Vae gan nlp
2 likes1,777 views
This slides are description for paper of Generating Natural language by VAE an GANs
1 of 23
Downloaded 26 times













Ad
Recommended
Ą┌Ż│╗žnipsšiż▀╗ß?ķv╬„Ī║variational inference foundations and modern methodsĪ╗
Ą┌Ż│╗žnipsšiż▀╗ß?ķv╬„Ī║variational inference foundations and modern methodsĪ╗koji ochiai
?
Ą┌Ż│╗žnipsšiż▀╗ßżŪż╬░k▒Ē┘Y┴ŽżŪż╣ĪŻ
ź¬źĻźĖź╩źļ┘Y┴ŽżŽęįŽ┬ż╬ż╚ż¬żĻĪŻ
ż▐ż╚żß
https://nips.cc/Conferences/2016/Schedule?showEvent=6199
Video
https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Variational-Inference-Foundations-and-Modern-Methods
║▌║▌▀Ż(PDF)
https://media.nips.cc/Conferences/2016/║▌║▌▀Żs/6199-║▌║▌▀Żs.pdf
▒ß▓Ō▒Ķ▒░∙┤Ū▒Ķ│┘ż╚żĮż╬ų▄▐xż╦ż─żżżŲ
▒ß▓Ō▒Ķ▒░∙┤Ū▒Ķ│┘ż╚żĮż╬ų▄▐xż╦ż─żżżŲKeisuke Hosaka
?
Hyperoptż╬įŁšō╬─ż“šiż¾żŪHyperoptż“ĮŌšhżĘż┐┘Y┴ŽżŪż╣ĪŻ
Ė┼ꬿ└ż▒żŪż╩ż»╝Üż½żżż╚ż│żĒżŌżŪżŁżļż└ż▒šh├„ż╣żļżĶż”ż╦żĘżŲżżż▐ż╣ĪŻźŽ?źżź╩źĻź╦źÕ®`źķźļź═ź├ź╚ż╚źŽ®`ź╚?ź”ź¦źóż╬ķvéS
źŽ?źżź╩źĻź╦źÕ®`źķźļź═ź├ź╚ż╚źŽ®`ź╚?ź”ź¦źóż╬ķvéSKento Tajiri
?
╚½├Śźó®`źŁźŲź»ź┴źŃ╚¶╩ųż╬╗ß Ą┌26╗ž├ŃÅŖ╗ß
░k▒ĒĪĪĪĪŻ║ų■▓©┤¾č¦ĪĪ╠’ÕĻ ĮĪČĘ
źßź¾ź┐®`Ż║┤¾┌µ┤¾č¦ĪĪ╬„╠’ ╣ń╬ß
ĪĪĪĪĪĪĪĪĪĪ¢|Š®┤¾č¦ĪĪ░╦─Š ═žšµ
pdf╗»ż╬ļHē▓żņżŲżĘż▐ż├ż┐ćĒż╩ż╔ż¼żóżĻż▐ż╣ż╬żŪßß╚šėåš²żĘż▐ż╣
7/9:ėåš²żĘż▐żĘż┐├©żŪżŌĘųż½żļVariational AutoEncoder
├©żŪżŌĘųż½żļVariational AutoEncoderSho Tatsuno
?
╔·│╔źŌźŪźļż╚ż½ż“żóż▐żĻų¬żķż╩żż╚╦ż╦żŌż╩żļż┘ż»Ęųż½żĻżõż╣żżšh├„ż“ą─ż¼ż▒ż┐Variational AutoEncoderż╬ź╣źķźżź╔
īgū░ż╚║åģgż╩čaūŃżŽęįŽ┬ż“▓╬šš
http://sh-tatsuno.com/blog/index.php/2016/07/30/variationalautoencoder/šō╬─ĮBĮķŻ║ĪĖEnd-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRFĪ╣
šō╬─ĮBĮķŻ║ĪĖEnd-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRFĪ╣Naonori Nagano
?
蹊┐╩ęż╬▌åųvż╬šō╬─ĮBĮķżŪė├żżż┐░k▒Ēź╣źķźżź╔żŪż╣ĪŻ
šō╬─ĮBĮķŻ║ĪĖEnd-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRFĪ╣│ę▒╩▒½╔ŽżŪż╬▒Ę│ó▒╩Ž“ż▒╔Ņ▓Ń覎░ż╬īgū░ż╦ż─żżżŲ
│ę▒╩▒½╔ŽżŪż╬▒Ę│ó▒╩Ž“ż▒╔Ņ▓Ń覎░ż╬īgū░ż╦ż─żżżŲYuya Unno
?
│ę▒╩▒½Ž“ż▒ż╦▒Ę│ó▒╩ż╬╔Ņ▓Ń覎░ż“īgąąż╣żļ│Ī║Žż╬╣żĘ“ż╦ż─żżżŲ░õ│¾▓╣Š▒▓į▒░∙żŪ┴„╠Õ╝Ų╦Ń
░õ│¾▓╣Š▒▓į▒░∙żŪ┴„╠Õ╝Ų╦ŃPreferred Networks
?
Deep Learningźšźņ®`źÓź’®`ź»ż╬Chainerż“╩╣ż├żŲ┴„╠Õėŗ╦Ńż“żõż├żŲż▀ż┐Deep learning├ŃÅŖ╗ß20121214ochi
Deep learning├ŃÅŖ╗ß20121214ochiOhsawa Goodfellow
?
Deep Learning ├ŃÅŖ╗ß┘Y┴ŽżŪż╣ĪŻhttps://sites.google.com/site/deeplearning2013/Practical recommendations for gradient-based training of deep architectures
Practical recommendations for gradient-based training of deep architecturesKoji Matsuda
?
Yoshua Bengio, Practical recommendations for gradient-based training of deep architectures, arXiv:1206.5533v2, 2012 ż╬ĮŌšh[DL▌åši╗ß]Flow-based Deep Generative Models
[DL▌åši╗ß]Flow-based Deep Generative ModelsDeep Learning JP
?
2019/03/08
Deep Learning JP:
http://deeplearning.jp/seminar-2/ [DL▌åši╗ß]Convolutional Sequence to Sequence Learning
[DL▌åši╗ß]Convolutional Sequence to Sequence LearningDeep Learning JP
?
