




























![Spark ML ?? Pain Point ???? #4
? Disk ?? ??
? Machine Learning ? ?? ?? ????? ??, ?? ??? Input
???? ????, ??? ??? ?? Node ? ?? Disk ? Full ?
????? ???? ??? ??.
? [???]
? Hyper-Parameter ? ?? Trade Off
? Hybrid Cloud ??? ??
? Mesos Cluster ?? ( Yarn Cluster ??? Hadoop Node ??? dependency?
???, Mesos Cluster ? ?? ? ??? ?? ? ??. ?, NoSQL Cluster ? ?
? ?? )](https://image.slidesharecdn.com/sparkmachinelearningdeepdivehoondongkim20170225-merge-170303071741/85/Spark-machine-learning-deep-learning-49-320.jpg)












![[????] Color space gamma correction](https://cdn.slidesharecdn.com/ss_thumbnails/colorspacegammacorrection-181201032300-thumbnail.jpg?width=560&fit=bounds)





![Q-Learning Algorithm: A Concise Introduction [Shakeeb A.]](https://cdn.slidesharecdn.com/ss_thumbnails/q-learningshakeebabuzarmustafasneha-200921155609-thumbnail.jpg?width=560&fit=bounds)



![[Ndc11 ???] deferred shading](https://cdn.slidesharecdn.com/ss_thumbnails/ndc11deferredshading-110602220043-phpapp01-thumbnail.jpg?width=560&fit=bounds)



![[NDC19] ????? ????? ??? ??? ???? PBR ??? ???](https://cdn.slidesharecdn.com/ss_thumbnails/ndc19unitycustomsubstancepbrshadermadumpa-190506140539-thumbnail.jpg?width=560&fit=bounds)








![[D2 COMMUNITY] Spark User Group - ???? ?? ??? ??? ??](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=560&fit=bounds)

More Related Content
What's hot (20)
Viewers also liked (10)








Similar to Spark machine learning & deep learning (20)


![NDC 2016, [???] ???? ??? ?? ??? ??????](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-2016-160429031551-thumbnail.jpg?width=560&fit=bounds)

![[AI & DevOps] BigData Scale Production AI ???? ?? ??? ??? ????](https://cdn.slidesharecdn.com/ss_thumbnails/msfuturenowaidevopsbestplatform-181117103331-thumbnail.jpg?width=560&fit=bounds)



![[246] foursquare??????????????????? ?????????](https://cdn.slidesharecdn.com/ss_thumbnails/246foursquare-161025031706-thumbnail.jpg?width=560&fit=bounds)
![[215]????????????????????????????? ????????](https://cdn.slidesharecdn.com/ss_thumbnails/215-161025030904-thumbnail.jpg?width=560&fit=bounds)



![[??????]MongoDB ? ??](https://cdn.slidesharecdn.com/ss_thumbnails/mongodb-171107063223-thumbnail.jpg?width=560&fit=bounds)






