









![ЧФИ»СФХZ„IАнӨЛӨӘӨұӨлCNN
®’ӨЯЮzӨЯӨтК№ӨГӨЖОДХВЦРӨО…gХZ
йvӮSӨтҝј‘]Ө·ӨҝEmbeddingұн¬F
Ө¬өГӨйӨмӨл
ЈЁЧФјәЧўТвӨО·Ҫ·ЁӨОЈұӨДЈ©
Ҷ–о}өг
?ҝЙүдйLӨОИлБҰӨЛҢқҸкӨЗӨӯӨКӨӨ
ЈЁ®’ӨЯЮzӨЯӨОҘ«©`ҘНҘлҘөҘӨҘәӨП№М¶Ё e.g. 3, 5Ј©
?ОДГ}ӨтТҠӨәӨЛЦШӨЯӨтӣQ¶ЁӨ·ӨЖӨӨӨл
14/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-14-320.jpg)
![? ҘвҘБҘЩ©`Ҙ·ҘзҘу
? ҝЙүдйLӨОИлБҰӨЛҢқҸкӨ·ӨДӨДЈ¬
ОДГ}Өтҝј‘]Ө·ӨҝEmbeddingұн¬FӨШӨО
үд“Q·Ҫ·ЁӨтЦӘӨкӨҝӨӨ
? РВӨҝӨКҘўҘЧҘн©`ҘБ
? ИлБҰӨО…gХZұн¬FӨОЦШӨЯё¶ӨӯәНӨт
ИлБҰӨШӨОAttentionӨЛ»щӨЕӨӨӨЖУӢЛгӨ№Өл
http://fuyw.top/NLP_02_QANet/
Attention
15/34ҘбҘвҘкҘНҘГҘИҘп©`ҘҜӨОҳӢіЙ
<ұіҫ°>
ИлБҰОДӨЛҢқҸкӨ·ӨҝЈ¬Я^ИҘӨОУӣеhӨтИЎӨГӨЖӨҜӨл
ҘбҘвҘкҘНҘГҘИҘп©`ҘҜӨИәфӨРӨмӨлҘ·Ҙ№ҘЖҘаӨЛӨДӨӨӨЖ
AttentionҷCҳӢӨЛӨиӨкЎўРФДЬӨ¬ёДЙЖӨ·ӨҝСРҫҝіЙ№ыӨ¬ӨўӨл
ЈЁMiller, 2016,Ўұ Key-Value Memory Networks for Directly Reading DocumentsЎұЈ©](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-15-320.jpg)

![AttentionӨИҘбҘвҘк
? …gХZӨПйLӨөЈҙӨОВсӨбЮzӨЯұн¬FӨИӨ№Өл ЈЁe.g. Ў°ҘӨҘуҘіЎұ=[?0.02, ?0.16, 0.12, ?0.10]Ј©
әГӨӯ
ӨП
„УОп
ӨК
ҘӨҘуҘі
әГӨӯ
Ө¬Input Memory
ЈҙЎБЈҙӨОРРБР
ЈіЎБЈҙӨОРРБР
17/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-17-320.jpg)





![SeЈмЈж-Attention
? MemoryӨИInputӨ¬Н¬Өё
? ТвО¶ЈәЎ°ИлБҰЎұӨ«ӨйЎұИлБҰЎұӨЛйvЯBӨ·ӨЖӨӨӨлІҝ·ЦӨтіЦӨГӨЖӨҜӨл
? ИлБҰӨОёч…gХZйgӨОйvӮSӨтҝј‘]Ө·Өҝ…gХZҘЩҘҜҘИҘлұн¬FӨ¬өГӨйӨмӨл 23/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-23-320.jpg)


![? ЦшХЯ/ЛщКфҷCйv
? Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
? Google AI Language
? Т»СФӨЗСФӨҰӨИ
? ¶аҢУӨЛ·eӨЯЦШӨНӨҝTransformerӨЛӨиӨГӨЖЈ¬
ОДХВӨтОДГ}Өтҝј‘]Ө·Өҝ…gХZұн¬FӨЛEmbeddingӨ№ӨлҘвҘЗҘл
Х“ОД Ў°BERT: pre-training of deep bidirectional transformers
for language understandingЎұ
26/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-26-320.jpg)