2017/5/19
Deep Learning JP:
http://deeplearning.jp/seminar-2/
[DL▌åši╗ß]A closer look at few shot classification
[DL▌åši╗ß]A closer look at few shot classificationDeep Learning JP
?
2019/03/01
Deep Learning JP:
http://deeplearning.jp/seminar-2/ [DL▌åši╗ß]QUASI-RECURRENT NEURAL NETWORKS
[DL▌åši╗ß]QUASI-RECURRENT NEURAL NETWORKSDeep Learning JP
?
2017/5/12
Deep Learning JP:
http://deeplearning.jp/seminar-2/
┤Ī│▄│┘┤Ū▒▓į│”┤Ū╗Õ▒░∙ż╬īgū░ż╚ėõ┐ņż╩ų┘╝õż╚ż╬▒╚ĮŽ
┤Ī│▄│┘┤Ū▒▓į│”┤Ū╗Õ▒░∙ż╬īgū░ż╚ėõ┐ņż╩ų┘╝õż╚ż╬▒╚ĮŽYumaMatsuoka
?
Ż▓Ż░Ż▒ŻČ─ĻŻ▓į┬Ż╣╚šĪĪż▀ż¾ż╩ż╬Python├ŃÅŖ╗ß#9 LT¢ś
Autoencoder, SparseAutoencoder, DenoisingAutoencoderż“Python(Numpy)ż“╩╣ż├żŲźšźļź╣ź»źķź├ź┴żŪīgū░żĘżŲąį─▄ż“▒╚▌^żĘżŲż▀ż▐żĘż┐ĪŻ
źĮ®`ź╣ź│®`ź╔żŽappendixż╦▌dż╗żŲżżż▐ż╣ĪŻ░┌Č┘│ó┬ųši╗ß▒š│ę▓Ž▒Ęż╚ķv┴¼čąŠ┐Ż¼╩└ĮńźŌźŪźļż╚ż╬ķvéSż╦ż─żżżŲ
░┌Č┘│ó┬ųši╗ß▒š│ę▓Ž▒Ęż╚ķv┴¼čąŠ┐Ż¼╩└ĮńźŌźŪźļż╚ż╬ķvéSż╦ż─żżżŲDeep Learning JP
?
2018/08/17
Deep Learning JP:
http://deeplearning.jp/seminar-2/ SSD: Single Shot MultiBox Detector (ECCV2016)
SSD: Single Shot MultiBox Detector (ECCV2016)Takanori Ogata
?
SSD: Single Shot MultiBox Detector (ECCV2016)░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├
░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├Seiya Tokui
?
Ą┌10╗ž NLP╚¶╩ųż╬╗ߟʟ¾ź▌źĖź”źÓ (YANS) ż╬ź┴źÕ®`ź╚źĻźóźļź╣źķźżź╔żŪż╣ĪŻź╦źÕ®`źķźļź═ź├ź╚ż╬Ż©źóźļź┤źĻź║źÓż╚żĘżŲż╬Ż®ż¬żĄżķżżż╚ĪóChainer v1.3.0ż╬╩╣żżĘĮż“ĮBĮķżĘżŲżżż▐ż╣ĪŻ2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├
2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├ Kenta Oono
?
GTC Japan 2015żŪż╬░k▒Ē┘Y┴Ž (Session ID:2015 - 1014)[DL▌åši╗ß]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[DL▌åši╗ß]Swin Transformer: Hierarchical Vision Transformer using Shifted WindowsDeep Learning JP
?
2021/05/14
Deep Learning JP:
http://deeplearning.jp/seminar-2/More modern gpu
More modern gpuPreferred Networks
?
GPUż¼ż╩ż╝╦┘żżż╬ż½Ż¼ż▐ż┐żĮż╬╔ŽżŪż╔ż╬żĶż”ż╩źŪ®`ź┐śŗįņżõźóźļź┤źĻź║źÓŻ¼źķźżźųźķźĻż¼╩╣ż©żļż╬ż½ż“šh├„żĘż▐ż╣ĪŻ╠žż╦MapReduceż╩ż╔ż╬ĘŪŠ∙┘|żŪŻ¼ļx╔óĄ─ż╩źóźļź┤źĻź║źÓż¼żżż½ż╦Ė▀╦┘ż╦īg¼FżĄżņżļż½ż“ĮBĮķżĘż▐ż╣ĪŻ
īg“Yż╦╩╣ż├ż┐ź│®`ź╔
https://github.com/hillbig/gpuexperiments
ź╗ź▀ź╩®`ż╬äė╗Ł
https://www.youtube.com/watch?v=WmETPBK3MOI[DL▌åši╗ß]NVAE: A Deep Hierarchical Variational Autoencoder
[DL▌åši╗ß]NVAE: A Deep Hierarchical Variational AutoencoderDeep Learning JP
?
2020/11/13
Deep Learning JP:
http://deeplearning.jp/seminar-2/More Related Content
What's hot (19)
░õ│¾▓╣Š▒▓į▒░∙żŪ┴„╠Õ╝Ų╦Ń
░õ│¾▓╣Š▒▓į▒░∙żŪ┴„╠Õ╝Ų╦ŃPreferred Networks
?
Deep Learningźšźņ®`źÓź’®`ź»ż╬Chainerż“╩╣ż├żŲ┴„╠Õėŗ╦Ńż“żõż├żŲż▀ż┐Deep learning├ŃÅŖ╗ß20121214ochi
Deep learning├ŃÅŖ╗ß20121214ochiOhsawa Goodfellow
?
Deep Learning ├ŃÅŖ╗ß┘Y┴ŽżŪż╣ĪŻhttps://sites.google.com/site/deeplearning2013/Practical recommendations for gradient-based training of deep architectures
Practical recommendations for gradient-based training of deep architecturesKoji Matsuda
?
Yoshua Bengio, Practical recommendations for gradient-based training of deep architectures, arXiv:1206.5533v2, 2012 ż╬ĮŌšh[DL▌åši╗ß]Flow-based Deep Generative Models
[DL▌åši╗ß]Flow-based Deep Generative ModelsDeep Learning JP
?