Spark machine learning & deep learning
- 1. Spark Machine Learning Deep Dive (feat. Deep Learning) ???(Spark Korea User Group) ???
- 2. Who am I ? ? ??? Chief Partner ( hoondongkim@emart.com ) ? ??? ?? ??? ?? SSG.COM ????? ?? ? Hadoop, Spark, Machine Learning, Azure ML ?? Microsoft MVP(Most Valuable Professional) ? Major in BigData RealTime Analytics & NoSQL ? http://hoondongkim.blogspot.kr
- 3. I will say ĪŁ ? Spark Cluster ?? ?? ? ??? ?? ? Spark? ?? Machine Learning ? ??? ? ??? ?? ? Machine Learning & Deep Learning ????? Spark? ?? ? Spark ? ???? ??? ?? ? ??? ? Spark ???? Deep Learning ??? ??? ??
- 4. ?? ?? ??? ???ĪŁ
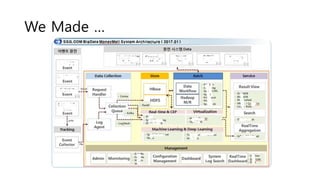
- 5. We Made ĪŁ
- 6. So What? He said Ī░??? ?????Ī▒
- 7. ???, ?? ?? ???? ??! ©C ?? ?? ?? ? ??? ?? ??. (BigData Eco System Infra) ? ??? ??? ???. ? ???? ?? ?? ??? ?? ???? ???. ? ???? ??? ?? ??? ??? ?? ???? ??. ? ??? ?? ??. (RealTime Layer / Spark Streaming / ELK) ? ????? ??? ???? ????. ? FDS, ????, ???? ? ????? ?? ??? ???? ??? ????? ????. ? ??? ?? ??. (Mining / Machine Learning / Deep Learning) ? ??? ?? ?? ?? ? ? ? ?? ?? ????. ? ??? ??? ?? ? ?? ?? ??? ?? ROI ?? ????. ? ??? ????. ? ??? ?? ??? ????. ? ??? ??? ?? ??? ???? ??? ??? ????. ? ??? ?? ??. (Machine Learning / Deep Learning) ? Chatbot ? ??? ??, ??? ?? -> ?? ? ?? ??? ? ?? 3~4? ? 2~3? ? ??
- 8. BigData ? ?? ??
- 9. BigData ? ?? ??
- 10. BigData + Deep Learning Approach
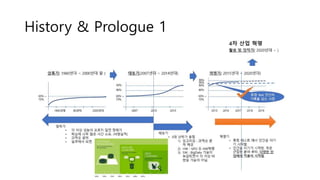
- 11. History & Prologue 1
- 12. History & Prologue 2
- 13. History & Prologue 3
- 14. Google
- 15. ???? AI??? ??? ??! ?? Math ? ??,????,???? ??? PH.D ? ???? ? ??? ?? ?? ? Develop Sprit ?? ?? ??? Base? Data Scientist? ???? ??? ??? ???! ??ĪŁ
- 16. ?? ???? ????! vs ?? ??? ????! Are you Data Scientist? ??? ???? ??? ??? ?? ???? ??? ? ??? ? ??? ????
- 17. ??? ?? ? ??ĪŁ
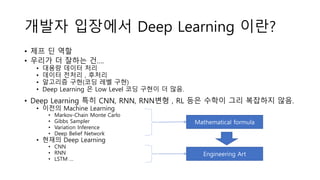
- 18. ??? ???? Deep Learning ??? ? ?? ? ?? ? ??? ? ??? ?ĪŁ. ? ??? ??? ?? ? ??? ??? , ??? ? ???? ??(?? ?? ??) ? Deep Learning ? Low Level ?? ??? ? ??. ? Deep Learning ?? CNN, RNN, RNN?? , RL ?? ??? ?? ???? ??. ? ??? Machine Learning ? Markov-Chain Monte Carlo ? Gibbs Sampler ? Variation Inference ? Deep Belief Network ? ??? Deep Learning ? CNN ? RNN ? LSTM ĪŁ Mathematical formula Engineering Art
- 19. Spark ? Position! - Spark ???? BigData Scale ML Job? ???? ????!
- 20. Spark ? Position! - Spark ???? BigData Scale ML Job? ???? ????!
- 21. Spark ML ? ????? ?? ??? ? ?? ??! ?? ?????