![? TransformerӨОEncoderЈЁSelf-attentionЈ©ӨтНЁӨ№ӨіӨИӨЗ
ОДГ}Өтҝј‘]Ө·Өҝ…gХZ·ЦЙўұн¬FӨ¬өГӨйӨмӨл
BERTӨОТвБx
http://jalammar.github.io
/illustrated-bert/
ЎщELMoӨПBERTТФЗ°ӨО
ОДГ}…gХZұн¬FҘвҘЗҘлЈ®
ҘНҘГҘИҘп©`ҘҜҳӢФмӨП
Bi-LSTMЈ®
28/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-28-320.jpg)
![? Masked LM
? ОДХВӨОТ»ІҝӨт[MASK]ҘИ©`ҘҜҘуӨЛЦГӨӯ“QӨЁЈ¬УиңyӨөӨ»Өл
ЈЁӨіӨОКЦ·ЁӨОіхіцӨПЎ°Cloze Procedure: A New Tool for Measuring ReadabilityЎұӨЗ1953ДкӨОХ“ОДЈ©
BERTӨОКВЗ°С§Б•ўЩ
http://jalammar.github.io
/illustrated-bert/
29/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-29-320.jpg)

![Ў°For each task, we simply plug in the task-specific inputs and
outputs into BERT and finetune all the parameters end-to-end.Ўұ
Fine-tuningӨПКВЗ°С§Б•ңgӨЯҘвҘЗҘлӨтМШ¶ЁӨО
ҘҝҘ№ҘҜУГӨЛФЩС§Б•Ө№ӨлӨіӨИӨтЦёӨ№
АэЈ©
ҘҜҘйҘ№·ЦоҗӨЗӨПInputӨООДо^ӨЛ
[CLS]ҘИ©`ҘҜҘуӨтЦГӨӯЈ®ӨҪӨОО»ЦГӨО
BERTіцБҰӨЛҘНҘГҘИҘп©`ҘҜӨтӨ«ӨЮӨ»ӨЖУиңyӨ№Өл
BERTӨОfine-tuning
31/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-31-320.jpg)

![? BERTӨПҡшУГөДӨКNLPӨОКВЗ°С§Б•ҘвҘЗҘл
? …gјғӨКҘў©`ҘӯҘЖҘҜҘБҘгЈЁTransformerӨОEncoderӨтЦШӨНӨҝӨАӨұЈ©
? EncoderӨЗУ–ҫҡӨ№ӨлӨҝӨбӨЛMasked LMӨИәфӨРӨмӨлКЦ·ЁӨт’сУГӨ·Өҝ
? ОДГ}Өтҝј‘]Ө·Өҝ…gХZӨО·ЦЙўұн¬FӨ¬өГӨйӨмӨл
? өГӨйӨмӨҝ·ЦЙўұн¬FӨП·ЗіЈӨЛҸҠБҰӨЗЈ¬BERTӨОtop layerӨЛ
…gјғӨКҫҖРОүд“QӨтЯBҪYӨ№ӨлӨАӨұӨЗЈ¬ҘҝҘ№ҘҜӨтҪвӨҜӨіӨИӨ¬ҝЙДЬ
? КВЗ°С§Б•ңgӨЯӨОBERTӨтfine-tuneӨ№ӨлӨіӨИӨЗ
ӨўӨйӨжӨлNLPҘҝҘ№ҘҜӨтҪвӣQӨЗӨӯӨлЈҝ
BERTӨЮӨИӨб
33/34](https://image.slidesharecdn.com/attention-200210111918/85/NLP-Attention-Seq2Seq-BERT-33-320.jpg)







![[DLЭҶХi»б]Pay Attention to MLPs ЈЁgMLPЈ©](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=560&fit=bounds)



![[DLЭҶХi»б]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=560&fit=bounds)














![[DLЭҶХi»б]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=560&fit=bounds)




![[DLЭҶХi»б]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=560&fit=bounds)


More Related Content
What's hot (20)
Similar to NLPӨЛӨӘӨұӨлAttentionЎ«Seq2Seq Ө«Өй BERTӨЮӨЗЎ« (20)


![[DLЭҶХi»б]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=560&fit=bounds)



