž§ĺ§ž§ő•Ļ•∆©`•ł§ňḈĻ§Ž•«©`•Ņ•Ľ•√•»§ő ◊ų§Í∑ŧňťv§∑§∆”õ Ų§Ę§Í°£
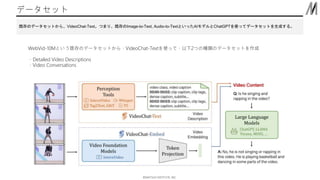
- 9. ??MATSUO INSTITUTE, INC. •«©`•Ņ•Ľ•√•» ľ»īś§ő•«©`•Ņ•Ľ•√•»§ę§ť°ĘVideoChat-Text°£§ń§ř§Í°Ęľ»īś§őImage-to-Text, Audio-to-Text§»§§§√§ŅAI•‚•«•Ž§»ChatGPT§Ú Ļ§√§∆•«©`•Ņ•Ľ•√•»§Ú…ķ≥…§Ļ§Ž°£ WebVid-10M§»§§§¶ľ»īś§ő•«©`•Ņ•Ľ•√•»§ę§ť°ĘVideoChat-Text§Ú Ļ§√§∆°Ę“‘Ō¬2§ń§ő∑NÓź§ő•«©`•Ņ•Ľ•√•»§Ú◊ų≥… ?Detailed Video Descriptions ?Video Conversations
- 10. ??MATSUO INSTITUTE, INC. Detailed Video Descriptions VideoChat-Text§ő≥ŲѶ§ňḈ∑§∆°ĘChatGPT§ő2∂őŽA§ő•◊•Ū•ů•◊•»§ÚÕ®§Ļ°£1∂őńŅ£®Table3£©§Ō∂ŗ≤ § •ť•Ŕ•Ž§Ú∑÷§ę§Í§š§Ļ§§•Ļ•»©`•Í©`§ň§Ļ§Ž°£ 2∂őńŅ£®Table4£©§Ō°Ęőń’¬§Ú•Í•’•°•§•ů§Ļ§Ž§≥§»§«•Ō•Ž•∑•Õ©`•∑•Á•ů§Ú“÷÷∆§Ļ§Ž°£ ≥ŲѶņż 2∂őŽA§ő•◊•Ū•ů•◊•»
- 11. ??MATSUO INSTITUTE, INC. Video Conversations 3∑NÓź£®descriptive, temporal, casual)§ő•◊•Ū•ů•◊•»§Ú Ļ§¶§≥§»§«°ĘĄ”Ľ≠§ňḈĻ§ŽĽŠ‘íņż§ÚĶ√§Ž
- 12. ??MATSUO INSTITUTE, INC. §ř§»§Š§»Future work §ř§»§Š§»Future work§»ňýł– §ř§»§Š “‘Ō¬§ő2§ń§ő ÷∑®§ÚŐŠįł°£VideoChat-Embed§ő∑ŧ¨ērŅ’ťg§őÕ∆’炙“ÚĻŻťvāS§Ú§Ť§ĮĪŪ§∑§∆§§§Ž ?VideoChat-Text£ļ•∆•≠•Ļ•»•Ŕ©`•Ļ•–©`•ł•Á•ů ?VideoChat-Embed£ļ end-to-end•–©`•ł•Á•ů Future work “‘Ō¬3Ķ„ ?•‚•«•Ž§ő•Ļ•Ī©`•Ž£®īů“éń£ĽĮ£© ?•Ŕ•ů•Ń•ř©`•Į ?ťLērťg§ő•”•«•™ĆĚŹÍ ňýł– ?•«©`•Ņ•Ľ•√•»ChatGPT§«§ń§Į§√§∆§§§ŽĶ„°Ę•◊•Ū•ů•◊•»§őĻ§∑Ú£®2∂őŽA°Ę3∑NÓź£©§Ō√śį◊§§£®…Ő”√ņŻ”√§Ō≤ĽŅ…£Ņ£© ?ťLērťg§őĄ”Ľ≠§ŌŽy§∑§Ĺ§¶°£§Ļ§įĆg”√ĽĮ§Ļ§Ž§»§∑§Ņ§ť°ĘĄ”Ľ≠ńŕ§Ú◊‘»Ľ—‘’Z§«ó ňų£®Appendix 1£©§∑§∆ērťgŐō∂®°ĘňŻ§ő•»•Í•¨§Ú Ļ§¶§»§§ §√§ŅĻ§∑Ú§¨Īō“™§Ĺ§¶ ?—‘’Z§»§§§¶•§•ů•Ņ©`•’•ß©`•Ļ§őŌřĹÁ£®«ťąůŃŅ§őĶÕŌ¬£©§Úł–§ł§Ņ£®Appendix 2£©
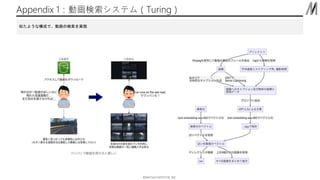
- 13. ??MATSUO INSTITUTE, INC. Appendix 1£ļĄ”Ľ≠ó ňų•∑•Ļ•∆•ŗ£®Turing£© ň∆§Ņ§Ť§¶§ ėč≥…§«°ĘĄ”Ľ≠§őó ňų§ÚĆg¨F
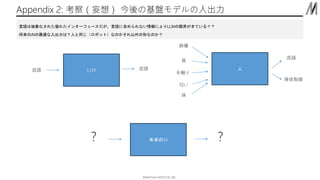
- 14. ??MATSUO INSTITUTE, INC. Appendix 2: Ņľ≤ž£®ÕżŌŽ£© ĹŮŠŠ§őĽýĪP•‚•«•Ž§ő»Ž≥ŲѶ LLM —‘’Z —‘’Z »ň “Ű ”≥ŌŮ ÷ī•§Í ĄŲ§§ ő∂ —‘’Z …ŪŐŚ÷∆”ý —‘’Z§Ō≥ťŌůĽĮ§Ķ§ž§ŅÉ짞§Ņ•§•ů•Ņ©`•’•ß©`•Ļ§ņ§¨°Ę—‘’Z§ňļ¨§Š§ť§ž§ §§«ťąů§ň§Ť§ÍLLM§őŌřĹÁ§¨§≠§∆§§§Ž£Ņ£Ņ Ĺęņī§őAI§ő◊ÓŖm§ »Ž≥ŲѶ§Ō£Ņ»ň§»Õ¨§ł£®•Ū•‹•√•»£©§ §ő§ę§Ĺ§ž“‘Õ‚§ő–ő§ §ő§ę£Ņ őīņī§őAI £Ņ £Ņ