- 23. Spark ?? ? Scala ? Java ? Python ? R
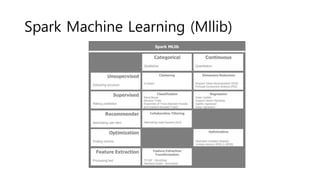
- 25. Spark Machine Learning (Mllib)
- 26. ??? ?? ?? ?? ? Scala + Java ? PySpark + Python ? SparkR + RevoScaleR(MS R) + CRAN-R
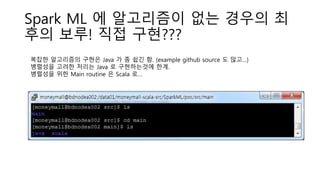
- 27. Spark ML ? ????? ?? ??? ? ?? ??! ?? ????? ??? ????? ??? Java ? ? ?? ?. (example github source ? ??ĪŁ) ???? ??? ??? Java ? ?????? ??. ???? ?? Main routine ? Scala ?ĪŁ
- 28. ??? ?? ?? ??
- 29. ??? ?? ?? ??
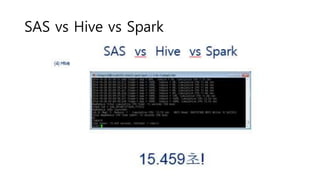
- 30. SAS vs Hive vs Spark
- 31. SAS vs Hive vs Spark
- 32. SAS vs Hive vs Spark
- 33. SAS vs Hive vs Spark
- 34. SAS vs Hive vs Spark
- 35. ?? ? ??(SAS vs Hive vs Spark)
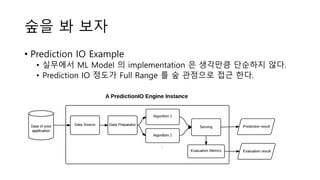
- 36. ?? ? ?? ? Prediction IO Example ? ???? ML Model ? implementation ? ???? ???? ??. ? Prediction IO ??? Full Range ? ? ???? ?? ??.
- 37. R on Spark ? ??? ? SparkR ? Sparklyr ? RevoScaleR(MS R)
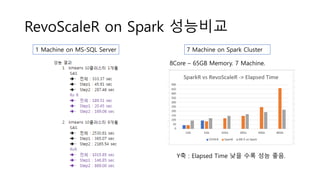
- 38. RevoScaleR on Spark ???? 1 Machine on MS-SQL Server 7 Machine on Spark Cluster Y? : Elapsed Time ?? ?? ?? ??. 8Core ©C 65GB Memory. 7 Machine.
- 39. Python Machine Learning on Spark
- 40. Spark Machine Learning ?? ???
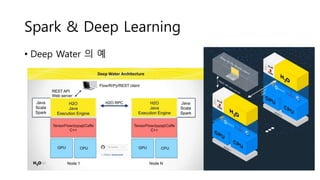
- 41. Spark & Deep Learning ? Deep Water ? ?
- 42. Spark & Deep Learning ? BigDL ?
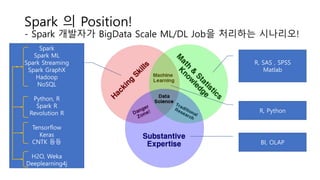
- 43. Spark Deep Learning Deep Dive ? Keras + Tensorflow + Spark : elephas
- 44. Spark Deep Learning Deep Dive
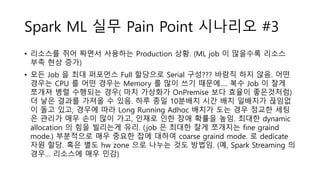
- 45. Spark ? Position! - Spark ???? BigData Scale ML/DL Job? ???? ????! R, SAS , SPSS Matlab R, Python BI, OLAP Spark Spark ML Spark Streaming Spark GraphX Hadoop NoSQL Python, R Spark R Revolution R Tensorflow Keras CNTK ?? H2O, Weka Deeplearning4j
- 46. Spark ML ?? Pain Point ???? #1 ? ??? & CPU ??? ?? ??(?? ??? ??? ?? ????? ???.) ? ML ??? CPU ??? ? ?? ? Yarn mode vs Mesos Mode vs Stand Alone ? Hadoop ??? ?? eco system ? 1/5 ? 1/3? ?? mesos ? ? ???? ????? ??. ?? ??? ??? ??? ???? ?? ??? ??? ?? ??? ???? ? ?. ? Mesos ? Off heap ? ???? ?? ? ??. CPU? Memory, Executor ? ???? ? ? ???? ????. ??? Job ???? ?? Elastic ?.( yarn ?? ? ??? ??? ? ??. Fine Grain ????). ?? Yarn ? Dynamic Allocation ?? ? ????? ??. ?? ???? ??? ??? ? ??. Mesos ? ?? Dynamic ?. But ??? ?? ? ?? ??. ? Dynamic ??? Overhead ? ? ?? ?. ? ??? Spark 2.x ??? ? ???. Mesos ? Dynamic Allocation ????? ????.) -> ??? ? ????? run ??? mesos ? spark.scheduler.mode = FAIR ??? ??? ??, Yarn ? Yarn ? ??? ??? Fair ????? ???? ?? ??? ??? ??.