2019/03/08
Deep Learning JP:
http://deeplearning.jp/seminar-2/ [DL▌åši╗ß]Convolutional Sequence to Sequence Learning
[DL▌åši╗ß]Convolutional Sequence to Sequence LearningDeep Learning JP
?
2017/5/19
Deep Learning JP:
http://deeplearning.jp/seminar-2/
[DL▌åši╗ß]A closer look at few shot classification
[DL▌åši╗ß]A closer look at few shot classificationDeep Learning JP
?
2019/03/01
Deep Learning JP:
http://deeplearning.jp/seminar-2/ [DL▌åši╗ß]QUASI-RECURRENT NEURAL NETWORKS
[DL▌åši╗ß]QUASI-RECURRENT NEURAL NETWORKSDeep Learning JP
?
2017/5/12
Deep Learning JP:
http://deeplearning.jp/seminar-2/
┤Ī│▄│┘┤Ū▒▓į│”┤Ū╗Õ▒░∙ż╬īgū░ż╚ėõ┐ņż╩ų┘╝õż╚ż╬▒╚ĮŽ
┤Ī│▄│┘┤Ū▒▓į│”┤Ū╗Õ▒░∙ż╬īgū░ż╚ėõ┐ņż╩ų┘╝õż╚ż╬▒╚ĮŽYumaMatsuoka
?
Ż▓Ż░Ż▒ŻČ─ĻŻ▓į┬Ż╣╚šĪĪż▀ż¾ż╩ż╬Python├ŃÅŖ╗ß#9 LT¢ś
Autoencoder, SparseAutoencoder, DenoisingAutoencoderż“Python(Numpy)ż“╩╣ż├żŲźšźļź╣ź»źķź├ź┴żŪīgū░żĘżŲąį─▄ż“▒╚▌^żĘżŲż▀ż▐żĘż┐ĪŻ
źĮ®`ź╣ź│®`ź╔żŽappendixż╦▌dż╗żŲżżż▐ż╣ĪŻ░┌Č┘│ó┬ųši╗ß▒š│ę▓Ž▒Ęż╚ķv┴¼čąŠ┐Ż¼╩└ĮńźŌźŪźļż╚ż╬ķvéSż╦ż─żżżŲ
░┌Č┘│ó┬ųši╗ß▒š│ę▓Ž▒Ęż╚ķv┴¼čąŠ┐Ż¼╩└ĮńźŌźŪźļż╚ż╬ķvéSż╦ż─żżżŲDeep Learning JP
?
2018/08/17
Deep Learning JP:
http://deeplearning.jp/seminar-2/ SSD: Single Shot MultiBox Detector (ECCV2016)
SSD: Single Shot MultiBox Detector (ECCV2016)Takanori Ogata
?
SSD: Single Shot MultiBox Detector (ECCV2016)░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├
░õ│¾▓╣Š▒▓į▒░∙ż╬╩╣żżĘĮż╚ūį╚╗čįė’äI└Ēżžż╬ÅĻė├Seiya Tokui
?
Ą┌10╗ž NLP╚¶╩ųż╬╗ߟʟ¾ź▌źĖź”źÓ (YANS) ż╬ź┴źÕ®`ź╚źĻźóźļź╣źķźżź╔żŪż╣ĪŻź╦źÕ®`źķźļź═ź├ź╚ż╬Ż©źóźļź┤źĻź║źÓż╚żĘżŲż╬Ż®ż¬żĄżķżżż╚ĪóChainer v1.3.0ż╬╩╣żżĘĮż“ĮBĮķżĘżŲżżż▐ż╣ĪŻ2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├
2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├ Kenta Oono
?
GTC Japan 2015żŪż╬░k▒Ē┘Y┴Ž (Session ID:2015 - 1014)[DL▌åši╗ß]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[DL▌åši╗ß]Swin Transformer: Hierarchical Vision Transformer using Shifted WindowsDeep Learning JP
?
2021/05/14
Deep Learning JP:
http://deeplearning.jp/seminar-2/More modern gpu
More modern gpuPreferred Networks
?
GPUż¼ż╩ż╝╦┘żżż╬ż½Ż¼ż▐ż┐żĮż╬╔ŽżŪż╔ż╬żĶż”ż╩źŪ®`ź┐śŗįņżõźóźļź┤źĻź║źÓŻ¼źķźżźųźķźĻż¼╩╣ż©żļż╬ż½ż“šh├„żĘż▐ż╣ĪŻ╠žż╦MapReduceż╩ż╔ż╬ĘŪŠ∙┘|żŪŻ¼ļx╔óĄ─ż╩źóźļź┤źĻź║źÓż¼żżż½ż╦Ė▀╦┘ż╦īg¼FżĄżņżļż½ż“ĮBĮķżĘż▐ż╣ĪŻ
īg“Yż╦╩╣ż├ż┐ź│®`ź╔
https://github.com/hillbig/gpuexperiments
ź╗ź▀ź╩®`ż╬äė╗Ł
https://www.youtube.com/watch?v=WmETPBK3MOI[DL▌åši╗ß]NVAE: A Deep Hierarchical Variational Autoencoder
[DL▌åši╗ß]NVAE: A Deep Hierarchical Variational AutoencoderDeep Learning JP
?
2020/11/13
Deep Learning JP:
http://deeplearning.jp/seminar-2/2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├
2015─Ļ9į┬18╚š (GTC Japan 2015) ╔Ņīėč¦┴Ģźšźņ®`źÓź’®`ź»Chainerż╬ī¦╚ļż╚╗»║Ž╬’╗ŅąįėĶ£yżžż╬ÅĻė├ Kenta Oono
?
Viewers also liked (20)
░┬┤Ū░∙╗Õ2▒╣▒│”ż╬└Ē┬█▒│Š░
░┬┤Ū░∙╗Õ2▒╣▒│”ż╬└Ē┬█▒│Š░Masato Nakai
?
This explains about Ż¶heoretical background of word2vec ŻŌŻ∙ the paper of PMI embeddings Analysis.Guide for program Implement for PRML
Guide for program Implement for PRML Masato Nakai
?
I described Guidance for Implement for PRML logic By C and posted of implement program with difficulty mark. ▒§│”▒Ķż╦żĶżļįŁ╗ŁŽ±═ŲČ©
▒§│”▒Ķż╦żĶżļįŁ╗ŁŽ±═ŲČ©Masato Nakai
?
