[DL▌åši╗ß]YOLO9000: Better, Faster, Stronger
29 likes207,528 views

2017/8/4 Deep Learning JP: http://deeplearning.jp/seminar-2/
![DEEP LEARNING JP [DL Papers]
Ī░YOLO9000: Better, Faster, StrongerĪ▒ (CVPRĪ»17 Best Paper)
And the History of Object Detection
Makoto Kawano, Keio University
http://deeplearning.jp/
1](https://image.slidesharecdn.com/dlreadingpaper20170804-170803075138/85/DL-YOLO9000-Better-Faster-Stronger-1-320.jpg)







![Region Proposal Methods
? Selective Search[]żõEdgeBoxes[]ż╩ż╔ żżż║żņżŌėŗ╦Ń┴┐ż¼┼“┤¾
? SSż╬ł÷║ŽŻ¼źįź»ź╗źļźņź┘źļżŪŅÉ╦Ųż╣żļŅIė“ż“ź░źļ®`źįź¾ź░żĘżŲżżż»
? ╦Ųż┐żĶż”ż╩╠žÅšż“│ųż─ŅIė“ż“ĮY║ŽżĘżŲżżżŁĪóŻ▒ż─ż╬ź¬źųźĖź¦ź»ź╚ż╚żĘżŲ│ķ│÷ż╣żļ
9](https://image.slidesharecdn.com/dlreadingpaper20170804-170803075138/85/DL-YOLO9000-Better-Faster-Stronger-9-320.jpg)

















![SSII2020 [OS2-02] Į╠ĤżóżĻ╩┬Ū░č¦┴Ģż“┴Ķ±{ż╣żļĪĖ╚§Ī╣Į╠ĤżóżĻ╩┬Ū░č¦┴Ģ](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=560&fit=bounds)









![[DL▌åši╗ß]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=560&fit=bounds)
![SSII2021 [OS2-01] ▄×ęŲč¦┴Ģż╬╗∙ĄAŻ║«Éż╩żļź┐ź╣ź»ż╬ų¬ūRż“└¹ė├ż╣żļż┐żßż╬ÖCąĄč¦┴Ģż╬ĘĮĘ©](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=560&fit=bounds)


![[DL▌åši╗ß]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=560&fit=bounds)



![SSII2021 [OS2-03] ūį╝║Į╠ĤżóżĻč¦┴Ģż╦ż¬ż▒żļīØššč¦┴Ģż╬╗∙ĄAż╚ÅĻė├](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=560&fit=bounds)

![[DL▌åši╗ß]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=560&fit=bounds)



![[DL▌åši╗ß]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=560&fit=bounds)


More Related Content
What's hot (20)
Viewers also liked (6)




More from Deep Learning JP (20)




















Recently uploaded (11)