- 47. Spark ML ?? Pain Point ???? #2
- 48. Spark ML ?? Pain Point ???? #3 ? ???? ?? ??? ???? Production ??. (ML job ? ???? ??? ?? ?? ??) ? ?? Job ? ?? ???? Full ???? Serial ????? ??? ?? ??. ?? ??? CPU ? ?? ??? Memory ? ?? ?? ???ĪŁ. ?? Job ? ?? ??? ?? ???? ??( ?? ???? OnPremise ?? ??? ?????) ? ?? ??? ??? ? ??. ?? ?? 10??? ?? ?? ???? ??? ? ?? ??, ??? ?? Long Running Adhoc ??? ?? ?? ??? ?? ? ??? ?? ?? ?? ??, ??? ?? ?? ??? ??. ??? dynamic allocation ? ?? ???? ??. (job ? ??? ?? ???? fine graind mode.) ????? ?? ??? ?? ??? coarse graind mode. ? dedicate ?? ??. ?? ?? hw zone ?? ??? ?? ???. (?, Spark Streaming ? ??ĪŁ ???? ?? ??)
- 49. Spark ML ?? Pain Point ???? #4 ? Disk ?? ?? ? Machine Learning ? ?? ?? ????? ??, ?? ??? Input ???? ????, ??? ??? ?? Node ? ?? Disk ? Full ? ????? ???? ??? ??. ? [???] ? Hyper-Parameter ? ?? Trade Off ? Hybrid Cloud ??? ?? ? Mesos Cluster ?? ( Yarn Cluster ??? Hadoop Node ??? dependency? ???, Mesos Cluster ? ?? ? ??? ?? ? ??. ?, NoSQL Cluster ? ? ? ?? )
- 50. Spark ML ?? Pain Point ???? #5 ? IO ?? ?? ? ???? Computer Science ??? ?? Spark ??? IO ??? ?? ? ??. ? ?? ??? ???? ?? File Operation ? ?? ? IO ??? ?? ? ???, ?? ?? ?? ???? Network Card ? ????? ? ? ??. ? 1G ??? 10G ? ??. ?? ??? 10G 2? ?? 4? ? ?? ?? ?? ?? ??. ? Spark ? ?? ? ?? 15~20% ??? ?? ??? ??.(?? ??? ??? ??? ??) ? Network ?? ??? ??? ?????, 20% ?? ?? ??? ?? ??? ?? ??. ??? ??? ??? CPU, Memory , IO ?? ?? ??? ??.
- 51. Spark ML ?? Pain Point ???? #6 ? BigData Scale Data Load ??? ???? ? ??? Map/Reduce ? ? ??. ? ???? ?? Choice ? Hadoop Streaming ? Pig, Hive ? ? Clojure ??? Cascalog, Scala ??? Scalding ? ? Map/Reduce Wrapping ??? Data ? ???, ?? ?? ??? ? Spark ML ??. ? ???? ??? BigData Scale ? Input ? ???? ?? ? Popular ????? Mahout? ?? (?? ?? ?? ? ??? ? ??) ? Weka, DeepLearning4J , H2O , Sparkling Water ? ?? Tool ? Support ?? ? ??
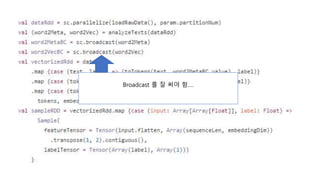
- 52. Spark ML ?? Pain Point ???? #7 ? ?? ??? ? ?? Model ? Hyper Parameter ? ??? ??? ??? ?. ? Driver Memory, Executor Memory ? ??? ??? ??? ?. ? Data ? BroadCast. ? ??? ?? Heavy Computing ? ??????, ?? ?? ? ???? ?.
- 53. Broadcast ? ? ?? ?ĪŁ.
- 54. Spark ML ?? Pain Point ???? #8 ? ?? ?? ??? ?? ??? ?????? ?? IO Over Head ?? ? File Write ????? Map ? RDD.saveAsTextFile(HDS_PATH) ? ?? ? Spark ML / Spark SQL Data Load ????? RDD.coalesce(1).saveAsTextFile(HDS_PATH) ? ?? ? File ? ???? ?? ??? coalesce(1) ?? Write ?? roading ?? ??, writing ?? Map/Reduce ? Merge ? ? ??.
