„Ž„¤„Æ„ķ„Ž„¦„¹¤Ī¤æ¤į¤Ī MATLAB/Simulink Öv׳ µŚ1»Ų - MATLABČėéT
13 likes7,418 views

2019/1/19¤ĖæŖ“ߤ·¤æ„Ž„¤„Æ„ķ„Ž„¦„¹¤Ī¤æ¤į¤Ī²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ½²×ł¤ĪµŚ1»Ų׏ĮĻ¤Ē¤¹£®²Ń“”°Õ³¢“”µž¤Ī»ł±¾²Ł×÷¤Č£¬„ķ„°„Ē©`„ææÉŹÓ»Æ¤Ī¤æ¤į¤Ī„ׄķ„ƄȤņÖ÷¤ĖQ¤Ć¤Ę¤¤¤Ž¤¹£®
















![„Ł„Æ„Č„ė?ŠŠĮŠ¤Īų¤·½
”ń ŠŠ„Ł„Æ„Č„ė
r = [1 2 3] ¤Ž¤æ¤Ļ r = [1, 2, 3]
”ń ĮŠ„Ł„Æ„Č„ė
c = [1; 2; 3]
”ń ŠŠĮŠ
M = [1 2 3; 4 5 6; 7 8 9]
Tip
„¹„Ś©`„¹ or „«„󄎤Ē
ĮŠ·½Ļņ(ŗį·½Ļņ)¤Ų¤ĪČėĮ¦,
„»„ß„³„ķ„ó¤ĒøÄŠŠ¤ņŅāĪ¶
¤¹¤ė.](https://image.slidesharecdn.com/mmmatlab01-190127053958/85/MATLAB-Simulink-1-MATLAB-25-320.jpg)




![ŠŠĮŠ¤ĪŅŖĖŲ¤Ų¤Ī„¢„Æ„»„¹
Č”¤ź³ö¤·¤ā“śČė¤ā¤Ē¤¤Ž¤¹
CŃŌÕZ¤ĪÅäĮŠ¤Ē¤¤¤¦ a[0] ¤Ļ, MATLAB¤Ē¤Ļ a(1) ¤Ē¤¹
”ń ŠŠĮŠ¤ĪöŗĻ¤Ļ, A(1,2) ¤Č¤¹¤ė¤³¤Č¤Ē ¤ņÖø¤»¤ė
”ń ¹ ģ¤ņČ”¤ź³ö¤·¤æ¤¤¤Č¤¤Ļ¹ ģ„Ł„Æ„Č„ė¤ņŹ¹¤¦
A(1:3, :) A¤Ī1”«3ŠŠÄæ£¬Č«ĮŠ(:)¤ņČ”¤ź³ö¤·
ŠŠ·¬ŗÅ
ĮŠ·¬ŗÅ
Tip
¹ ģ„Ł„Æ„Č„ė¤Ē¤Ź¤Æ¤Ę¤ā
OK. Öø¶Ø¤·¤æķ·¬¤É¤Ŗ¤ź
¤ĖČ”¤ź³ö¤·/“śČė¤Ē¤¤ė.
Ąż)
>> A([1 3], [1 4])](https://image.slidesharecdn.com/mmmatlab01-190127053958/85/MATLAB-Simulink-1-MATLAB-30-320.jpg)

![Tips [Coffee Break]
Ó¢ÕZ¤ņÕi¤į¤ė·½¤Ļ, UI
¤ČMathWorks¤Ī„¦„§
„Ö„µ„¤„ȤņÓ¢ÕZŌO¶Ø¤Ė
¤·¤æ·½¤¬¤ļ¤«¤ź¤ä¤¹¤¤
¤«¤ā.
ŅŖĖŲ¤“¤Č¤ĪŃŻĖć¤ņ¤¦¤Ž
¤ÆĄūÓƤ¹¤ė¤³¤Č¤ĒøßĖŁ
¤Ź„³©`„ɤņų¤±¤ė.
http://blog.tokor.org/2017/12/17/rogy-Adv
ent-Calendar-2017-%E3%80%8C%E3%81%8
6%E3%82%8F%E3%81%A3%E2%80%A6%E3
%82%8F%E3%81%9F%E3%81%97%E3%81%
AEMATLAB%E3%82%B3%E3%83%BC%E3%83
%89%E3%80%81%E9%81%85%E3%81%99%
E3%81%8E%E2%80%A6%EF%BC%9F%E3%80
%8D/
„³©`„Ē„£„ó„°ÓĆ„Õ„©„ó
„Ȥņ„¤„ó„¹„Č©`„ė¤¹¤ė
¤ČÕi¤ß¤ä¤¹¤Æ¤Ź¤ė.
