[DLŻÕi»į] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
4 likes22,757 views

2017/8/28 Deep Learning JP: http://deeplearning.jp/seminar-2/






![Method > Simultaneous Detection and Association
? ²æĪ»ŹÖŖ¤Ī confidence map ¤Č²æĪ»évS„؄󄳩`„ɤĪ affinity fields ¤ņĶ¬r¤Ė
Óčy.
? 2¤Ä¤Ī„Ö„é„ó„Į; [ķÉĻ] confidence map¤ņÓčy, [ķĻĀ] affinity fields¤ņÓčy.
? »Ļń¤Ļ¤Ž¤ŗConvÓ(VGG-19¤Ī×ī³õ10Ó¤Ē³õĘŚ»Æ)¤ĒIĄķ¤µ¤ģ, ĢŲÕ„Ž„Ć„×F¤Č¤·
¤Ę, Stage1¤Ī??¤Ė¤Ź¤ė.
? Stage1¤Ē, ŹÖŖ confidence map S1 = ¦Ń1(F)¤Č, part affinity fields¤Ī„»„Ć„Č L1
= ¦µ1(F)¤ņ?³É¤¹¤ė. (¦Ń, ¦µ¤Ļ¤½¤ģ¤¾¤ģ¤Īstage¤Ė¤Ŗ¤±¤ėCNNs)
? Ē°¤ĪStage¤Ī³ö?2¤Ä¤ČŌŖ¤ĪĢŲÕ„Ž„Ć„×F¤¬¤Ä¤Ź¤®ŗĻ¤ļ¤µ¤ģ¤Ę“Ī¤Ī??¤Ė¤Ź¤ė.
7](https://image.slidesharecdn.com/realtimemultipersonposeestimation1-170907054459/85/DL-Realtime-Multi-Person-2D-Pose-Estimation-using-Part-Affinity-Fields-7-320.jpg)


















![[DLŻÕi»į]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=560&fit=bounds)
![[DLŻÕi»į]A Higher-Dimensional Representation for Topologically Varying Neural R...](https://cdn.slidesharecdn.com/ss_thumbnails/ahigher-dimensionalrepresentationfortopologicallyvaryingneuralradiancefields1-210924021911-thumbnail.jpg?width=560&fit=bounds)






![SSII2021 [SS1] Transformer x Computer Vision¤Ī g»īÓĆæÉÄÜŠŌ¤ČÕ¹Ķū ? Transformer¤ĪCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=560&fit=bounds)




![[DLŻÕi»į]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=560&fit=bounds)


![[½āÕh„¹„鄤„É] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=560&fit=bounds)



![SSII2022 [SS1] „Ė„å©`„é„ė3D±ķ¬F¤Ī×īŠĀÓĻņ? „Ė„å©`„é„ė„Ķ„ƄȤĒ¤Ź¤ó¤Ē¤ā±ķ¤»¤ė£æ£æ ??](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=560&fit=bounds)
![[DLŻÕi»į]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=560&fit=bounds)






More Related Content
What's hot (20)
Similar to [DLŻÕi»į] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (20)









![[DLŻÕi»į]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=560&fit=bounds)


![[DLŻÕi»į]Meta-Learning Probabilistic Inference for Prediction](https://cdn.slidesharecdn.com/ss_thumbnails/20181214dl-181218052422-thumbnail.jpg?width=560&fit=bounds)


![[DLŻÕi»į]EfficientDet: Scalable and Efficient Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/191122dlseminar-191122013544-thumbnail.jpg?width=560&fit=bounds)
![[DLŻÕi»į]Dense Captioning·ÖŅ°¤Ī¤Ž¤Č¤į](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=560&fit=bounds)

More from Deep Learning JP (20)




















[DLŻÕi»į] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
- 1. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields |¾©?ѧ?ѧŌŗ?ѧĻµŃŠ¾ææĘ ¼¼Šg½UÓéĀŌѧ¹„ ĖÉĪ²ŃŠ¾æŹŅ ?Ņ°¾žµä
- 2. ųÕIĒéó 2 ? Õ?Ćū£ŗ”°Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields”± ØC https://arxiv.org/abs/1611.08050 ? ÖųÕߣŗZhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh ØC The Robotics Institute, Carnegie Mellon University ? ¹«é_?£ŗ24 Nov 2016 ? CVPR 2017 Oral ? ŗŻŗŻß£ ? Video ? ”ł ĢŲ¤Ė¶Ļ¤ź¤¬o¤¤öŗĻ¤Ļ, ÉĻÓÕ?, ŗŻŗŻß£, Video¤«¤éŅż?
