



























![[ ņ×ÉļŻīņØś ļČäņäØ ]
ŌæĀ ļ¬®ņĀü : ņ¦æņØä ĒīöĻĖ░ ņøÉĒĢ©. ņĢīļ¦×ņØĆ Ļ░ĆĻ▓®ņØä ņ░ŠĻĖ░ ņøÉĒĢ©.
ŌæĪ Ļ│ĀļĀżĒĢĀ ļ│Ćņłś(feature) : ņ¦æņØś Ēü¼ĻĖ░(in square feet), ņ╣©ņŗżņØś Ļ░£ņłś, ņ¦æ Ļ░ĆĻ▓®](https://image.slidesharecdn.com/03-161011160648/85/03-linear-regression-39-320.jpg)

































![[Probability for machine learning]](https://cdn.slidesharecdn.com/ss_thumbnails/probabilityformachinelearning-180726131331-thumbnail.jpg?width=560&fit=bounds)
More Related Content
What's hot (20)
Similar to 03. linear regression (20)










![[GomGuard] ļē┤ļ¤░ļČĆĒä░ YOLO Ļ╣īņ¦Ć - ļöźļ¤¼ļŗØ ņĀäļ░śņŚÉ ļīĆĒĢ£ ņØ┤ņĢ╝ĻĖ░](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=560&fit=bounds)







03. linear regression
- 2. ņ¦Ćļé£ ņŗ£Ļ░ä.....Naive Bayes Classifier arg max Øæ” Øæā Øæź1, ŌĆ” , Øæź Øææ Øæ” Øæā(Øæ”) = arg max Øæ” Øæā ØæźØæ¢ Øæ” Øæā(Øæ”) Øææ Øæ¢=1 class Øæ” ņØś ļ░£ņāØ ĒÖĢļźĀĻ│╝ test setņŚÉņä£ class Øæ”ņØś labelņØä Ļ░Ćņ¦ä ļŹ░ņØ┤Ēä░ņØś ĒŖ╣ņä▒ ļ▓ĪĒä░ņØś ņøÉņåī ØæźØæ¢ (ļ¼Ėņä£ņØś ņśłņŚÉņä£ļŖö ļŗ©ņ¢┤) Ļ░Ć ļéśņś¼ ĒÖĢļźĀņØś Ļ│▒ ex) (I, love, you)Ļ░Ć spamņØĖņ¦Ć ņĢäļŗīņ¦Ć ņĢīĻĖ░ ņ£äĒĢ┤ņä£ļŖö, test setņŚÉņä£ spamņØ┤ ņ░©ņ¦ĆĒĢśļŖö ļ╣äņ£©Ļ│╝ spamņ£╝ļĪ£ labeling ļÉ£ ļ¼Ėņä£ņŚÉņä£ IņÖĆ loveņÖĆ youĻ░Ć ļ░£ņāØĒĢśļŖö ĒÖĢļźĀņØä ļ¬©ļæÉ Ļ│▒ĒĢ£ Ļ▓āĻ│╝, test setņŚÉņä£ hamņØ┤ ņ░©ņ¦ĆĒĢśļŖö ļ╣äņ£©Ļ│╝ hamņ£╝ļĪ£ labeling ļÉ£ ļ¼Ėņä£ņŚÉņä£ IņÖĆ loveņÖĆ youĻ░Ć ļ░£ņāØĒĢśļŖö ĒÖĢļźĀņØä ļ¬©ļæÉ Ļ│▒ĒĢ£ Ļ▓āņØä, ļ╣äĻĄÉĒĢ£ļŗż.
- 3. ņ¦Ćļé£ ņŗ£Ļ░ä ļ»Ėļ╣äĒ¢łļŹś ņĀÉ ļōż... 1. Laplacian Smoothing (appendix ņ░ĖĻ│Ā) 2. MLE / MAP 1
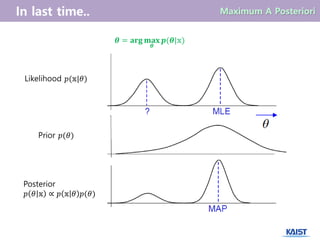
- 4. BayesŌĆÖ Rule ØæØ Ø£ā ØĢ® = ØæØ ØĢ® Ø£ā ØæØ(Ø£ā) ØæØ ØĢ® Ø£ā ØæØ(Ø£ā) posteriori (ņé¼Ēøä ĒÖĢļźĀ) likelihood (ņÜ░ļÅä Ļ░Æ) prior (ņé¼ņĀä ĒÖĢļźĀ) ņé¼Ēøä ĒÖĢļźĀ : Ļ┤Ćņ░░ Ļ░ÆļōżņØ┤ Ļ┤Ćņ░░ ļÉ£ ĒøäņŚÉ ļ¬©ņłś(parameter)ņØś ļ░£ņāØ ĒÖĢļźĀņØä ĻĄ¼ĒĢ£ļŗż. ņé¼ņĀä ĒÖĢļźĀ : Ļ┤Ćņ░░ Ļ░ÆļōżņØ┤ Ļ┤Ćņ░░ ļÉśĻĖ░ ņĀäņŚÉ ļ¬©ņłśņØś ļ░£ņāØ ĒÖĢļźĀņØä ĻĄ¼ĒĢ£ļŗż. ņÜ░ļÅä Ļ░Æ : ļ¬©ņłśņØś Ļ░ÆņØ┤ ņŻ╝ņ¢┤ņĪīņØä ļĢī Ļ┤Ćņ░░ Ļ░ÆļōżņØ┤ ļ░£ņāØĒĢĀ ĒÖĢļźĀ
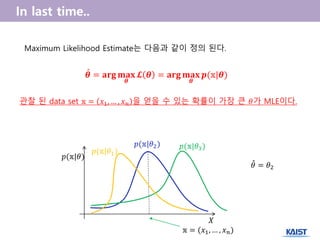
- 5. Maximum Likelihood Estimate ØĢ® = (Øæź1, ŌĆ” , Øæź Øæø) Øōø Ø£Į = ØÆæ ØĢ® Ø£Į ņÜ░ļÅä(likelihood)ļŖö ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀĢņØś ļÉ£ļŗż. ļ│Ćņłś(parameter) Ø£āĻ░Ć ņŻ╝ņ¢┤ņĪīņØä ļĢī, data set ØĢ® = (Øæź1, ŌĆ” , Øæź Øæø) (Ļ┤Ćņ░░ ļÉ£, observed) ļź╝ ņ¢╗ņØä ņłś ņ׳ļŖö(obtaining) ĒÖĢļźĀ ØæØ(ØĢ®|Ø£ā) Øæŗ Ø£āņØś ĒĢ©ņłś. Ø£āņØś pdfļŖö ņĢäļŗś. ØĢ® = (Øæź1, ŌĆ” , Øæź Øæø)
