ĄūDLÝÕiŧáĄŋAn Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Download as PPTX, PDF0 likes1,166 views

2022/8/19 Deep Learning JP http://deeplearning.jp/seminar-2/
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Ą°An Image is Worth One Word: Personalizing Text-to-
Image Generation usingTextual InversionĄą
University ofTsukuba M1,Yuki Sato](https://image.slidesharecdn.com/sato20220819-220819032017-7840a5f4/85/DL-An-Image-is-Worth-One-Word-Personalizing-Text-to-Image-Generation-using-Textual-Inversion-1-320.jpg)



![gōYÔOķĻ
? LAION-400MĪĮĘÂĮ°Ņ§ÁĪĩĪėĪŋLDMĨâĨĮĨë(1.4B params)ĪōĘđÓÃ.text
encoderĪËĪÏBERTĪŽÓÃĪĪĪéĪėĪÆĪĪĪë.
? V100x2ĪĮ5000epochŅ§ÁĪōÐÐĪÃĪŋ.
? Ņ§ÁrĪËČëÁĶĪđĪëÎÄÕÂĪÏCLIP ImageNet templates[1]ĪËĪĒĪëŌÔÏÂĪÎÎÄÕÂĪŦ
ĪéĨéĨóĨĀĨāĪËĨĩĨóĨŨĨęĨóĨ°.
8
[1] https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb](https://image.slidesharecdn.com/sato20220819-220819032017-7840a5f4/85/DL-An-Image-is-Worth-One-Word-Personalizing-Text-to-Image-Generation-using-Textual-Inversion-8-320.jpg)













![ËųļÐ
? ÉúģÉ―YđûĪōŌĪÆĪâŅÔÕZŧŊĪŽëyĪ·ĪĪŧÏņĪÎĖØÕĪōČëÁĶĪĩĪėĪŋÎÄÕÂĪÎŌâÎķĪË
žīĪ·ĪÆßmĮÐĪËÉúģÉ―YđûĪË·īÓģĪ·ĪÆĪŠĪęĄĒĨâĨĮĨëĪŽŅ§ÁĪ·Īŋ
gÕZĪÎĨËĨåĨĒĨó
ĨđĪōĀí―âĪŧĪšĪČĪâŌâíĪ·ĪŋŧÏņĪŽÉúģÉĪĮĪĪëŌâÁxĪÏīóĪĪĪ.
? ÖøÕßĪéĪÎĖá°ļĘÖ·ĻĪÏžČīæĪÎLDMĪōÓÃĪĪĪÆÂņĪáÞzĪßąíŽFĪōĖ―ËũĪđĪëĪČĪĪĪĶ
Ĩ·ĨóĨŨĨëĪĘĘÖ·ĻĪĮĪĒĪęĄĒLDMĪËÏÞĪéĪšËûĪÎŅ§ÁgĪßĪÎT2IĨâĨĮĨëĪËĪâęÓÃ
ĪŽŋÉÄÜĪČŋžĪĻĪéĪėĪë.
? 1
gÕZĪĮÎīÖŠĪÎŧÏņĪōÕhÃũĪĮĪĪëÂņĪáÞzĪßąíŽFĪŽŅ§ÁĪĮĪĪÆĪŠĪęĄĒ
DALLE-2ĪĮÖļÕŠĪĩĪėĪÆĪĪĪëĨâĨĮĨëķĀŨÔĪÎŅÔÕZ[1]ĪÎ―âÎöĪËĪâĀûÓÃĪĮĪĄĒĨâĨĮ
ĨëĪÎ―âáÐÔĪä°ēČŦÐÔĪÎŅÐūŋĪËĪâęÓÃĪĮĪĪëĪČŋžĪĻĪÆĪĪĪë.