¤Ŗ¤¹¤¹¤į:
- Ricty Discord
- Cica](https://image.slidesharecdn.com/mmmatlab01-190127053958/85/MATLAB-Simulink-1-MATLAB-32-320.jpg)






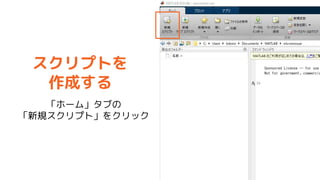
![„¹„Æ„ź„ׄȤĒ¤č¤ÆŹ¹ÓƤ¹¤ė„³„Ž„ó„É
³õĘŚ»ÆĻµ¤Ī„³„Ž„ó„ɤņ„Õ„”„¤„ėĆ°ī^¤Ėų¤Æ¤³¤Č¤ņĶĘX
”ń „ļ©`„Æ„¹„Ś©`„¹äŹż¤ņĻūČ„¤¹¤ė
clear
”ń „ׄķ„ƄȤņ¤¹¤Ł¤Ęé]¤ø¤ė
close all
”ń „³„Ž„ó„É„¦„£„ó„É„¦¤ņ„Æ„ź„¢¤¹¤ė
clc
Tip
MATLAB¤Ē¤Ļ£¬„¹„Æ„ź„×
„ȤĪgŠŠ¤“¤Č¤Ė䏿¤Ļ³õ
ĘŚ»Æ¤µ¤ģ¤Ź¤¤£®
»ł±¾µÄ¤Ė¤Ļclear„³„Ž„ó„É
¤Ē䏿¤ņĻūČ„¤·¤Ę¤«¤éI
Ąķ¤ņé_Ź¼¤¹¤ė¤³¤Č¤ņĶĘX
¤¹¤ė£®](https://image.slidesharecdn.com/mmmatlab01-190127053958/85/MATLAB-Simulink-1-MATLAB-44-320.jpg)









„Ž„¤„Æ„ķ„Ž„¦„¹¤Ī¤æ¤į¤Ī MATLAB/Simulink Öv׳ µŚ1»Ų - MATLABČėéT
- 2. ¤³¤ĪÖvĮ»į¤Ė¤Ä¤¤¤Ę MATLAB/Simulink ¤ņŹ¹ÓƤ·¤Ę ””½UņY¤Čæ± ”ś „Ē©`„æ¤Č½āĪö”” ¤Ų¤ĪŅĘŠŠ¤ņÄæÖø¤·¤Ž¤¹£® „·„ß„å„ģ©`„·„ē„ó¤ä„Ē©`„æ¤ĪæÉŅ»Æ¤ņŹ¹¤¤¤Ź¤¬¤é£¬S¤·¤Æ ѧ¤Ó¤Ž¤·¤ē¤¦£®
- 3. ÖvĮ»į¤Ī³É Č«5»Ų¤ņÓč¶Ø 1) MATLABČėéT (1/19)”” 2) SimulinkČėéT (3/16) 3) ŠÅŗÅIĄķ?„·„¹„Ę„ąĶ¬¶Ø(¢) (5ŌĀ) 4) „ķ„°„Ē©`„ææÉŅ»Æ?½āĪö(¢) (7ŌĀ) 5) Simulink¤«¤é¤Ī„³©`„ÉÉś³É(¢) (9ŌĀ)
- 4. „¢„ø„§„ó„Ą ½ń»Ų¤ĪÄŚČŻ¤ĻŅŌĻĀ¤Ī3¤Ä¤Ē¤¹£® 1. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB/Simulink¤¬¤É¤Ī¤č¤¦¤Ė„Ž„¤„Æ„ķ „Ž„¦„¹¤ĪŃu×÷¤ĖŅŪĮ¢¤Ä¤«ÕhĆ÷¤·¤Ž¤¹£® 2. „³„Ž„ó„É„¦„£„ó„É„¦¤ĒŹ¹¤¦ ¤Ž¤ŗ¤Ļė×æ¤Č¤·¤ĘMATLAB¤ņŹ¹¤Ć¤Ę ¤ß¤Ž¤·¤ē¤¦£® 3. „¹„Æ„ź„ׄČ?évŹż¤ņ×÷¤ė ±¾øńµÄ¤Ź„ׄķ„°„é„ß„ó„°¤ņŠŠ¤¦¤æ¤į¤Ī »łµA¤ņѧ¤Ó¤Ž¤¹£®