- 6. Maximum Likelihood EstimateļŖö ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀĢņØś ļÉ£ļŗż. Ļ┤Ćņ░░ ļÉ£ data set ØĢ® = Øæź1, ŌĆ” , Øæź Øæø ņØä ņ¢╗ņØä ņłś ņ׳ļŖö ĒÖĢļźĀņØ┤ Ļ░Ćņן Ēü░ Ø£āĻ░Ć MLEņØ┤ļŗż. ØæØ(ØĢ®|Ø£ā1) Øæŗ ØĢ® = (Øæź1, ŌĆ” , Øæź Øæø) Ø£Į = ØÉÜØɽØÉĀ ØÉ”ØÉÜØÉ▒ Ø£Į Øōø Ø£Į = ØÉÜØɽØÉĀ ØÉ”ØÉÜØÉ▒ Ø£Į ØÆæ(ØĢ®|Ø£Į)╠é ØæØ(ØĢ®|Ø£ā2) ØæØ(ØĢ®|Ø£ā3) ØæØ(ØĢ®|Ø£ā) Ø£ā = Ø£ā2 ╠é
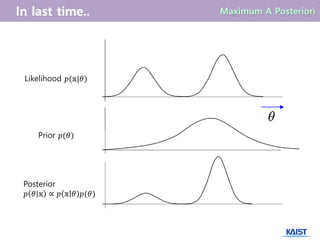
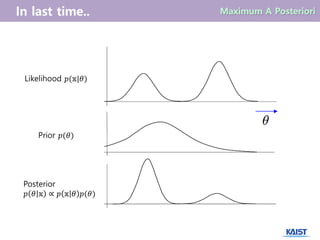
- 7. ņÜ░ļ”¼Ļ░Ć likelihood function ØæØ(ØĢ®|Ø£ā)ņÖĆ prior ØæØ(Ø£ā)ļź╝ ņĢī ļĢī, Bayes ruleņŚÉ ņØśĒĢśņŚ¼ posteriori functionņØś Ļ░ÆņØä ĻĄ¼ĒĢĀ ņłś ņ׳ļŗż. ØÆæ Ø£Į ØĢ® ŌłØ ØÆæ ØĢ® Ø£Į ØÆæ(Ø£Į) Maximum A Posteriori Estimate ØæØ Ø£ā ØĢ® = ØæØ ØĢ® Ø£ā ØæØ(Ø£ā) ØæØ ØĢ® Ø£ā ØæØ(Ø£ā) posteriori (ņé¼Ēøä ĒÖĢļźĀ) likelihood (ņÜ░ļÅä Ļ░Æ) prior (ņé¼ņĀä ĒÖĢļźĀ)
- 8. Likelihood ØæØ(ØĢ®|Ø£ā) Prior ØæØ(Ø£ā) Posterior ØæØ Ø£ā ØĢ® ŌłØ ØæØ ØĢ® Ø£ā ØæØ(Ø£ā)
- 9. Likelihood ØæØ(ØĢ®|Ø£ā) Prior ØæØ(Ø£ā) Posterior ØæØ Ø£ā ØĢ® ŌłØ ØæØ ØĢ® Ø£ā ØæØ(Ø£ā)
- 10. Ø£Į = ØÉÜØɽØÉĀ ØÉ”ØÉÜØÉ▒ Ø£Į ØÆæ(Ø£Į|ØĢ®) Likelihood ØæØ(ØĢ®|Ø£ā) Prior ØæØ(Ø£ā) Posterior ØæØ Ø£ā ØĢ® ŌłØ ØæØ ØĢ® Ø£ā ØæØ(Ø£ā)
- 11. Regression
- 12. ļéśļŖö Ēü░ ņŗĀļ░£ĒÜīņé¼ņØś CEOņØ┤ļŗż. ļ¦ÄņØĆ ņ¦ĆņĀÉļōżņØä Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŗż. ĻĘĖļ”¼Ļ│Ā ņØ┤ļ▓łņŚÉ ņāłļĪ£ņÜ┤ ņ¦ĆņĀÉņØä ļé┤Ļ│Ā ņŗČļŗż. ņ¢┤ļŖÉ ņ¦ĆņŚŁņŚÉ ļé┤ņĢ╝ ļÉĀĻ╣ī? ļé┤Ļ░Ć ņāłļĪ£ņÜ┤ ņ¦ĆņĀÉņØä ļé┤Ļ│Ā ņŗČņ¢┤ĒĢśļŖö ņ¦ĆņŚŁļōżņØś ņśłņāü ņłśņØĄļ¦ī ĒīīņĢģĒĢĀ ņłś ņ׳ņ£╝ļ®┤ Ēü░ ļÅäņøĆņØ┤ ļÉĀ Ļ▓āņØĖļŹ░! ļé┤Ļ░Ć Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö ņ×ÉļŻī(data)ļŖö Ļ░ü ņ¦ĆņĀÉņØś ņłśņØĄ(profits)Ļ│╝ Ļ░ü ņ¦ĆņĀÉņØ┤ ņ׳ļŖö ņ¦ĆņŚŁņØś ņØĖĻĄ¼ņłś(populations)ņØ┤ļŗż. ĒĢ┤Ļ▓░ņ▒ģ! Linear Regression! ņØ┤Ļ▓āņØä ĒåĄĒĢśņŚ¼, ņāłļĪ£ņÜ┤ ņ¦ĆņŚŁņØś ņØĖĻĄ¼ņłśļź╝ ņĢīĻ▓ī ļÉĀ Ļ▓ĮņÜ░, ĻĘĖ ņ¦ĆņŚŁņØś ņśłņāü ņłśņØĄņØä ĻĄ¼ ĒĢĀ ņłś ņ׳ļŗż. Example 1)
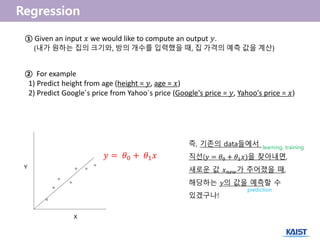
- 13. Example 2) ļéśļŖö ņ¦ĆĻĖł PittsburghļĪ£ ņØ┤ņé¼ļź╝ ņÖöļŗż ļéśļŖö Ļ░Ćņן ĒĢ®ļ”¼ņĀüņØĖ Ļ░ĆĻ▓®ņØś ņĢäĒīīĒŖĖļź╝ ņ¢╗ĻĖ░ ņøÉĒĢ£ļŗż. ĻĘĖļ”¼Ļ│Ā ļŗżņØīņØś ņĪ░Ļ▒┤ļōżņØĆ ļé┤Ļ░Ć ņ¦æņØä ņé¼ĻĖ░ ņ£äĒĢ┤ Ļ│ĀļĀżĒĢśļŖö Ļ▓āļōżņØ┤ļŗż. square-ft(ĒÅēļ░®ļ»ĖĒä░), ņ╣©ņŗżņØś ņłś, ĒĢÖĻĄÉ Ļ╣īņ¦ĆņØś Ļ▒░ļ”¼... ļé┤Ļ░Ć ņøÉĒĢśļŖö Ēü¼ĻĖ░ņÖĆ ņ╣©ņŗżņØś ņłśļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö ņ¦æņØś Ļ░ĆĻ▓®ņØĆ Ļ│╝ņŚ░ ņ¢╝ļ¦łņØ╝Ļ╣ī?