![[DLЭҶХi»б]Attention InterpretabilityAcross NLPTasks](https://cdn.slidesharecdn.com/ss_thumbnails/dlrindokukai-190927013932-thumbnail.jpg?width=560&fit=bounds)









![[MLХ“ОДХiӨЯ»бЩYБП] Teaching Machines to Read and Comprehend](https://cdn.slidesharecdn.com/ss_thumbnails/ml2-171222014201-thumbnail.jpg?width=560&fit=bounds)

NLPӨЛӨӘӨұӨлAttentionЎ«Seq2Seq Ө«Өй BERTӨЮӨЗЎ«
- 2. ? ӨіӨО°kұнӨПТФПВӨО3Х“ОДӨтӨЮӨИӨбӨҝӨвӨОӨЗӨ№ Ў°Neural Machine Translation by jointly learning to align and translateЎұ Ў°Attention Is All You NeedЎұ Ў°BERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingЎұ ? ЙоҢУС§Б•ӨЛӨиӨлNLPӨЗҪьДкЦШТӘӨКЎұAttentionЎұӨЛӨДӨӨӨЖ ӨҪӨОЖрФҙӨИ°kХ№ӨтХсӨк·өӨкӨЮӨ№Ј® ӨПӨёӨбӨЛ 2/34
- 3. Outline Ў°Neural Machine Translation by jointly learning to align and translateЎұ ?LSTMӨЛӨиӨл·ӯФUҘвҘЗҘл ?Attention + RNN Ў°Attention Is All You NeedЎұ ?AttentionӨЛӨиӨлRNNӨОЦГ“Q ?Self-AttentionӨИTransformer Ў°BERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingЎұ ?КВЗ°С§Б•ЈәMasked LMӨИNext Sentence Prediction ?BERTӨОРФДЬ 3/34
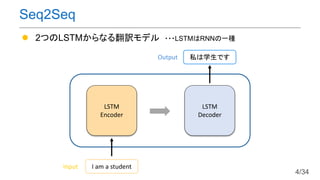
- 4. ? 2ӨДӨОLSTMӨ«ӨйӨКӨл·ӯФUҘвҘЗҘл ???LSTMӨПRNNӨОТ»·N Seq2Seq LSTM Encoder LSTM Decoder I am a studentInput ЛҪӨПС§ЙъӨЗӨ№Output 4/34
- 6. •rПөБРӨЗӨЯӨлSeq2SeqӨО„УЧчДЪИЭ 21 43 5 76 98 •rҝМ 6/34
- 7. ? ИлБҰӨОйLӨөӨЛӨ«Ө«ӨпӨйӨәЈ¬EncoderӨОіцБҰӨт №М¶ЁйLӨОҘЩҘҜҘИҘлұн¬F(?4)ӨЛВдӨИӨ·ЮzӨуӨЗӨ·ӨЮӨҰ ? йLӨөӨ¬50ӨООДХВӨЗӨвйLӨө4ӨООДХВӨИН¬ӨёҘөҘӨҘәӨОұн¬FӨЛӨКӨл ? ҘӯҘгҘСҘ·ҘЖҘЈӨ¬¶ЁӨЮӨГӨЖӨӨӨлӨҝӨбйLОДӨАӨИРФДЬӨ¬ВдӨБӨл Seq2SeqӨОҶ–о}өг Ўъ ОДХВӨОйLӨөӨЛҸкӨёӨҝұн¬Fүд“QҘ·Ҙ№ҘЖҘаӨ¬УыӨ·ӨӨ 7/34