22
1. Giannis Daras, Alexandros G. Dimakis. Ą°Discovering the HiddenVocabulary of DALLE-2Ąą.
arXiv preprint arXiv:2206.00169, 2022.](https://image.slidesharecdn.com/sato20220819-220819032017-7840a5f4/85/DL-An-Image-is-Worth-One-Word-Personalizing-Text-to-Image-Generation-using-Textual-Inversion-22-320.jpg)




![[DLÝÕiŧá]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=560&fit=bounds)
![[DLÝÕiŧá]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=560&fit=bounds)
![[DLÝÕiŧá]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=560&fit=bounds)



![[DLÝÕiŧá]StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators](https://cdn.slidesharecdn.com/ss_thumbnails/stylegan-nada-210813013304-thumbnail.jpg?width=560&fit=bounds)











![[DLÝÕiŧá]Dense Captioning·ÖŌ°ĪÎĪÞĪČĪá](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=560&fit=bounds)







More Related Content
What's hot (20)
More from Deep Learning JP (20)


















Recently uploaded (11)











ĄūDLÝÕiŧáĄŋAn Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- 1. 1 DEEP LEARNING JP [DL Papers] http://deeplearning.jp/ Ą°An Image is Worth One Word: Personalizing Text-to- Image Generation usingTextual InversionĄą University ofTsukuba M1,Yuki Sato
- 2. øÕIĮéó An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion ? Rinon Gal1, 2, Yuval Alaluf1, Yuval Atzmon2, Or Patashnik1, Amit H. Bermano1, Gal Chechik2, Daniel Cohen-Or1 - 1Tel-Aviv University, 2NVIDIA ? ÍķļåÏČ: arXiv(2022/08/02) ? ĨŨĨíĨļĨ§ĨŊĨČĨÚĐ`Ĩļ: https://textual-inversion.github.io/ ? ßxķĻĀíÓÉ: ?―üÄęĘĒĪóĪĘText-to-ImageĪËĪŠĪĪĪÆÉúģÉŧÏņĪÎķāÐÔĪĀĪąĪĮĪÏĪĘĪŊĨæĐ`ĨķĪÎŌâí ĪōžģĪóĪĀŧÏņÉúģÉĪōgŽFĪ·ĪÆĪŠĪęÐčŌŠĪŽļßĪĪĪČŋžĪĻĪéĪėĪë. ?Ĩ·ĨóĨŨĨëĪĘĘÖ·ĻĪĮęÓÃĪηųĪŽÚĪĪĪČŋžĪĻĪéĪėĪë. ĄųģöĩäĪŽÃũÓĪĩĪėĪÆĪĪĪĘĪĪÏÞĪęíąíĪÏÕÎÄ?ĨŨĨíĨļĨ§ĨŊĨČĨÚĐ`ĨļĪčĪęŌýÓà 2
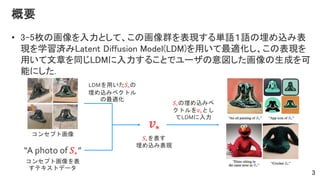
