


















![Smoothing regularization
ŌĆó ņØ╝ļ░śņĀüņØĖ RegularizationņØś ņØæņÜ®.
ŌĆó ØæÜØæ¢ØæøØæ¢ØæÜØæ¢Øæ¦ØæÆ (ØÉ┐ ØÉ┤, ØÆÖ, ØæÅ , Ōłź ØÆÖ Ōłź)
ŌĆó ØÆÖ Ļ░Ć ņŗ£Ļ░äņŚÉ ļö░ļźĖ ļ│ĆņłśņØ╝ ļĢī
ŌĆó (ex, Øæźd : [0, 1]ņØä nļČäĒĢĀ Ē¢łņØä ļĢī, i/n ņŗ£ņĀÉņØś ņś©ļÅä)
ŌĆó | ØÆÖ | ļīĆņŗĀņŚÉ | ØÉĘØÆÖ | ļź╝ ļäŻļŖöļŗż.
ŌĆó ØÉĘØæź : Øæź ņØś ļ│ĆļÅÖņä▒ņØ┤ļéś ļ¦żļüäļ¤¼ņÜ┤ ņĀĢļÅäļź╝ ņĖĪņĀĢĒĢśļŖö ĒĢ©ņłś](https://image.slidesharecdn.com/vectoroptimization-200118074429/85/Vector-Optimization-21-320.jpg)





















![[ĒÖŹļīĆ ļ©ĖņŗĀļ¤¼ļŗØ ņŖżĒä░ļöö - ĒĢĖņ”łņś© ļ©ĖņŗĀļ¤¼ļŗØ] 4ņן. ļ¬©ļŹĖ ĒøłļĀ©](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=560&fit=bounds)
![[ĒĢ£ĻĖĆ] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=560&fit=bounds)



![[ļ░æļ¤¼ļŗØ] Chap06 ĒĢÖņŖĄĻ┤ĆļĀ©ĻĖ░ņłĀļōż](https://cdn.slidesharecdn.com/ss_thumbnails/chap06-171119110341-thumbnail.jpg?width=560&fit=bounds)







![[GomGuard] ļē┤ļ¤░ļČĆĒä░ YOLO Ļ╣īņ¦Ć - ļöźļ¤¼ļŗØ ņĀäļ░śņŚÉ ļīĆĒĢ£ ņØ┤ņĢ╝ĻĖ░](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=560&fit=bounds)




More Related Content
Similar to Vector Optimization (20)
More from SEMINARGROOT (20)


