- 8. ? Attention in RNNs ЈЁіхіцЈәЎұ Neural Machine Translation by jointly learning to align and translateЎұЈ© ? RNNӨОИ«•rҝМӨОіцБҰӨтУГӨӨӨл ҘвҘёҘе©`ҘлЈЁAttentionҷCҳӢЈ©ӨтЧ·јУЈ®(AttentionӨЛӨДӨӨӨЖӨПббӨЫӨЙХhГч) ? •rПөБРӨОЦРӨ«ӨйЦШТӘӨҪӨҰӨКЗйҲуӨтЯxӨЦӨіӨИӨ¬ӨЗӨӯӨл AttentionӨО°kГч ТэУГЈЁТ»ІҝёДЈ©github/tensorflow/tensorflow/blob/master/ tensorflow/contrib/eager/python/examples/nmt_with_attention <УаХ„>ӨіӨОNNҘвҘЗҘлӨЛӨиӨГӨЖ2016Дк10ФВн•ӨЛGoogle·ӯФUӨОРФДЬӨ¬пwЬSөДӨЛЙПӨ¬ӨГӨҝ 8/34
- 9. ? …gјғӨКLSTMӨЛӨиӨл·ӯФUҘвҘЗҘлӨтӨЯӨҝ ? ӨҪӨіӨҪӨіӨОРФДЬ ? ОДХВӨОйLӨөӨЛӨПҢқҸкӨЗӨӯӨЖӨӨӨКӨ«ӨГӨҝ ? Attention in RNNs ? іхЖЪӨОAttentionӨПRNNӨИҒгУГӨөӨмӨЖӨӨӨҝ ? Attention WeightӨтУГӨӨӨЖЦШӨЯё¶ӨӯәНӨтУӢЛгӨ№ӨлҘ·Ҙ№ҘЖҘаӨП ҝЙүдйLИлБҰӨЛҢқҸкӨ№ӨлЦШТӘӨКјјРg Seq2SeqӨОӨЮӨИӨб 9/34
- 10. ? ӨҪӨвӨҪӨвRNNӨӨӨйӨКӨӨӨОӨЗӨПЈҝ ? SequenceӨтХiӨЯЮzӨЮӨ»ӨлӨОӨЗУӢЛгӨ¬ЯWӨӨ ? йLӨӨОДХВӨАӨИУӢЛгӨ¬ӨҰӨЮӨҜӨӨӨ«ӨКӨӨЈЁ№ҙЕдПыК§or№ҙЕдұ¬°kӨ¬АнУЙЈ© ? RNNӨтAttentionӨЗЦГӨӯ“QӨЁӨиӨҰ ? TransformerӨОМб°ё ЎұAttention Is All You NeedЎұ RNNӨ«ӨйAttentionӨШ https://adventuresinmachinelearning.com/ recurrent-neural-networks-lstm-tutorial- tensorflow/ 10/34
- 11. ? ЦшХЯ/ЛщКфҷCйv ? Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin ? Google Brain, Google Research, University of Toronto ? Т»СФӨЗСФӨҰӨИ ? Encoder-DecoderҘвҘЗҘлӨОRNNӨтAttentionӨЗ ЦГӨӯ“QӨЁӨҝҘвҘЗҘлЈ¬ЎұTransformerЎұӨтМб°ёЈ® ¶МӨӨУ–ҫҡ•rйgӨЗӨўӨкӨКӨ¬Өй¶аӨҜӨОҘҝҘ№ҘҜӨЗSoTAЈ® Х“ОД Ў°Attention Is All You NeedЎұ 11/34
- 13. ? RNNӨООДХВ„IАн ОДХВЎұI am a studentЎұӨЛӨДӨӨӨЖ Ў°IЎұЎъЎұamЎұЎъЎұaЎұЎъЎұstudentЎұӨИнҳ·¬ӨЛХiӨЯЮzӨЮӨ»ӨлӨіӨИӨЗЈ¬ RNNӨОДЪІҝЧҙ‘BӨтЯwТЖӨөӨ»Ј¬ ЎұОДХВЦРӨО…gХZЎұӨИӨӨӨҰұн¬FӨт«@өГӨ·ӨЖӨӨӨҝЈ® ? ЧФЙнӨОИлБҰӨЛЧўТвӨтПтӨұӨл ЈЁЧФјәЧўТвЈ© RNNӨЛҙъӨпӨлКЦ·ЁЈәЧФјәЧўТв ЎъОДХВӨО…gХZйvӮSӨт…gХZӨОҘЩҘҜҘИҘлұн¬FӨЛВсӨбЮzӨаЧчУГӨтіЦӨД 13/34