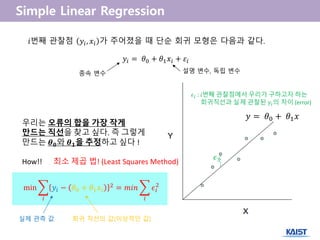
- 14. ŌæĀ Given an input Øæź we would like to compute an output Øæ”. (ļé┤Ļ░Ć ņøÉĒĢśļŖö ņ¦æņØś Ēü¼ĻĖ░ņÖĆ, ļ░®ņØś Ļ░£ņłśļź╝ ņ×ģļĀźĒ¢łņØä ļĢī, ņ¦æ Ļ░ĆĻ▓®ņØś ņśłņĖĪ Ļ░ÆņØä Ļ│äņé░) ŌæĪ For example 1) Predict height from age (height = Øæ”, age = Øæź) 2) Predict Google`s price from Yahoo`s price (Google's price = Øæ”, Yahoo's price = Øæź) Øæ” = Ø£ā0 + Ø£ā1 Øæź ņ”ē, ĻĖ░ņĪ┤ņØś dataļōżņŚÉņä£ ņ¦üņäĀ(Øæ” = Ø£ā0 + Ø£ā1 Øæź)ņØä ņ░ŠņĢäļé┤ļ®┤, ņāłļĪ£ņÜ┤ Ļ░Æ Øæź ØæøØæÆØæżĻ░Ć ņŻ╝ņ¢┤ņĪīņØä ļĢī, ĒĢ┤ļŗ╣ĒĢśļŖö Øæ”ņØś Ļ░ÆņØä ņśłņĖĪĒĢĀ ņłś ņ׳Ļ▓ĀĻĄ¼ļéś! learning, training prediction
- 15. Input : ņ¦æņØś Ēü¼ĻĖ░(Øæź1), ļ░®ņØś Ļ░£ņłś(Øæź2), ĒĢÖĻĄÉĻ╣īņ¦ĆņØś Ļ▒░ļ”¼(Øæź3),..... (Øæź1, Øæź2, ŌĆ” , Øæź Øæø) : ĒŖ╣ņä▒ ļ▓ĪĒä░ feature vector Output : ņ¦æ Ļ░Æ(Øæ”) ØÆÜ = Ø£Į Ø¤Ä + Ø£Į ؤŠØÆÖ Ø¤Å + Ø£Į Ø¤É ØÆÖ Ø¤É + Ōŗ» + Ø£Į ØÆÅ ØÆÖ ØÆÅ training setņØä ĒåĄĒĢśņŚ¼ ĒĢÖņŖĄ(learning)
- 17. Øæ”Øæ¢ = Ø£ā0 + Ø£ā1 ØæźØæ¢ + Ø£ĆØæ¢ Øæ¢ļ▓łņ¦Ė Ļ┤Ćņ░░ņĀÉ Øæ”Øæ¢, ØæźØæ¢ Ļ░Ć ņŻ╝ņ¢┤ņĪīņØä ļĢī ļŗ©ņł£ ĒÜīĻĘĆ ļ¬©ĒśĢņØĆ ļŗżņØīĻ│╝ Ļ░Öļŗż. Ø£¢3 Ø£¢Øæ¢ : Øæ¢ļ▓łņ¦Ė Ļ┤Ćņ░░ņĀÉņŚÉņä£ ņÜ░ļ”¼Ļ░Ć ĻĄ¼ĒĢśĻ│Āņ×É ĒĢśļŖö ĒÜīĻĘĆņ¦üņäĀĻ│╝ ņŗżņĀ£ Ļ┤Ćņ░░ļÉ£ Øæ”Øæ¢ņØś ņ░©ņØ┤ (error) ņÜ░ļ”¼ļŖö ņśżļźśņØś ĒĢ®ņØä Ļ░Ćņן ņ×æĻ▓ī ļ¦īļō£ļŖö ņ¦üņäĀņØä ņ░ŠĻ│Ā ņŗČļŗż. ņ”ē ĻĘĖļĀćĻ▓ī ļ¦īļō£ļŖö Ø£Į ؤÄņÖĆ Ø£Į ؤÅņØä ņČöņĀĢĒĢśĻ│Ā ņŗČļŗż ! How!! ņĄ£ņåī ņĀ£Ļ│▒ ļ▓Ģ! (Least Squares Method) min Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ 2 Øæ¢ = ØæÜØæ¢Øæø Ø£¢Øæ¢ 2 Øæ¢ Øæ” = Ø£ā0 + Ø£ā1 Øæź ņŗżņĀ£ Ļ┤ĆņĖĪ Ļ░Æ ĒÜīĻĘĆ ņ¦üņäĀņØś Ļ░Æ(ņØ┤ņāüņĀüņØĖ Ļ░Æ) ņóģņåŹ ļ│Ćņłś ņäżļ¬ģ ļ│Ćņłś, ļÅģļ”Į ļ│Ćņłś
- 18. min Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ 2 Øæ¢ = min Ø£¢Øæ¢ 2 Øæ¢ ņŗżņĀ£ Ļ┤ĆņĖĪ Ļ░Æ ĒÜīĻĘĆ ņ¦üņäĀņØś Ļ░Æ(ņØ┤ņāüņĀüņØĖ Ļ░Æ) ņ£äņØś ņŗØņØä ņĄ£ļīĆĒĢ£ ļ¦īņĪ▒ ņŗ£ĒéżļŖö Ø£ā0, Ø£ā1ņØä ņČöņĀĢĒĢśļŖö ļ░®ļ▓ĢņØĆ ļ¼┤ņŚćņØ╝Ļ╣ī? (ņØ┤ļ¤¼ĒĢ£ Ø£ā1, Ø£ā2ļź╝ Ø£ā1, Ø£ā2 ļØ╝Ļ│Ā ĒĢśņ×É.) - Normal Equation - Steepest Gradient Descent ╦å ╦å
- 19. What is normal equation? ĻĘ╣ļīĆ Ļ░Æ, ĻĘ╣ņåī Ļ░ÆņØä ĻĄ¼ĒĢĀ ļĢī, ņŻ╝ņ¢┤ņ¦ä ņŗØņØä ļ»ĖļČäĒĢ£ ĒøäņŚÉ, ļ»ĖļČäĒĢ£ ņŗØņØä 0ņ£╝ļĪ£ ļ¦īļō£ļŖö Ļ░ÆņØä ņ░ŠļŖöļŗż. min Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ 2 Øæ¢ ļ©╝ņĀĆ, Ø£ā0ņŚÉ ļīĆĒĢśņŚ¼ ļ»ĖļČäĒĢśņ×É. ŌłÆ Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ = 0 Øæ¢ Ø£Ģ Ø£ĢØ£ā0 Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ 2 Øæ¢ = ļŗżņØīņ£╝ļĪ£, Ø£ā1ņŚÉ ļīĆĒĢśņŚ¼ ļ»ĖļČäĒĢśņ×É. ŌłÆ Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ ØæźØæ¢ = 0 Øæ¢ Ø£Ģ Ø£ĢØ£ā1 Øæ”Øæ¢ ŌłÆ Ø£ā0 + Ø£ā1 ØæźØæ¢ 2 Øæ¢ = ņ£ä ņØś ļæÉ ņŗØņØä 0ņ£╝ļĪ£ ļ¦īņĪ▒ņŗ£ĒéżļŖö Ø£ā0, Ø£ā1ļź╝ ņ░Šņ£╝ļ®┤ ļÉ£ļŗż. ņØ┤ņ▓śļ¤╝ 2Ļ░£ņØś ļ»Ėņ¦ĆņłśņŚÉ ļīĆĒĢśņŚ¼, 2Ļ░£ņØś ļ░®ņĀĢņŗØ(system)ņØ┤ ņ׳ņØä ļĢī, ņÜ░ļ”¼ļŖö ņØ┤ systemņØä normal equation(ņĀĢĻĘ£ļ░®ņĀĢņŗØ)ņØ┤ļØ╝ ļČĆļźĖļŗż.