[DL▌åši╗ß]YOLO9000: Better, Faster, Stronger
- 1. DEEP LEARNING JP [DL Papers] Ī░YOLO9000: Better, Faster, StrongerĪ▒ (CVPRĪ»17 Best Paper) And the History of Object Detection Makoto Kawano, Keio University http://deeplearning.jp/ 1
- 2. Ģ°šIŪķł¾ ? CVPR2017 Best Paper Award ? Joseph Redmon, Ali Farhadi(ź’źĘź¾ź╚ź¾┤¾č¦) ? ▀xČ©└Ēė╔Ż║ ? YOLOż╚żżż”Ū░źą®`źĖźńź¾(═¼żĖų°š▀ż┐ż┴Ż½”┴)ż╬┤µį┌ż“ų¬ż├żŲżżż┐ ? źą®`źĖźńź¾źóź├źūżĘżŲŻ¼ź┘ź╣ź╚ź┌®`źč®`ż╦▀xżążņż┐ż│ż╚ż“Č·ż╦żĘż┐ż½żķ ? ż│ż╬šō╬─ż“ųąą─ż╦╬’╠ÕŚ╩│÷ż╬Üs╩Ęż▀ż┐żżż╩żŌż╬ż“įÆżĘż▐ż╣ ? R-CNN(2014)Ī½Mask R-CNN(2017) ? R-CNN, SPPNet, Fast R-CNN, Faster R-CNN, YOLO, SSD, YOLO9000, (Mask R-CNNż╬żĄż’żĻż└ż▒Ż® ? ż█ż╚ż¾ż╔┤źżņż┐ż│ż╚ż¼ż╩żżĘųę░żŪŻ¼ą¹čįżĘż┐ż│ż╚ż“żŌż╬ż╣ż┤ż»ßß╗┌ ? ĮYśŗČ└ČŽż╚Ų½ęŖż╦£║ż┴ęńżņżŲżżżļż╬żŪŻ¼ķg▀`ż├żŲż┐żķųĖš¬ż¬ŅŖżżżĘż▐ż╣ 2
- 3. 3
- 4. źóźĖź¦ź¾ź└Ż©Üs╩ĘŻ® ? NOT End-to-End LearningĢr┤·Ż©2013Ī½2015─ĻŻ® ? R-CNN(CVPRĪ»14, 2013/11) ? SPPNet(ECCVĪ»14, 2014/6) ? Fast R-CNN(ICCVĪ»15, 2015/4) ? End-to-End LearningĢr┤·Ż©2015─ĻĪ½¼Fį┌Ż® ? Faster R-CNN(NIPSĪ»15, 2015/6) ? YOLO(2015/6) ? SSD(2015/12) ? YOLO9000(CVPRĪ»17, 2016/12) ? Mask R-CNN(2017/3) 4
- 5. źóźĖź¦ź¾ź└Ż©Üs╩ĘŻ® ? NOT End-to-End LearningĢr┤·Ż©2013Ī½2015─ĻŻ® ? R-CNN(CVPRĪ»14, 2013/11) GirshickżķŻ©UCźą®`ź»źņ®`Ż® ? SPPNet(ECCVĪ»14, 2014/6) HeżķŻ©MicrosoftŻ® ? Fast R-CNN(ICCVĪ»15, 2015/4) GirshickŻ©MicrosoftŻ® ? End-to-End LearningĢr┤·Ż©2015─ĻĪ½¼Fį┌Ż® ? Faster R-CNN(NIPSĪ»15, 2015/6) He+GirshickżķŻ©MicrosoftŻ® ? YOLO(2015/6) Redmon+GirshickżķŻ©ź’źĘź¾ź╚ź¾┤¾č¦Ż½FacebookŻ® ? SSD(2015/12) Googleä▌ ? YOLO9000(CVPRĪ»17, 2016/12) RedmonżķŻ©ź’źĘź¾ź╚ź¾┤¾č¦Ż® ? Mask R-CNN(2017/3) He+GirshickżķŻ©FacebookŻ® ╩└ĮńżŽ3╚╦(1╚╦)ż╦š±żĻ╗žżĄżņżŲżżżļ 5Kaiming He Ross Girshick Joseph Redmon ü╗╩┌Ż┐
- 6. źóźĖź¦ź¾ź└(ŽĄūVŻ┐) 6 Fast R-CNN R-CNN SPPnet YOLO Faster R-CNN SSD YOLO9000 Masked R-CNN NOT End-to-End learningĢr┤· End-to-End learningĢr┤· 2013─Ļ 2015─Ļ6į┬ źżź¾ź╣ź┐ź¾ź╣Ś╩│÷Ģr┤·═╗╚ļŻ┐
- 7. żĮżŌżĮżŌ╬’╠ÕŚ╩│÷ż╚żŽ ? CVź┐ź╣ź»ż╬ę╗ż─ ? ėļż©żķżņż┐╗ŁŽ±ż╬ųąż½żķŻ¼ ╬’╠Õż╬╬╗ų├ż╚ź½źŲź┤źĻŻ©ź»źķź╣Ż®ż“Ą▒żŲżļ ? ╗∙▒ŠĄ─ż╩┴„żņŻ║ 1. ╗ŁŽ±ż½żķ╬’╠ÕŅIė“ż╬║“ča▀x│÷(Region Proposal) ¢ś, Bounding Boxż╚żŌ║¶żążņżļ 2. Ė„¢śżŪ╗ŁŽ±šJūR ČÓź»źķź╣ĘųŅÉå¢Ņ} 7
- 8. ╬’╠ÕŚ╩│÷ż╬Č■ż─ż╬Ģr┤· ? Not End-to-End LearningĢr┤· ? 1.ŅIė“║“čaŻ©Region ProposalŻ®ż╚2.╬’╠ÕšJūR(ĘųŅÉ)ż“äeĪ®ż╦ąąż” ? ╬’╠ÕšJūRżŪÅŖż½ż├ż┐CNNż“╚ĪżĻ╚ļżņżŲż╣ż┤żżż╚żĄżņż┐Ģr┤· ? End-to-End LearningĢr┤· ? 1.ż╚2.ż╬äI└Ēż“ę╗ż─ż╬ź╦źÕ®`źķźļź═ź├ź╚ź’®`ź»żŪ£gż▐ż╗żļ ? Š½Č╚Ž“╔Ž?╦┘Č╚Ž“╔Žż“─┐ųĖż╣Ģr┤· 8
- 9. Region Proposal Methods ? Selective Search[]żõEdgeBoxes[]ż╩ż╔ żżż║żņżŌėŗ╦Ń┴┐ż¼┼“┤¾ ? SSż╬ł÷║ŽŻ¼źįź»ź╗źļźņź┘źļżŪŅÉ╦Ųż╣żļŅIė“ż“ź░źļ®`źįź¾ź░żĘżŲżżż» ? ╦Ųż┐żĶż”ż╩╠žÅšż“│ųż─ŅIė“ż“ĮY║ŽżĘżŲżżżŁĪóŻ▒ż─ż╬ź¬źųźĖź¦ź»ź╚ż╚żĘżŲ│ķ│÷ż╣żļ 9
- 10. Regional-CNN ? ╬’╠Õż╬ŅIė“ż“ęŖż─ż▒żļ ? ŅIė“ż“źĻźĄźżź║żĘżŲŻ¼CNNżŪ╠žÅš│ķ│÷ ? SVMżŪ╗ŁŽ±ĘųŅÉ Selective Search Object Classification 10
- 11. R-CNNż╬ŪĘĄŃ ? Ė„╣ż│╠ż“żĮżņżŠżņżŪč¦┴Ģż╣żļ▒žę¬ż¼żóżļ ? ŅIė“║“čaż╬╗žÄó ? CNNż╬Fine-tuning ? SVMż╬ČÓź»źķź╣ĘųŅÉč¦┴Ģ ? źŲź╣ź╚Ż©īgąąŻ®Ģrķgż¼▀Wżż ? Selective SearchŻ║1├Čżóż┐żĻ2├ļż»żķżż 11