- 9. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB æĘѧ?¼¼ŠgÓĖć¤ĖĢŲ»Æ¤·¤æ„ׄķ„°„é„ß„ó„° ŃŌÕZ?é_°kh¾³. ĢŲÕ ? ŠŠĮŠ?„Ł„Æ„Č„ėÓĖć¤ņĖŹ×°ä ? ĮµĆ¤·¤ä¤¹¤¤ŃŌÕZŹĖ ? ŲNø»¤ŹĖŹévŹż?„Ä©`„ė„Ü„Ć„Æ„¹¤Ē ±¾Ł|µÄ¤Ē¤Ź¤¤g×°¤ĪŹÖég¤ņŹ”¤±¤ė Simulink „Ö„ķ„Ć„Æ¾ķ¤ņ„Ł©`„¹¤Ė¤·¤æ„·„ß„å„ģ©` „·„ē„󄽄ՄČ. ĢŲÕ ? „Ö„ķ„Ć„Æ¤ņ¤Ä¤Ź¤¤¤Ē„ׄķ„°„é„ß„ó„° ? „·„ß„å„ģ©`„·„ē„ó¤Čg×°¤ņŅ»ĄØ¤Ēé_°k ? C/C++¤Ī„½©`„¹„³©`„ɤņ„Ö„ķ„Ć„Æ¾ķ ¤«¤éÉś³É¤Ē¤¤ė(„³©`„ÉÉś³É)
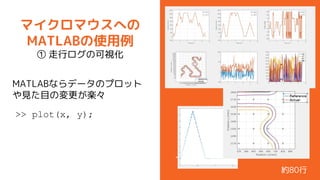
- 10. „Ž„¤„Æ„ķ„Ž„¦„¹¤Ų¤Ī MATLAB¤ĪŹ¹ÓĆĄż ¢Ł ×ߊŠ„ķ„°¤ĪæÉŅ»Æ MATLAB¤Ź¤é„Ē©`„æ¤Ī„ׄķ„Ć„Č ¤äŅ¤æÄæ¤Īäøü¤¬S”© >> plot(x, y); ¼s80ŠŠ
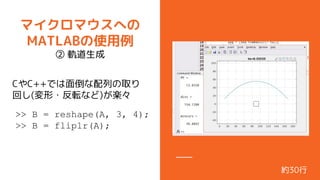
- 11. „Ž„¤„Æ„ķ„Ž„¦„¹¤Ų¤Ī MATLAB¤ĪŹ¹ÓĆĄż ¢Ś ܵĄÉś³É C¤äC++¤Ē¤ĻĆęµ¹¤ŹÅäĮŠ¤ĪČ”¤ź »Ų¤·(äŠĪ?·“ܤŹ¤É)¤¬S”© >> B = reshape(A, 3, 4); >> B = fliplr(A); ¼s30ŠŠ
- 12. „Ž„¤„Æ„ķ„Ž„¦„¹¤Ų¤Ī MATLAB¤ĪŹ¹ÓĆĄż ¢Ū ĆŌĀ·„Ē©`„æ¤ĪČ”¤źŽz¤ß »ĻńIĄķ¤Ź¤É¤Ī„Ä©`„ė„Ü„Ć„Æ„¹ ¤¬³äg, źÓƤ¬ŗ g >> IM = imread('1.jpg'); ¼s60ŠŠ https://gist.github.com/tokoro10g/57d88b5aafd 8ab0e62bf56cf74e99373
- 13. „Ž„¤„Æ„ķ„Ž„¦„¹¤Ų¤Ī MATLAB¤ĪŹ¹ÓĆĄż ¢Ü „Ž„¦„¹„愤„Ž©`(GUI) GUI¤Ī×÷³É¤ā, App Designer¤ņ Ź¹¤Ø¤Šŗ g! „·„ź„¢„ėĶ؊ŤĒ„Ē„Š„¤„¹¤Č¤ĪßB ŠÆ¤āæÉÄÜ! >> appdesigner >> s = serial('COM3') @Ryokeri14
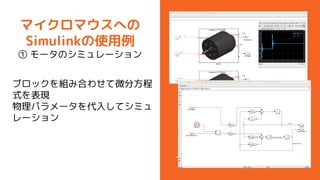
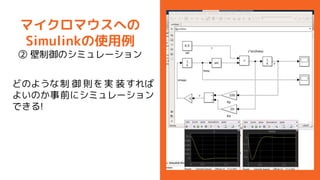
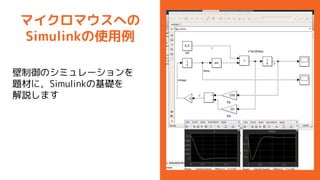
- 15. „Ž„¤„Æ„ķ„Ž„¦„¹¤Ų¤Ī Simulink¤ĪŹ¹ÓĆĄż ¢Ś ±ŚÖĘÓł¤Ī„·„ß„å„ģ©`„·„ē„ó ¤É¤Ī¤č¤¦¤ŹÖĘ Ół t¤ņg ×°¤¹¤ģ¤Š ¤č¤¤¤Ī¤«ŹĀĒ°¤Ė„·„ß„å„ģ©`„·„ē„ó ¤Ē¤¤ė!