- 20. The normal equation form ØĢ®Øæ¢ = 1, ØæźØæ¢ Øæć , ╬ś = Ø£ā0, Ø£ā1 Øæć , ØĢ¬ = Øæ”1, Øæ”2, ŌĆ” , Øæ” Øæø Øæć , Øæŗ = 1 1 ŌĆ” Øæź1 Øæź2 ŌĆ” 1 Øæź Øæø , ØĢ¢ = (Ø£¢1, ŌĆ” , Ø£¢ Øæø) ļØ╝Ļ│Ā ĒĢśņ×É. ØĢ¬ = Øæŗ╬ś + ØĢ¢ Øæ”1 = Ø£ā0 + Ø£ā1 Øæź1 + Ø£¢1 Øæ”2 = Ø£ā0 + Ø£ā1 Øæź2 + Ø£¢2 ....... Øæ” ØæøŌłÆ1 = Ø£ā0 + Ø£ā1 Øæź ØæøŌłÆ1 + Ø£¢ ØæøŌłÆ1 Øæ” Øæø = Ø£ā0 + Ø£ā1 Øæź Øæø + Ø£¢ Øæø ØæøĻ░£ņØś Ļ┤ĆņĖĪ Ļ░Æ (ØæźØæ¢, Øæ”Øæ¢)ņØĆ ņĢäļלņÖĆ Ļ░ÖņØĆ ĒÜīĻĘĆ ļ¬©ĒśĢņØä Ļ░Ćņ¦äļŗżĻ│Ā Ļ░ĆņĀĢĒĢśņ×É. Øæ”1 Øæ”2 Øæ”3 ŌĆ” Øæ” Øæø = 1 1 1 ŌĆ” Øæź1 Øæź2 Øæź3 ŌĆ” 1 Øæź Øæø Ø£ā0 Ø£ā1 + Ø£¢1 Ø£¢2 Ø£¢3 ŌĆ” Ø£¢ Øæø
- 21. Ø£¢ØæŚ 2 Øæø ØæŚ=1 = ØĢ¢ Øæć ØĢ¢ = ØĢ¬ ŌłÆ Øæŗ╬ś Øæć (ØĢ¬ ŌłÆ Øæŗ╬ś) = ØĢ¬ Øæć ØĢ¬ ŌłÆ ╬ś Øæć Øæŗ Øæć ØĢ¬ ŌłÆ ØĢ¬ Øæć Øæŗ╬ś + ╬ś Øæć Øæŗ Øæć Øæŗ╬ś = ØĢ¬ Øæć ØĢ¬ ŌłÆ 2╬ś Øæć Øæŗ Øæć ØĢ¬ + ╬ś Øæć Øæŗ Øæć Øæŗ╬ś 1 by 1 Ē¢ēļĀ¼ņØ┤ļ»ĆļĪ£ ņĀäņ╣śĒ¢ēļĀ¼ņØś Ļ░ÆņØ┤ Ļ░Öļŗż! Ø£Ģ(ØĢ¢ Øæć ØĢ¢) Ø£Ģ╬ś = Ø¤Ä Ø£Ģ(ØĢ¢ Øæć ØĢ¢) Ø£Ģ╬ś = ŌłÆ2Øæŗ Øæć ØĢ¬ + 2Øæŗ Øæć Øæŗ╬ś = Ø¤Ä Øæŗ Øæć ØæŗØÜ» = Øæŗ Øæć ØĢ¬ ØÜ» = Øæŗ Øæć Øæŗ ŌłÆ1 Øæŗ Øæć ØĢ¬╦å ņĀĢĻĘ£ļ░®ņĀĢņŗØ ØĢ¬ = Øæŗ╬ś + ØĢ¢ ØĢ¢ = ØĢ¬ ŌłÆ Øæŗ╬ś Minimize Ø£¢ØæŚ 2 Øæø ØæŚ=1
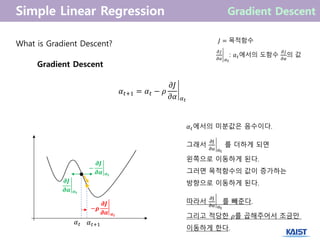
- 22. What is Gradient Descent? machine learningņŚÉņä£ļŖö ļ¦żĻ░£ ļ│Ćņłś(parameter, ņäĀĒśĢĒÜīĻĘĆņŚÉņä£ļŖö Ø£ā0, Ø£ā1)Ļ░Ć ņłśņŗŁ~ ņłśļ░▒ ņ░©ņøÉņØś ļ▓ĪĒä░ņØĖ Ļ▓ĮņÜ░Ļ░Ć ļīĆļČĆļČäņØ┤ļŗż. ļśÉĒĢ£ ļ¬®ņĀü ĒĢ©ņłś(ņäĀĒśĢĒÜīĻĘĆņŚÉņä£ļŖö ╬ŻØ£¢Øæ¢ 2 )Ļ░Ć ļ¬©ļōĀ ĻĄ¼Ļ░äņŚÉņä£ ļ»ĖļČä Ļ░ĆļŖźĒĢśļŗżļŖö ļ│┤ņןņØ┤ ĒĢŁņāü ņ׳ļŖö Ļ▓āļÅä ņĢäļŗłļŗż. ļö░ļØ╝ņä£ ĒĢ£ ļ▓łņØś ņłśņŗØ ņĀäĻ░£ļĪ£ ĒĢ┤ļź╝ ĻĄ¼ĒĢĀ ņłś ņŚåļŖö ņāüĒÖ®ņØ┤ ņĀüņ¦Ć ņĢŖĻ▓ī ņ׳ļŗż. ņØ┤ļ¤░ Ļ▓ĮņÜ░ņŚÉļŖö ņ┤łĻĖ░ ĒĢ┤ņŚÉņä£ ņŗ£ņ×æĒĢśņŚ¼ ĒĢ┤ļź╝ ļ░śļ│ĄņĀüņ£╝ļĪ£ Ļ░£ņäĀĒĢ┤ ļéśĻ░ĆļŖö ņłśņ╣śņĀü ļ░®ļ▓ĢņØä ņé¼ņÜ®ĒĢ£ļŗż. (ļ»ĖļČäņØ┤ ņé¼ņÜ® ļÉ©)