- 4. Abstract ? »ĻńÖŠ¤ĪŃ}Źż?¤Ī2D„Ż©`„ŗ¤ņæĀŹµÄ¤ĖŹ³ö¤¹¤ė?·Ø¤ĪĢį°ø¤·¤Ę¤¤¤ė. ? ?·Ø¤ĪĢŲÕ ØC Part Affinity Fields(PAFs)£ŗ?Ģå²æĪ»¤Č”©?¤ĪévßBø¶¤±¤ņѧĮ¤·¤Ę¤¤¤ė. ØC „Ü„Č„ą„¢„Ƅ׵Ą¢„ׄķ©`„Į£ŗ»ĻńČ«ĢåÖŠ¤Ī?Ć}¤ņ„؄󄳩`„ɤ·, ?Źż¤Ė¤č¤é¤ŗ, ?ĖŁ? ?¾«¶Č¤ņ¾S³Ö. ØC Sequential Prediction with Learned Spatial Context£ŗCNN¤ĒÓčy¤ņ?¤¦„ę„Ė„ƄȤņ ĄR¤ź·µ¤¹. ØC Jointly Learning Parts detection and Parts Association£ŗ²æĪ»¤ĪöĖł¤Č¤½¤ĪévßBø¶¤± ¤ņ¹²Ķ¬¤ĒѧĮ¤¹¤ė ? ½Y¹ū ØC COCO2016keypoints challenge¤Ē1Ī», MPII Multi-Person benchmark¤Ė¤Ŗ¤¤¤Ęæ ĀŹ?¾«¶Č¤Č¤ā¤ĖsotaÉĻ»Ų¤Ć¤æ. 4
- 5. Introduction ? ¼Č“ęŃŠ¾æ¤Ē¤Ļ, Ń}Źż?¤Ī½j¤ą×“r¤Ē¤Ī”©?¤Ī?Ģå²æĪ»ŹÖŖ¤Ļėy¤·¤¤ī}¤Č¤·¤ĘÖŖ¤é¤ģ¤Ę¤ ¤æ. ØC ?Źż, „¹„±©`„ė¤¬²»¶Ø ØC ?Ķ¬?¤Ī„¤„ó„æ„é„Æ„·„ē„ó ØC ?Źż¤Ė?Ąż¤·¤ĘÓĖćĮæ¼Ó ? top-downµÄ„¢„ׄķ©`„Į£ŗ?¤ĪŹÖŖ¤ņ?¤¤, ¤½¤Īįį¤Ė?¤Ī×ĖŻĶĘ¶Ø¤ņ?¤¦. ØC ? ¢Ł »ĻńÄŚ¤Ī?¤ĪŹÖŖ¤ĖŹ§”¤¹¤ė¤Č”¢×ĖŻĶĘ¶Ø¤Ē¤¤Ź¤¤ ØC ? ¢Ś ?Źż¤Ė?Ąż¤·¤ĘÓĖćĮæ¼Ó ? bottom-upµÄ„¢„ׄķ©`„Į£ŗ”ū ±¾Õ?¤Ļ¤³¤Ć¤Į. ØC ? ¢Ł? ÉĻÓ¢Ł¤Ė¤·¤Ę, „ķ„Š„¹„Č. ØC ? ¢Ś? ÓĖćĮæŅ֤ؤ¦¤ė ØC ? ¼Č“ę¤Ī?·Ø¤Ē¤Ļ, Ėū¤ĪĢå²æĪ»¤ä?¤«¤é¤Ī„°„ķ©`„Š„ė¤Ź„³„ó„Ę„„¹„ČĒéó¤ņÖ±½ÓµÄ¤Ė¤ĻŹ¹¤Ø¤Ę¤Ŗ¤é¤ŗ, ²æĪ»¤Ī¤Ä¤Ź¤®ŗĻ¤ļ¤»¤ĪĶĘ¶Ø¤ĪÓĖćĮ椬¤«¤«¤ź, ?æĀŹ. ? ”ś ±¾Õ?¤Ē¤Ļ, ¤³¤³¤ņøÄÉĘ. ? ±¾Õ?¤Ē¤Ļ, bottom-up„¢„ׄķ©`„Į¤Ē, Ń}Źż?¤Ī„Ż©`„ŗĶĘ¶Ø¤ņSoTA¤Ī¾«¶Č¤Ēß_³É. ØC Part Affinity Fields(PAFs)¤Ė¤č¤Ć¤Ę²æĪ»Ķ¬?¤ĪévßB¶Č¤ņ±ķ¬F£ŗĢå²æĪ»¤ĪöĖł, Ļņ¤¤ņ„؄󄳩`„ɤ·¤æ2 “ĪŌŖ„Ł„Æ„Č„ė. ØC ²æĪ»ŹÖŖ¤ČévßB¶Č¤Ī„Ü„Č„ą„¢„Ƅ׵ĤŹ±ķ¬F¤ņĶ¬r¤ĖĶĘ¶Ø¤¹¤ė¤³¤Č¤Ē, „°„ķ©`„Š„ė¤Ź„³„ó„Ę„„¹„Ȥ¬? ·Ö„؄󄳩`„ɤĒ¤¤ė. ¤½¤ģ¤Ė¤č¤ź, ?¾«¶Č??ĖŁ¤ņg¬F¤·¤æ. 5
- 6. Method ? Feed forward network ¤Ė¤č¤ź, Ģå²æĪ»¤ĪĪ»ÖƤĪ confidence map S (ķb) ¤Č, „Ł„Æ„æ¤Ē²æ·Öég¤ĪévßB¶Č¤ņ„؄󄳩`„ɤ·¤æ affinity fields L (ķc)¤ņ×÷³É. ØC S = (S1, S2, ”, SJ) ¤Ē J¤Īconfidence maps¤ņ³Ö¤Ä. J¤Ī²æĪ»¤Ė¤½¤ģ¤¾¤ģź. ? Sj ”Ź Rw”Įh, j ”Ź {1”J} ØC L = (L1, L2, ”, LC) ¤Ē C¤Ī„Ł„Æ„æ³Ö¤Į, ¤½¤ģ¤¾¤ģø÷²æĪ»„Ś„¢¤Ėź. ? Lc ”Ź R w”Įh”Į2, c ”Ź {1”C} ? confidence map¤Čaffinity fields¤ņŌŖ¤Ė, Bipartite Matching(2µćég¤ĪévS ŠŌÓĖć)¤ņ?¤¦(ķd) 6 <??¤«¤é³ö?¤ĪĮ÷¤ģ£¾ ?? ³ö?