- 14. ЧФИ»СФХZ„IАнӨЛӨӘӨұӨлCNN ®’ӨЯЮzӨЯӨтК№ӨГӨЖОДХВЦРӨО…gХZ йvӮSӨтҝј‘]Ө·ӨҝEmbeddingұн¬F Ө¬өГӨйӨмӨл ЈЁЧФјәЧўТвӨО·Ҫ·ЁӨОЈұӨДЈ© Ҷ–о}өг ?ҝЙүдйLӨОИлБҰӨЛҢқҸкӨЗӨӯӨКӨӨ ЈЁ®’ӨЯЮzӨЯӨОҘ«©`ҘНҘлҘөҘӨҘәӨП№М¶Ё e.g. 3, 5Ј© ?ОДГ}ӨтТҠӨәӨЛЦШӨЯӨтӣQ¶ЁӨ·ӨЖӨӨӨл 14/34
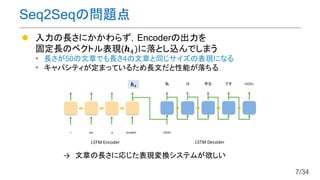
- 15. ? ҘвҘБҘЩ©`Ҙ·ҘзҘу ? ҝЙүдйLӨОИлБҰӨЛҢқҸкӨ·ӨДӨДЈ¬ ОДГ}Өтҝј‘]Ө·ӨҝEmbeddingұн¬FӨШӨО үд“Q·Ҫ·ЁӨтЦӘӨкӨҝӨӨ ? РВӨҝӨКҘўҘЧҘн©`ҘБ ? ИлБҰӨО…gХZұн¬FӨОЦШӨЯё¶ӨӯәНӨт ИлБҰӨШӨОAttentionӨЛ»щӨЕӨӨӨЖУӢЛгӨ№Өл http://fuyw.top/NLP_02_QANet/ Attention 15/34ҘбҘвҘкҘНҘГҘИҘп©`ҘҜӨОҳӢіЙ <ұіҫ°> ИлБҰОДӨЛҢқҸкӨ·ӨҝЈ¬Я^ИҘӨОУӣеhӨтИЎӨГӨЖӨҜӨл ҘбҘвҘкҘНҘГҘИҘп©`ҘҜӨИәфӨРӨмӨлҘ·Ҙ№ҘЖҘаӨЛӨДӨӨӨЖ AttentionҷCҳӢӨЛӨиӨкЎўРФДЬӨ¬ёДЙЖӨ·ӨҝСРҫҝіЙ№ыӨ¬ӨўӨл ЈЁMiller, 2016,Ўұ Key-Value Memory Networks for Directly Reading DocumentsЎұЈ©
- 16. ? ТФПВӨО…gјғӨКQuestion AnsweringӨЛӨДӨӨӨЖҝјӨЁӨл АэЈ© Q. әГӨӯӨК„УОпӨПЈҝ Ўъ A. ҘӨҘуҘіӨ¬әГӨӯ ? ӨіӨОҘҝҘ№ҘҜӨПЈ¬ТФПВӨОҘЧҘнҘ»Ҙ№ӨЗіЙӨкБўӨД ЎёәГӨӯӨК„УОпӨПЈҝЎ№ Ўэ °kФ’ХЯӨОЯ^ИҘӨОУӣеhӨ«ӨйЈ¬әГӨӯӨК„УОпӨЛйvӨ№ӨлСФј°ӨтӨЯӨл Ўэ ЎёҘӨҘуҘіӨ¬әГӨӯЎ№ӨИӨО°kСФӨ¬ӨўӨГӨҝӨОӨЗЈ¬ӨҪӨмӨтҙрӨЁӨЛӨ№Өл ? ӨіӨіӨЗӨПЎўУлӨЁӨйӨмӨҝҘҜҘЁҘкӨЛҢқҸкӨ№ӨлЗйҲуӨт НвІҝЦӘЧRӨ«ӨйӨИӨГӨЖӨҜӨлІЩЧчЈЁҙЗ•шөДҷCДЬЈ©ӨтРРӨГӨЖӨӨӨл ? AttentionӨПҫҖРОСЭЛгӨтЦчТӘӨКУӢЛгӨИӨ·ӨЖЎў ҙЗ•шҘӘҘЦҘёҘ§ҘҜҘИӨОТЫёоӨт№ыӨҝӨ№ӨіӨИӨ¬ӨЗӨӯӨлКЛҪMӨЯ НвІҝЦӘЧRӨтҢқПуӨИӨ№ӨлAttention 16/34 НвІҝЦӘЧRӨЛҢқӨ№ӨлAttention
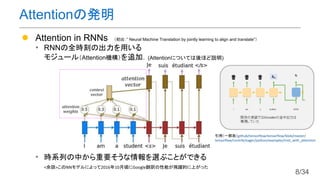
- 17. AttentionӨИҘбҘвҘк ? …gХZӨПйLӨөЈҙӨОВсӨбЮzӨЯұн¬FӨИӨ№Өл ЈЁe.g. Ў°ҘӨҘуҘіЎұ=[?0.02, ?0.16, 0.12, ?0.10]Ј© әГӨӯ ӨП „УОп ӨК ҘӨҘуҘі әГӨӯ Ө¬Input Memory ЈҙЎБЈҙӨОРРБР ЈіЎБЈҙӨОРРБР 17/34