- 23. What is Gradient Descent? ņ┤łĻĖ░ĒĢ┤ Øø╝0 ņäżņĀĢ ØæĪ = 0 Øø╝ ØæĪĻ░Ć ļ¦īņĪ▒ņŖżļ¤Įļéś? Øø╝ ØæĪ+1 = Øæł Øø╝ ØæĪ ØæĪ = ØæĪ + 1 Øø╝ = Øø╝ ØæĪ ╦åNo Yes
- 24. What is Gradient Descent? Gradient Descent Ēśäņ×¼ ņ£äņ╣śņŚÉņä£ Ļ▓Įņé¼Ļ░Ć Ļ░Ćņן ĻĖēĒĢśĻ▓ī ĒĢśĻ░ĢĒĢśļŖö ļ░®Ē¢źņØä ņ░ŠĻ│Ā, ĻĘĖ ļ░®Ē¢źņ£╝ļĪ£ ņĢĮĻ░ä ņØ┤ļÅÖĒĢśņŚ¼ ņāłļĪ£ņÜ┤ ņ£äņ╣śļź╝ ņ×ĪļŖöļŗż. ņØ┤ļ¤¼ĒĢ£ Ļ│╝ņĀĢņØä ļ░śļ│ĄĒĢ©ņ£╝ļĪ£ņŹ© Ļ░Ćņן ļé«ņØĆ ņ¦ĆņĀÉ(ņ”ē ņĄ£ņĀĆ ņĀÉ)ņØä ņ░ŠņĢä Ļ░äļŗż. Gradient Ascent Ēśäņ×¼ ņ£äņ╣śņŚÉņä£ Ļ▓Įņé¼Ļ░Ć Ļ░Ćņן ĻĖēĒĢśĻ▓ī ņāüņŖ╣ĒĢśļŖö ļ░®Ē¢źņØä ņ░ŠĻ│Ā, ĻĘĖ ļ░®Ē¢źņ£╝ļĪ£ ņĢĮĻ░ä ņØ┤ļÅÖĒĢśņŚ¼ ņāłļĪ£ņÜ┤ ņ£äņ╣śļź╝ ņ×ĪļŖöļŗż. ņØ┤ļ¤¼ĒĢ£ Ļ│╝ņĀĢņØä ļ░śļ│ĄĒĢ©ņ£╝ļĪ£ņŹ© Ļ░Ćņן ļåÆņØĆ ņ¦ĆņĀÉ(ņ”ē ņĄ£ļīĆ ņĀÉ)ņØä ņ░ŠņĢä Ļ░äļŗż.
- 25. What is Gradient Descent? Gradient Descent Øø╝ ØæĪ+1 = Øø╝ ØæĪ ŌłÆ Ø£ī Ø£ĢØÉĮ Ø£ĢØø╝ Øø╝ ØæĪ ØÉĮ = ļ¬®ņĀüĒĢ©ņłś Ø£ĢØÉĮ Ø£ĢØø╝ Øø╝ ØæĪ : Øø╝ ØæĪņŚÉņä£ņØś ļÅäĒĢ©ņłś Ø£ĢØÉĮ Ø£ĢØø╝ ņØś Ļ░Æ Øø╝ ØæĪ Øø╝ ØæĪ+1 ŌłÆ ØØÅØæ▒ ØØÅØ£Č Ø£Č ØÆĢ ØØÅØæ▒ ØØÅØ£Č Ø£Č ØÆĢ Øø╝ ØæĪņŚÉņä£ņØś ļ»ĖļČäĻ░ÆņØĆ ņØīņłśņØ┤ļŗż. ĻĘĖļלņä£ Ø£ĢJ Ø£Ģ╬▒ ╬▒t ļź╝ ļŹöĒĢśĻ▓ī ļÉśļ®┤ ņÖ╝ņ¬Įņ£╝ļĪ£ ņØ┤ļÅÖĒĢśĻ▓ī ļÉ£ļŗż. ĻĘĖļ¤¼ļ®┤ ļ¬®ņĀüĒĢ©ņłśņØś Ļ░ÆņØ┤ ņ”ØĻ░ĆĒĢśļŖö ļ░®Ē¢źņ£╝ļĪ£ ņØ┤ļÅÖĒĢśĻ▓ī ļÉ£ļŗż. ļö░ļØ╝ņä£ Ø£ĢJ Ø£Ģ╬▒ ╬▒t ļź╝ ļ╣╝ņżĆļŗż. ĻĘĖļ”¼Ļ│Ā ņĀüļŗ╣ĒĢ£ Ø£īļź╝ Ļ│▒ĒĢ┤ņŻ╝ņ¢┤ņä£ ņĪ░ĻĖłļ¦ī ņØ┤ļÅÖĒĢśĻ▓ī ĒĢ£ļŗż. ŌłÆØØå ØØÅØæ▒ ØØÅØ£Č Ø£Č ØÆĢ
- 26. What is Gradient Descent? Gradient Descent Øø╝ ØæĪ+1 = Øø╝ ØæĪ ŌłÆ Ø£ī Ø£ĢØÉĮ Ø£ĢØø╝ Øø╝ ØæĪ Gradient Ascent Øø╝ ØæĪ+1 = Øø╝ ØæĪ + Ø£ī Ø£ĢØÉĮ Ø£ĢØø╝ Øø╝ ØæĪ ØÉĮ = ļ¬®ņĀüĒĢ©ņłś Ø£ĢØÉĮ Ø£ĢØø╝ Øø╝ ØæĪ : Øø╝ ØæĪņŚÉņä£ņØś ļÅäĒĢ©ņłś Ø£ĢØÉĮ Ø£ĢØø╝ ņØś Ļ░Æ Gradient Descent, Gradient AscentļŖö ņĀäĒśĢņĀüņØĖ Greedy algorithmņØ┤ļŗż. Ļ│╝Ļ▒░ ļśÉļŖö ļ»Ėļלļź╝ Ļ│ĀļĀżĒĢśņ¦Ć ņĢŖĻ│Ā Ēśäņ×¼ ņāüĒÖ®ņŚÉņä£ Ļ░Ćņן ņ£Āļ”¼ĒĢ£ ļŗżņØī ņ£äņ╣śļź╝ ņ░ŠņĢä Local optimal pointļĪ£ ļüØļéĀ Ļ░ĆļŖźņä▒ņØä Ļ░Ćņ¦ä ņĢīĻ│Āļ”¼ņ”śņØ┤ļŗż.