- 12. SPPnet ? ż│ż╬Ģr┤·ż╬CNNżŽ╚ļ┴”╗ŁŽ±źĄźżź║ż¼╣╠Č© ? R-CNNżŌźĻźĄźżź║żĘżŲżżż┐ ? ŅIė“║“ča╚½żŲŻ©2000éĆŻ®ż╦īØżĘżŲCNNżŽ▀Wżż ? Spatial Pyramid Poolingż╬╠ß░Ė ? śöĪ®ż╩HĪ┴Wż╬ź░źĻź├ź╔ż╦ĘųĖŅżĘżŲżĮżņżŠżņżŪMaxpooling ? Pros. ? Ė▀╦┘╗»ż╦│╔╣” ? Cons. ? SPPż╬ż╔żņż“─µü╗░ßż╣żņżążżżżż½ż’ż½żķż╩żż ? ╚½īėż“═©żĘżŲż╬č¦┴ĢżŽżŪżŁż╩żż 12
- 13. Fast R-CNN ? ╬’╠ÕŚ╩│÷ż╬ż┐żßż╬č¦┴Ģż“┐╔─▄ż╦żĘż┐ ? SVMż╬┤·ż’żĻż╦Softmaxż╚ū∙ś╦ż╬╗žÄóīė ? Region on Interest Pooling Layerż╬ī¦╚ļ ? Selective Searchż╩ż╔żŪ│÷żŲżŁż┐ŅIė“ż“Feature Mapż╦╔õė░ż╣żļ ? HĪ┴Wż╬ź░źĻź├ź╔ż╦ĘųĖŅżĘżŲŻ¼Ė„ź╗źļżŪMaxpoolingż╣żļ ? Spatial Pyramid Pollingźņźżźõ®`ż╬ę╗ĘNŅÉż└ż▒ż╚═¼żĖ ? éĆ╚╦Ą─ż╦5.4. Do SVMs outperform softmax? ż╚żżż”╣Øż╬žĢŽū┤¾ż╬ėĪŽ¾ ? ProsŻ« ? č¦┴Ģż╚źŲź╣ź╚üIĘĮżŪĖ▀Š½Č╚?Ė▀╦┘╗»ż“▀_│╔ ? Cons. ? ę└╚╗ż╚żĘżŲSelective Searchż╩ż╔ŅIė“║“ča▀x│÷żŽäeż╬źóźļź┤źĻź║źÓ 13
- 14. End-to-End LearningĢr┤·ż╬─╗ķ_ż▒ ? ż╔ż¾ż╩ż╦CNNé╚ż¼╦┘ż»ż╩ż├ż┐żĻŻ¼ąį─▄ż¼┴╝ż»ż╩ż├ż┐żĻżĘżŲżŌŻ¼ Selective Searchż“╩╣ż├żŲżżżļŽ▐żĻ╬┤└┤żŽż╩żż ? Region ProposalżŌCNN╩╣ż©żążżżżż¾żĖżŃż╩żżŻ┐Ż┐ ? Faster R-CNNż╚YOLOż╬ĄŪł÷ ? Faster R-CNN: 2015/6/4 ? YOLO: 2015/6/8 ? ż╔ż┴żķżŌż¬╗źżżż“▓╬ššżĘżŲż╩żż ? żŪżŌ╣▓ų°ż╦═¼żĖ╚╦żżżļŻ¼Ż¼Ż¼ 14
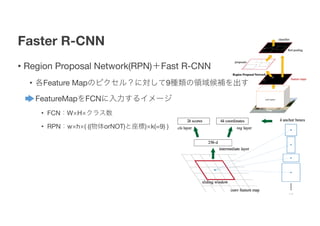
- 15. Faster R-CNN ? Region Proposal Network(RPN)Ż½Fast R-CNN ? Ė„Feature Mapż╬źįź»ź╗źļŻ┐ż╦īØżĘżŲ9ĘNŅÉż╬ŅIė“║“čaż“│÷ż╣ ? FeatureMapż“FCNż╦╚ļ┴”ż╣żļźżźß®`źĖ ? FCNŻ║WĪ┴HĪ┴ź»źķź╣╩² ? RPNŻ║wĪ┴hĪ┴( ((╬’╠ÕorNOT)ż╚ū∙ś╦)Ī┴k(=9) ) 15