This slide explain about identification between various points cloud that is generated by Leaser scanning. The identification is made by ICP(Interactive Closed Point) which uses SVD method.Inference Bayesian Network from data
Inference Bayesian Network from dataMasato Nakai
?
Describe 3 methods for inference Bayesian Network from data and compare each other by example of Kaggle problem.Differentiable neural conputers
Differentiable neural conputersnaoto moriyama
?
Neural Turing Machineż╬▀M╗»░µż╦Ą▒ż┐żļDifferentiable Neural Computersż╚żĮż╬į¬šō╬─żŪżóżļHybrid computing using a neural network with dynamic external memoryż“ĮŌšhżĘżŲż▀ż▐żĘż┐ĪŻź╦źÕ®`źķźļź┴źÕ®`źĻź¾ź»?ź▐źĘź¾╚ļ├┼
ź╦źÕ®`źķźļź┴źÕ®`źĻź¾ź»?ź▐źĘź¾╚ļ├┼naoto moriyama
?
DeepMind╔ńżĶżĻ░k▒ĒżĄżņż┐Neural Turing Machineż“ż▐ż╚żßżŲż▀ż▐żĘż┐Decoupled Neural Interfaces▌åši┘Y┴Ž
Decoupled Neural Interfaces▌åši┘Y┴ŽReiji Hatsugai
?
Decoupled Neural Interfaces Using Synthetic Gradientsż“▌åšiżĘż┐ļHż╬░k▒Ē┘Y┴ŽżŪż╣On the benchmark of Chainer
On the benchmark of ChainerKenta Oono
?
This document discusses benchmarking deep learning frameworks like Chainer. It begins by defining benchmarks and their importance for framework developers and users. It then examines examples like convnet-benchmarks, which objectively compares frameworks on metrics like elapsed time. It discusses challenges in accurately measuring elapsed time for neural network functions, particularly those with both Python and GPU components. Finally, it introduces potential solutions like Chainer's Timer class and mentions the DeepMark benchmarks for broader comparisons.╔Ņīėč¦┴ĢźķźżźųźķźĻż╬ŁhŠ│å¢Ņ}Chainer Meetup2016 07-02
╔Ņīėč¦┴ĢźķźżźųźķźĻż╬ŁhŠ│å¢Ņ}Chainer Meetup2016 07-02Yuta Kashino
?
The document summarizes a meetup discussing deep learning and Docker. It covered Yuta Kashino introducing BakFoo and his background in astrophysics and Python. The meetup discussed recent advances in AI like AlphaGo, generative adversarial networks, and neural style transfer. It provided an overview of Chainer and arXiv papers. The meetup demonstrated Chainer 1.3, NVIDIA drivers, and Docker for deep learning. It showed running a TensorFlow tutorial using nvidia-docker and provided Dockerfile examples and links to resources.Ad
Similar to Vae gan nlp (20)
Controllable Text Generation (ICML 2017 under review)
Controllable Text Generation (ICML 2017 under review)Toru Fujino
?
Controllable Text Generation (ICML 2017 under review)▒╩Ėķ▓č│ó覎░š▀ż½żķ╚ļżļ╔Ņ▓Ń╔·│╔źŌźŪźļ╚ļ├┼
▒╩Ėķ▓č│ó覎░š▀ż½żķ╚ļżļ╔Ņ▓Ń╔·│╔źŌźŪźļ╚ļ├┼tmtm otm
?
ź╝ź▀żŪ░k▒ĒżĘż┐ū╩┴ŽżŪż╣ĪŻ╝õ╬źż├żŲżżż┐żķ░šĘ╔Š▒│┘│┘▒░∙ż╦┴¼┬ńż»ż└żĄżżĪŻ░¬┤Ū│┘│┘▓╣│Š│Š│Õ190Variational Template Machine for Data-to-Text Generation
Variational Template Machine for Data-to-Text Generationharmonylab
?
╣½ķ_URLŻ║https://openreview.net/forum?id=HkejNgBtPB
│÷ĄõŻ║Rong Ye, Wenxian Shi, Hao Zhou, Zhongyu Wei, Lei Li : Variational Template Machine for Data-to-Text Generation, 8th International Conference on Learning Representations(ICLR2020), Addis Ababa, Ethiopia (2020)
Ė┼꬯║Tableą╬╩Įż╬śŗįņ╗»źŪ®`ź┐ż½żķ╬─š┬ż“╔·│╔ż╣żļź┐ź╣ź»(Data-to-Text)ż╦ż¬żżżŲĪóVariational Auto Encoder(VAE)ź┘®`ź╣ż╬╩ųĘ©Variational Template Machine(VTM)ż“╠ß░Ėż╣żļšō╬─żŪż╣ĪŻEncoder-DecoderźŌźŪźļż“ė├żżż┐╝╚┤µż╬źóźūźĒ®`ź┴żŪżŽĪó╔·│╔╬─ż╬ČÓśöąįż╦ŪĘż▒żļż╚żżż”šnŅ}ż¼żóżĻż▐ż╣ĪŻ▒Ššō╬─żŪżŽČÓśöż╩╬─š┬ż“╔·│╔ż╣żļż┐żßż╦żŽźŲź¾źūźņ®`ź╚ż¼ųžę¬żŪżóżļż╚żżż”ų„Åłż╦╗∙ż┼żŁĪóźŲź¾źūźņ®`ź╚ż“č¦┴Ģ┐╔─▄ż╩VAEź┘®`ź╣ż╬╩ųĘ©ż“╠ß░ĖżĘż▐ż╣ĪŻ╠ß░Ė╩ųĘ©żŪżŽŪ▒į┌ēõ╩²ż╬┐šķgż“źŲź¾źūźņ®`ź╚┐šķgż╚ź│ź¾źŲź¾ź─┐šķgż╦├„╩ŠĄ─ż╦Ęųļxż╣żļż│ż╚ż╦żĶż├żŲĪóš²┤_żŪČÓśöż╩╬─╔·│╔ż¼┐╔─▄ż╚ż╩żĻż▐ż╣ĪŻż▐ż┐Īótable-textż╬ź┌źóźŪ®`ź┐ż└ż▒żŪżŽż╩ż»tableźŪ®`ź┐ż╬ż╩żżraw textźŪ®`ź┐ż“└¹ė├żĘż┐░ļĮ╠ĤżóżĻč¦┴Ģż“ąążżż▐ż╣ĪŻ╔Ņīė╔·│╔źŌźŪźļż╚╩└ĮńźŌźŪźļŻ¼
╔Ņīė╔·│╔źŌźŪźļźķźżźųźķźĻPixyzż╦ż─żżżŲ
╔Ņīė╔·│╔źŌźŪźļż╚╩└ĮńźŌźŪźļŻ¼
╔Ņīė╔·│╔źŌźŪźļźķźżźųźķźĻPixyzż╦ż─żżżŲMasahiro Suzuki
?
