

















































![[Probability for machine learning]](https://cdn.slidesharecdn.com/ss_thumbnails/probabilityformachinelearning-180726131331-thumbnail.jpg?width=560&fit=bounds)
More Related Content
Similar to Multinomial classification and application of ML (20)
Multinomial classification and application of ML
- 1. Machine/Deep Learning with Theano Softmax classification : Multinomial classification Application & Tips : Learning rate, data preprocessing, overfitting Deep Neural Nets for Everyone
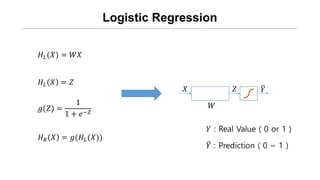
- 3. Logistic Regression ØÉ╗ØÉ┐(Øæŗ) = ØæŖØæŗ ØÉ╗ØÉ┐ Øæŗ = ØæŹ Øæö(ØæŹ) = 1 1 + ØæÆŌłÆØæŹ ØÉ╗ Øæģ Øæŗ = Øæö(ØÉ╗ØÉ┐(Øæŗ)) Øæŗ ØæŖ ØæŹ Øæī Øæī : Prediction ( 0 ~ 1 ) Øæī : Real Value ( 0 or 1 )
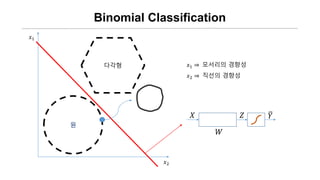
- 4. Binomial Classification ņÖ╝ņ¬ĮņØś ĻĘĖļ”╝ņØĆ ņøÉ ņØ╝Ļ╣ī? yes/no
- 5. Binomial Classification Øæź1 ŌćÆ ļ¬©ņä£ļ”¼ņØś Ļ▓ĮĒ¢źņä▒ Øæź2 ŌćÆ ņ¦üņäĀņØś Ļ▓ĮĒ¢źņä▒ Øæź1 Øæź2 ņøÉ Øæŗ ØæŖ ØæŹ Øæī ļŗżĻ░üĒśĢ
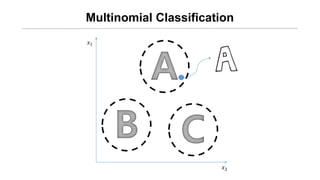
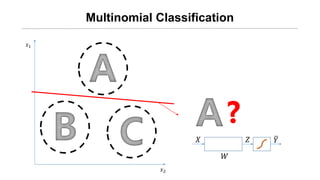
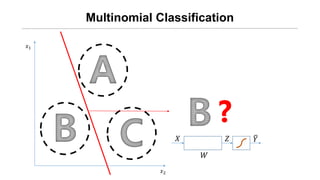
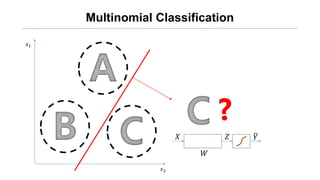
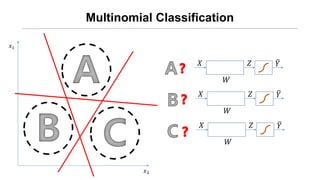
- 6. Multinomial Classification ņÖ╝ņ¬ĮņØś ĻĘĖļ”╝ņØĆ A/B/C ņżæ ļ¼┤ņŚćņØ╝Ļ╣ī?