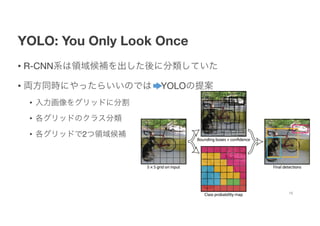
- 16. YOLO: You Only Look Once ? R-CNNŽĄżŽŅIė“║“čaż“│÷żĘż┐ßßż╦ĘųŅɿʿŲżżż┐ ? üIĘĮ═¼Ģrż╦żõż├ż┐żķżżżżż╬żŪżŽ YOLOż╬╠ß░Ė ? ╚ļ┴”╗ŁŽ±ż“ź░źĻź├ź╔ż╦ĘųĖŅ ? Ė„ź░źĻź├ź╔ż╬ź»źķź╣ĘųŅÉ ? Ė„ź░źĻź├ź╔żŪ2ż─ŅIė“║“ča 16
- 17. YOLO: You Only Look Once ? źó®`źŁźŲź»ź┴źŃżŽżŌż╬ż╣ż┤ż»ģg╝ā ? GoogLeNetż“▓╬┐╝ż╦żĘż┐CNN Ė„ź░źĻź├ź╔ż╬ź»źķź╣ĘųŅÉż╚ū∙ś╦ż“╦Ń│÷ż╣żļ 17 ”╦coord S2 X i=0 BX j=0 1lobj ij ? (xi ? ?xi)2 + (yi ? ?yi)2 ? + ”╦coord S2 X i=0 BX j=0 1lobj ij " ?p wi ? p ?wi ?2 + ?p hi ? q ?hi Ī¶2 # + S2 X i=0 1lobj ij (pi(c) ? ?pi(c)) 2 + S2 X i=0 BX j=0 1lobj ij ? Ci ? ?Ci ?2 + ”╦noobj S2 X i=0 BX j=0 1lnoobj ij ? Ci ? ?Ci ?2 ū∙ū∙ś╦ś╦ż╬ż╬š`š`▓Ņ▓Ņ ą┼ą┼ŅmŅmČ╚Č╚ż╬ż╬š`š`▓Ņ▓Ņ ĘųĘųŅÉŅÉš`š`▓Ņ▓Ņ
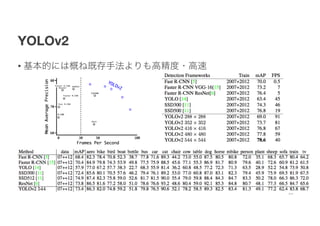
- 18. YOLO: You Only Look Once ? Pros. ? Faster R-CNNż╦▒╚ż┘żļż╚Š½Č╚żŽ┴ėżļż¼Ż¼Ś╩│÷╦┘Č╚żŽ╦┘żż ? 45FPS-155FPS ? CNNż╦╗ŁŽ±╚½╠Õż“╚ļżņżļż┐żßŻ¼▒│Š░ż╚ż╬ęŖĘųż▒żŽFast R-CNNżĶżĻ┴╝żż ? Cons. ? Ė„ź░źĻź├ź╔ż╦ż─żŁ1ź»źķź╣ż╬ż┐żßŻ¼ č}╩²╬’╠Õż¼1ź░źĻź├ź╔─┌ż╦żóżļż╚ż└żß 18
- 19. ? YOLOż“StraightForwardż╦Ė─┴╝żĘż┐źą®`źĖźńź¾ ? ó┘ó┌ó█Ż║ź═ź├ź╚ź’®`ź»ż╬źó®`źŁźŲź»ź┴źŃż“Ė─┴╝ ? ó▄Ż║│÷┴”ż“LinearżŪżŽż╩ż»Ż¼FCNż╦żĘż┐Ż©Faster R-CNN▓╬┐╝Ż® ? ó▌ó▐Ż║źŪ®`ź┐ż“č}╩²ĮŌŽ±Č╚żŪėļż©żļ ? ó▀óÓŻ║źŪ®`ź┐ż╬╩┬Ū░Ūķł¾ ó┘ó┘ ó┌ó┌ ó█ó█ ó▄ó▄ ó▌ó▌ ó▐ó▐ ó▀ó▀ óÓóÓ YOLOv2
- 20. YOLOv2 ? źó®`źŁźŲź»ź┴źŃż╬╣żĘ“ ? ó┘╚½Convīėż╦Batch Normalizationż“╚ļżņżļ ? ģ¦╩°ż“╦┘ż»żĘŻ¼š²ät╗»ż╬ä┐╣¹ż“Ą├żļ ? ó┌ą┬żĘżżśŗįņDarknet-19ż╦ż╣żļ ? VGG16ż╬żĶż”ż╦3Ī┴3ż╬źšźŻźļź┐źĄźżź║ ? Network In Networkż╬Global Average Poolingż“╩╣ż” ? ó█Passthroughż“╚ļżņżļŻ©ż’ż½żķż╩żżŻ® ? add a passthrough layer from the final 3 Ī┴ 3 Ī┴ 512 layer to the second to last convolutional layer 20