- 27. ØÉĮ ╬ś = 1 2 Ø£ā0 + Ø£ā1 ØæźØæ¢ ŌłÆ Øæ”Øæ¢ 2 Øæø Øæ¢=1 = 1 2 ╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢ 2 Øæø Øæ¢=1 ØĢ®Øæ¢ = 1, ØæźØæ¢ Øæć , ╬ś = Ø£ā0, Ø£ā1 Øæć , ØĢ¬ = Øæ”1, Øæ”2, ŌĆ” , Øæ”Øæø Øæć , Øæŗ = 1 1 ŌĆ” Øæź1 Øæź2 ŌĆ” 1 Øæź Øæø , ØĢ¢ = (Ø£¢1, ŌĆ” , Ø£¢ Øæø) ļØ╝Ļ│Ā ĒĢśņ×É. Ø£ā0 ØæĪ+1 = Ø£ā0 ØæĪ ŌłÆ Øø╝ Ø£Ģ Ø£ĢØ£ā0 ØÉĮ(╬ś)ØæĪ Ø£ā1 ØæĪ+1 = Ø£ā1 ØæĪ ŌłÆ Øø╝ Ø£Ģ Ø£ĢØ£ā1 ØÉĮ(╬ś)ØæĪ Ø£ā0ņØś ØæĪļ▓łņ¦Ė Ļ░ÆņØä, ØÉĮ(╬ś)ļź╝ Ø£ā0ņ£╝ļĪ£ ļ»ĖļČäĒĢ£ ņŗØņŚÉļŗżĻ░Ć ļīĆņ×ģ. ĻĘĖ ĒøäņŚÉ, ņØ┤ Ļ░ÆņØä Ø£ā0ņŚÉņä£ ļ╣╝ ņżī. ļ»ĖļČäĒĢĀ ļĢī ņØ┤ņÜ®. Gradient descentļź╝ ņżæņ¦ĆĒĢśļŖö ĻĖ░ņżĆņØ┤ ļÉśļŖö ĒĢ©ņłś
- 28. ØÉĮ ╬ś = 1 2 Ø£ā0 + Ø£ā1 ØæźØæ¢ ŌłÆ Øæ”Øæ¢ 2 Øæø Øæ¢=1 = 1 2 ╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢ 2 Øæø Øæ¢=1 ØĢ®Øæ¢ = 1, ØæźØæ¢ Øæć , ╬ś = Ø£ā0, Ø£ā1 Øæć , ØĢ¬ = Øæ”1, Øæ”2, ŌĆ” , Øæ”Øæø Øæć , Øæŗ = 1 1 ŌĆ” Øæź1 Øæź2 ŌĆ” 1 Øæź Øæø , ØĢ¢ = (Ø£¢1, ŌĆ” , Ø£¢ Øæø) ļØ╝Ļ│Ā ĒĢśņ×É. Gradient of ØÉĮ(╬ś) Ø£Ģ Ø£ĢØ£ā0 ØÉĮ Ø£ā = (╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢) Øæø Øæ¢=1 1 Ø£Ģ Ø£ĢØ£ā1 ØÉĮ Ø£ā = (╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢) Øæø Øæ¢=1 ØæźØæ¢ Øø╗ØÉĮ ╬ś = Ø£Ģ Ø£ĢØ£ā0 ØÉĮ ╬ś , Ø£Ģ Ø£ĢØ£ā1 ØÉĮ ╬ś Øæć = ╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢ ØĢ®Øæ¢ Øæø Øæ¢=1
- 29. ØĢ®Øæ¢ = 1, ØæźØæ¢ Øæć , ╬ś = Ø£ā0, Ø£ā1 Øæć , ØĢ¬ = Øæ”1, Øæ”2, ŌĆ” , Øæ”Øæø Øæć , Øæŗ = 1 1 ŌĆ” Øæź1 Øæź2 ŌĆ” 1 Øæź Øæø , ØĢ¢ = (Ø£¢1, ŌĆ” , Ø£¢ Øæø) ļØ╝Ļ│Ā ĒĢśņ×É. Ø£ā0 ØæĪ+1 = Ø£ā0 ØæĪ ŌłÆ Øø╝ (╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢) Øæø Øæ¢=1 1 ļŗ©, ņØ┤ ļĢīņØś ╬śņ×Éļ”¼ņŚÉļŖö ØæĪļ▓łņ¦ĖņŚÉ ņ¢╗ņ¢┤ņ¦ä ╬śĻ░ÆņØä ļīĆņ×ģĒĢ┤ņĢ╝ ĒĢ£ļŗż. Ø£ā1 ØæĪ+1 = Ø£ā1 ØæĪ ŌłÆ Øø╝ ╬ś Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢ ØæźØæ¢ Øæø Øæ¢=1
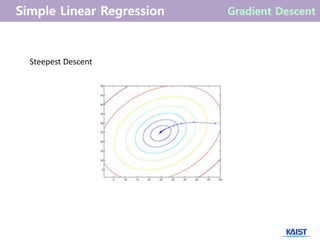
- 30. Steepest Descent
- 31. Steepest Descent ņןņĀÉ : easy to implement, conceptually clean, guaranteed convergence ļŗ©ņĀÉ : often slow converging ╬ś ØæĪ+1 = ╬ś ØæĪ ŌłÆ Øø╝ {(╬ś ØæĪ) Øæć ØĢ®Øæ¢ ŌłÆ Øæ”Øæ¢}ØĢ®Øæ¢ Øæø Øæ¢=1 Normal Equations ņןņĀÉ : a single-shot algorithm! Easiest to implement. ļŗ©ņĀÉ : need to compute pseudo-inverse Øæŗ Øæć Øæŗ ŌłÆ1 , expensive, numerical issues (e.g., matrix is singular..), although there are ways to get around this ... ØĢ¢ = Øæŗ Øæć Øæŗ ŌłÆ1 Øæŗ Øæć ØĢ¬╦å
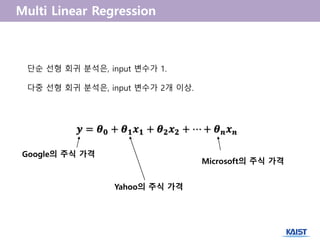
- 33. ØÆÜ = Ø£Į Ø¤Ä + Ø£Į ؤŠØÆÖ Ø¤Å + Ø£Į Ø¤É ØÆÖ Ø¤É + Ōŗ» + Ø£Į ØÆÅ ØÆÖ ØÆÅ ļŗ©ņł£ ņäĀĒśĢ ĒÜīĻĘĆ ļČäņäØņØĆ, input ļ│ĆņłśĻ░Ć 1. ļŗżņżæ ņäĀĒśĢ ĒÜīĻĘĆ ļČäņäØņØĆ, input ļ│ĆņłśĻ░Ć 2Ļ░£ ņØ┤ņāü. GoogleņØś ņŻ╝ņŗØ Ļ░ĆĻ▓® YahooņØś ņŻ╝ņŗØ Ļ░ĆĻ▓® MicrosoftņØś ņŻ╝ņŗØ Ļ░ĆĻ▓®
- 34. ØÆÜ = Ø£Į Ø¤Ä + Ø£Į ؤŠØÆÖ Ø¤Å Ø¤É + Ø£Į Ø¤É ØÆÖ Ø¤É Ø¤Æ + ØØÉ ņśłļź╝ ļōżņ¢┤, ņĢäļלņÖĆ Ļ░ÖņØĆ ņŗØņØä ņäĀĒśĢņ£╝ļĪ£ ņāØĻ░üĒĢśņŚ¼ ĒÆĆ ņłś ņ׳ļŖöĻ░Ć? ļ¼╝ļĪĀ, input ļ│ĆņłśĻ░Ć polynomial(ļŗżĒĢŁņŗØ)ņØś ĒśĢĒā£ņØ┤ņ¦Ćļ¦ī, coefficients Ø£āØæ¢Ļ░Ć ņäĀĒśĢ(linear)ņØ┤ļ»ĆļĪ£ ņäĀĒśĢ ĒÜīĻĘĆ ļČäņäØņØś ĒĢ┤ļ▓Ģņ£╝ļĪ£ ĒÆĆ ņłś ņ׳ļŗż. ØÜ» = Øæŗ Øæć Øæŗ ŌłÆ1 Øæŗ Øæć ØĢ¬╦å Ø£ā0, Ø£ā1, ŌĆ” , Ø£ā Øæø Øæć
- 36. ØÆÜ = Ø£Į Ø¤Ä + Ø£Į ؤŠØÆÖ Ø¤Å + Ø£Į Ø¤É ØÆÖ Ø¤É + Ōŗ» + Ø£Į ØÆÅ ØÆÖ ØÆÅņżæ ĒÜīĻĘĆ ļČäņäØ ņØ╝ļ░ś ĒÜīĻĘĆ ļČäņäØ ØÆÜ = Ø£Į Ø¤Ä + Ø£Į ؤŠØÆł ؤÅ(ØÆÖ Ø¤Å) + Ø£Į Ø¤É ØÆł ؤÉ(ØÆÖ Ø¤É) + Ōŗ» + Ø£Į ØÆÅ ØÆł ØÆÅ(ØÆÖ ØÆÅ) ØæöØæŚļŖö Øæź ØæŚ ļśÉļŖö (ØæźŌłÆØ£ć ØæŚ) 2Ø£Ä ØæŚ ļśÉļŖö 1 1+exp(ŌłÆØæĀ ØæŚ Øæź) ļō▒ņØś ĒĢ©ņłśĻ░Ć ļÉĀ ņłś ņ׳ļŗż. ņØ┤Ļ▓āļÅä ļ¦łņ░¼Ļ░Ćņ¦ĆļĪ£ ņäĀĒśĢ ĒÜīĻĘĆ ĒÆĆņØ┤ ļ░®ļ▓Ģņ£╝ļĪ£ ļ¼ĖņĀ£ļź╝ ĒÆĆ ņłś ņ׳ļŗż.