- 16. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB æĘѧ?¼¼ŠgÓĖć¤ĖĢŲ»Æ¤·¤æ„ׄķ„°„é„ß„ó„° ŃŌÕZ?é_°kh¾³. ĢŲÕ ? ŠŠĮŠ?„Ł„Æ„Č„ėÓĖć¤ņĖŹ×°ä ? ĮµĆ¤·¤ä¤¹¤¤ŃŌÕZŹĖ ? ŲNø»¤ŹĖŹévŹż?„Ä©`„ė„Ü„Ć„Æ„¹¤Ē ±¾Ł|µÄ¤Ē¤Ź¤¤g×°¤ĪŹÖég¤ņŹ”¤±¤ė Simulink „Ö„ķ„Ć„Æ¾ķ¤ņ„Ł©`„¹¤Ė¤·¤æ„·„ß„å„ģ©` „·„ē„󄽄ՄČ. ĢŲÕ ? „Ö„ķ„Ć„Æ¤ņ¤Ä¤Ź¤¤¤Ē„ׄķ„°„é„ß„ó„° ? „·„ß„å„ģ©`„·„ē„ó¤Čg×°¤ņŅ»ĄØ¤Ēé_°k ? C/C++¤Ī„½©`„¹„³©`„ɤņ„Ö„ķ„Ć„Æ¾ķ ¤«¤éÉś³É¤Ē¤¤ė(„³©`„ÉÉś³É) ”ü ½ńČÕ¤Ļ¤³¤Ć¤Į
- 17. „¢„ø„§„ó„Ą ½ń»Ų¤ĪÄŚČŻ¤ĻŅŌĻĀ¤Ī3¤Ä¤Ē¤¹£® 1. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB/Simulink¤¬¤É¤Ī¤č¤¦¤Ė„Ž„¤„Æ„ķ „Ž„¦„¹¤ĪŃu×÷¤ĖŅŪĮ¢¤Ä¤«ÕhĆ÷¤·¤Ž¤¹£® 2. „³„Ž„ó„É„¦„£„ó„É„¦¤ĒŹ¹¤¦ ¤Ž¤ŗ¤Ļė×æ¤Č¤·¤ĘMATLAB¤ņŹ¹¤Ć¤Ę ¤ß¤Ž¤·¤ē¤¦£® 3. „¹„Æ„ź„ׄČ?évŹż¤ņ×÷¤ė ±¾øńµÄ¤Ź„ׄķ„°„é„ß„ó„°¤ņŠŠ¤¦¤æ¤į¤Ī »łµA¤ņѧ¤Ó¤Ž¤¹£®
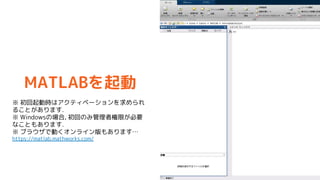
- 19. MATLAB¤ņĘšÓ ”ł ³õ»ŲĘšÓr¤Ļ„¢„Æ„Ę„£„Ł©`„·„ē„ó¤ņĒó¤į¤é¤ģ ¤ė¤³¤Č¤¬¤¢¤ź¤Ž¤¹. ”ł Windows¤ĪöŗĻ, ³õ»Ų¤Ī¤ß¹ÜĄķÕßŲĻŽ¤¬±ŲŅŖ ¤Ź¤³¤Č¤ā¤¢¤ź¤Ž¤¹. ”ł „ք鄦„¶¤ĒӤƄŖ„ó„鄤„ó°ę¤ā¤¢¤ź¤Ž¤¹” https://matlab.mathworks.com/
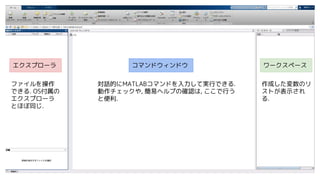
- 20. „Ø„Æ„¹„ׄķ©`„é „³„Ž„ó„É„¦„£„ó„É„¦ „ļ©`„Æ„¹„Ś©`„¹ „Õ„”„¤„ė¤ņ²Ł×÷ ¤Ē¤¤ė. OSø¶Źō¤Ī „Ø„Æ„¹„ׄķ©`„é ¤Č¤Ū¤ÜĶ¬¤ø. ŌµÄ¤ĖMATLAB„³„Ž„ó„ɤņČėĮ¦¤·¤ĘgŠŠ¤Ē¤¤ė. Ó×÷„Į„§„Ć„Æ¤ä, ŗŅׄŲ„ė„פĪ“_ÕJ¤Ļ, ¤³¤³¤ĒŠŠ¤¦ ¤Č±ćĄū. ×÷³É¤·¤æ䏿¤Ī„ź „¹„Ȥ¬±ķŹ¾¤µ¤ģ ¤ė.
- 22. MATLAB¤ĒŹ¹ÓƤ¹¤ėŃŻĖć×Ó »ł±¾¤Ļ¤Ū¤Č¤ó¤ÉCŃŌÕZ¤ČĶ¬. ”ń ĖÄtŃŻĖć?ĄŪ\ + - * / ^ ”ń “śČė = ”ń ±ČŻ^?ÕĄķŃŻĖć < > == ~= <= >= && || ~ Tip MATLAB¤Ī䏿¤Ļ„Ē„Õ„© „ė„ȤĒ¤ĻdoubleŠĶ¤Ė¤Ź ¤ė. e¤ĪŠĶ¤Ē¶ØĮx¤·¤æ¤¤¤Č¤ ¤Ė¤ĻŅŌĻĀ¤Ī¤č¤¦¤Ė¤¹¤ė. >> a = uint8(3)
- 23. MATLAB¤ĒŹ¹ÓƤ¹¤ėŹżŃ§évŹż »ł±¾¤Ļ¤Ū¤Č¤ó¤ÉCŃŌÕZ¤ČĶ¬. ”ń Čż½ĒévŹż sin cos sind cosd atan2 pi ... ”ń ÖøŹż?Źż exp log log10 log2 ”ń Ń}ĖŲŹż (MATLAB¤Ē¤ĻĖŹ×°ä!!) real imag abs angle i j Tip évŹż¤ĪŹ¹¤¤·½¤Ļ help„³„Ž „ó„É ¤ä doc„³„Ž„ó„É ¤Ē “_ÕJ¤Ē¤¤ė. Ąż) >> help sind >> doc cosd
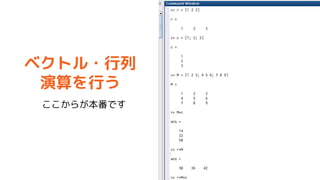
- 25. „Ł„Æ„Č„ė?ŠŠĮŠ¤Īų¤·½ ”ń ŠŠ„Ł„Æ„Č„ė r = [1 2 3] ¤Ž¤æ¤Ļ r = [1, 2, 3] ”ń ĮŠ„Ł„Æ„Č„ė c = [1; 2; 3] ”ń ŠŠĮŠ M = [1 2 3; 4 5 6; 7 8 9] Tip „¹„Ś©`„¹ or „«„󄎤Ē ĮŠ·½Ļņ(ŗį·½Ļņ)¤Ų¤ĪČėĮ¦, „»„ß„³„ķ„ó¤ĒøÄŠŠ¤ņŅāĪ¶ ¤¹¤ė.
