SIGIR 2017: Extracting Hierarchies of Search Tasks & Subtasks via a Bayesian Nonparametric Approach

SIGIR 2017 talk Tokyo, Japan A significant amount of search queries originate from some real world information need or tasks [13]. In order to improve the search experience of the end users, it is important to have accurate representations of tasks. As a result, signi┬Ćcant amount of research has been devoted to extracting proper representations of tasks in order to enable search systems to help users complete their tasks, as well as providing the end user with be┬Ŗer query suggestions [9], for be┬Ŗer recommendations [41], for satisfaction prediction [36] and for improved personalization in terms of tasks [24, 38]. Most existing task extraction methodologies focus on representing tasks as ┬āat structures. However, tasks o┬ēen tend to have multiple subtasks associated with them and a more naturalistic representation of tasks would be in terms of a hierarchy, where each task can be composed of multiple (sub)tasks. To this end, we propose an e┬ücient Bayesian nonparametric model for extracting hierarchies of such tasks & subtasks. We evaluate our method based on real world query log data both through quantitative and crowdsourced experiments and highlight the importance of considering task/subtask hierarchies



![What is a Task?
ŌĆó A search task is an atomic information need resulting in one or more
queries [Jones and Klinkner, CIKM '08]
ŌĆó Complex search task: A set of related information needs, resulting in
one or more (possibly complex) tasks.
Credit
check
House buying
guide ŌĆ”
Houses
for sale
Loans for
house
17:00pm 17:02pm 17:06pm 18:15pm
Session 1 Session 2
Improve
credit
score
18:25pm](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-6-320.jpg)

![Extracting Search Tasks: Prior Work
Clustering session based queries [WSDM'11]](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-8-320.jpg)
![Extracting Search Tasks: Prior Work
q
1
q
2
q
3
q
4
q
6
q
5
q
1
q
2
q
3
q
4
q
6
q
5
q
0
Latent!
Clustering session based queries [WSDM'11] Structured Learning Approach [WWW'13]](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-9-320.jpg)
![Extracting Search Tasks: Prior Work
q
1
q
2
q
3
q
4
q
6
q
5
q
1
q
2
q
3
q
4
q
6
q
5
q
0
Latent!
Clustering session based queries [WSDM'11] Structured Learning Approach [WWW'13]
Hawkes Process based Task Extraction [KDD'14]](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-10-320.jpg)
![Extracting Search Tasks: Prior Work
q
1
q
2
q
3
q
4
q
6
q
5
q
1
q
2
q
3
q
4
q
6
q
5
q
0
Latent!
Clustering session based queries [WSDM'11] Structured Learning Approach [WWW'13]
Hawkes Process based Task Extraction [KDD'14] dd-CRPs for extracting subtasks [NAACLŌĆÖ16]](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-11-320.jpg)

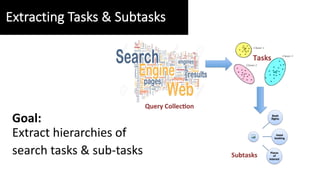


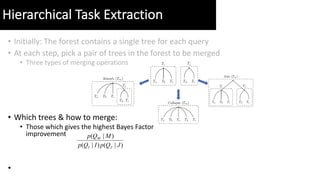
![Hierarchical Task Extraction
Bayesian non-parametric approach
ŌĆó Bayesian Rose Trees [UAIŌĆÖ10, NIPSŌĆÖ13]
ŌĆó Represents a set of partitions of the data (recursively)](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-16-320.jpg)