- 37. Øæż Øæć = (Øæż0, Øæż1, ŌĆ” , Øæż Øæø) Ø£Ö Øæź Øæ¢ Øæć = Ø£Ö0 Øæź Øæ¢ , Ø£Ö1 Øæź Øæ¢ , ŌĆ” , Ø£Ö Øæø Øæź Øæ¢
- 38. Øæż Øæć = (Øæż0, Øæż1, ŌĆ” , Øæż Øæø) Ø£Ö Øæź Øæ¢ Øæć = Ø£Ö0 Øæź Øæ¢ , Ø£Ö1 Øæź Øæ¢ , ŌĆ” , Ø£Ö Øæø Øæź Øæ¢ normal equation
- 39. [ ņ×ÉļŻīņØś ļČäņäØ ] ŌæĀ ļ¬®ņĀü : ņ¦æņØä ĒīöĻĖ░ ņøÉĒĢ©. ņĢīļ¦×ņØĆ Ļ░ĆĻ▓®ņØä ņ░ŠĻĖ░ ņøÉĒĢ©. ŌæĪ Ļ│ĀļĀżĒĢĀ ļ│Ćņłś(feature) : ņ¦æņØś Ēü¼ĻĖ░(in square feet), ņ╣©ņŗżņØś Ļ░£ņłś, ņ¦æ Ļ░ĆĻ▓®
- 40. (ņČ£ņ▓ś : http://aimotion.blogspot.kr/2011/10/machine-learning-with-python-linear.html) Ōæó ņŻ╝ņØśņé¼ĒĢŁ : ņ¦æņØś Ēü¼ĻĖ░ņÖĆ ņ╣©ņŗżņØś Ļ░£ņłśņØś ņ░©ņØ┤Ļ░Ć Ēü¼ļŗż. ņśłļź╝ ļōżņ¢┤, ņ¦æņØś Ēü¼ĻĖ░Ļ░Ć 4000 square feetņØĖļŹ░, ņ╣©ņŗżņØś Ļ░£ņłśļŖö 3Ļ░£ņØ┤ļŗż. ņ”ē, ļŹ░ņØ┤Ēä░ ņāü featureļōż Ļ░ä ĻĘ£ļ¬©ņØś ņ░©ņØ┤Ļ░Ć Ēü¼ļŗż. ņØ┤ļ¤┤ Ļ▓ĮņÜ░, featureņØś Ļ░ÆņØä ņĀĢĻĘ£ĒÖö(normalizing)ļź╝ ĒĢ┤ņżĆļŗż. ĻĘĖļלņĢ╝, Gradient Descentļź╝ ņłśĒ¢ēĒĢĀ ļĢī, Ļ▓░Ļ│╝Ļ░Æņ£╝ļĪ£ ļ╣Āļź┤Ļ▓ī ņłśļĀ┤ĒĢśļŗż. ŌæŻ ņĀĢĻĘ£ĒÖöņØś ļ░®ļ▓Ģ - featureņØś mean(ĒÅēĻĘĀ)ņØä ĻĄ¼ĒĢ£ Ēøä, featureļé┤ņØś ļ¬©ļōĀ dataņØś Ļ░ÆņŚÉņä£ meanņØä ļ╣╝ņżĆļŗż. - dataņŚÉņä£ meanņØä ļ╣╝ ņżĆ Ļ░ÆņØä, ĻĘĖ dataĻ░Ć ņåŹĒĢśļŖö standard deviation(Ēæ£ņżĆ ĒÄĖņ░©)ļĪ£ ļéśļłäņ¢┤ ņżĆļŗż. (scaling) ņØ┤ĒĢ┤Ļ░Ć ņĢł ļÉśļ®┤, ņÜ░ļ”¼Ļ░Ć Ļ│Āļō▒ĒĢÖĻĄÉ ļĢī ļ░░ņøĀļŹś ņĀĢĻĘ£ļČäĒżļź╝ Ēæ£ņżĆņĀĢĻĘ£ļČäĒżļĪ£ ļ░öĻŠĖņ¢┤ņŻ╝ļŖö Ļ▓āņØä ļ¢Āņś¼ļĀżļ│┤ņ×É. Ēæ£ņżĆņĀĢĻĘ£ļČäĒżļź╝ ņé¼ņÜ®ĒĢśļŖö ņØ┤ņ£Ā ņżæ ĒĢśļéśļŖö, ņä£ļĪ£ ļŗżļźĖ ļæÉ ļČäĒż, ņ”ē ļ╣äĻĄÉĻ░Ć ļČłĻ░ĆļŖźĒĢśĻ▒░ļéś ņ¢┤ļĀżņÜ┤ ļæÉ ļČäĒżļź╝ ņēĮĻ▓ī ļ╣äĻĄÉĒĢĀ ņłś ņ׳Ļ▓ī ĒĢ┤ņŻ╝ļŖö Ļ▓āņØ┤ņŚłļŗż. ØæŹ = Øæŗ ŌłÆ Ø£ć Ø£Ä If Øæŗ~(Ø£ć, Ø£Ä) then ØæŹ~Øæü(1,0)
- 41. 1. http://www.cs.cmu.edu/~epxing/Class/10701/Lecture/lecture5-LiR.pdf 2. http://www.cs.cmu.edu/~10701/lecture/RegNew.pdf 3. ĒÜīĻĘĆļČäņäØ ņĀ£ 3ĒīÉ (ļ░Ģņä▒Ēśä ņĀĆ) 4. Ēī©Ēä┤ņØĖņŗØ (ņśżņØ╝ņäØ ņ¦ĆņØī) 5. ņłśļ”¼ĒåĄĻ│äĒĢÖ ņĀ£ 3ĒīÉ (ņĀäļ¬ģņŗØ ņ¦ĆņØī)