- 26. ĢŲe¤Ź„Ł„Æ„Č„ė?ŠŠĮŠ ”ń ¹ ģ„Ł„Æ„Č„ė 1:10 ¤Ž¤æ¤Ļ 1:2:10 ¤Ž¤æ¤Ļ linspaceévŹż ”ń gĪ»ŠŠĮŠ eye(3) ”ń „¼„ķŠŠĮŠ zeros(3) ¤Ž¤æ¤Ļ zeros(4,2) ”ń 1¤ĒĀń¤į¤æŠŠĮŠ ones(3) ¤Ž¤æ¤Ļ ones(4,2) ”ń ĀŅŹżŠŠĮŠ rand(3) ¤Ž¤æ¤Ļ rand(4,2) Tip „«„Ć„³ÄŚ¤ĻŠŠĮŠ¤Ī“󤤵 ħ·ØźŠŠĮŠ¤ä„Ļ„󄱄ėŠŠ ĮŠ¤Č¤¤¤Ć¤æĢŲŹā¤ŹŠŠĮŠ¤ā ÓĆŅā¤µ¤ģ¤Ę¤¤¤ė. https://jp.mathworks. com/help/matlab/cons tants-and-test-matric es.html
- 28. „Ł„Æ„Č„ė?ŠŠĮŠĢŲÓŠ¤ĪŃŻĖć×Ó ”ń ŅŖĖŲ¤“¤Č¤Ī\Ėć?³żĖć?ĄŪ\ .* ./ .^ ”ń ÜÖĆ?¹²ŅŪÜÖĆ .' ' ”ń ÄꊊĮŠ¤Č„Ł„Æ„Č„ė¤Ī·e ( , ) Ab c/A ”ń ŅŖĖŲ¤“¤Č¤ĪÕĄķŃŻĖć & | Tip ÄꊊĮŠ×ŌĢå¤ņÓĖ椷¤æ¤¤ ¤Č¤¤Ļ, invévŹż¤ņŹ¹¤¦. Ąż) >> B = inv(A);
- 30. ŠŠĮŠ¤ĪŅŖĖŲ¤Ų¤Ī„¢„Æ„»„¹ Č”¤ź³ö¤·¤ā“śČė¤ā¤Ē¤¤Ž¤¹ CŃŌÕZ¤ĪÅäĮŠ¤Ē¤¤¤¦ a[0] ¤Ļ, MATLAB¤Ē¤Ļ a(1) ¤Ē¤¹ ”ń ŠŠĮŠ¤ĪöŗĻ¤Ļ, A(1,2) ¤Č¤¹¤ė¤³¤Č¤Ē ¤ņÖø¤»¤ė ”ń ¹ ģ¤ņČ”¤ź³ö¤·¤æ¤¤¤Č¤¤Ļ¹ ģ„Ł„Æ„Č„ė¤ņŹ¹¤¦ A(1:3, :) A¤Ī1”«3ŠŠÄæ£¬Č«ĮŠ(:)¤ņČ”¤ź³ö¤· ŠŠ·¬ŗÅ ĮŠ·¬ŗÅ Tip ¹ ģ„Ł„Æ„Č„ė¤Ē¤Ź¤Æ¤Ę¤ā OK. Öø¶Ø¤·¤æķ·¬¤É¤Ŗ¤ź ¤ĖČ”¤ź³ö¤·/“śČė¤Ē¤¤ė. Ąż) >> A([1 3], [1 4])
- 31. ŠŠĮŠ¤Ī½YŗĻ?¼Ó¹¤ Tip „Ö„ķ„Ć„ÆŠŠĮŠ¤ĪøŠŅ¤Ē, ŠŠĮŠ¤ä„Ł„Æ„Č„ė¤ņ½YŗĻ ¤Ē¤¤ė Tip clear„³„Ž„ó„ɤĒ¶ØĮx¤·¤æ 䏿¤ņČ«¤Ę„Æ„ź„¢¤Ē¤¤ė ŠŠĮŠ¤Ī¼Ó¹¤¤ĖŹ¹¤¦évŹż¤ĪĄż ”ń repmat ŠŠĮŠ¤ņĄR¤ź·µ¤·¤æ¤ā¤Ī¤ņ×÷¤ė ”ń fliplr, flipud ×óÓŅ?ÉĻĻĀ·“Ü ”ń sort ŅŖĖŲ¤Ī„½©`„Č