TensorFlow User Group Meetup - ź┘źżź║Ęų┐Ų╗ß░k▒Ē┘Y┴ŽLarge scale gan training for high fidelity natural
Large scale gan training for high fidelity naturalKCS Keio Computer Society
?
These slides were presented in Yagami-ai seminar.Nexus network connecting the preceding and the following in dialogue generation
Nexus network connecting the preceding and the following in dialogue generationOgataTomoya
?
ąĪŅ«čą 2018
NLPšō╬─ĮBĮķ
Deep Learning Chap. 12: Applications
Deep Learning Chap. 12: ApplicationsShion Honda
?
Deep Learning Chap. 12: Applications (pp.438-481)
╔Ņīėč¦┴Ģ Ą┌12š┬ ÅĻė├
▌åši╗ßż╬┘Y┴ŽżŪż╣ĪŻ[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...
[DL Hacks]Variational Approaches For Auto-Encoding Generative Adversarial Ne...Deep Learning JP
?
2018/04/16
Deep Learning JP:
http://deeplearning.jp/hacks/ Deep Learning 20š┬ ▌åųv╗ß ┘Y┴Ž
Deep Learning 20š┬ ▌åųv╗ß ┘Y┴Žsorashido
?
Deep Learning 20š┬ ▌åųv╗ß ┘Y┴Ž
https://www.deeplearningbook.org/ĪŠ▓╬┐╝╬─ŽūūĘ╝ėĪ┐20180115│ÕČ½┤¾ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`│Õ╔Ņ▓Ń覎░ż╬ūŅŪ░Ž▀ż╚ż│żņż½żķ│ÕĖįę░įŁ┤¾Ė©
ĪŠ▓╬┐╝╬─ŽūūĘ╝ėĪ┐20180115│ÕČ½┤¾ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`│Õ╔Ņ▓Ń覎░ż╬ūŅŪ░Ž▀ż╚ż│żņż½żķ│ÕĖįę░įŁ┤¾Ė©Preferred Networks
?
ĪŠį┘Æ„Ī┐2018─Ļ1į┬15╚šż╬Č½Š®┤¾č¦ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`żŪż╬Ėįę░įŁ┤¾Ė©ż╬Į▓č▌ū╩┴ŽżŪż╣ĪŻŻ©ūŅ║¾ż╬▓╬┐╝╬─Žūż“ūĘ╝ėżĘż▐żĘż┐Ż®20180115│ÕČ½┤¾ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`│Õ╔Ņ▓Ń覎░ż╬ūŅŪ░Ž▀ż╚ż│żņż½żķ│ÕĖįę░įŁ┤¾Ė©
20180115│ÕČ½┤¾ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`│Õ╔Ņ▓Ń覎░ż╬ūŅŪ░Ž▀ż╚ż│żņż½żķ│ÕĖįę░įŁ┤¾Ė©Preferred Networks
?
2018─Ļ1į┬15╚šż╬¢|Š®┤¾č¦ęĮč¦▓┐ÖC─▄╔·╬’覟╗ź▀ź╩®`żŪż╬ī∙ę░įŁ┤¾▌oż╬ųvč▌┘Y┴ŽżŪż╣ĪŻ
ūŅßßż╬▓╬┐╝╬─Žūż“ą▐š²żĘż▐żĘż┐ĪŻ
ą▐š²░µżŽż│ż┴żķżŪż╣ĪŻ
/pfi/20180115-87025513
¢|Š®┤¾č¦2020─ĻČ╚╔Ņīėč¦┴ĢŻ©Deep learning╗∙ĄAųvū∙Ż® Ą┌9╗žĪĖ╔Ņīėč¦┴Ģż╚ūį╚╗čįė’äI└ĒĪ╣(ę╗▓┐╬─ūųż¼ŪĘż▒żŲż▐ż╣Ż®
¢|Š®┤¾č¦2020─ĻČ╚╔Ņīėč¦┴ĢŻ©Deep learning╗∙ĄAųvū∙Ż® Ą┌9╗žĪĖ╔Ņīėč¦┴Ģż╚ūį╚╗čįė’äI└ĒĪ╣(ę╗▓┐╬─ūųż¼ŪĘż▒żŲż▐ż╣Ż®Hitomi Yanaka
?
¢|Š®┤¾č¦2020─ĻČ╚╔Ņīėč¦┴ĢŻ©Deep learning╗∙ĄAųvū∙Ż® https://deeplearning.jp/lectures/dlb2020/
Ą┌9╗žŻ©2020/06/25Ż®ĪĖ╔Ņīėč¦┴Ģż╚ūį╚╗čįė’äI└ĒĪ╣ż╬ųv┴x┘Y┴ŽżŪż╣ĪŻ
ż│ż┴żķż╬┘Y┴ŽżŽę╗▓┐╬─ūųż¼ęŖż©ż╩żżż╬żŪĪóŽ┬ėøż╬URLż╦źóź├źūźĒ®`ź╔żĘż╩ż¬żĘż▐żĘż┐ĪŻ
/HitomiYanaka/2020deep-learning-9-236561673Deep nlp 4.2-4.3_0309
Deep nlp 4.2-4.3_0309cfiken
?