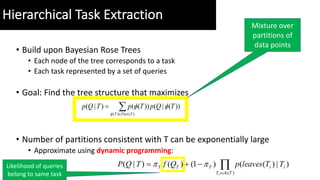





![ŌĆó Pairwise precision/recall:
ŌĆó LDA-TW performs worst
ŌĆó Too strong assumptions on queries belonging to
same task
ŌĆó Gains over QC-HTC/WCC
ŌĆó Query affinities can better reflect semantic
relationships
Experimental Evaluation ŌĆō I
[Search Task Identification]
Flattened version of hierarchy is useful too!](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-26-320.jpg)
![ŌĆó Evaluating task coherence:
ŌĆó Task Relatedness: Randomly pick 2 queries from a task, and
get judgments for task relatedness
ŌĆó Evaluating the hierarchy:
ŌĆó Valid hierarchy:
ŌĆó parent task ~ higher level task
ŌĆó children tasks ~ more focused subtasks
ŌĆó Useful hierarchy:
ŌĆó Is the subtask useful in completing the
overall search task?
Experimental Evaluation ŌĆō II
[Hierarchy Quality Evaluation]
Extracts tasks-subtasks which are Valid & Useful and have Related subtasks.](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-27-320.jpg)
![ŌĆó Indirect evaluation based on term
prediction
1. Construct hierarchy
2. Map to correct node in the hierarchy
3. Leverage node queries for term prediction
ŌĆó Assumption: identifying good tasks should
help in predicting future queries
ŌĆó Intersection of TREC Session track & AOL
log data
Experimental Evaluation ŌĆō III
[Term Prediction]
Outperforms flat-task extraction techniques as well as hierarchical baselines](https://image.slidesharecdn.com/sigir17talk2-170809025709/85/SIGIR-2017-Extracting-Hierarchies-of-Search-Tasks-Subtasks-via-a-Bayesian-Nonparametric-Approach-28-320.jpg)










![[KDD 2018 tutorial] End to-end goal-oriented question answering systems](https://cdn.slidesharecdn.com/ss_thumbnails/kdd2018tutorialend-to-endgoal-orientedquestionansweringsystems-180821081440-thumbnail.jpg?width=560&fit=bounds)



![[CS570] Machine Learning Team Project (I know what items really are)](https://cdn.slidesharecdn.com/ss_thumbnails/finalprojectpresentation11-130618082905-phpapp02-thumbnail.jpg?width=560&fit=bounds)

















More Related Content
Similar to SIGIR 2017: Extracting Hierarchies of Search Tasks & Subtasks via a Bayesian Nonparametric Approach (6)
More from Rishabh Mehrotra (9)
Recently uploaded (18)







![phase_4_presentation[1] - Read-Only.pptx Iot](https://cdn.slidesharecdn.com/ss_thumbnails/phase4presentation1-read-only-250301195122-ec11f187-thumbnail.jpg?width=560&fit=bounds)