- 32. Tips [Coffee Break] Ó¢ÕZ¤ņÕi¤į¤ė·½¤Ļ, UI ¤ČMathWorks¤Ī„¦„§ „Ö„µ„¤„ȤņÓ¢ÕZŌO¶Ø¤Ė ¤·¤æ·½¤¬¤ļ¤«¤ź¤ä¤¹¤¤ ¤«¤ā. ŅŖĖŲ¤“¤Č¤ĪŃŻĖć¤ņ¤¦¤Ž ¤ÆĄūÓƤ¹¤ė¤³¤Č¤ĒøßĖŁ ¤Ź„³©`„ɤņų¤±¤ė. http://blog.tokor.org/2017/12/17/rogy-Adv ent-Calendar-2017-%E3%80%8C%E3%81%8 6%E3%82%8F%E3%81%A3%E2%80%A6%E3 %82%8F%E3%81%9F%E3%81%97%E3%81% AEMATLAB%E3%82%B3%E3%83%BC%E3%83 %89%E3%80%81%E9%81%85%E3%81%99% E3%81%8E%E2%80%A6%EF%BC%9F%E3%80 %8D/ „³©`„Ē„£„ó„°ÓĆ„Õ„©„ó „Ȥņ„¤„ó„¹„Č©`„ė¤¹¤ė ¤ČÕi¤ß¤ä¤¹¤Æ¤Ź¤ė. ¤Ŗ¤¹¤¹¤į: - Ricty Discord - Cica
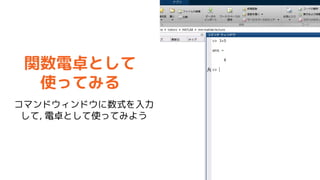
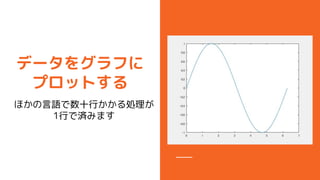
- 34. „Ē©`„æ¤Ī„ׄķ„Ć„Č Ąż) >> x = 0:0.01:pi*2; >> y = sin(x); >> plot(x, y); Tip »ł±¾¤Ļplot„³„Ž„ó„É! Ź¹¤¤·½¤¬Ń}ėj¤Ź¤Ī¤Ē„Ų„ė „פņÕi¤ā¤¦ "matlab plot"¤Ē „°„°¤ė¤Č³ö¤Ę¤Æ¤ė Tip „É„„å„į„ó„Ę©`„·„ē„ó¤Ļ „°„°¤ė¤«doc„³„Ž„ó„ɤĒ ±ķŹ¾¤¹¤ė
- 37. „É„„å„į„ó„Ę©`„·„ē„ó¤ĪÕi¤ß·½ Ō¼¤ŹĒéó(ųŹ½?ŠĶ?„µ„¤„ŗ ¤Ź¤É)¤¬“_ÕJ¤Ē¤¤ė£” Ąż) >> x = 0:0.01:pi*2; >> y = sin(x); >> plot(x, y, 'r--');
- 38. „ׄķ„ƄȤĪŅ¤æÄæ¤Ī¾¼Æ „³„Ž„ó„ɤņŹ¹ÓƤ¹¤ėöŗĻ ”ń „°„ź„Ć„É grid on grid off ”ń ŻS¤Ī¹ ģ?„é„Ł„ė?ÄæŹ¢¤ź xlim xlabel xticks ylim ... ”ń ·²Ąż legend ”ń ¤½¤ĪĖū¤Ī„ׄķ„Ń„Ę„£¤ĪŌO¶Ø set get Tip évßB¤¹¤ėévŹż¤Ī„ź„¹„ȤĻ ¤³¤Ī„Ś©`„ø¤«¤é„«„Ę„“„ź ¤ņßxk¤¹¤ė¤ČŅ¤é¤ģ¤ė https://mathworks.co m/help/matlab/format ting-and-annotation.h tml
- 42. „¢„ø„§„ó„Ą ½ń»Ų¤ĪÄŚČŻ¤ĻŅŌĻĀ¤Ī3¤Ä¤Ē¤¹£® 1. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB/Simulink¤¬¤É¤Ī¤č¤¦¤Ė„Ž„¤„Æ„ķ „Ž„¦„¹¤ĪŃu×÷¤ĖŅŪĮ¢¤Ä¤«ÕhĆ÷¤·¤Ž¤¹£® 2. „³„Ž„ó„É„¦„£„ó„É„¦¤ĒŹ¹¤¦ ¤Ž¤ŗ¤Ļė×æ¤Č¤·¤ĘMATLAB¤ņŹ¹¤Ć¤Ę ¤ß¤Ž¤·¤ē¤¦£® 3. „¹„Æ„ź„ׄČ?évŹż¤ņ×÷¤ė ±¾øńµÄ¤Ź„ׄķ„°„é„ß„ó„°¤ņŠŠ¤¦¤æ¤į¤Ī »łµA¤ņѧ¤Ó¤Ž¤¹£®