╔Ņīėč¦┴Ģż╦żĶżļūį╚╗čįė’äI└Ē 4.2-4.3
š`ż├żŲ╣┼żżźšźĪźżźļż“żóż▓żŲżĘż▐ż├żŲżżż┐ż┐żßĪó▓╬┐╝╬─Žūż╬Ž┬3ż─ż╦Ūķł¾ż¼┬®żņżŲżļż╬ż╚ĪóżĮż╬żóż╚ż╦ėÓĘųż╩ź╣źķźżź╔ż¼▌dż├ż┴żŃż├żŲżżż▐ż╣ ??Īß?│ę┤Ī▒Ęż╬╗∙▒Š
│ę┤Ī▒Ęż╬╗∙▒Šsohtakannan
?
╔·│╔źŌźŪźļż╬ę╗ż─żŪżóżļGANż╦ż─żżżŲ蹊┐╩ę─┌żŪ░k▒ĒżĘż┐ļHż╬ź╣źķźżź╔żŪż╣
īg“Yż╬ź│®`ź╔
https://github.com/kan-nan-sohta/GAN
ŁhŠ│
Python 3.6.9
Tensorflow 1.8.0
Keras 2.1.6
Deep Learningż╬╗∙ĄAż╚ÅĻė├
Deep Learningż╬╗∙ĄAż╚ÅĻė├Seiya Tokui
?
Ą┌14╗žŪķł¾┐Ųč¦╝╝ągźšź®®`źķźÓ (FIT2015) ż╬źżź┘ź¾ź╚Ų¾╗ŁĪĖźėź├ź░źŪ®`ź┐ĮŌ╬÷ż╬ż┐żßż╬ÖCąĄč¦┴Ģ╝╝ągĪ╣ż╦ż¬ż▒żļź┴źÕ®`ź╚źĻźóźļųvč▌┘Y┴ŽżŪż╣ĪŻź╦źÕ®`źķźļź═ź├ź╚ż╬╗∙ĄAŻ©ėŗ╦Ńź░źķźšż╚żĘżŲż╬Č©╩Į╗»Īó╣┤┼õĘ©Īóš`▓Ņ─µü╗▓źĘ©Ż®ż“żĄżķż├ż┐żóż╚ĪóūŅĮ³╗ŁŽ±żõūį╚╗čįšZż╩ż╔żŪūó─┐żĄżņżŲżżżļÅĻė├?╩ųĘ©ż╦ż─żżżŲÄ┌ż»Ū│ż»ĮBĮķżĘżŲżżż▐ż╣ĪŻ20160716 ICML paper reading, Learning to Generate with Memory
20160716 ICML paper reading, Learning to Generate with MemoryShinagawa Seitaro
?
NAIST ICMLšiż▀╗ßż╬░k▒Ē┘Y┴ŽżŪż╣ĪŻ
https://ahclab.naist.jp/wiki/Jornal/Conference_paper_reading
[šō╬─]: http://jmlr.org/proceedings/papers/v48/lie16.htmlDeep learning for acoustic modeling in parametric speech generation
Deep learning for acoustic modeling in parametric speech generationYuki Saito
?
蹊┐╩ę─┌ż╬┬█╬─╔▄Įķū╩┴ŽŻ©Ą▒╩▒▓č2Ż®ĪŠ▓╬┐╝╬─ŽūūĘ╝ėĪ┐20180115│ÕČ½┤¾ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`│Õ╔Ņ▓Ń覎░ż╬ūŅŪ░Ž▀ż╚ż│żņż½żķ│ÕĖįę░įŁ┤¾Ė©
ĪŠ▓╬┐╝╬─ŽūūĘ╝ėĪ┐20180115│ÕČ½┤¾ęĮč¦▓┐╗·─▄╔·╬’覟╗ź▀ź╩®`│Õ╔Ņ▓Ń覎░ż╬ūŅŪ░Ž▀ż╚ż│żņż½żķ│ÕĖįę░įŁ┤¾Ė©Preferred Networks
?
¢|Š®┤¾č¦2020─ĻČ╚╔Ņīėč¦┴ĢŻ©Deep learning╗∙ĄAųvū∙Ż® Ą┌9╗žĪĖ╔Ņīėč¦┴Ģż╚ūį╚╗čįė’äI└ĒĪ╣(ę╗▓┐╬─ūųż¼ŪĘż▒żŲż▐ż╣Ż®
¢|Š®┤¾č¦2020─ĻČ╚╔Ņīėč¦┴ĢŻ©Deep learning╗∙ĄAųvū∙Ż® Ą┌9╗žĪĖ╔Ņīėč¦┴Ģż╚ūį╚╗čįė’äI└ĒĪ╣(ę╗▓┐╬─ūųż¼ŪĘż▒żŲż▐ż╣Ż®Hitomi Yanaka
?
Ad
More from Masato Nakai (20)
Padoc_presen4R.pdf
Padoc_presen4R.pdfMasato Nakai
?
This slides are presented for data analytics environment that is aimed at cooperation between user side and data scientists.Factor analysis for ml by padoc 6 r
Factor analysis for ml by padoc 6 rMasato Nakai
?
This slide is explanation for padoc as factor analysis tool▒©│Ļż¼┤∙ż╔Ą├żķżņż╩żż│Ī║Žż╬Ū┐╗»č¦Ž░
▒©│Ļż¼┤∙ż╔Ą├żķżņż╩żż│Ī║Žż╬Ū┐╗»č¦Ž░Masato Nakai
?
Reinforcement Learning with few reward is challenge subject. This slide provides same method for reinforce learning with few reward and some latent variable model by VAE.Ai neuro science_pdf
Ai neuro science_pdfMasato Nakai
?
This document is described for explanation of Hassabis@DeepMind survey paper [Neuroscience Inspired Artificial Intelligence].Deep IRL by C language
Deep IRL by C languageMasato Nakai
?
This document discusses maximum entropy deep inverse reinforcement learning. It presents the mathematical formulation of inverse reinforcement learning using maximum entropy. It shows that the objective is to maximize the log likelihood of trajectories by finding the reward parameters ”╚ that best match the expected features under the learned reward function and the demonstrated trajectories. It derives the gradient of the objective with respect to the reward parameters, which involves the difference between expected features under the data distribution and the learned reward distribution. This gradient can then be used with stochastic gradient descent to learn the reward parameters from demonstrations.Open poseĢrŽĄ┴ąĮŌ╬÷7
Open poseĢrŽĄ┴ąĮŌ╬÷7Masato Nakai
?