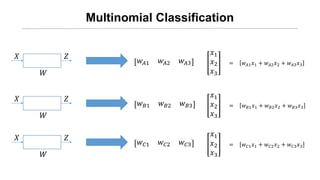
- 11. Øæź1 Øæź2 Multinomial Classification Øæŗ ØæŖ ØæŹ Øæī Øæŗ ØæŖ ØæŹ Øæī Øæŗ ØæŖ ØæŹ Øæī
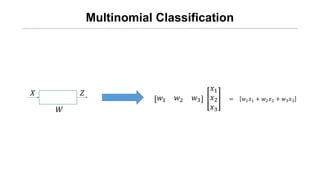
- 12. Multinomial Classification Øæŗ ØæŖ ØæŹ Øæż1 Øæż2 Øæż3 Øæź1 Øæź2 Øæź3 = Øæż1 Øæź1 + Øæż2 Øæź2 + Øæż3 Øæź3
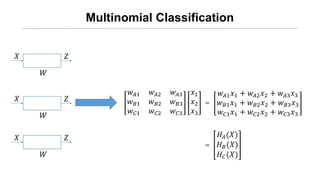
- 13. Multinomial Classification Øæŗ ØæŖ ØæŹ Øæż ØÉ┤1 Øæż ØÉ┤2 Øæż ØÉ┤3 Øæź1 Øæź2 Øæź3 = Øæż ØÉ┤1 Øæź1 + Øæż ØÉ┤2 Øæź2 + Øæż ØÉ┤3 Øæź3 Øæŗ ØæŖ ØæŹ Øæż ØÉĄ1 Øæż ØÉĄ2 Øæż ØÉĄ3 Øæź1 Øæź2 Øæź3 = Øæż ØÉĄ1 Øæź1 + Øæż ØÉĄ2 Øæź2 + Øæż ØÉĄ3 Øæź3 Øæŗ ØæŖ ØæŹ Øæż ØÉČ1 Øæż ØÉČ2 Øæż ØÉČ3 Øæź1 Øæź2 Øæź3 = Øæż ØÉČ1 Øæź1 + Øæż ØÉČ2 Øæź2 + Øæż ØÉČ3 Øæź3
- 14. Multinomial Classification Øæŗ ØæŖ ØæŹ Øæż ØÉ┤1 Øæź1 + Øæż ØÉ┤2 Øæź2 + Øæż ØÉ┤3 Øæź3 Øæż ØÉĄ1 Øæź1 + Øæż ØÉĄ2 Øæź2 + Øæż ØÉĄ3 Øæź3 Øæż ØÉČ1 Øæź1 + Øæż ØÉČ2 Øæź2 + Øæż ØÉČ3 Øæź3 Øæŗ ØæŖ ØæŹ Øæź1 Øæź2 Øæź3 = Øæŗ ØæŖ ØæŹ Øæż ØÉ┤1 Øæż ØÉ┤2 Øæż ØÉ┤3 Øæż ØÉĄ1 Øæż ØÉĄ2 Øæż ØÉĄ3 Øæż ØÉČ1 Øæż ØÉČ2 Øæż ØÉČ3 ØÉ╗ØÉ┤(Øæŗ) ØÉ╗ ØÉĄ(Øæŗ) ØÉ╗ ØÉČ(Øæŗ) =
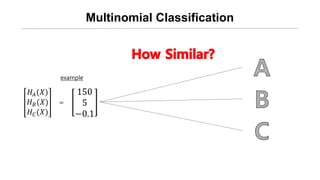
- 15. Multinomial Classification ØÉ╗ØÉ┤(Øæŗ) ØÉ╗ ØÉĄ(Øæŗ) ØÉ╗ ØÉČ(Øæŗ) 150 5 ŌłÆ0.1 example =
- 16. Multinomial Classification : Softmax Function Score Probability Øæ» Øæ© Øæ┐ = ØÆü Øæ© Øæ» Øæ® Øæ┐ = ØÆü Øæ® Øæ» Øæ¬ Øæ┐ = ØÆü Øæ¬ ØÆĆ Øæ© ØÆĆ Øæ® ØÆĆ Øæ¬ ØÆöØÆÉØÆćØÆĢØÆÄØÆéØÆÖ(ØÆüØÆŖ) = ØÆå ØÆü ØÆŖ ØÆŖ ØÆå ØÆü ØÆŖ (2) ØÆŖ ØÆĆØÆŖ = ؤÅ(1) Ø¤Ä Ōēż ØÆĆØÆŖ Ōēż ؤÅ
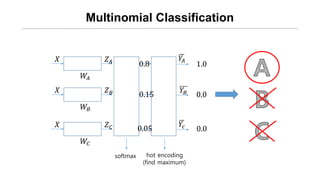