- 19. AttentionӨИҘбҘвҘк ? QueryӨИKeyӨО·eӨтИЎӨл???ИлБҰӨИҘбҘвҘкӨОйvЯB¶ИӨтУӢЛг ? Attention WeightӨИValueӨО·eӨтИЎӨл???ЦШӨЯӨЛҸҫӨГӨЖӮҺӨтИЎөГ ЎщЧуҮнӨПsoftmaxӨт КЎВФӨ·ӨЖӨӨӨл ЎщЧуҮнӨПТ»ҢУdense layerӨтКЎВФӨ·ӨЖӨӨӨл 19/34
- 20. AttentionӨИҘбҘвҘк ? УӢЛгҪY№ыӨОАэЈЁҘӨҘуҘіЈ© әГӨӯ ӨП „УОп ӨК ҘӨҘуҘі әГӨӯӨ¬0.3ЎБ +0.05ЎБ +0.65ЎБ ҘӨҘуҘі әГӨӯӨ¬0.3ЎБ + 0.4ЎБ + 0.3ЎБ ҘӨҘуҘі әГӨӯӨ¬0.7ЎБ +0.05ЎБ +0.25ЎБ ҘӨҘуҘі әГӨӯӨ¬0.3ЎБ + 0.4ЎБ + 0.3ЎБ 20/34
- 22. AttentionӨИҘбҘвҘк ? Attention = ҙЗ•шҷCДЬ ? ИлБҰӨЛҢқҸкӨ·ӨҝЦШӨЯӨЕӨұӨЗҘбҘвҘкӨ«ӨйӮҺӨтӨИӨГӨЖӨҜӨл ? ҘбҘвҘкӨИӨПӨҪӨвӨҪӨвәОЈҝ ? ЎёИлБҰӨЛҸҫӨӨЈ¬йvЯBӨ·ӨҝЗйҲуӨтіцБҰӨ№ӨлҘӘҘЦҘёҘ§ҘҜҘИЎ№ ? АэЈ©ОД•шУӣеhЈ¬Question AnsweringӨЛӨӘӨұӨлQОДЈ¬·ӯФUҘвҘЗҘлӨЛӨӘӨұӨлФӯОД ? Key-ValueҘЪҘўӨЛ·ЦӨұӨлАнУЙӨПЈҝ ? KeyӨЛҸҫӨГӨЖValueӨтТэӨӯіцӨ№ӨИӨӨӨҰІЩЧчӨЛӨиӨГӨЖЈ¬ Уӣ‘ӣӨОХiӨЯіцӨ·Ө¬Ҙ№Ҙа©`ҘәӨЛӨКӨл ? KeyӨИValueӨт¶АБўӨЛЧчіЙӨ№ӨлӨіӨИӨЗЈ¬Key-ValueйgӨОүд“QӨ¬ ·ЗЧФГчӨЛӨКӨкЈ¬ұн¬FБҰӨ¬ёЯӨҜӨКӨл ? Self-AttentionӨИTarget-Source Attention ? ҘбҘвҘк©`ӨИӨ·ӨЖЧФ·ЦЧФЙнӨтК№ӨҰӨвӨОӨтSelf-AttentionЈ¬ ӨҪӨмТФНвӨтTarget-Source AttentionӨИӨӨӨҰ ? Target-Source AttentionӨПSeq2SeqӨЛӨӘӨӨӨЖ EncoderӨИDecoderӨОйgӨЗУГӨӨӨйӨмӨЖӨӨӨҝКЦ·Ё ? Self-AttentionӨПRNNӨОҙъУГӨИӨ·ӨЖК№ӨЁӨл 22/34
- 23. SeЈмЈж-Attention ? MemoryӨИInputӨ¬Н¬Өё ? ТвО¶ЈәЎ°ИлБҰЎұӨ«ӨйЎұИлБҰЎұӨЛйvЯBӨ·ӨЖӨӨӨлІҝ·ЦӨтіЦӨГӨЖӨҜӨл ? ИлБҰӨОёч…gХZйgӨОйvӮSӨтҝј‘]Ө·Өҝ…gХZҘЩҘҜҘИҘлұн¬FӨ¬өГӨйӨмӨл 23/34
- 24. ? TransformerӨОҘў©`ҘӯҘЖҘҜҘБҘг ? Чу°л·ЦӨ¬EncoderЈ¬УТ°л·ЦӨ¬Decoder Transformer EncoderӨОИлБҰӨПЈ¬ИлБҰЧФЙнӨОӨЯ ЎъSelf-AttentionӨҪӨОӨвӨО DecoderӨПSelf-AttentionӨИ Target-Source AttentionӨОҒгУГ. (BERTӨЗӨПEncoderӨ·Ө«К№ӨпӨКӨӨ ӨҝӨбХhГчӨПКЎВФЈ© 24/34
