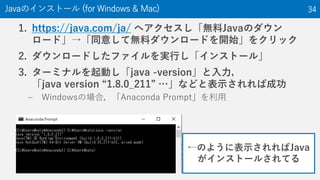
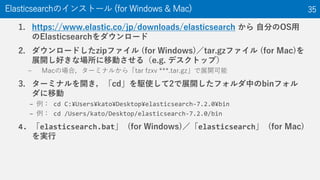
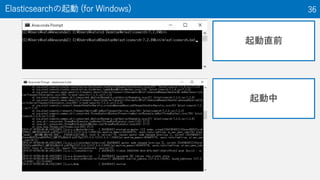
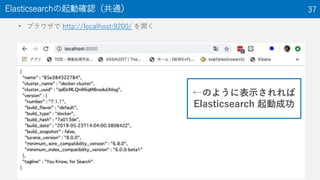
The document discusses the Optuna hyperparameter optimization framework, highlighting its features like define-by-run, pruning, and distributed optimization. It provides examples of successful applications in competitions and introduces the use of LightGBM hyperparameter tuning. Additionally, it outlines the installation procedure, key components of Optuna, and the introduction of the lightgbmtuner for automated optimization.
The document discusses the Optuna hyperparameter optimization framework, highlighting its features like define-by-run, pruning, and distributed optimization. It provides examples of successful applications in competitions and introduces the use of LightGBM hyperparameter tuning. Additionally, it outlines the installation procedure, key components of Optuna, and the introduction of the lightgbmtuner for automated optimization.
The document discusses the introduction of context-guided learning (CGL) as a method for ranking entities using numerical attributes and contextual information. It highlights the challenges of overfitting when training data is limited and how CGL can improve ranking accuracy by leveraging contextual factors. Experimental results demonstrate that CGL significantly enhances the learning process in ranking tasks across various entity types and criteria.
1. Makoto P. Kato is a professor at the University of Tsukuba who researches music information retrieval and cross-domain information retrieval.
2. His lab website provides information on his background, publications, and research projects which use techniques like domain adaptation and relative aggregation points for cross-domain retrieval tasks.
3. Some of his recent work includes developing a method for searching for unknown music by mixing known music clips together, as well as applying domain adaptation methods to transfer knowledge across domains like GDP statistics and product reviews.
Two-layered Summaries for Mobile Search: Does the Evaluation Measure Reflect ...kt.mako
?
This document investigates the effectiveness of a two-layered summarization approach for mobile search, focusing on user preferences and evaluating the new m-measure metric. It discusses the role of intent probabilities in user satisfaction and provides experimental results showing high agreement between the m-measure and user preferences. The findings highlight the importance of both summarization layers, particularly the second layer, in influencing perceived summary quality.
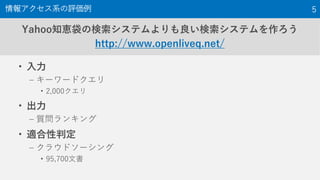
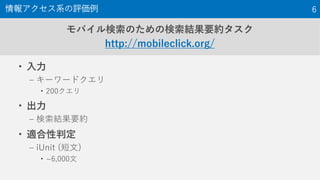
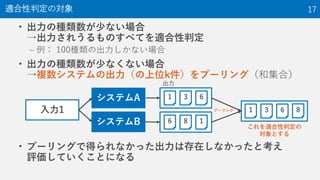
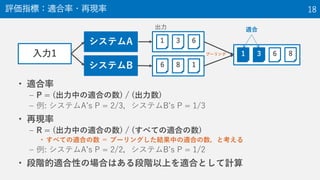
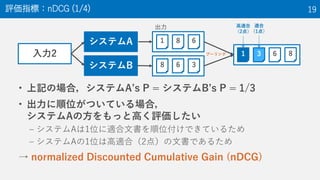
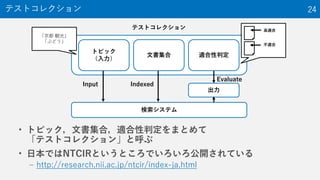
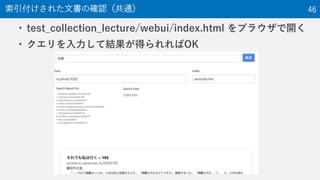
The document provides an overview of the NTCIR-12 MobileClick-2 Task, which included two subtasks: iUnit ranking and iUnit summarization. For iUnit ranking, participants ranked iUnits (information pieces relevant to a query) based on estimated importance. For iUnit summarization, participants generated a two-layered summary given a query, iUnits, and intents (interpretations of an ambiguous query). The task used queries, documents, and extracted iUnits. iUnits were evaluated based on importance ratings. Summaries were evaluated using M-measure, which considers the expected usefulness of multiple reading paths. Results showed similar performance across most runs for both English and Japanese iUnit ranking.