- 17. Multinomial Classification Øæŗ ØæŖØÉ┤ ØæŹ ØÉ┤ Øæŗ ØæŖØÉĄ ØæŹ ØÉĄ Øæŗ ØæŖØÉČ ØæŹ ØÉČ softmax hot encoding (find maximum) 1.0 0.0 0.0 ØæīØÉĄ ØæīØæÉ ØæīØÉ┤ 0.8 0.15 0.05
- 18. Cost Function Cross Entropy Function
- 19. Entropy Function ØÉ╗ ØæØ = ŌłÆ ØæØ(Øæź) log ØæØ(Øæź) ŌĆó ĒÖĢļźĀ ļČäĒż p ņŚÉ ļŗ┤ĻĖ┤ ļČłĒÖĢņŗżņä▒ņØä ļéśĒāĆļé┤ļŖö ņ¦ĆĒæ£ ŌĆó ņØ┤ Ļ░ÆņØ┤ Ēü┤ ņłśļĪØ ņØ╝ņĀĢĒĢ£ ļ░®Ē¢źņä▒Ļ│╝ ĻĘ£ņ╣Öņä▒ņØ┤ ņŚåļŖö chaos ŌĆó pļØ╝ļŖö ļīĆņāüņØä Ēæ£ĒśäĒĢśĻĖ░ņ£äĒĢ┤ ĒĢäņÜöĒĢ£ ņĀĢļ│┤ļ¤ē(bit)
- 20. Cross Entropy Function ØÉ╗ ØæØ, Øæ× = ŌłÆ ØæØ(Øæź) log Øæ×(Øæź) ŌĆó ļæÉ ĒÖĢļźĀ ļČäĒż p, q ņé¼ņØ┤ņŚÉ ņĪ┤ņ×¼ĒĢśļŖö ņĀĢļ│┤ļ¤ēņØä Ļ│äņé░ĒĢśļŖö ļ░®ļ▓Ģ ŌĆó p->qļĪ£ ņĀĢļ│┤ļź╝ ļ░öĻŠĖĻĖ░ ņ£äĒĢ┤ ĒĢäņÜöĒĢ£ ņĀĢļ│┤ļ¤ē(bit)
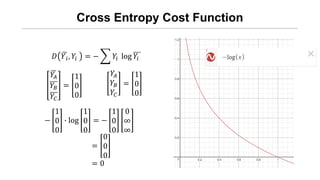
- 21. Cross Entropy Cost Function Øæŗ ØæŖØÉ┤ ØæŹ ØÉ┤ Øæŗ ØæŖØÉĄ ØæŹ ØÉĄ Øæŗ ØæŖØÉČ ØæŹ ØÉČ ØæīØÉ┤ ØæīØÉĄ ØæīØæÉ Øæī : Prediction ( 0 ~ 1 ) Øæī : Real Value ( 0 or 1 ) ØÉĘ ØæīØæ¢, ØæīØæ¢ = ŌłÆ ØæīØæ¢ log ØæīØæ¢
- 22. Cross Entropy Cost Function ØæīØÉ┤ ØæīØÉĄ ØæīØÉČ = 1 0 0 ØæīØÉ┤ ØæīØÉĄ ØæīØÉČ = 1 0 0 ŌłÆ 1 0 0 ŌłÖ log 1 0 0 = ŌłÆ 1 0 0 0 Ōł× Ōł× = 0 0 0 = 0 ØÉĘ ØæīØæ¢, ØæīØæ¢ = ŌłÆ ØæīØæ¢ log ØæīØæ¢
- 23. Cross Entropy Cost Function ØÉĘ ØæīØæ¢, Øæī Øæ¢ = ŌłÆ ØæīØæ¢ log ØæīØæ¢ ØæīØÉ┤ ØæīØÉĄ ØæīØÉČ = 1 0 0 ØæīØÉ┤ ØæīØÉĄ ØæīØÉČ = 0 1 0 ŌłÆ 0 1 0 ŌłÖ log 1 0 0 = ŌłÆ 1 0 0 0 Ōł× Ōł× = 0 ŌłÆŌł× 0 = ŌłÆŌł×