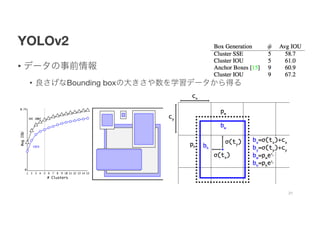
- 21. YOLOv2 ? źŪ®`ź┐ż╬╩┬Ū░Ūķł¾ ? ┴╝żĄż▓ż╩Bounding boxż╬┤¾żŁżĄżõ╩²ż“č¦┴ĢźŪ®`ź┐ż½żķĄ├żļ 21
- 22. YOLOv2 ? │÷┴”żŽFeature Mapż╬Ė„źįź»ź╗źļż╦ż─żŁ(whxyż╚ź»źķź╣)Ī┴5 ? č¦┴ĢżŽęįŽ┬ż╬╩ųĒśŻ║ ? 1Ż«╗ŁŽ±ĘųŅÉż╬č¦┴Ģ ? ūŅ│§ż╦224Ī┴224żŪč¦┴ĢżĄż╗ż┐ß߯¼448Ī┴448żŪč¦┴ĢżĄż╗żļ ? 2Ż«╬’╠ÕŚ╩│÷ż╬č¦┴Ģ ? {320, 352, ĪŁ 608}źįź»ź╗źļż╬╗ŁŽ±ż“10ź©ź▌ź├ź»ż┤ż╚ż╦źķź¾ź└źÓż╦ēõż©żŲč¦┴ĢżĄż╗żļ ? CNNżŪ╚ļ┴”╗ŁŽ±żŽ32Ęųż╬1ż╦ż╩żļż┐żßŻ¼żĮż╬▒Č╩²źįź»ź╗źļż“ÆQż” 22
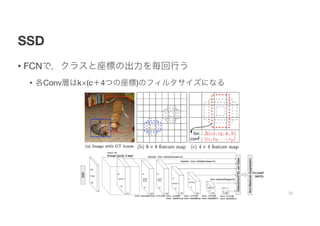
- 23. SSD ? FCNżŪŻ¼ź»źķź╣ż╚ū∙ś╦ż╬│÷┴”ż“Ü░╗žąąż” ? Ė„ConvīėżŽkĪ┴(cŻ½4ż─ż╬ū∙ś╦)ż╬źšźŻźļź┐źĄźżź║ż╦ż╩żļ 23
- 25. YOLO9000 ? ╬’╠ÕŚ╩│÷ė├ż╬źŪ®`ź┐ź╗ź├ź╚ż╬ź½źŲź┤źĻżŽ╔┘ż╩żż ? źóź╬źŲ®`źĘźńź¾ź│ź╣ź╚ż¼Ė▀ż╣ż«żļ ? ImageNetż╬ź½źŲź┤źĻż╚ż½ż“╩╣ż©ż┐żķżżżżż╬żŪżŽŻ┐ ? Distant SupervisionĄ─ż╩Ż┐ ? WordNetż“╩╣ż©żąÆłÅłżŪżŁżļŻĪ ? ėąŽ“ź░źķźšżŪśŗ║BżĄżņżŲżżżļĪ┘─Šśŗįņ 25
- 26. YOLO9000 ? ImageNetż╬visual nounżŪWordTreeż“śŗ║B ? ╠§╝■ĖČżŁ┤_┬╩żŪ▒Ē¼F┐╔─▄ż╦ 26
- 27. YOLO9000 ? ImageNetŚ╩│÷ź┐ź╣ź» ? COCOż╦żóżļ44ź½źŲź┤źĻż“╣▓ėążĘżŲżżżļ ? ż█ż╚ż¾ż╔ĘųŅÉė├żŪŻ¼Ś╩│÷ė├źŪ®`ź┐żŽż█ż╚ż¾ż╔č¦┴ĢżŪżŁżŲżżż╩żż ? ▓ążĻż╬156ź½źŲź┤źĻżŪżŽ16.0mAPŻ¼╚½╠ÕżŪ19.7mAP ? ĮY╣¹ż╬┐╝▓ņŻ║ ? COCOż╦║¼ż▐żņżŲżżżļäė╬’żŽż”ż▐ż»═ŲČ©żŪżŁżŲżżżļ ? ║¼ż▐żņżŲżżż╩żżĘ■ū░żŽżŪżŁż╩żż 27
- 28. Mask R-CNN ? ╬’╠ÕŚ╩│÷ż└ż▒żŪżŽż╩ż»Ż¼źżź¾ź╣ź┐ź¾ź╣Ś╩│÷ż└ż├ż┐ ? ╠Õ┴”ż¼żóżņżążõżĻż▐ż╣ 28