NTCIR is a series of evaluation workshops designed to enhance research in information access technologies. The NTCIR-12 workshop was held in June 2016 in Tokyo, Japan. The MobileClick-2 task at NTCIR-12 included two subtasks: an iUnit ranking subtask that evaluated systems' ability to predict the importance of information snippets for a given query, and an iUnit summarization subtask to generate a two-layer summary of information snippets and subtopics. The MobileClick-2 task schedule included releasing the test queries in August 2015 and a submission deadline in December 2015.
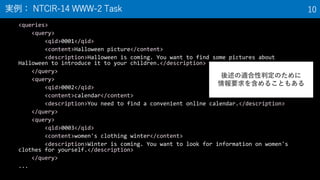
10. <queries>
<query>
<qid>0001</qid>
<content>Halloween picture</content>
<description>Halloween is coming. You want to find some pictures about
Halloween to introduce it to your children.</description>
</query>
<query>
<qid>0002</qid>
<content>calendar</content>
<description>You need to find a convenient online calendar.</description>
</query>
<query>
<qid>0003</qid>
<content>women's clothing winter</content>
<description>Winter is coming. You want to look for information on women's
clothes for yourself.</description>
</query>
...
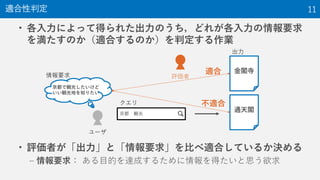
実例: NTCIR-14 WWW-2 Task 10
後述の適合性判定のために
情報要求を含めることもある
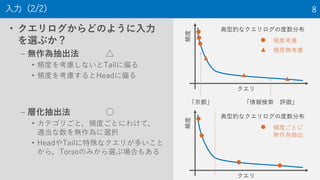
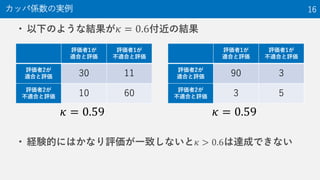
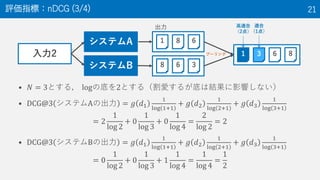
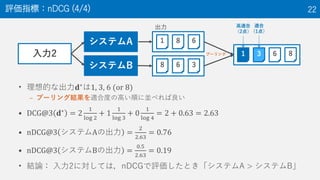
13. 段階的適合性(NTCIR-9 INTENT-1 Taskの例) 13
? Highly relevant (2点)
– The document fully satisfies the
information need
? Relevant (1点)
– The document only partially
satisfies the information need
? Non-relevant (0点)
金閣寺
通天閣
出力
近畿の
お寺
Highly relevant
Relevant
Non-relevant
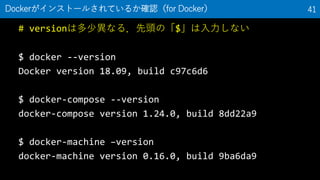
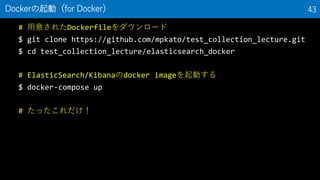
41. # versionは多少異なる.先頭の「$」は入力しない
$ docker --version
Docker version 18.09, build c97c6d6
$ docker-compose --version
docker-compose version 1.24.0, build 8dd22a9
$ docker-machine –version
docker-machine version 0.16.0, build 9ba6da9
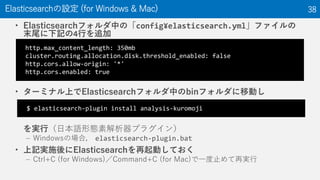
Dockerがインストールされているか確認(for Docker) 41
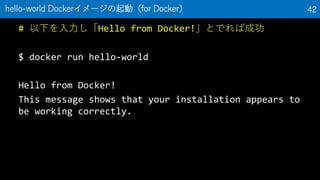
42. # 以下を入力し「Hello from Docker!」とでれば成功
$ docker run hello-world
Hello from Docker!
This message shows that your installation appears to
be working correctly.
hello-world Dockerイメージの起動(for Docker) 42
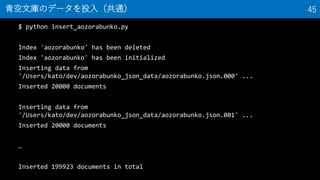
45. $ python insert_aozorabunko.py
Index 'aozorabunko' has been deleted
Index 'aozorabunko' has been initialized
Inserting data from
'/Users/kato/dev/aozorabunko_json_data/aozorabunko.json.000' ...
Inserted 20000 documents
Inserting data from
'/Users/kato/dev/aozorabunko_json_data/aozorabunko.json.001' ...
Inserted 20000 documents
…
Inserted 199923 documents in total
青空文庫のデータを投入(共通) 45