- 24. Logistic Cost VS Cross Entropy binomial classification ņØś Ļ▓ĮņÜ░ Ļ░üĻ░ü ņśżņ¦ü 2Ļ░Ćņ¦Ć Ļ▓ĮņÜ░ņØś Real DataņÖĆ H(x) Ļ░ÆņØ┤ ļéśņś¼ ņłś ņ׳ļŗż. 0 1 1 0 ņ£ä Ē¢ēļĀ¼ņØĆ ļŗżņØīĻ│╝ Ļ░ÖņØ┤ Ēæ£Ēśä ĒĢĀ ņłś ņ׳ļŗż. ØÉ╗(Øæź) 1 ŌłÆ ØÉ╗(Øæź) ØÉ╗ Øæź , Øæ” 0 1 Øæ” 1 ŌłÆ Øæ”
- 25. Logistic Cost VS Cross Entropy Cross Entropy Cost FunctionņŚÉ ļīĆņ×ģĒĢśļ®┤ ØÉ╗ ØÉ╗(Øæź), Øæ” = ŌłÆ Øæ” 1 ŌłÆ Øæ” ŌłÖ log ØÉ╗(Øæź) 1 ŌłÆ ØÉ╗(Øæź) = ŌłÆ Øæ”log ØÉ╗ Øæź 1 ŌłÆ Øæ” log(1 ŌłÆ ØÉ╗ Øæź ) = ŌłÆØæ” log ØÉ╗ Øæŗ ŌłÆ (1 ŌłÆ Øæ”)log(1 ŌłÆ ØÉ╗ Øæź ) = ØÉČ(ØÉ╗ Øæź , Øæ”)
- 26. Cross Entropy Cost Function ØÉ┐ = 1 Øæü Øæø ØÉĘ Øæø Øæī, Øæī = ŌłÆ 1 Øæü ØæīØæ¢log ØæīØæ¢ N Ļ░£ņØś training set ņŚÉ ļīĆĒĢ£ CostļōżņØś ĒĢ®
- 27. Application & Tips Learning Rate Data Preprocessing Overshooting
- 28. Gradient Descent Function ØæŖ = ØæŖ ŌłÆ Øø╝ Ø£Ģ Ø£ĢØæŖ ØÉČØæ£ØæĀØæĪ(ØæŖ) Learning Rate
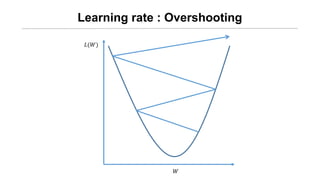
- 29. Learning rate : Overshooting ØÉ┐(ØæŖ) ØæŖ
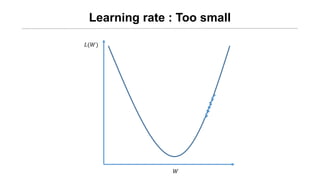
- 30. Learning rate : Too small ØÉ┐(ØæŖ) ØæŖ
- 32. Data Preprocessing Øæż1 Øæż2 ØæŖ = ØæŖ ŌłÆ Øø╝ Ø£Ģ Ø£ĢØæŖ ØÉČØæ£ØæĀØæĪ(ØæŖ) Øø╝ Ļ░Ć ļ│ĆĒĢśļ®┤ņä£ Ļ░ü weight Ļ░ÆļōżņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢źņØ┤ ļŗżļź╝ ļĢī ņĀüņĀłĒĢ£ Learning rateņØä ņ░ŠĻĖ░Ļ░Ć Ēלļōżņ¢┤ņ¦ä ļŗż.
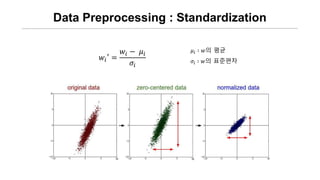
- 33. Data Preprocessing : Standardization ØæżØæ¢ŌĆ▓ = ØæżØæ¢ ŌłÆ Ø£ćØæ¢ Ø£ÄØæ¢ Ø£ćØæ¢ ŌłČ ØæżņØś ĒÅēĻĘĀ Ø£ÄØæ¢ ŌłČ ØæżņØś Ēæ£ņżĆĒÄĖņ░©
- 34. Overfitting ŌĆó training dataņŚÉ Ļ│╝ļÅäĒĢśĻ▓ī ņĄ£ņĀüĒÖö ļÉśļŖö Ēśäņāü ŌĆó real dataņŚÉ ļīĆĒĢ┤ņäĀ ņל ļÅÖņ×æĒĢśņ¦Ć ņĢŖļŖöļŗż.