- 44. „¹„Æ„ź„ׄȤĒ¤č¤ÆŹ¹ÓƤ¹¤ė„³„Ž„ó„É ³õĘŚ»ÆĻµ¤Ī„³„Ž„ó„ɤņ„Õ„”„¤„ėĆ°ī^¤Ėų¤Æ¤³¤Č¤ņĶĘX ”ń „ļ©`„Æ„¹„Ś©`„¹äŹż¤ņĻūČ„¤¹¤ė clear ”ń „ׄķ„ƄȤņ¤¹¤Ł¤Ęé]¤ø¤ė close all ”ń „³„Ž„ó„É„¦„£„ó„É„¦¤ņ„Æ„ź„¢¤¹¤ė clc Tip MATLAB¤Ē¤Ļ£¬„¹„Æ„ź„× „ȤĪgŠŠ¤“¤Č¤Ė䏿¤Ļ³õ ĘŚ»Æ¤µ¤ģ¤Ź¤¤£® »ł±¾µÄ¤Ė¤Ļclear„³„Ž„ó„É ¤Ē䏿¤ņĻūČ„¤·¤Ę¤«¤éI Ąķ¤ņé_Ź¼¤¹¤ė¤³¤Č¤ņĶĘX ¤¹¤ė£®
- 46. ifĪÄ Tip any, all évŹż¤ņŹ¹¤¦¤Č£¬ „Ł„Æ„Č„ė¤ĪŅŖĖŲ¤Ī any: ÉŁ¤Ź¤Æ¤Č¤ā1¤Ä all: ¤¹¤Ł¤Ę ¤¬Ģõ¼ž¤ņŗ¤æ¤·¤Ę¤¤¤ė¤« ¤ņÅŠ¶Ø¤Ē¤¤ė£® if Ģõ¼žŹ½ ... elseif Ģõ¼žŹ½ ... else ... end MATLAB¤Ē¤ĻĄØ»”¤Ī“ś¤ļ¤ź¤Ėend¤ņŹ¹¤¦
- 47. forĪÄ Tip ¹ ģ„Ł„Æ„Č„ėŅŌĶā¤Ė¤ā£¬ ČĪŅā¤Ī„Ł„Æ„Č„ė¤ņÖø¶Ø¤Ē ¤¤ė£® PHP¤äJavaScript¤Ė¤¢¤ė foreach¤Ė½ü¤¤øŠ¤ø£® for „«„¦„ó„æ䏿 = „Ł„Æ„Č„ė ... end CŃŌÕZµČ¤ČĮ÷x¤¬“ó¤¤Æ®¤Ź¤ė n = 0; for k = 1:5 n = n + k^2; end Ąż)
- 48. ¤½¤ĪĖū¤ĪÖĘÓłĪÄ ¤¢¤Č¤Ļ“óĢåCŃŌÕZµČ¤ČĶ¬¤ø ”ń while ”ń switch ~ case ”ń try ~ catch ”ń break, continue, return
- 49. g¼ł¤·¤Ę¤ß¤ė „ķ„°¤ĪæÉŅ»Æ¤ņĄż¤Ė„¹„Æ„ź„ׄȤņ ×÷³É¤·¤Ę¤ß¤č¤¦ ½ń»Ų¤ĪÄæĖ ”ń x, y׳Ė¤ĪrĻµĮŠ¤ņ¤½¤ģ¤¾¤ģ„ׄķ„Ć„Č ”ń xy„ׄķ„Ć„Č ”ń ÄæĖ¤ČĶĘ¶Ø¤Īxy„ׄķ„ƄȤĪ±ČŻ^
- 51. Step 1. „Ē©`„æ¤ĪÕi¤ßŽz¤ß x, y, ¦Č ÄæĖ x, y, ¦Č ĶĘ¶Ø rég
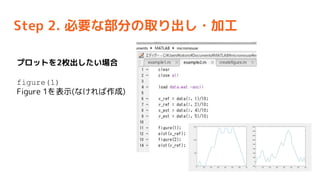
- 53. Step 2. ±ŲŅŖ¤Ź²æ·Ö¤ĪČ”¤ź³ö¤·?¼Ó¹¤ „ׄķ„ƄȤņ2ƶ³ö¤·¤æ¤¤öŗĻ figure(1) Figure 1¤ņ±ķŹ¾(¤Ź¤±¤ģ¤Š×÷³É)
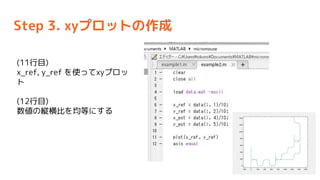