- 3. ? 3-5ÃķĪÎŧÏņĪōČëÁĶĪČĪ·ĪÆĄĒĪģĪÎŧÏņČšĪōąíŽFĪđĪë gÕZĢąÕZĪÎÂņĪáÞzĪßąí ŽFĪōŅ§ÁgĪßLatent Diffusion Model(LDM)ĪōÓÃĪĪĪÆŨîßmŧŊĪ·ĄĒĪģĪÎąíŽFĪō ÓÃĪĪĪÆÎÄÕÂĪōÍŽĪļLDMĪËČëÁĶĪđĪëĪģĪČĪĮĨæĐ`ĨķĪÎŌâíĪ·ĪŋŧÏņĪÎÉúģÉĪōŋÉ ÄÜĪËĪ·Īŋ. 3 ĨģĨóĨŧĨŨĨČŧÏņ ?? ??ĪōąíĪđ ÂņĪáÞzĪßąíŽF Ą°A photo of ??Ąą ĨģĨóĨŧĨŨĨČŧÏņĪōąí ĪđĨÆĨĨđĨČĨĮĐ`Ĩŋ ļÅŌŠ LDMĪōÓÃĪĪĪŋ??ĪÎ ÂņĪáÞzĪßĨŲĨŊĨČĨë ĪÎŨîßmŧŊ ??ĪÎÂņĪáÞzĪßĨŲ ĨŊĨČĨëĪō??ĪČĪ· ĪÆLDMĪËČëÁĶ
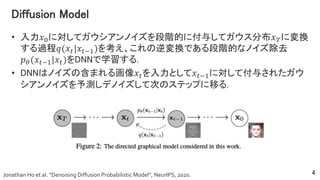
- 4. Diffusion Model ? ČëÁĶ?0ĪËĪ·ĪÆĨŽĨĶĨ·ĨĒĨóĨÎĨĪĨšĪōķÎëAĩÄĪËļķÓëĪ·ĪÆĨŽĨĶĨđ·Öēž??ĪËäQ ĪđĪëß^ģĖ?(??|???1)ĪōŋžĪĻĄĒĪģĪėĪÎÄæäQĪĮĪĒĪëķÎëAĩÄĪĘĨÎĨĪĨšģýČĨ ??(???1|??)ĪōDNNĪĮŅ§ÁĪđĪë. ? DNNĪÏĨÎĨĪĨšĪΚŽĪÞĪėĪëŧÏņ??ĪōČëÁĶĪČĪ·ĪÆ???1ĪËĪ·ĪÆļķÓëĪĩĪėĪŋĨŽĨĶ Ĩ·ĨĒĨóĨÎĨĪĨšĪōÓčyĪ·ĨĮĨÎĨĪĨšĪ·ĪÆīÎĪÎĨđĨÆĨÃĨŨĪËŌÆĪë. 4 Jonathan Ho et al. Ą°Denoising Diffusion Probabilistic ModelĄą, NeurIPS, 2020.
- 5. Latent Diffusion Model ? AutoEncoderĪÎĮąÔÚäĘýĪËĪ·ĪÆDiffusion modelĪōßmÓÃĪđĪëĨâĨĮĨë. ? ČëÁĶŧÏņĪŦĪéEncoder?ĪōÓÃĪĪĪÆÖÐégąíŽFĪōģéģöĪ·ĄĒÖÐégąíŽFĪËĪ·ĪÆ Diffusion modelĪōßmÓÃĄĒÔŲģÉĪĩĪėĪŋÖÐégąíŽFĪōDecoder ?ĪËČëÁĶĪ·ĪÆŧ ÏņĪōģöÁĶĪđĪë. ? ?, ?ĪÏĘÂĮ°ĪËŅ§ÁĪĩĪėĪÆĪŠĪęĄĒU-Net??ĪČĖõžþļķĪąĪÎEncoder ??ĪÎŅ§Ár ĪËĪÏđĖķĻĪđĪë. 5 Robin Rombach et al. Ą°High-Resolution Image Synthesis with Latent Diffusion ModelĄą, CVPR, 2022. ? ĄĘ ??ĄÁ?ĄÁ3 ? ĄĘ ??ĄÁ?ĄÁ?
- 6. Latent Diffusion Model ? LDMĪÎĪĮĪÏÖÐégąíŽFĪËĪ·ĪÆĨÎĨĪĨšĪōļķÓëĪ·U-Net ??ĪĮĨĮĨÎĨĪĨšĪđĪë.ĪģĪÎ rĄĒĨĮĨÎĨĪĨšß^ģĖĪËĪŠĪĪĪÆĨŊĨéĨđĨéĨŲĨëĩČĪōEncoder ??ĪōÓÃĪĪĪÆÖÐégąíŽF ĪËäQĪ·??ĪÎcross-attentionĪĮÓÃĪĪĪë. ? ??ĪČ??ĪÏŌÔÏÂĪÎpʧévĘýĪĮÍŽrĪËŨîßmŧŊĪĩĪėĪë. 6 Robin Rombach et al. Ą°High-Resolution Image Synthesis with Latent Diffusion ModelĄą, CVPR, 2022. ĖõžþļķĪąĪëĖØÕÁŋ: ?? ? ĄĘ ??ĄÁ?? U-NetĪÎÖÐégĖØÕÁŋ: ?? ?? ĄĘ ??ĄÁ?? ? Attention ?, ?, ? = softmax ??? ? ? ? ? = ? ? (?) ? ?? ?? , ? ? ? ĄĘ ??ĄÁ?? K = ? ? (?) ? ?? ? , ? ? ? ĄĘ ??ĄÁ?? V = ? ? (?) ? ?? ? , ? ? (?) ĄĘ ??ĄÁ?? ?