- 36. Overfitting ŌĆó ļ¦ÄņØĆ ņ¢æņØś training dataļĪ£ ĒĢÖņŖĄ ņŗ£Ēé©ļŗż. ŌĆó feature(ØæźØæ¢)ņØś Ļ░£ņłśļź╝ ņżäņØĖļŗż. ŌĆó Regularization Solution:
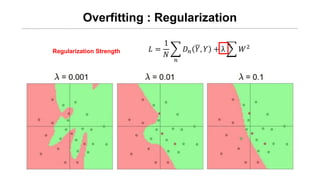
- 37. Overfitting : Regularization ØÉ┐ = 1 Øæü Øæø ØÉĘ Øæø Øæī, Øæī + ╬╗ ØæŖ2 ŌĆó weightĻ░Ć ļäłļ¼┤ Ēü░ Ļ░ÆņØä Ļ░Ćņ¦Ćņ¦Ć ņĢŖļÅäļĪØ ĒĢ£ļŗż. => Cost ĒĢ©ņłśĻ░Ć ĻĄ┤Ļ│ĪņØ┤ ņŗ¼ĒĢśņ¦Ć ņĢŖļÅäļĪØ ņĪ░ņĀĢĒĢ£ļŗż. Regularization Strength
- 38. Overfitting : Regularization ØÉ┐ = 1 Øæü Øæø ØÉĘ Øæø Øæī, Øæī + ╬╗ ØæŖ2 Regularization Strength
- 39. Application & Tips Learning and Test data sets
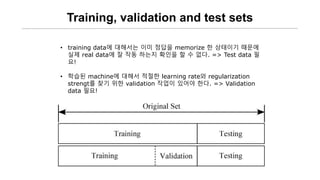
- 40. Training, validation and test sets ŌĆó training dataņŚÉ ļīĆĒĢ┤ņä£ļŖö ņØ┤ļ»Ė ņĀĢļŗĄņØä memorize ĒĢ£ ņāüĒā£ņØ┤ĻĖ░ ļĢīļ¼ĖņŚÉ ņŗżņĀ£ real dataņŚÉ ņל ņ×æļÅÖ ĒĢśļŖöņ¦Ć ĒÖĢņØĖņØä ĒĢĀ ņłś ņŚåļŗż. => Test data ĒĢä ņÜö! ŌĆó ĒĢÖņŖĄļÉ£ machineņŚÉ ļīĆĒĢ┤ņä£ ņĀüņĀłĒĢ£ learning rateņÖĆ regularization strengtļź╝ ņ░ŠĻĖ░ ņ£äĒĢ£ validation ņ×æņŚģņØ┤ ņ׳ņ¢┤ņĢ╝ ĒĢ£ļŗż. => Validation data ĒĢäņÜö!
- 41. Online Learning Data Model ŌĆó ļäłļ¼┤ ļ¦ÄņØĆ ņ¢æņØś ļŹ░ņØ┤Ēä░ Ļ░Ć ņ׳ņØä ļĢī, ļČäĒĢĀĒĢśņŚ¼ ļéśļłäņ¢┤ ĒĢÖņŖĄņŗ£Ēé©ļŗż. ŌĆó DataĻ░Ć ņ¦ĆņåŹņĀüņ£╝ļĪ£ ņ£Ā ņ×ģ ļÉśļŖö Ļ▓ĮņÜ░ ņé¼ņÜ®ļÉśĻĖ░ ļÅä ĒĢ£ļŗż.
Editor's Notes
- #20: ļÅäļ░ĢņØä ĒĢĀ ļĢī ĒÖĢļźĀ Ļ░ÆņØä ĻĖ░ļ░śņ£╝ļĪ£ Ļ░ÆņØä ļ¦×ņČśļŗżĻ│Ā ĒĢśņ×É ļÅÖņĀä ļŹśņ¦ĆĻĖ░ņØś Ļ▓ĮņÜ░ H, T 0.5 0.5 ņØ┤ļ»ĆļĪ£ ĒÖĢļźĀ ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ ļŗĄņØä ļ¦×ņČöļŖö ņØśļ»ĖĻ░Ć ņŚåļŗż. => ņŚöĒŖĖļĪ£Ēö╝ 1 ĒŖ╣ņĀĢ ļÅÖņĀäņØś Ļ▓ĮņÜ░ H, T 0.8, 0.2 ņØ┤ļØ╝Ļ│Ā ĒĢĀ ļĢī ņØ┤ ĒÖĢļźĀ ļŹ░ņØ┤Ēä░ļź╝ ĻĖ░ļ░śņ£╝ļĪ£ Hļź╝ ņäĀĒāØĒĢśļ®┤ ļŗĄņØä ļ¦×ņČ£ ĒÖĢļźĀņØ┤ ļåÆņĢäņ¦äļŗż. => ņŚöĒŖĖļĪ£Ēö╝Ļ░Ć ņ×æņĢäņ¦äļŗż. ņ”ē ļ¬©ļōĀ ĒÖĢļźĀņØś Ļ░ÆņØ┤ ļśæĻ░ÖņØä ļĢī ņŚöĒŖĖļĪ£Ēö╝ļŖö Ļ░Ćņן ļåÆĻ│Ā ĒŖ╣ņĀĢ ļŹ░ņØ┤Ēä░ņŚÉ ĒÖĢļźĀņØ┤ ņ╣śņżæ ļÉśņ¢┤ ņ׳ņØä ļĢī ņŚöĒŖĖļĪ£Ēö╝ļŖö ņ×æņĢäņ¦äļŗż.