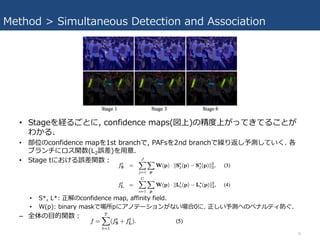
- 7. Method > Simultaneous Detection and Association ? ²æĪ»ŹÖŖ¤Ī confidence map ¤Č²æĪ»évS„؄󄳩`„ɤĪ affinity fields ¤ņĶ¬r¤Ė Óčy. ? 2¤Ä¤Ī„Ö„é„ó„Į; [ķÉĻ] confidence map¤ņÓčy, [ķĻĀ] affinity fields¤ņÓčy. ? »Ļń¤Ļ¤Ž¤ŗConvÓ(VGG-19¤Ī×ī³õ10Ó¤Ē³õĘŚ»Æ)¤ĒIĄķ¤µ¤ģ, ĢŲÕ„Ž„Ć„×F¤Č¤· ¤Ę, Stage1¤Ī??¤Ė¤Ź¤ė. ? Stage1¤Ē, ŹÖŖ confidence map S1 = ¦Ń1(F)¤Č, part affinity fields¤Ī„»„Ć„Č L1 = ¦µ1(F)¤ņ?³É¤¹¤ė. (¦Ń, ¦µ¤Ļ¤½¤ģ¤¾¤ģ¤Īstage¤Ė¤Ŗ¤±¤ėCNNs) ? Ē°¤ĪStage¤Ī³ö?2¤Ä¤ČŌŖ¤ĪĢŲÕ„Ž„Ć„×F¤¬¤Ä¤Ź¤®ŗĻ¤ļ¤µ¤ģ¤Ę“Ī¤Ī??¤Ė¤Ź¤ė. 7
- 8. Method > Simultaneous Detection and Association ? Stage¤ņ½U¤ė¤“¤Č¤Ė, confidence maps(ķÉĻ)¤Ī¾«¶ČÉĻ¤¬¤Ć¤Ę¤¤Ę¤ė¤³¤Č¤¬ ¤ļ¤«¤ė. ? ²æĪ»¤Īconfidence map¤ņ1st branch¤Ē, PAFs¤ņ2nd branch¤ĒĄR¤ź·µ¤·Óčy¤·¤Ę¤¤¤Æ. ø÷ „Ö„é„ó„Į¤Ė„ķ„¹évŹż(L2Õ`²ī)¤ņ?Ņā. ? Stage t¤Ė¤Ŗ¤±¤ėÕ`²īévŹż£ŗ ? S*, L*: Õż½ā¤Īconfidence map, affinity field. ? W(p): binary mask¤ĒöĖłp¤Ė„¢„Ī„Ę©`„·„ē„󤬤Ź¤¤öŗĻ0¤Ė. Õż¤·¤¤Óčy¤Ų¤Ī„Ś„Ź„ė„Ę„£·Ą¤°. ØC Č«Ģå¤Ī?µÄévŹż£ŗ 8
- 9. Method > Confidence Maps for Part Detection ? Ź½5¤Ē¤ĪŌuż¤Ī¤æ¤į, Õż½ā¤Īmap S*¤ņ„¢„Ī„Ę©`„·„ē„󤵤ģ¤æ2D„©`„Ż„¤„ó „Ȥ«¤é?³É¤¹¤ė. ? Ń}Źż?¤¤¤Ę, ø÷²æĪ»¤¬?¤Ø¤ė¤Č¤, ø÷²æĪ»j, ?k¤Ėź¤¹¤ėconfidence map ¤Ī„Ō©`„Ƥ¬“ęŌŚ¤¹¤Ł¤. ? ¤Ž¤ŗ, ”©¤Īconfidence maps S*j,k (Õż½ā)¤ņø÷?k¤Ė?³É¤¹¤ė. ØC xj,k”ŹR2¤ņ²æĪ»j?k¤Ī»ĻńÖŠ¤ĪÕż½āĪ»ÖƤȤ¹¤ė¤Č, S*jk¤Ė¤Ŗ¤±¤ėø÷öĖłp”ŹR2¤ĻŅŌĻĀ¤Ī¤č ¤¦¤Ė¶ØĮx¤µ¤ģ¤ė. ? ¦Ņ: „Ō©`„ƤĪŚ¤¬¤ź¾ßŗĻ¤ņÕ{Õū¤¹¤ėķ ØC „Ķ„Ć„Č„ļ©`„Ƥ«¤éÓčy¤µ¤ģ¤ėŠĪŹ½¤ĖŗĻ¤ļ¤»¤Ę, Č«¤Ę¤Ī?¤Ėév¤·¤Ęmap¤ņ¤¢¤ļ¤»¤Ę, ø÷²æ Ī»¤Ėév¤¹¤ėÕż½ā¤Īconfidence map¤ĻŅŌĻĀ¤Ī¤č¤¦¤Ė¤«¤±¤ė. (max„Ŗ„Ś„ģ©`„æ) 9
- 10. Method > Confidence Maps for Part Detection ? Confidence maps¤ĪĘ½¾ł¤ņČ”¤ė¤Ī¤Ē¤Ļo¤Æ”¢×ī?¤ņČ”¤ė¤č¤¦¤Ė¤¹¤ė¤³¤Č ¤Ē”¢·å¤Ė½ü¤¤öĖł¤¬Ć÷“_¤Ī¤Ž¤Ž¤Ē¤¢¤ģ¤ė”£ ? „Ę„¹„Čr¤Ļ”¢predict¤·¤æconfidence maps¤ņ?¤¤¤Ę”¢non-maximum suppression¤ņ?¤¦¤³¤Č¤Ē”¢Ģå²æĪ»¤ĪÓčyĪ»ÖƤņµĆ¤ė”£ ØC £ØŃa?£©Non-maximum suppression£ŗéŅŌÉĻ¤ĪøīŗĻ¤Ē·Ö²¼¤¬¤«¤Ö¤Ć¤Ę¤¤¤ėöŗĻ”¢ ×ī¤ā?¤¤confidence ¤ņ³Ö¤Ä·Ö²¼¤ņ²Š¤¹. 10