- 25. Ў°Attention Is All You NeedЎұӨЮӨИӨб ? ҘбҘвҘк©`ӨДӨӯAttentionӨтӨЯӨҝ ? ЧФЙнӨОИлБҰӨЛЧўДҝӨ№ӨлSelf-AttentionӨтҢ§ИлЈ¬ ҳӢФмӨ«ӨйRNNӨтЕЕӨ·ӨҝTransformerӨОНкіЙ ? ҒKБРУӢЛгӨЗӨӯӨл ? ҝЙүдйLӨОИлБҰӨЛӨҰӨЮӨҜҢқҸкӨЗӨӯӨл RNNӨОЕЕіэ 25/34
- 26. ? ЦшХЯ/ЛщКфҷCйv ? Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova ? Google AI Language ? Т»СФӨЗСФӨҰӨИ ? ¶аҢУӨЛ·eӨЯЦШӨНӨҝTransformerӨЛӨиӨГӨЖЈ¬ ОДХВӨтОДГ}Өтҝј‘]Ө·Өҝ…gХZұн¬FӨЛEmbeddingӨ№ӨлҘвҘЗҘл Х“ОД Ў°BERT: pre-training of deep bidirectional transformers for language understandingЎұ 26/34
- 29. ? Masked LM ? ОДХВӨОТ»ІҝӨт[MASK]ҘИ©`ҘҜҘуӨЛЦГӨӯ“QӨЁЈ¬УиңyӨөӨ»Өл ЈЁӨіӨОКЦ·ЁӨОіхіцӨПЎ°Cloze Procedure: A New Tool for Measuring ReadabilityЎұӨЗ1953ДкӨОХ“ОДЈ© BERTӨОКВЗ°С§Б•ўЩ http://jalammar.github.io /illustrated-bert/ 29/34
- 30. ? Next Sentence Prediction ? ЈІӨДӨООДХВӨ¬лOҪУӨ·ӨЖӨӨӨлӨ«ӨтөұӨЖӨл BERTӨОКВЗ°С§Б•ўЪ http://jalammar.github.io /illustrated-bert/ 30/34
- 31. Ў°For each task, we simply plug in the task-specific inputs and outputs into BERT and finetune all the parameters end-to-end.Ўұ Fine-tuningӨПКВЗ°С§Б•ңgӨЯҘвҘЗҘлӨтМШ¶ЁӨО ҘҝҘ№ҘҜУГӨЛФЩС§Б•Ө№ӨлӨіӨИӨтЦёӨ№ АэЈ© ҘҜҘйҘ№·ЦоҗӨЗӨПInputӨООДо^ӨЛ [CLS]ҘИ©`ҘҜҘуӨтЦГӨӯЈ®ӨҪӨОО»ЦГӨО BERTіцБҰӨЛҘНҘГҘИҘп©`ҘҜӨтӨ«ӨЮӨ»ӨЖУиңyӨ№Өл BERTӨОfine-tuning 31/34
- 33. ? BERTӨПҡшУГөДӨКNLPӨОКВЗ°С§Б•ҘвҘЗҘл ? …gјғӨКҘў©`ҘӯҘЖҘҜҘБҘгЈЁTransformerӨОEncoderӨтЦШӨНӨҝӨАӨұЈ© ? EncoderӨЗУ–ҫҡӨ№ӨлӨҝӨбӨЛMasked LMӨИәфӨРӨмӨлКЦ·ЁӨт’сУГӨ·Өҝ ? ОДГ}Өтҝј‘]Ө·Өҝ…gХZӨО·ЦЙўұн¬FӨ¬өГӨйӨмӨл ? өГӨйӨмӨҝ·ЦЙўұн¬FӨП·ЗіЈӨЛҸҠБҰӨЗЈ¬BERTӨОtop layerӨЛ …gјғӨКҫҖРОүд“QӨтЯBҪYӨ№ӨлӨАӨұӨЗЈ¬ҘҝҘ№ҘҜӨтҪвӨҜӨіӨИӨ¬ҝЙДЬ ? КВЗ°С§Б•ңgӨЯӨОBERTӨтfine-tuneӨ№ӨлӨіӨИӨЗ ӨўӨйӨжӨлNLPҘҝҘ№ҘҜӨтҪвӣQӨЗӨӯӨлЈҝ BERTӨЮӨИӨб 33/34