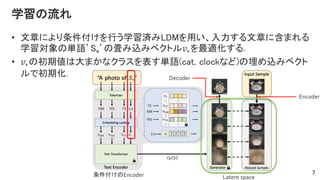
- 7. Ņ§ÁĪÎÁũĪė ? ÎÄÕÂĪËĪčĪęĖõžþļķĪąĪōÐÐĪĶŅ§ÁgĪßLDMĪōÓÃĪĪĄĒČëÁĶĪđĪëÎÄÕÂĪËšŽĪÞĪėĪë Ņ§ÁÏóĪÎ gÕZĄŊS*ĄŊĪÎŪĪßÞzĪßĨŲĨŊĨČĨë??ĪōŨîßmŧŊĪđĪë. ? ??ĪÎģõÆÚĪÏīóĪÞĪŦĪĘĨŊĨéĨđĪōąíĪđ gÕZ(cat, clockĪĘĪÉ)ĪÎÂņĪáÞzĪßĨŲĨŊĨČ ĨëĪĮģõÆÚŧŊ. 7 ĖõžþļķĪąĪÎEncoder Latent space Encoder Decoder
- 8. gōYÔOķĻ ? LAION-400MĪĮĘÂĮ°Ņ§ÁĪĩĪėĪŋLDMĨâĨĮĨë(1.4B params)ĪōĘđÓÃ.text encoderĪËĪÏBERTĪŽÓÃĪĪĪéĪėĪÆĪĪĪë. ? V100x2ĪĮ5000epochŅ§ÁĪōÐÐĪÃĪŋ. ? Ņ§ÁrĪËČëÁĶĪđĪëÎÄÕÂĪÏCLIP ImageNet templates[1]ĪËĪĒĪëŌÔÏÂĪÎÎÄÕÂĪŦ ĪéĨéĨóĨĀĨāĪËĨĩĨóĨŨĨęĨóĨ°. 8 [1] https://github.com/openai/CLIP/blob/main/notebooks/Prompt_Engineering_for_ImageNet.ipynb
- 12. gōY―Yđû: ĨđĨŋĨĪĨëäQ ? ČëÁĶĪđĪëĨÆĨĨđĨČĪōĄąA painting in the style of S*ĄąĪČĪ·ĪÆŅ§Á. 12
- 16. gōY―Yđû: ÂņĪáÞzĪßąíŽFĪÎŅ§ÁĘÖ·ĻĪÎąČÝ^ ? Extended latent space: ÂņĪáÞzĪßąíŽFĪōŅ§ÁĪđĪë gÕZĘýĪō2,3ĪË. ? Progressive extensions: 2000stepĪīĪČĪËÂņĪáÞzĪßąíŽFĪōŨ·žÓ. ? Regularization: īóĪÞĪŦĪĘĨŊĨéĨđĪōąíĪđÂņĪáÞzĪßąíŽFĪËĪčĪëÕýtŧŊ. ? Pre-image token: Ņ§ÁĨĮĐ`ĨŋĨŧĨÃĨČČŦĖåĪōąíŽFĪđĪ륰S*ĄąĪČeĪÎĖØÕĪōąí ŽFĪđĪë{?? ? }??1ĪōķĻÁxĪ·ĪÆĄąA photo of S* with SiĄąĪČĪĪĪĶĨÆĨĨđĨČĪōČëÁĶĪ·ĪÆ ŨîßmŧŊĪōÐÐĪĶ. ? Human captions: Ą°S*ĄąĪōČËégĪÎĨĨãĨŨĨ·ĨįĨóĪËÖÃĪQĪĻĪë. ? Reference: Ņ§ÁĨĮĐ`ĨŋĨŧĨÃĨČĪÎĨĮĐ`ĨŋĪČĄ°S*ĄąĪōÓÃĪĪĪĘĪĪĨÆĨĨđĨČĪōČëÁĶĪ·ĪÆ ĩÃĪéĪėĪëÉúģÉĨĮĐ`ĨŋĪōĘđÓÃ. ? Textual-Inversion: ĨâĨĮĨëĪÎŅ§ÁÂĘĪō2e-2,1e-4ĪĮgōY. ? Additional setup: Bipartite inversionĪČpivotal inversionĪōŨ·žÓ. 16
- 17. gōY―Yđû: ÂņĪáÞzĪßąíŽFĪÎÔuýÖļË ? Ą°A photo of S*ĄąĪÎĨÆĨĨđĨČĪČÂņĪáÞzĪßąíŽFĪōÓÃĪĪĪÆÉúģÉĪĩĪėĪŋ64ÃķĪÎŧÏņ ĪČÂņĪáÞzĪßąíŽFĪÎŅ§ÁĪËÓÃĪĪĪŋĨĮĐ`ĨŋĨŧĨÃĨČĪÎĨÚĨĒĪīĪČĪÎCLIPĖØÕÁŋĪÎĨģ ĨĩĨĪĨóîËÆķČĪÎÆ―ūųĪĮÔŲģÉĪÎūŦķČĪōËãģöĪđĪë.(Image Similarity) ? ąģū°ĪÎäļüĄĒĨđĨŋĨĪĨëĪÎäļüĪĘĪÉĄĐĪĘëyŌŨķČĪÎĨÆĨĨđĨČ(ex Ą°A photo of S* on the moonĄą)ĪōÓÃĪĪĪÆĄĒļũĨÆĨĨđĨČĪōČëÁĶĪČĪ·ĪÆ50ŧØĪÎDDIMĨđĨÆĨÃĨŨĪĮ 64ÃķĪÎŧÏņĪōÉúģÉĪ·ĄĒÉúģÉŧÏņĪÎCLIPĖØÕÁŋĪÎÆ―ūųĪōËãģöĄĒĄą S*ĄąĪōšŽĪÞ ĪĘĪĪĨÆĨĨđĨČ(ex Ą°A photo of on the moonĄą)ĪÎCLIPĖØÕÁŋĪČĪÎĨģĨĩĨĪĨóî ËÆķČĪōËãģöĪđĪë.(Text Similarity) 17
- 18. gōY―Yđû: ÂņĪáÞzĪßąíŽFĪÎÔuý ? ķāĪŊĪÎĘÖ·ĻĪÎÔŲģÉĪÎūŦ ķČĪÏŅ§ÁÓÃĨĮĐ`ĨŋĨŧĨÃĨČĪŦ ĪéĨéĨóĨĀĨāĪËģéģöĪ·ĪŋöšÏ ĪČÍŽĪĮĪĒĪë. ? 1 gÕZĪÎöšÏĪŽŨîĪâtext similarityĪŽļßĪĪ. 18
- 19. gōY―Yđû: ČËĪËĪčĪëÔuý ? ĢēĪÄĪÎĨĒĨóĨąĐ`ĨČĪōļũ600žþĄĒÓ1200žþ §žŊĪ·Īŋ. 1. ĢīĪÄĪÎŅ§ÁĨĮĐ`ĨŋĪÎŧÏņĪËĪ·ĪÆĨâĨĮĨëĪŽÉúģÉĪ·ĪŋĢĩĪÄÄŋĪÎŧÏņĪŽĪÉĪÎģĖķČîËÆ Ī·ĪÆĪĪĪëĪŦĨéĨóĨŊļķĪąĪ·ĪÆĪâĪéĪĶ. 2. ŧÏņĪÎÎÄÃ}ĪōąíĪđĨÆĨĨđĨČĪČÉúģÉĪĩĪėĪŋŧÏņĪÎîËÆķČĪōĨéĨóĨŊļķĪąĪ·ĪÆĪâĪéĪĶ. 19