- 11. Method > Part Affinity Fields for Part Association ? ČĪŅā¤Ī?Źż¤Ī?¤Ėév¤·¤Ę, ŹÖŖ¤µ¤ģ¤æ²æĪ»Ķ¬?¤ņ¤¤¤«¤Ė¤Ä¤Ź¤²¤ė¤«. (ķa) ØC ÖŠégµć¤ņČ”¤ė? Ń}Źż?¤¬½ü¤«¤Ć¤æ¤ź¤¹¤ė¤Č¤¦¤Ž¤Æ¤Ä¤Ź¤®ŗĻ¤ļ¤»¤é¤ģ¤Ź¤¤(ķb) ? Ī»ÖƤĪ¤ß¤Ī„؄󄳩`„ɤĒĻņ¤Ēé󤏤¤¤Ź¤É±ķ¬F?¤ĪĻŽ½ē. ? ”ś Part affinity fields£ŗĪ»ÖĆĒéó, Ļņ¤Ēéó¤ņŗ¬¤ó¤Ą±ķ¬F(ķc) ØC ø÷limb(²æĪ»¤Ī¤Ä¤Ź¤®ŗĻ¤ļ¤»²æ·Ö)¤Ė¤·¤Ęø÷2D„Ł„Æ„Č„ė ØC ø÷limb¤ĻévßB¤¹¤ė²æĪ»¤ņ¤Ä¤Ź¤°affinity field¤ņ³Ö¤Ä. 11
- 12. Method > Part Affinity Fields for Part Association ? „Ł„Æ„Č„ė¤ĪQ¤į? ØC xj1,k , xj2,k: ?k¤Īlimb c ¤Ė¤Ŗ¤±¤ė²æĪ»j1,j2¤ĪÕż½ā¤Č¤¹¤ė. ØC Limb cÉĻ¤Īpoint pß_¤Ėév¤·¤Ę, L*c,k(p)¤Ļj1¤«¤éj2¤Ų¤Ī gĪ»„Ł„Æ„Č„ė¤Ė¤Ź¤ė. Limb cĶā ¤Īpoint p¤Ė¤Ŗ¤¤¤Ę¤ĻČ«¤Ęzero„Ł„Æ„Č„ė¤Ė. ¶ØŹ½»Æ¤¹¤ė¤ČŅŌĻĀ. ? v = (xj2,k-xj1,k) / || xj2,k-xj1,k ||2 £Ølimb¤ĪĻņ¤¤Ī gĪ»„Ł„Æ„Č„ė£© ØC Limb cÉĻ¤«¤É¤¦¤«¤ĪÅŠ¶Ø¤ĻŅŌĻĀ¤ĪŹ½¤Ē¶ØĮx. ? ·ł¦Ņl¤Ļ„Ō„Æ„»„ė¾ąėx, lc,k¤Ļ²æĪ»ég¤Ī„ę©`„Æ„ź„Ć„É¾ąėx. 12
- 13. Method > Part Affinity Fields for Part Association ? „Ķ„Ć„Č„ļ©`„Ƥ«¤éÓčy¤µ¤ģ¤ėŠĪ¤ĖŗĻ¤ļ¤»¤ĘČ«¤Ę¤Ī?¤Ėév¤·¤Ęfields¤ņ¤¢¤ļ¤» ¤Ęlimb¤“¤Č¤Īfield¤ņ?³É. (average) ØC nc(p)£ŗpoint p ¤Ė¤Ŗ¤¤¤Ęk people¤ĪÖŠ¤Ē„¼„ķ¤ø¤ć¤Ź¤¤„Ł„Æ„Č„ė¤ĪŹż(limb¤¬ÖŲ¤Ź¤Ć¤æö ŗĻ¤ĖĘ½¾łČ”¤ź¤æ¤¤¤æ¤į) ? „Ę„¹„Čr¤Ļ, ź¤¹¤ėPAF¤Ī¾·e·Ö¤ņŗņŃa²æĪ»¤ĪĪ»ÖƤņ½Y¤Ö¾·Ö¤ĖŃŲ¤Ć¤ĘÓ Ėć¤¹¤ė¤³¤Č¤Ē, ŗņŃa²æĪ»ég¤ĪévßB¶Č¤ņy¤ė. (= Ź³ö¤µ¤ģ¤æ²æĪ»¤ņ½Y¤Ö¤³¤Č¤Ē ×÷¤é¤ģ¤ėŗņŃalimb¤Č, Óčy¤µ¤ģ¤æPAFég¤Ī?ÖĀ¶Č¤ņy¤ė) ØC ¾ßĢåµÄ¤Ė¤Ļ, £²¤Ä¤ĪŗņŃa²æĪ»dj1¤Čdj2¤Ė¤·¤Ę, Óčy¤µ¤ģ¤æPAF Lc¤ņ²æĪ»ég¤Ī¾·Ö¤ĖŃŲ¤Ć ¤Ę„µ„ó„ׄź„ó„°¤·¤Ę, ²æĪ»¤ĪévßB¶Č¤Īconfidence¤ņÓy¤¹¤ė. ? p(u)£ŗ£²¤Ä¤Ī²æĪ»dj1¤Čdj2¤ņ¤Ä¤Ź¤°Ī»ÖĆ ØC g?ÉĻ¤Ļ, ?¶Øégøō¤Īu¤Ī¤ņŗĻÓ¤·¤Ę·e·Ö¤ņ½üĖʤ·¤Ę¤¤¤ė. 13
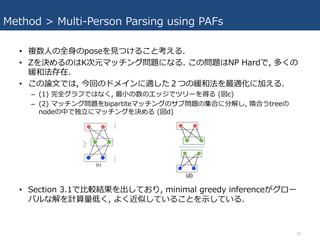