Discription of Time Analysis for bascket ball free throw by Openpose Semi vae memo (2)
Semi vae memo (2)Masato Nakai
?
This document summarizes a research paper on semi-supervised learning with deep generative models. It presents the key formulas and derivations used in variational autoencoders (VAEs) and their extension to semi-supervised models. The proposed semi-supervised model has two lower bounds - one for labeled data that maximizes the likelihood of inputs given labels, and one for unlabeled data that maximizes the likelihood based on inferred labels. Experimental results show the model achieves better classification accuracy compared to supervised models as the number of labeled samples increases.Open posedoc
Open posedocMasato Nakai
?
OpenPose is a real-time system for multi-person 2D pose estimation using part affinity fields. It uses a bottom-up approach with convolutional neural networks to first detect body keypoints for each person and then assemble the keypoints into full body poses. OpenPose runs in real-time at 20 frames per second and uses part affinity fields to encode pairwise relations between body joints to group joints into full poses for multiple people.Dr.raios papers
Dr.raios papersMasato Nakai
?
Dr. Reio presented several papers at an AI meeting that explored topics including grounding topic models with knowledge bases, a survey of Bayesian deep learning, using recurrent neural networks for visual paragraph generation based on long-range semantic dependencies, and examining natural language understanding unit tests and semantic representations.Deep genenergyprobdoc
Deep genenergyprobdocMasato Nakai
?
1) The document discusses deep directed generative models that use energy-based probability estimation. It describes using an energy function to define a probability distribution over data and training the model using positive and negative phases.
2) The training process involves using samples from the data distribution as positive examples and samples from the model's distribution as negative examples. The model is trained to minimize the difference in energy between positive and negative samples.
3) Applications discussed include deep energy models, variational autoencoders combined with generative adversarial networks, and adversarial neural machine translation using energy functions.Irs gan doc
Irs gan docMasato Nakai
?
This document discusses the connection between generative adversarial networks (GANs) and inverse reinforcement learning (IRL). It shows that the objectives of GAN discriminators and IRL cost functions are equivalent, and GAN generators are equivalent to the IRL sampler objective plus a constant term. The derivative of the IRL cost function with respect to the cost parameters is also equivalent to the derivative of the GAN discriminator objective. Therefore, GANs can be used to perform IRL by training the discriminator to estimate the cost function and the generator to produce sample trajectories.Semi vae memo (1)
Semi vae memo (1)Masato Nakai
?
This document discusses using variational autoencoders for semi-supervised learning. It presents the general variational formula for calculating the log likelihood of data, and derives lower bound formulas for semi-supervised models. Specifically, it shows lower bound formulas for predicting a semi-supervised value z given inputs x and y, and for predicting both z and a supervised value y given only x as input. The key ideas are using an encoder-decoder model with latent variables z and y, and optimizing an objective function that combines supervised and unsupervised loss terms.│¦Š▒┤┌│┘ż╦żĶżļ╠žÅšĄŃ│ķ│÷
│¦Š▒┤┌│┘ż╦żĶżļ╠žÅšĄŃ│ķ│÷Masato Nakai
?
This slides explain about scanning picture feature points that is made by SIFT(Scale Invariant Feature Transform) which uses Gaussian Filter Difference Logic (DoG).End to end training with deep visiomotor
End to end training with deep visiomotorMasato Nakai
?
This is explanation about robotics with visiomotor policy control which is published in ICML 2016 journal.Vae gan nlp
- 1. VAE+GAN Controllable Text Generation 2017/03/24 mabonki0725
- 2. ContentsĪĪand ĪĪSelf-introduction ? Contents 1.ēõĘųĘ©Ż©Variational BayesŻ®ż╬šh├„ 2.VAEŻ©Variational Auto-Encoder)šō╬─ż╬šh├„ 3.DCGANŻ©Deep CNN Generative Advance Network)ż╬šh├„ 4.Conditional GANż╬šh├„ 5.VAEŻ½GANż“╩╣ż├ż┐ ĪĪControllable Text Generationšō╬─ż╬šh├„ ? ūį╝║ĮBĮķ ©C Įyėŗ╩²└Ē蹊┐╦∙ĪĪÖCąĄč¦┴Ģź╝ź▀╦∙╩¶ ©C Č╝┴ó«bśI╝╝ąg┤¾č¦į║ĪĪäōįņ╝╝ągč¦┐ŲĪĪč¦╔· ©C Į╚┌ÖCķvżŪAIźŌźŪźļż“śŗ║B
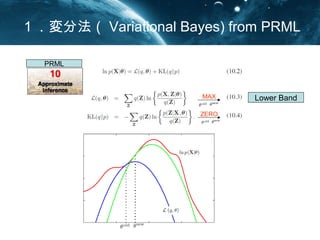
- 3. Ż▒Ż«ēõĘųĘ©Ż©Variational Bayes) from PRML Lower Band PRML MAX ZERO Z:latent value ę╗░ŃĄ─ż╦żŽMCMCżŪ”╚ż“ĮŌż»
- 4. ēõĘųĘ©Ż©Variational Bayes) Proof ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ? ? )()()()|(log)|(log )|(log)()|(log )( )|,( )|,( )|()( log)|(log )( |, log )|,( )|()( log)()|(log |, log )|( |, log)()|(log |, log ),|( log)()|(log )( )|,( log ,| log)()|(log Pr ,||)|(log xFxFzqxpxp xpzqxp zq zxp xzp xpzq zqxp zq zxp xzp xpzq zqxp zq zxp xpzq xzp zqxp zq zxp zq xzp zqxp zq zxp zq zq xzp zqxp oof qLpqKLxp z z z z z z zz ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ? ? ? ? ? ? ? ? ? ? ? ? ?? ?? ? ? ? ? ? ? ?? ?ĪĪĪĪ?? ?? ? ? ? ? ? ? ? ? ? ? ? ? ?? ? ?? ? ??