SIGIR 2017: Extracting Hierarchies of Search Tasks & Subtasks via a Bayesian Nonparametric Approach
- 6. What is a Task? ŌĆó A search task is an atomic information need resulting in one or more queries [Jones and Klinkner, CIKM '08] ŌĆó Complex search task: A set of related information needs, resulting in one or more (possibly complex) tasks. Credit check House buying guide ŌĆ” Houses for sale Loans for house 17:00pm 17:02pm 17:06pm 18:15pm Session 1 Session 2 Improve credit score 18:25pm
- 7. Why Tasks?
- 12. Extracting Search Tasks: Prior Work Problems: ŌĆó Link query to on-going task = long chains ŌĆó impure tasks ŌĆó Rely on large corpus of pre-tagged queries ŌĆó Do not aggregate across users ŌĆó Tasks are not necessarily flat-structures ŌĆó complex tasks decompose into sub-tasks
- 15. Constructing Task Hierarchies ŌĆó Most previous work represents tasks as flat structures ŌĆó One possibility: Hierarchical clustering methods ŌĆó No guide on the correct number of clusters ŌĆó Most construct binary tree representations of data ŌĆó Need models that can represent trees with arbitrary branches ŌĆó Complexity is a major problem
- 17. ŌĆó Build upon Bayesian Rose Trees ŌĆó Each node of the tree corresponds to a task ŌĆó Each task represented by a set of queries Hierarchical Task Extraction
- 18. ŌĆó Build upon Bayesian Rose Trees ŌĆó Each node of the tree corresponds to a task ŌĆó Each task represented by a set of queries ŌĆó Goal: Find the tree structure that maximizes ├ź├Ä = )()( ))(|())(()|( TPartT TQpTpTQp f ff Hierarchical Task Extraction Mixture over partitions of data points
- 19. ŌĆó Build upon Bayesian Rose Trees ŌĆó Each node of the tree corresponds to a task ŌĆó Each task represented by a set of queries ŌĆó Goal: Find the tree structure that maximizes ŌĆó Number of partitions consistent with T can be exponentially large ŌĆó Approximate using dynamic programming: ├ź├Ä = )()( ))(|())(()|( TPartT TQpTpTQp f ff Hierarchical Task Extraction Likelihood of queries belong to same task )|)(()1()()|( )( ii TchT TTT TTleavespQfTQP i ├Ģ├Ä -+= pp Mixture over partitions of data points
- 20. Data Likelihood: Query to Query Affinity r1: Query term based affinity ŌĆó Lexical similarity between queries r2: URL based affinity ŌĆó Similarity between the returned URLs r3: User/Session based affinity ŌĆó Query co-occurrence in the same session ├Ģ ├ź ├ź = = ├Ä ├Ä = 3 1 ||...1 ||...1 , ),|()( k k Qi Qj kkqq k jirpQf ba
- 22. ŌĆó Initially: The forest contains a single tree for each query ŌĆó At each step, pick a pair of trees in the forest to be merged ŌĆó Three types of merging operations Hierarchical Task Extraction
- 23. ŌĆó Initially: The forest contains a single tree for each query ŌĆó At each step, pick a pair of trees in the forest to be merged ŌĆó Three types of merging operations ŌĆó Which trees & how to merge: ŌĆó Those which gives the highest Bayes Factor improvement ŌĆó )|()|( )|( JQpIQp MQp JI M Hierarchical Task Extraction
- 24. ŌĆó Initially: The forest contains a single tree for each query ŌĆó At each step, pick a pair of trees in the forest to be merged ŌĆó Three types of merging operations ŌĆó Which trees & how to merge: ŌĆó Those which gives the highest Bayes Factor improvement ŌĆó Tree Pruning: ŌĆó node that represents a coherent task should not be split further ŌĆó Prune trees based on task coherence )|()|( )|( JQpIQp MQp JI M )()( ),( log),( 21 21 21 wpwp wwp wwPMI = Hierarchical Task Extraction
- 25. ŌĆó Experiment 1: Search task identification ŌĆó Experiment 2: Crowd-sourced evaluation of hierarchy ŌĆó Experiment 3: Term prediction application Baselines: 1. Bestlink-SVM 2. QC-WCC/QC-HTC 3. LDA-Hawkes 4. LDA-TW 5. Jones hierarchy 6. BHCD: Bayesian Hierarchical Community Detection 7. Bayesian agglomerative clustering Experimental Evaluation Task extraction baselines Hierarchical model baselines
- 26. ŌĆó Pairwise precision/recall: ŌĆó LDA-TW performs worst ŌĆó Too strong assumptions on queries belonging to same task ŌĆó Gains over QC-HTC/WCC ŌĆó Query affinities can better reflect semantic relationships Experimental Evaluation ŌĆō I [Search Task Identification] Flattened version of hierarchy is useful too!
- 27. ŌĆó Evaluating task coherence: ŌĆó Task Relatedness: Randomly pick 2 queries from a task, and get judgments for task relatedness ŌĆó Evaluating the hierarchy: ŌĆó Valid hierarchy: ŌĆó parent task ~ higher level task ŌĆó children tasks ~ more focused subtasks ŌĆó Useful hierarchy: ŌĆó Is the subtask useful in completing the overall search task? Experimental Evaluation ŌĆō II [Hierarchy Quality Evaluation] Extracts tasks-subtasks which are Valid & Useful and have Related subtasks.
- 28. ŌĆó Indirect evaluation based on term prediction 1. Construct hierarchy 2. Map to correct node in the hierarchy 3. Leverage node queries for term prediction ŌĆó Assumption: identifying good tasks should help in predicting future queries ŌĆó Intersection of TREC Session track & AOL log data Experimental Evaluation ŌĆō III [Term Prediction] Outperforms flat-task extraction techniques as well as hierarchical baselines
- 29. ŌĆó Hierarchies provide a more naturalistic view of complex tasks ŌĆó Bayesian non-parametric approach for hierarchy extraction ŌĆó Coherence based pruning helps identify atomic tasks ŌĆó Richer & more expressive models of tasks ŌĆó Valid, useful hierarchy with related subtasks Take-Home Message
- 31. Thank You! Rishabh Mehrotra PhD candidate @ UCL http://rishabhmehrotra.com @erishabh r.mehrotra@cs.ucl.ac.uk Summary: - Naturalistic view of tasks-subtasks - Nonparametric approach - Coherence pruning helps - Richer & more expressive Future Work: - Evaluation techniques for hierarchies - Mapping to correct level in hierarchy - Subtask sequences & transitions