- 14. Method > Multi-Person Parsing using PAFs ? ø÷²æĪ»¤Ėév¤·¤ĘŃ}ŹżŹÖŖ¤µ¤ģ¤ėöĖł¤¬¤¢¤ź£ØŃ}Źż? or ĪźŠŌ¤ę¤Ø£©, ¤½¤Ī ·ÖæÉÄܤŹlimb¤Ī„Ń„æ©`„󤬶ą¤Æ“ęŌŚ. ? AFÉĻ¤Ī¾·e·ÖÓĖć¤Ė¤č¤źø÷ŗņŃalimb¤Ė„¹„³„¢¤ņ¤Ä¤±¤ė. ×īßm¤Ź½M¤ßŗĻ¤ļ¤»¤ņ ?¤Ä¤±¤ėī}¤Ļ, NP-Hardī}¤Ē¤¢¤ėK“ĪŌŖ¤Ī„Ž„Ć„Į„ó„°ī}¤Ėź¤¹¤ė. ØC ”ś greedy ¾ŗĶ·Ø¤Ė¤č¤Ć¤ĘI¤Ē¤¤ė. ØC ¤½¤ĪĄķÓɤĻ, PAF„Ķ„Ć„Č„ļ©`„ƤĪŹÜČŻŅ°¤¬?¤¤¤¤æ¤į, pair-wise¤ĪévßB¶Č„¹„³„¢¤¬°µüa ¤Ė„°„ķ©`„Š„ė„³„ó„Ę„„¹„Ȥņ„؄󄳩`„ɤ·¤Ę¤¤¤ė¤æ¤į¤Č漤ؤé¤ģ¤ė. (įįŹö) ? ¤Ž¤ŗ, Ń}Źż?¤ĪŗņŃa²æĪ»¤Ī¼ÆŗĻ¤ņµĆ¤ė. ØC DJ = {dj m : for j ”Ź {1”J}, m ”Ź{1”Nj} } ? Nj: ²æĪ»j¤ĪŗņŃaŹż ? dj m ”Ź R2: ¤Ļ²æĪ»j¤Īm·¬?¤ĪŹÖŖŗņŃa. ? ²æĪ»ŗņŃa dj1 m¤Čdj2 n¤¬¤Ä¤Ź¤¬¤Ć¤Ę¤¤¤ė¤«?¤¹äŹż z j1j2 mn ”Ź{0,1}¤ņ¶ØĮx. ØC „“©`„ė¤Ļ, æÉÄܤŹæ¤¬¤ź¤Ī¤¦¤Į×īßm¤Ź½M¤ßŗĻ¤ļ¤»¤ņ?¤Ä¤±¤ė¤³¤Č. ØC ŅŌĻĀZ¤Ļz¤ĪČ«½M¤ßŗĻ¤ļ¤»¤Ėév¤¹¤ė¼ÆŗĻ. 14
- 15. Method > Multi-Person Parsing using PAFs ? ¤¢¤ėc·¬?¤Īlimb¤Ė¤Ä¤Ź¤¬¤ėj1¤Čj2¤Ī„Ś„¢¤ņ漤ؤė. ØC Ź½10¤ĒĒó¤į¤æc¤Ė¤Ŗ¤±¤ėÖŲ¤ß¤¬×ī?¤Ė¤Ź¤ė¤č¤¦¤Ź?µćég„Ž„Ć„Į„ó„°¤ņ?¤¦. ØC Ec¤Ļlimb type c¤Ī„Ž„Ć„Į„ó„°¤ĪČ«Ģå¤ĪÖŲ¤ß¤Ē, Zc¤Ļlimb type c¤ĪZ¤Ī„µ„Ö„»„ƄȤĒ, Emn¤Ļ²æĪ»dj1 m¤Čdj2 nég¤Īpart affinity (Ź½10¤Ē¶ØĮx) ØC Ź½13,14¤Ļ, £²¤Ä¤Ī„Ø„Ć„ø¤¬„Ī©`„ɤņ„·„§„¢¤¹¤ė¤Ī¤ņ·Ą¤°. (Ķ¬¤øtype¤Ī£²¤Ä¤Īlimb¤¬²æ Ī»¤Ī¹²ÓŠ¤ņ·Ą¤°.) Hungarian algorithm¤Ē×īßm½ā?¤Ä¤±¤ė. 15
- 16. Method > Multi-Person Parsing using PAFs ? Ń}Źż?¤ĪČ«?¤Īpose¤ņ?¤Ä¤±¤ė¤³¤Č漤ؤė. ? Z¤ņQ¤į¤ė¤Ī¤ĻK“ĪŌŖ„Ž„Ć„Į„ó„°ī}¤Ė¤Ź¤ė. ¤³¤Īī}¤ĻNP Hard¤Ē, ¶ą¤Æ¤Ī ¾ŗĶ·Ø“ęŌŚ. ? ¤³¤ĪÕ?¤Ē¤Ļ, ½ń»Ų¤Ī„É„į„¤„ó¤Ėßm¤·¤æ£²¤Ä¤Ī¾ŗĶ·Ø¤ņ×īßm»Æ¤Ė¼Ó¤Ø¤ė. ØC (1) ĶźČ«„°„é„Õ¤Ē¤Ļ¤Ź¤Æ, ×ī?¤ĪŹż¤Ī„Ø„Ć„ø¤Ē„Ä„ź©`¤ņµĆ¤ė (ķc) ØC (2) „Ž„Ć„Į„ó„°ī}¤ņbipartite„Ž„Ć„Į„ó„°¤Ī„µ„Öī}¤Ī¼ÆŗĻ¤Ė·Ö½ā¤·, ėOŗĻ¤¦tree¤Ī node¤ĪÖŠ¤Ē¶Ą?¤Ė„Ž„Ć„Į„ó„°¤ņQ¤į¤ė (ķd) ? Section 3.1¤Ē?Ż^½Y¹ū¤ņ³ö¤·¤Ę¤Ŗ¤ź, minimal greedy inference¤¬„°„ķ©` „Š„ė¤Ź½ā¤ņÓĖćĮæµĶ¤Æ, ¤č¤Æ½üĖʤ·¤Ę¤¤¤ė¤³¤Č¤ņ?¤·¤Ę¤¤¤ė. 16
- 17. Method > Multi-Person Parsing using PAFs ? £²¤Ä¤Ī¾ŗĶ·Ø¤Ē, ×īßm»Æ¤ĻŅŌĻĀ¤Ī¤č¤¦¤Ė„·„ó„ׄė¤Ė·Ö½ā¤µ¤ģ¤ė. ? ¤ę¤Ø¤Ė, ø÷limb type¤Ė¤·¤Ę, Ź½12-14(ø÷limb c¤Ė¤·¤Ęjoint?¤Ä¤±¤ė¤ä ¤Ä)¤ņŹ¹¤Ć¤Ę, ¶Ą?¤Ė, limb¤Ī椬¤źŗņŃa¤ņµĆ¤ė. ? Č«¤Ę¤Īlimb椬¤źŗņŃa¤ņ³Ö¤Ć¤Ę, Ķ¬¤øŗņŃa²æĪ»¤ņ„·„§„¢¤¹¤ė椬¤ź¤ņ½M¤ß¤ļ ¤»¤Ę, Ń}Źż?¤ĪČ«?¤Īpose¤ņ×÷¤ė. 17