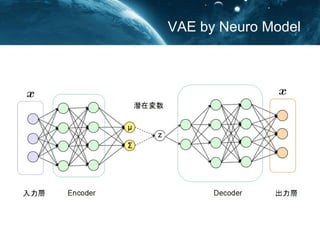
- 5. Ż▓Ż«VAE(Variational AutoEncoder) VAEżŽKingmaż¼╠ß│¬ ? źŪ®`ź┐xż“╔·│╔żĘżŲżżżļļLżņ ēõ╩²zż“┤_┬╩├▄Č╚ķv╩²ĪĪĪĪĪĪ q”Ą(z/x)żŪĮ³╦Ųż╣żļĘĮĘ© ? q”Ą(z/x)żŽēõĘųĘ©żŪĮ³╦Ųż╣żļ ? ēõĘųĮ³╦ŲżŽź╦źÕ®`źĒ?źŌźŪ źļż“▀mÅĻż╣żļ https://arxiv.org/abs/1312.6114
- 6. Auto-Encoding Variational Bayes proof (2) Ī·(3) proof (2) from PRML(10.3) Ž┬Ž▐ż╬MLP PRMLŻ©10.1)
- 7. loss Function on VAE Encoder Decoder when MAX networkżŪ”╚”šż“ Ė─╔ŲżĘżŲErrorż“ ūŅąĪ╗»ż╣żļ ZERO MIN
- 8. VAE by Neuro Model
- 9. VEA Program by Chainer (1)
- 10. VEA Program by Chainer(2)
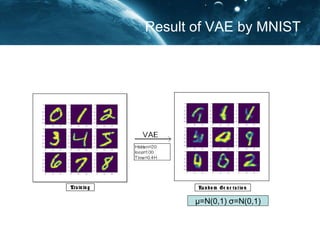
- 11. Result of VAE by MNIST
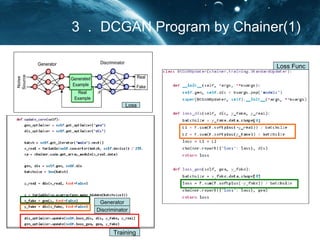
- 12. Ż│Ż«DCGAN Program by Chainer(1) Loss Loss Func Training Generator Discriminator object of GAN softplus=log{1+exp(D)}
- 13. GCGAN Program by Chainer(2) Generator Discriminator
- 14. Result of DCGAN
- 15. Ż┤Ż«Conditional(Controllable) Gan Ū¾żßż┐żżźčź┐®`ź¾ż╬╝▄┐šż╬╗ŁŽ±ż“╔·│╔ż╣żļ Condition cImage x Encode cEncode x Generator Discriminator Condition Image Conditional GAN
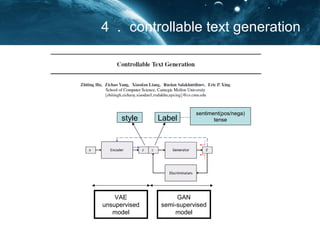
- 16. ŻĄŻ«Controllable Text Generation style Label sentiment(pos/nega) tense VAE unsupervised model GAN semi-supervised model
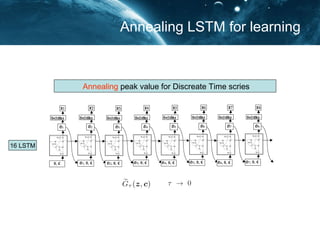
- 17. Annealing LSTM for learning Annealing LSTM to mitigate peak weight on Discreate model 16 LSTM
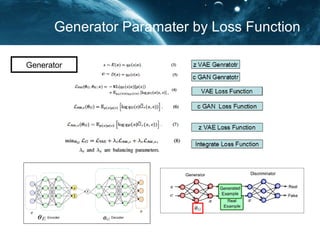
- 18. Generator Paramater by Loss Function
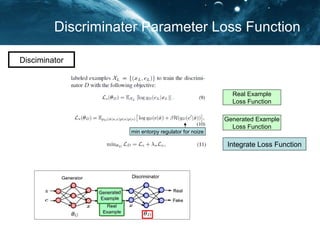
- 19. Discriminater Parameter by Loss Function Real Example Loss Function Generated Example Loss Function Integrate Loss Function min entorpy regulator for noize Disciminator
- 20. Training Data and accuracy use data set content size Corpus IMDB movie reviews of max 16 words 1.4M Sentim ent SST-full labeled sentence with annotations 2737 SST-small labeled sentence 250 Lexicon sentiment labeled word 2700 IMDB For train/dev/test 16K Tense TimeBank tense labeled sentences 5250 Training Data Classification accuracy
- 21. Alogorithm for Parameters of VAE Generater Discriminater wake proc sleep proc VAE gen-dis Input unlabeled sentence Input labeled sentence zĪ½ VAE cĪ½p(c) cĪ½Discriminator(X) XtĪ½LSTM(z,c,Xt-1)
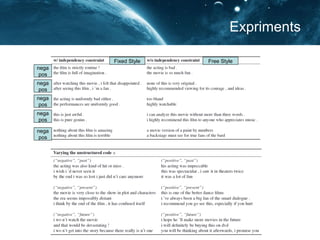
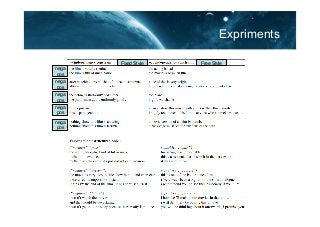
- 22. Expriments Fixed Style Free Style nega pos nega pos nega pos nega pos nega pos
- 23. ŻČŻ«Summary ż▐ż╚żß ? ¼FŽ¾xż½żķįŁę“zż╬Ęų▓╝p(z|x)żŽź┘źżź║ĮyėŗżŪŪ¾żßżŲżż ż┐ż¼ĪóDeepLearningż╬VAEżõGANżŪ┐╔─▄ż╦ż╩ż├ż┐ĪŻ ? DeepLearningźŌźŪźļżŽīØżŪśŗįņż╩ż╬żŪīgū░ż¼║åģg ©C VAEŻ║Encoder - Decoder ©C GANŻ║Generator - Discriminator ? Ū¾żßż┐żżŻ©Contrallable)╗ŁŽ±żõ╬─š┬╔·│╔ż¼┐╔─▄ż╦ż╩ż├ż┐ĪŻ ©C ╗ŁŽ±Ż║Conditional GAN ©C ╬─Ģ°Ż║Controlable Text Generation