- 55. Spark ML ?? Pain Point ???? #9 ? ???? ?? ?? ? ?? ? feature selection ???? ??? ????? ??? ??? ??? ?? ??? ? ??? ??. ? Spark ML ? ???? ?????? ??? ?? Popular ??, ??? ?? ????? ?? ????? 1? ?? ??. ? ?? ??? ??? ?? ???? ???? ??. ? ???? Selection ? Python ?? R ? Support ????? ? ??? ???? ? ??. ? ????? ????, ?? ????? Spark ML ? ???? ?? ? ???? ?? Spark ML ? Production ? ??. ? ?, R ? 2? 3? ??? ??? Spark ML ? ?? ?? ? ??. ? ?, ??? ?? ???? ?? ???? ?? ??? ??. Production ?? ?? ?? ??? ??.
- 56. Spark ML ?? Pain Point ???? #10 ? ????? ????? ???? ?? ?? ? ?? ????? ?????, ?? ???? ????, ?? ?? ?? ?? ???? ?? ??? ??. ? Word2Vec ? ? ? FP-Growth ? ?
- 57. Spark ML ?? Pain Point ???? #11 ? ????? ???? ?? ??. (ML ? ??) ? ????? ???? ?? ??. (Deep Learning ? ??)
- 58. ??. ? Deep Learning ? ?? ? http://ankivil.com/choosing-a-deep-learning-software/ ? ??? ????? ?? ?? ? https://tensorflow.blog/2017/02/13/chainer-mxnet-cntk-tf- benchmarking/ ? Keras ? ?? 2 ?? ?? ??. ? CNTK ? Keras ???? ? ?. ? Keras ? Tensorflow ?? ???? ????
Editor's Notes
- #4: ?? ? ??? ??? ????? ???.
- #5: SSG ?? ?? ??
- #6: ?? spark ?? ??? Spark Job, Spark R , Spark Streaming , Machine Learning & Deep Learning ?? Spark ML ??? 3?? ???? ?? ??? ??? Spark ML ,??? Deep Learning ??? ?? ? ??? ??? ????, ??? ?? ?? ?? ??? ?? ??? ???? ??? ?? ??? Spark? ????? ??? ????? ?????.
- #47: Disk ??? Hyper-Parameter ? ???? ???? ??. Trade Off. - IO ??? ??? ??. ??? IO ??? ??? ??? ???, (??? ?? ?? ???? ???) Network ??? 10G? ???, ?? 10G ??? 2? ~ 4? ?? ????? 15~20% ??? ?? ??? ???. Network ?? ??? ??? ?????, 20% ?? ?? ??? ?? ??? ?? ??. ??? ??? ??? CPU, Memory , IO ?? ????? ??.
- #50: Disk ??? Hyper-Parameter ? ???? ???? ??. Trade Off. - IO ??? ??? ??. ??? IO ??? ??? ??? ???, (??? ?? ?? ???? ???) Network ??? 10G? ???, ?? 10G ??? 2? ~ 4? ?? ????? 15~20% ??? ?? ??? ???. Network ?? ??? ??? ?????, 20% ?? ?? ??? ?? ??? ?? ??. ??? ??? ??? CPU, Memory , IO ?? ????? ??.
- #51: - IO ??? ??? ??. ??? IO ??? ??? ??? ???, (??? ?? ?? ???? ???) Network ??? 10G? ???, ?? 10G ??? 2? ~ 4? ?? ????? 15~20% ??? ?? ??? ???. Network ?? ??? ??? ?????, 20% ?? ?? ??? ?? ??? ?? ??. ??? ??? ??? CPU, Memory , IO ?? ????? ??.
- #59: Tensorflow ? ??? ?? GPU + ???? ? ???. ( ?? ?? Theano , Torch ? ???? ??? ?. ) Lua ??? Python ( Torch ? ?? ??ĪŁ ) Tensorflow Serving Scikit flow (?? Tensorflow ? ???. TF.Learn ???. Scikit Learn ??? Tensorflow Wrapper API)