- 54. Step 3. xy„ׄķ„ƄȤĪ×÷³É (11ŠŠÄæ) x_ref, y_ref ¤ņŹ¹¤Ć¤Ęxy„ׄķ„Ć „Č (12ŠŠÄæ) Źż¤Īækŗį±Č¤ņ¾łµČ¤Ė¤¹¤ė
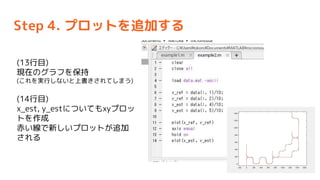
- 55. Step 4. „ׄķ„ƄȤņ×·¼Ó¤¹¤ė (13ŠŠÄæ) ¬FŌŚ¤Ī„°„é„Õ¤ņ±£³Ö (¤³¤ģ¤ņgŠŠ¤·¤Ź¤¤¤ČÉĻų¤¤µ¤ģ¤Ę¤·¤Ž¤¦) (14ŠŠÄæ) x_est, y_est¤Ė¤Ä¤¤¤Ę¤āxy„ׄķ„Ć „Ȥņ×÷³É ³ą¤¤¾¤ĒŠĀ¤·¤¤„ׄķ„ƄȤ¬×·¼Ó ¤µ¤ģ¤ė
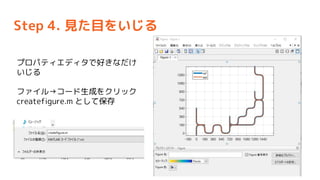
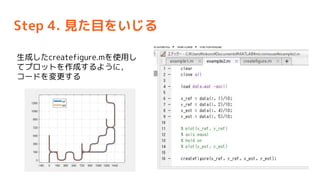
- 56. Step 4. Ņ¤æÄæ¤ņ¤¤¤ø¤ė „ׄķ„Ń„Ę„£„Ø„Ē„£„æ¤ĒŗƤ¤Ź¤Ą¤± ¤¤¤ø¤ė „Õ„”„¤„ė”ś„³©`„ÉÉś³É¤ņ„Æ„ź„Ć„Æ createfigure.m ¤Č¤·¤Ę±£“ę
- 57. Step 4. Ņ¤æÄæ¤ņ¤¤¤ø¤ė Éś³É¤·¤æcreatefigure.m¤ņŹ¹ÓƤ· ¤Ę„ׄķ„ƄȤņ×÷³É¤¹¤ė¤č¤¦¤Ė£¬ „³©`„ɤņäøü¤¹¤ė
- 60. „¢„ø„§„ó„Ą ½ń»Ų¤ĪÄŚČŻ¤ĻŅŌĻĀ¤Ī3¤Ä¤Ē¤¹£® 1. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB/Simulink¤¬¤É¤Ī¤č¤¦¤Ė„Ž„¤„Æ„ķ „Ž„¦„¹¤ĪŃu×÷¤ĖŅŪĮ¢¤Ä¤«ÕhĆ÷¤·¤Ž¤¹£® 2. „³„Ž„ó„É„¦„£„ó„É„¦¤ĒŹ¹¤¦ ¤Ž¤ŗ¤Ļė×æ¤Č¤·¤ĘMATLAB¤ņŹ¹¤Ć¤Ę ¤ß¤Ž¤·¤ē¤¦£® 3. „¹„Æ„ź„ׄČ?évŹż¤ņ×÷¤ė ±¾øńµÄ¤Ź„ׄķ„°„é„ß„ó„°¤ņŠŠ¤¦¤æ¤į¤Ī »łµA¤ņѧ¤Ó¤Ž¤¹£®
- 65. ²Ń“”°Õ³¢“”µž/³§¾±³¾³Ü±ō¾±²Ō°ģ¤Č¤Ļ? MATLAB æĘѧ?¼¼ŠgÓĖć¤ĖĢŲ»Æ¤·¤æ„ׄķ„°„é„ß„ó„° ŃŌÕZ?é_°kh¾³. ĢŲÕ ? ŠŠĮŠ?„Ł„Æ„Č„ėÓĖć¤ņĖŹ×°ä ? ĮµĆ¤·¤ä¤¹¤¤ŃŌÕZŹĖ ? ŲNø»¤ŹĖŹévŹż?„Ä©`„ė„Ü„Ć„Æ„¹¤Ē ±¾Ł|µÄ¤Ē¤Ź¤¤g×°¤ĪŹÖég¤ņŹ”¤±¤ė Simulink „Ö„ķ„Ć„Æ¾ķ¤ņ„Ł©`„¹¤Ė¤·¤æ„·„ß„å„ģ©` „·„ē„󄽄ՄČ. ĢŲÕ ? „Ö„ķ„Ć„Æ¤ņ¤Ä¤Ź¤¤¤Ē„ׄķ„°„é„ß„ó„° ? „·„ß„å„ģ©`„·„ē„ó¤Čg×°¤ņŅ»ĄØ¤Ēé_°k ? C/C++¤Ī„½©`„¹„³©`„ɤņ„Ö„ķ„Ć„Æ¾ķ ¤«¤éÉś³É¤Ē¤¤ė(„³©`„ÉÉś³É)