- 18. Results ? Ń}Źż?pose estimation¤Ī2¤Ä¤Ī„Ł„ó„Į„Ž©`„Æ ØC (1) MPII human multi-person dataset £Ø25k images, 40k ppl, 410 human activities£© ØC (2) the COCO 2016 keypoints challenge dataset ? ¤¤¤ķ¤ó¤ŹgŹĄ½ē¤Īדr¤Ī»Ļń¤ņŗ¬¤ó¤Ą„Ē©`„æ„»„Ć„Č ? ¤½¤ģ¤¾¤ģSotA. ? ÓĖćæĀŹ¤Ėév¤¹¤ėæ¼²ģ¤ā¼Ó¤Ø¤æ(Fig10. įįŹö) 18
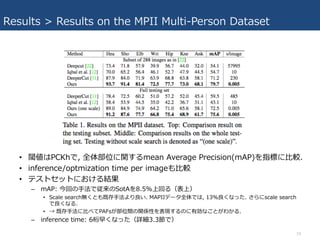
- 19. Results > Results on the MPII Multi-Person Dataset ? é¤ĻPCKh¤Ē, Č«Ģå²æĪ»¤Ėév¤¹¤ėmean Average Precision(mAP)¤ņÖøĖ¤Ė?Ż^. ? inference/optmization time per image¤ā?Ż^ ? „Ę„¹„Č„»„ƄȤĖ¤Ŗ¤±¤ė½Y¹ū ØC mAP: ½ń»Ų¤Ī?·Ø¤Ē¾Ą“¤ĪSotA¤ņ8.5%ÉĻ»Ų¤ė£Ø±ķÉĻ£© ? Scale searcho¤Æ¤Č¤ā¼Č“ę?·Ø¤č¤źĮ¼¤¤. MAPII„Ē©`„æČ«Ģå¤Ē¤Ļ, 13%Į¼¤Æ¤Ź¤Ć¤æ. ¤µ¤é¤Ėscale search ¤ĒĮ¼¤Æ¤Ź¤ė. ? ”ś ¼Č“ę?·Ø¤Ė?¤Ł¤ĘPAFs¤¬²æĪ»ég¤ĪévSŠŌ¤ņ±ķ¬F¤¹¤ė¤Ī¤ĖÓŠæ¤Ź¤³¤Č¤¬¤ļ¤«¤ė. ØC inference time: 6čģŌē¤Æ¤Ź¤Ć¤æ£ØŌ¼3.3¹¤Ē£© 19
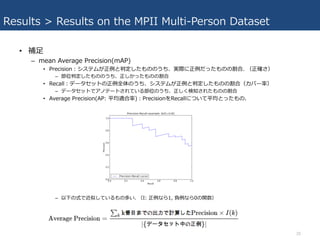
- 20. Results > Results on the MPII Multi-Person Dataset ? Ńa? ØC mean Average Precision(mAP) ? Precision£ŗ„·„¹„Ę„ą¤¬ÕżĄż¤ČÅŠ¶Ø¤·¤æ¤ā¤Ī¤Ī¤¦¤Į”¢gėH¤ĖÕżĄż¤Ą¤Ć¤æ¤ā¤Ī¤ĪøīŗĻ. £ØÕż“_¤µ£© ØC ²æĪ»ÅŠ¶Ø¤·¤æ¤ā¤Ī¤Ī¤¦¤Į”¢Õż¤·¤«¤Ć¤æ¤ā¤Ī¤ĪøīŗĻ ? Recall£ŗ„Ē©`„æ„»„ƄȤĪÕżĄżČ«Ģå¤Ī¤¦¤Į”¢„·„¹„Ę„ą¤¬ÕżĄż¤ČÅŠ¶Ø¤·¤æ¤ā¤Ī¤ĪøīŗĻ£Ø„«„Š©`ĀŹ£© ØC „Ē©`„æ„»„ƄȤĒ„¢„Ī„Ę©`„Ȥµ¤ģ¤Ę¤¤¤ė²æĪ»¤Ī¤¦¤Į”¢Õż¤·¤ÆŹÖŖ¤µ¤ģ¤æ¤ā¤Ī¤ĪøīŗĻ ? Average Precision(AP: Ę½¾łßmŗĻĀŹ)£ŗPrecision¤ņRecall¤Ė¤Ä¤¤¤ĘĘ½¾ł¤Č¤Ć¤æ¤ā¤Ī. ØC ŅŌĻĀ¤ĪŹ½¤Ē½üĖʤ·¤Ę¤¤¤ė¤ā¤Ī¶ą¤¤. £ØI: ÕżĄż¤Ź¤é1, ŲĄż¤Ź¤é0¤ĪévŹż£© 20
- 21. Results > Results on the MPII Multi-Person Dataset ? Ńa? ØC mean Average Precision(mAP)£ŗ½ń»Ų¤ĪöŗĻ ? mAP£ŗČ«¤Ę¤Ī?¤Ī²æĪ»¤Ė¤¹¤ėĘ½¾ł¤Īprecision”£ ØC ¤Ž¤ŗ”¢Ń}ŹżĢ劓¤Ć¤Ę¤¤¤ė»Ļń¤Ė¤·¤Ępose estimationg?”£ ØC ×ī¤ā?¤¤PCKhé¤Ė¤ā¤Č¤Å¤¤¤Ę”¢estimate¤µ¤ģ¤æ„Ż„¤„ó„Ȥņground truth(GT)¤Ėøī¤źŗĻ¤Ę¤Ę¤Æ”£ ØC GT¤Ėøī¤źµ±¤Ę¤é¤ģ¤Ź¤«¤Ć¤æÓčy„Ż„¤„ó„ȤĻ”¢false positive¤Č¤·¤ĘQ¤¦”£ ØC ø÷²æĪ»¤“¤Č¤ĖAverage Precision£ØAP£©¤ņÓĖć”£ ØC Č«Ģå¤Ī²æĪ»¤Ėév¤·¤ĘAP¤ĪĘ½¾ł¤ņČ”¤Ć¤Ę”¢mAP¤Ė¤Ź¤ė”£ ØC PCKh threshhold£ŗ ? PCP£ŗ¤¢¤ė„Ń©`„ĤĪI¶Ė¤Ī²æĪ»¤ĪŹ³öĪ»ÖƤ¬”¢¤½¤Ī„Ń©`„ĤĪ?