- 21. LimitationĪČsocial impact ? Limitation ?ÔŲģÉĪÎūŦķČĪŽĪÞĪĀĩÍĪŊĄĒĢąĪÄĪÎÂņĪáÞzĪßąíŽFĪÎŅ§ÁĪËĢērégĪŦĪŦĪë. ? Social impact ?T2IĨâĨĮĨëĪÏÓÃĪĩĪėĪëŋÉÄÜÐÔĪŽÖļÕŠĪĩĪėĪÆĪŠĪęĄĒĨŅĐ`Ĩ―ĨĘĨéĨĪĨšĪđĪëĪģĪČĪĮĪčĪęÕæÎ ĪŽŌOĪáĪËĪŊĪŊĪĘĪëĪčĪĶĪËËžĪĻĪëĪŽĪģĪÎĨâĨĮĨëĪÏĪ―ĪģĪÞĪĮÁĶĪĮĪĘĪĪ. ?ķāĪŊĪÎT2IĨâĨĮĨëĪĮĪÏÉúģÉ―YđûĪčĪÃĪÆÆŦĪęĪŽÉúĪļĪëĪŽgōY―YđûĪčĪęĪģĪÎĨâĨĮĨëĪÏĪģĪė ĪōÝXpĪĮĪĪëĪĀĪíĪĶ. ?ĨæĐ`ĨķĪŽĨĒĐ`ĨÆĨĢĨđĨČĪÎŧÏņĪōoķÏĪĮŅ§ÁĪËÓÃĪĪĪÆîËÆŧÏņĪōÉúģÉĪĮĪĪëĪŽĄĒ―ŦĀī ĩÄĪËĪÏĨĒĐ`ĨÆĨĢĨđĨČĪŽT2IĨâĨĮĨëĪËĪčĪëķĀŨÔĪÎĨđĨŋĨĪĨëĪÎŦ@ĩÃĪäŅļËŲĪĘģõÆÚĨŨĨíĨÃĨČ ĪÎŨũģÉĪČĪĪĪÃĪŋķũ{ĪĮÏāĒĪĩĪėĪëĪģĪČĪōÆÚīýĪđĪë. 21
- 22. ËųļÐ ? ÉúģÉ―YđûĪōŌĪÆĪâŅÔÕZŧŊĪŽëyĪ·ĪĪŧÏņĪÎĖØÕĪōČëÁĶĪĩĪėĪŋÎÄÕÂĪÎŌâÎķĪË žīĪ·ĪÆßmĮÐĪËÉúģÉ―YđûĪË·īÓģĪ·ĪÆĪŠĪęĄĒĨâĨĮĨëĪŽŅ§ÁĪ·Īŋ gÕZĪÎĨËĨåĨĒĨó ĨđĪōĀí―âĪŧĪšĪČĪâŌâíĪ·ĪŋŧÏņĪŽÉúģÉĪĮĪĪëŌâÁxĪÏīóĪĪĪ. ? ÖøÕßĪéĪÎĖá°ļĘÖ·ĻĪÏžČīæĪÎLDMĪōÓÃĪĪĪÆÂņĪáÞzĪßąíŽFĪōĖ―ËũĪđĪëĪČĪĪĪĶ Ĩ·ĨóĨŨĨëĪĘĘÖ·ĻĪĮĪĒĪęĄĒLDMĪËÏÞĪéĪšËûĪÎŅ§ÁgĪßĪÎT2IĨâĨĮĨëĪËĪâęÓà ĪŽŋÉÄÜĪČŋžĪĻĪéĪėĪë. ? 1 gÕZĪĮÎīÖŠĪÎŧÏņĪōÕhÃũĪĮĪĪëÂņĪáÞzĪßąíŽFĪŽŅ§ÁĪĮĪĪÆĪŠĪęĄĒ DALLE-2ĪĮÖļÕŠĪĩĪėĪÆĪĪĪëĨâĨĮĨëķĀŨÔĪÎŅÔÕZ[1]ĪÎ―âÎöĪËĪâĀûÓÃĪĮĪĄĒĨâĨĮ ĨëĪÎ―âáÐÔĪä°ēČŦÐÔĪÎŅÐūŋĪËĪâęÓÃĪĮĪĪëĪČŋžĪĻĪÆĪĪĪë. 22 1. Giannis Daras, Alexandros G. Dimakis. Ą°Discovering the HiddenVocabulary of DALLE-2Ąą. arXiv preprint arXiv:2206.00169, 2022.