- 42. Laplacian Smoothing multinomial random variable Øæ¦ : Øæ¦ļŖö 1ļČĆĒä░ ØæśĻ╣īņ¦ĆņØś Ļ░ÆņØä Ļ░Ćņ¦ł ņłś ņ׳ļŗż. ņÜ░ļ”¼ļŖö test setņ£╝ļĪ£ ØæÜĻ░£ņØś ļÅģļ”ĮņØĖ Ļ┤Ćņ░░ Ļ░Æ Øæ¦ 1 , ŌĆ” , Øæ¦ ØæÜ ņØä Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŗż. ņÜ░ļ”¼ļŖö Ļ┤Ćņ░░ Ļ░ÆņØä ĒåĄĒĢ┤, ØÆæ(ØÆø = ØÆŖ) ļź╝ ņČöņĀĢĒĢśĻ│Ā ņŗČļŗż. (Øæ¢ = 1, ŌĆ” , Øæś) ņČöņĀĢ Ļ░Æ(MLE)ņØĆ, ØæØ Øæ¦ = ØæŚ = ØÉ╝{Øæ¦ Øæ¢ = ØæŚ}ØæÜ Øæ¢=1 ØæÜ ņØ┤ļŗż. ņŚ¼ĻĖ░ņä£ ØÉ╝ . ļŖö ņ¦Ćņŗ£ ĒĢ©ņłś ņØ┤ļŗż. Ļ┤Ćņ░░ Ļ░Æ ļé┤ņŚÉņä£ņØś ļ╣łļÅäņłśļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ņČöņĀĢĒĢ£ļŗż. ĒĢ£ Ļ░Ćņ¦Ć ņŻ╝ņØś ĒĢĀ Ļ▓āņØĆ, ņÜ░ļ”¼Ļ░Ć ņČöņĀĢĒĢśļĀżļŖö Ļ░ÆņØĆ ļ¬©ņ¦æļŗ©(population)ņŚÉņä£ņØś ļ¬©ņłś ØæØ(Øæ¦ = Øæ¢)ļØ╝ļŖö Ļ▓āņØ┤ļŗż. ņČöņĀĢĒĢśĻĖ░ ņ£äĒĢśņŚ¼ test set(or Ēæ£ļ│Ė ņ¦æļŗ©)ņØä ņé¼ņÜ®ĒĢśļŖö Ļ▓ā ļ┐ÉņØ┤ļŗż. ņśłļź╝ ļōżņ¢┤, Øæ¦(Øæ¢) ŌēĀ 3 for all Øæ¢ = 1, ŌĆ” , ØæÜ ņØ┤ļØ╝ļ®┤, ØæØ Øæ¦ = 3 = 0 ņØ┤ ļÉśļŖö Ļ▓āņØ┤ļŗż. ņØ┤Ļ▓āņØĆ, ĒåĄĻ│äņĀüņ£╝ļĪ£ ļ│╝ ļĢī, ņóŗņ¦Ć ņĢŖņØĆ ņāØĻ░üņØ┤ļŗż. ļŗ©ņ¦Ć, Ēæ£ļ│Ė ņ¦æļŗ©ņŚÉņä£ ļ│┤ņØ┤ņ¦Ć ņĢŖļŖö ļŗżļŖö ņØ┤ņ£ĀļĪ£ ņÜ░ļ”¼Ļ░Ć ņČöņĀĢĒĢśĻ│Āņ×É ĒĢśļŖö ļ¬©ņ¦æļŗ©ņØś ļ¬©ņłś Ļ░ÆņØä 0ņ£╝ļĪ£ ĒĢ£ļŗżļŖö Ļ▓āņØĆ ĒåĄĻ│äņĀüņ£╝ļĪ£ ņóŗņ¦Ć ņĢŖņØĆ ņāØĻ░ü(bad idea)ņØ┤ļŗż. (MLEņØś ņĢĮņĀÉ)
- 43. ņØ┤Ļ▓āņØä ĻĘ╣ļ│ĄĒĢśĻĖ░ ņ£äĒĢ┤ņä£ļŖö, ŌæĀ ļČäņ×ÉĻ░Ć 0ņØ┤ ļÉśņ¢┤ņä£ļŖö ņĢł ļÉ£ļŗż. ŌæĪ ņČöņĀĢ Ļ░ÆņØś ĒĢ®ņØ┤ 1ņØ┤ ļÉśņ¢┤ņĢ╝ ĒĢ£ļŗż. ØæØ Øæ¦ = ØæŚØæ¦ =1 (ŌłĄ ĒÖĢļźĀņØś ĒĢ®ņØĆ 1ņØ┤ ļÉśņ¢┤ņĢ╝ ĒĢ©) ļö░ļØ╝ņä£, ØÆæ ØÆø = ØÆŗ = Øæ░ ØÆø ØÆŖ = ØÆŗ + ؤÅØÆÄ ØÆŖ=ؤŠØÆÄ + ØÆī ņØ┤ļØ╝Ļ│Ā ĒĢśņ×É. ŌæĀņØś ņä▒ļ”Į : test set ļé┤ņŚÉ ØæŚņØś Ļ░ÆņØ┤ ņŚåņ¢┤ļÅä, ĒĢ┤ļŗ╣ ņČöņĀĢ Ļ░ÆņØĆ 0ņØ┤ ļÉśņ¦Ć ņĢŖļŖöļŗż. ŌæĪņØś ņä▒ļ”Į : Øæ¦(Øæ¢) = ØæŚņØĖ dataņØś ņłśļź╝ ØæøØæŚļØ╝Ļ│Ā ĒĢśņ×É. ØæØ Øæ¦ = 1 = Øæø1+1 ØæÜ+Øæś , ŌĆ” , ØæØ Øæ¦ = Øæś = Øæø Øæś+1 ØæÜ+Øæś ņØ┤ļŗż. Ļ░ü ņČöņĀĢ Ļ░ÆņØä ļŗż ļŹöĒĢśĻ▓ī ļÉśļ®┤ 1ņØ┤ ļéśņś©ļŗż. ņØ┤Ļ▓āņØ┤ ļ░öļĪ£ Laplacian smoothingņØ┤ļŗż. Øæ¦Ļ░Ć ļÉĀ ņłś ņ׳ļŖö Ļ░ÆņØ┤ 1ļČĆĒä░ ØæśĻ╣īņ¦Ć ĻĘĀļō▒ĒĢśĻ▓ī ļéśņś¼ ņłś ņ׳ļŗżļŖö Ļ░ĆņĀĢņØ┤ ņČöĻ░ĆļÉśņŚłļŗżĻ│Ā ņ¦üĻ┤ĆņĀüņ£╝ļĪ£ ņĢī ņłś ņ׳ļŗż. 1