¤µ¤Ī°ė·Ö¤č¤ź¤āÕż½ā¤Ė½ü¤±¤ģ¤Š Ź³ö³É¹¦¤Č¤¹¤ė. ? PCK£ŗ?Īļ¤Ībounding box„µ„¤„ŗ¤ĪÄꏿ¤ņé¤Č¤·¤Ę¶ØĮx ? PCKh£ŗHead„»„°„į„ó„ȤĪ50%¤Ī?¤µ¤ņé¤Č¤·¤Ę¶ØĮx 21
- 22. Results > Results on the MPII Multi-Person Dataset ? ®¤Ź¤ė„¹„±„ė„Č„óŌģ¤Ī?Ż^½Y¹ū ØC (6b) Č«¤Ę¤Ī„Ń„æ©`„ó¤Ä¤Ź¤¤¤Ą„Ø„Ć„ø, (6c) ×ī?ĻŽ¤Ī„Ä„ź©`„Ø„Ć„ø¤ĒÕūŹż„ź„Ė„¢„ׄķ„° „é„ß„ó„°¤Ē¤Č¤«¤ģ¤ė¤ā¤Ī, (6d) ×ī?ĻŽ¤Ī„Ä„ź©`„Ø„Ć„ø¤ĒŲÓū„¢„ė„“„ź„ŗ„ą¤Ė¤č¤Ć¤Ę¤Č¤« ¤ģ¤ė¤ā¤Ī ØC ”ś ×ī?ĻŽ¤Ī„Ø„Ć„ø¤Ē”¢ŠŌÄܵĤĖ¤Ļ?·Ö¤Ź¤³¤Č¤ņ?¤·¤Ę¤¤¤ė. ØC (6d)¤Ī„°„é„Õ¤¬¾«¶Č×ī¤āĮ¼¤Æ¤Ź¤Ć¤Ę¤¤¤ė.„Č„ģ©`„Ė„ó„°¤Ī §Źų¤¬¤Ļ¤ė¤«¤ĖČŻŅפĖ¤Ź¤ė¤æ ¤į¤Č漤ؤé¤ģ¤ė.(13 edges vs 91 edges) 22
- 23. Results > Results on the MPII Multi-Person Dataset ? PCKh-0.5¤Ī¤·¤¤¤¤ĪöŗĻ, PAF¤ņŹ¹?¤·¤æ½Y¹ū¤Ļ, ÖŠégµć±ķ?¤ņĄū?¤·¤æ½Y¹ū ¤č¤ź¤ģ¤Ę¤ė. (one-midpoint¤č¤ź2.9%?¤Æ, two-midpoint¤č¤ź2.3%?¤¤) ? „é„Ł„ė¤ņ¤Ä¤±¤é¤ģ¤Ę¤¤¤Ź¤¤?¤Ė„Ž„¹„ƤņŹ¹?¤·¤æÓ¾¤Ē, True Positive¤ĪÓčy¤Ė ¤č¤ė£Ø²»µ±¤Ź£©„ķ„¹·Ą¤°¤Č, 2.3%¾«¶ČøÄÉʤĒ¤¤ė. ? ²æĪ»detection¤ĪGround Truth¤ņ?¤¤¤Ę, PAFs¤ĒÓčy?¤¦¤Č, mAP 88.3%. ¤½ ¤ĪöŗĻDetection¤Ė¤Ŗ¤±¤ėÕ`²ī¤¬o¤¤¤Ī¤Ē, PCKhé¤Ė¤č¤é¤ŗ?¶Ø. ? ²æĪ»connection¤ĪGround Truth¤ņ?¤¤¤Ę, detect¤Ą¤±?¤¦„±©`„¹¤Ē¤Ļ, mAP 81.6%. ØC ”ś PAF¤Ė¤č¤ėconnectionÅŠ¶Ø¤Č, Ground TruthŹ¹?¤Ē¤Ū¤Č¤ó¤É¾«¶Č¤¬ä¤ļ¤é¤Ź¤¤. (79.4% vs 81.6%) . PAF¤¬, ?³£¤Ė?¤¤¾«¶Č¤ĒŹ³ö¤Ē¤¤ė¤³¤Č?¤·¤Ę¤¤¤ė. ? (b) stage¤“¤Č¤ĪmAP¤Ī?Ż^, ¾«¶ČÉĻ¤¬¤Ć¤Ę¤¤¤ė¤³¤Č¤¬¤ļ¤«¤ė. 23
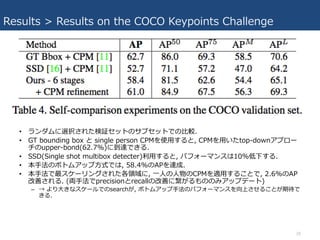
- 24. Results > Results on the COCO Keypoints Challenge ? 10Ķņ?ŅŌÉĻ¤Ī?Īļ, 100ĶņŅŌÉĻ¤Īkeypoints. ? COCO¤Ē¤ĪŌuż¤Ē¤Ļ, object keypoint similarity (OKS) ¤ņ¶ØĮx¤·, 10¤Ī OKSé¤Ē¤Īmean average precision (AP) ¤ņŹ¹?¤¹¤ė. ØC OKS¤Ļ, ĪļĢåÕJ×R¤Ė¤Ŗ¤±¤ėIoU¤ČĶ¬¤øŅŪøī. ØC ?¤Ī„¹„±©`„ė¤Č, GTĪ»ÖƤČÓčy¤Ī²ī, ¤ĪI?¤ņ?¤¤¤ĘÓĖ椵¤ģ¤ė. ? ±ķ3: top team¤Č¤Ī?Ż^. ? ?Ż^µÄ?¤µ¤¤„¹„±©`„ė¤Ī?(APM)¤Ėģ¶¤¤¤Ę¤Ļ, top-down„¢„ׄķ©`„Į¤Ī?·Ø ¤Ė¾«¶ČŲ¤±¤Ę¤ė. ØC ĄķÓÉ: ±¾?·Ø¤Ē¤Ļ, Ėū¤č¤ź¤Ļ¤ė¤«¤Ė?¤¤¤„¹„±©`„ė¤Ē, »ĻńÄŚ¤ĪČ«¤Ę¤Ī?”©¤ņ??¤ĖQ¤ļ ¤Ź¤¤¤Č¤¤¤±¤Ź¤¤. ? top-down„¢„ׄķ©`„Į¤Ē¤Ļ, ?¤ņŹÖŖ¤·¤Ę¤½¤Ī?¤“¤Č¤ĖĒŠ¤źČ”¤Ć¤Ę ?¤·¤ĘQ¤Ø¤ė¤Ī¤Ē, ?¤µ¤¤„¹„±©`„ė¤Ė¤č¤ėÓ°ķ¤¬?Ż^µÄ×÷¤Ź¤ė. 24