- 34. ІОҝјОДПЧЈЁХ“ОДТФНвЈ© Х“ОДҪвХh Attention Is All You Need (Transformer) ? http://deeplearning.hatenablog.com/entry/transformer ЧчӨГӨЖАнҪвӨ№Өл Transformer / Attention ? https://qiita.com/halhorn/items/c91497522be27bde17ce The Illustrated Transformer ? https://jalammar.github.io/illustrated-transformer/ Neural Machine Translation with Attention ? https://www.tensorflow.org/beta/tutorials/text/nmt_with_attention Transformer model for language understanding ? https://www.tensorflow.org/beta/tutorials/text/transformer The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) ? http://jalammar.github.io/illustrated-bert/ ҘјҘнӨ«ӨйЧчӨлDeep LearningўЪ - ЧФИ»СФХZ„IАнҫҺ ? ”ИМЩ ҝөТг, 2018/07/21, ҘӘҘйҘӨҘк©`Йз 34/34
- 36. ? Positional Encoding ??left ???, ? = sin(??? ? 1 10000 ?? 2 ????? ) ??right ???, ? = cos(??? ? 1 10000 ?? 2 ??????1 ) ё¶еhўЪ ???:әО·¬ДҝӨО…gХZӨ«, ? :…gХZВсӨбЮzӨЯұн¬FЦРӨОО»ЦГ ЈЁПИо^Ө«ӨйКэӨЁӨЖЈ©Ј¬?????Јә…gХZВсӨбЮzӨЯұн¬FӨОйLӨө ӨБӨКӨЯӨЛleftӨП? < ?????/2Ј¬rightӨП? ЎЭ ?????/2ӨтКҫӨ№ https://jalammar.github.io/illustrated-transformer/ 36/34
Editor's Notes
- #4: Seq2SeqӨЗAttentionӨИӨӨӨҰёЕДоӨ¬іхӨбӨЖіцӨЖӨӯӨҝЈ® ¬FФЪӨОAttentionӨИӨПЙЩӨ·Я`ӨҰЈ¬ӨҪӨО•rӨОAttentionӨ¬ӨЙӨОӨиӨҰӨКӨвӨОӨАӨГӨҝӨ«Ј® 2017ДкӨОAttention Is All You NeedӨПSeq2SeqӨЗAttentionӨ¬°kГчӨөӨмӨҝӨИӨӯӨ«Өй2ДкИхҪUӨГӨЖӨӨӨлЈ® ӨҪӨмӨЮӨЗӨЛAttentionӨ¬ӨЙӨОӨиӨҰӨКЯwТЖӨтӨҝӨЙӨГӨЖӨӯӨҝӨОӨ«Ј® ЧоббӨЛNLPӨОҡшУГөДӨККВЗ°С§Б•ҘвҘЗҘлӨЗӨўӨлBERTӨЛӨДӨӨӨЖФ’Ө№Ј®