- 25. Ńa?: IoU ? Ņż?: http://www.pyimagesearch.com/2016/11/07/intersection- over-union-iou-for-object-detection/ 25
- 26. Results > Results on the COCO Keypoints Challenge ? „é„ó„Ą„ą¤Ėßxk¤µ¤ģ¤æŹŌ^„»„ƄȤĪ„µ„Ö„»„ƄȤĒ¤Ī?Ż^. ? GT bounding box ¤Č single person CPM¤ņŹ¹?¤¹¤ė¤Č, CPM¤ņ?¤¤¤ætop-down„¢„ׄķ©` „Į¤Īupper-bond(62.7%)¤Ėµ½ß_¤Ē¤¤ė. ? SSD(Single shot multibox detecter)Ąū?¤¹¤ė¤Č, „Ń„Õ„©©`„Ž„󄹤Ļ10%µĶĻĀ¤¹¤ė. ? ±¾?·Ø¤Ī„Ü„Č„ą„¢„Ć„×?Ź½¤Ē¤Ļ, 58.4%¤ĪAP¤ņß_³É. ? ±¾?·Ø¤Ē×ī„¹„±©`„ź„ó„°¤µ¤ģ¤æø÷īIÓņ¤Ė, ??¤Ī?Īļ¤ĪCPM¤ņßm?¤¹¤ė¤³¤Č¤Ē, 2.6%¤ĪAP øÄÉʤµ¤ģ¤ė. (I?·Ø¤Ēprecision¤Črecall¤ĪøÄÉʤĖ椬¤ė¤ā¤Ī¤Ī¤ß„¢„ƄׄĒ©`„Č) ØC ”ś ¤č¤ź?¤¤Ź„¹„±©`„ė¤Ē¤Īsearch¤¬, „Ü„Č„ą„¢„Ć„×?·Ø¤Ī„Ń„Õ„©©`„Ž„󄹤ņĻņÉĻ¤µ¤»¤ė¤³¤Č¤¬ĘŚ“ż¤Ē ¤¤ė. 26
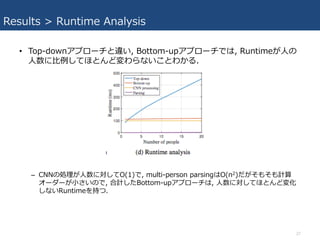
- 27. Results > Runtime Analysis ? Top-down„¢„ׄķ©`„Į¤Čß`¤¤, Bottom-up„¢„ׄķ©`„Į¤Ē¤Ļ, Runtime¤¬?¤Ī ?Źż¤Ė?Ąż¤·¤Ę¤Ū¤Č¤ó¤Éä¤ļ¤é¤Ź¤¤¤³¤Č¤ļ¤«¤ė. ØC CNN¤ĪIĄķ¤¬?Źż¤Ė¤·¤ĘO(1)¤Ē, multi-person parsing¤ĻO(n2)¤Ą¤¬¤½¤ā¤½¤āÓĖć „Ŗ©`„Ą©`¤¬?¤µ¤¤¤Ī¤Ē, ŗĻÓ¤·¤æBottom-up„¢„ׄķ©`„Į¤Ļ, ?Źż¤Ė¤·¤Ę¤Ū¤Č¤ó¤Éä»Æ ¤·¤Ź¤¤Runtime¤ņ³Ö¤Ä. 27
- 28. Discussion ? »ĻńÄŚ¤Ī?ĪļĄķ½ā¤Ė¤Ŗ¤¤¤Ę, Ń}Źż?Īļ¤Ī2“ĪŌŖ×ĖŻ?ŹĀ. ? ½ń»Ų¤Ī?·ņ ØC 1. ²æĪ»¤ĪĪ»ÖƤČ, ?Ļņ¤ĪI?¤ņ·ūŗŻƤ¹¤ė±ķ¬F ØC 2. ²æĪ»Ź³ö¤ČévSŠŌ¤ņ¹²Ķ¬¤Ēѧ¤Ö„¢©`„„Ę„Æ„Į„ć ØC 3. greedy„¢„ė„“„ź„ŗ„ą¤Ė¤č¤ź?¤ĪŹż¤¬¤Ø¤Ę¤āÓĖćĮæŅÖ¤Ø, ¾«¶Č?·Ö. ? “ś±ķµÄ¤ŹŹ§”ŹĀĄż 28
- 29. g×° ? C++£ŗhttps://github.com/CMU-Perceptual-Computing-Lab/openpose ? Caffe£ŗhttps://github.com/ZheC/Realtime_Multi- Person_Pose_Estimation ? PyTorch£ŗhttps://github.com/tensorboy/pytorch_Realtime_Multi- Person_Pose_Estimation (trainĪ“g×°) 29