Vector Optimization
- 1. Vector optimization ņäØ ņ¦ä ĒÖś
- 2. ņÜ®ņ¢┤ ņĀĢļ”¼ ŌĆó Convex ŌĆó Regularization ŌĆó L1, L2
- 3. ņĄ£ņĀüĒÖö ļ¼ĖņĀ£ Ēæ£ņżĆņĀü ĒśĢĒā£ Q : What is optimal( ņĀ£ņØ╝ ņóŗņØĆ ) vector x* in this primal problem? Step 1. Existence ( SlaterŌĆÖs Condition ) Step 2. Where? ( KKT Condition ) Step 3. How? ( Backtracking Line Search, Gradient Descent, ŌĆ” )
- 5. example
- 6. ņäĀĒśĖ ņ▓┤Ļ│äĻ░Ć ĒĢŁņāü ļ¬ģĒÖĢĒĢ£ Ļ▓āņØĆ ņĢäļŗłļŗż. ĒÖĢņŗżĒĢ£ Ļ▓āņØĆ Ļ│Āļō▒ņ¢┤ 4ļ¦łļ”¼ņÖĆ 2000ņøÉņØ┤ ļæÉ Ļ▓ĮņÜ░ļ│┤ļŗż ļŹö ņóŗļŗżļŖö Ļ▓ā!
- 7. ņ¦¼ļĮĢĻ│╝ ņ¦£ņןļ®┤ ņżæņŚÉ ĒĢśļéśļź╝ ņäĀĒāØĒĢ┤ņĢ╝ĒĢśļŖö ņł£Ļ░ä.. Regularization termņØä ņČöĻ░ĆĒĢśļŖö ņØ┤ņ£Ā - ļ¬©ņłśņØś ņĀłļīĆĻ░ÆņØä ņżäņØ┤ĻĖ░ ņ£äĒĢ©. - ņłśļ”¼ņĀü Ēæ£ĒśäņŚÉ ļīĆĒĢ┤ Ļ│Āļ»╝ĒĢ┤ļ│┤ņ×É.
- 8. Standard form of ŌĆ£Vector optimizationŌĆØ Proper coneņØĆ ļČĆļČäņĀüņ£╝ļĪ£ ļīĆņåī Ļ┤ĆĻ│äļź╝ ļ¦īļōżņ¢┤ņżĆļŗż.
- 9. ŌĆś(ņĀ£ņØ╝) ņóŗņØĆŌĆÖ ņØś ņĀĢņØś, Optimal and Pareto optimal ņĄ£Ļ│Ā ņÖĆ ņĄ£ņäĀņØś ņ░©ņØ┤
- 11. Remark. ŌĆó Vector optimization ņŚÉņä£ļŖö optimal(ņĄ£ņĀü) point ļź╝ ņ░ŠĻĖ░ļ│┤ļŗżļŖö Pareto(ņĄ£ņäĀ) optimal ņØä ņ░ŠļŖö Ļ▓āņØ┤ ņĀüņĀłĒĢśļŗż. ŌĆó Pareto optimal value lies in the boundary of the set of achievable object values. ŌĆó Optimal point is Pareto optimal. ŌĆó Pareto optimal point ļź╝ ļ¬©ļæÉ ņ░Šņ×É. ŌĆó ĻĘĖ ņżæņŚÉ Optimal pointĻ░Ć ņ׳ļŗżļ®┤ optimal valueļź╝ ņēĮĻ▓ī ņĢī ņłś ņ׳ļŗż.
- 12. Pareto optimal ņØä ņ░ŠļŖö ļ░®ļ▓Ģ ŌĆō Scalarization ņØ┤ ļ░®ļ▓Ģņ£╝ļĪ£ ļ¬©ļōĀ pareto optimal ņØä ņ░ŠņØä ņłś ņ׳ļŖö Ļ▓āņØĆ ņĢäļŗłļŗż.
- 13. ŌĆó Lemma ØÉ┐ØæÆØæĪ Øæå ØæÅØæÆ ØæÄ ØæÉØæ£ØæøØæŻØæÆØæź ØæĀØæÆØæĪ. ØÉ╣Øæ£Øæ¤ ØæÄØæøØæ” ØæÜØæ¢ØæøØæ¢ØæÜØæÄØæÖ ØæÆØæÖØæÆØæÜØæÆØæøØæĪ Øæŗ Øæ£Øæō Øæå, ØæćŌäÄØæÆØæ¤ØæÆ ØæÆØæźØæ¢ØæĀØæĪØæĀ ØæÄ ØæøØæ£ØæøØæ¦ØæÆØæ¤Øæ£ Ø£å ŌēĮ<ŌłŚ 0 ØæĀØæóØæÉŌäÄ ØæĪŌäÄØæÄØæĪ Øæŗ ØæÜØæ¢ØæøØæ¢ØæÜØæ¢Øæ¦ØæÆØæĀ Ø£å@ Øæ¦ Øæ£ØæŻØæÆØæ¤ Øæ¦ Ōłł Øæå. pf ) easy ŌĆó Proposition ØÉ╣Øæ£Øæ¤ ØÉČØæ£ØæøØæŻØæÆØæź ØæŻØæÆØæÉØæĪØæ£Øæ¤ Øæ£ØæØØæĪØæ¢ØæÜØæ¢Øæ¦ØæÄØæĪØæ¢Øæ£Øæø ØæØØæ¤Øæ£ØæÅØæÖØæÆØæÜ, for every Pareto optimal point ØæźRS , ØæĪŌäÄØæÆØæ¤ØæÆ Øæ¢ØæĀ ØæÄ ØæøØæ£ØæøØæ¦ØæÆØæ¤Øæ£ Ø£å ŌēĮ<ŌłŚ 0 ØæĀØæóØæÉŌäÄ ØæĪŌäÄØæÄØæĪ ØæźRS ØæÜØæ¢ØæøØæ¢ØæÜØæ¢Øæ¦ØæÆØæĀ ØæĪŌäÄØæÆ ØæĀØæÉØæÄØæÖØæÄØæ¤Øæ¢Øæ¦ØæÆØææ ØæØØæ¤Øæ£ØæÅØæÖØæÆØæÜ. ŌĆó Remark! ŌĆó Optimal of the scalarized problem Ō¤Č Pareto optimal Ōŗ» Ø£å Ōē╗<ŌłŚ 0 ŌĆó Pareto optimal Ō¤Č Optimal of the scalarized problem Ōŗ» Ø£å ŌēĮ<ŌłŚ 0 ņ┤łĻ│╝ņØĖņ¦Ć ņØ┤ņāüņØĖņ¦ĆļŖö ņŗżļ¼┤ņĀüņ£╝ļĪ£ ļ│ä ļ¼ĖņĀ£ ņĢäļŗłļŗż !!
- 14. ņ¦ĆĻĖłĻ╣īņ¦Ć ĒĢ£ Ļ▓āļōżņØä ņĀĢļ”¼ļź╝ ĒĢśļ®┤ 1. ņäĀĒśĖ ņ▓┤Ļ│ä ļČłĒÖĢņŗż ĒĢĀ ņłś ņ׳ļŗż. 2. Vector optimization 3. Optimal? No! Pareto optimal ! 4. ņ¢┤ļ¢╗Ļ▓ī? Scalarization ! 5. ņÖ£? PropositionņŚÉ ņØśĒĢ┤ !
- 15. Application ŌĆó Regularized least squares ŌĆó Smoothing regularization ŌĆó Reconstruction, smoothing and de-noising
- 16. Application ŌĆó Regularized least squares ŌĆó Smoothing regularization ŌĆó Reconstruction, smoothing and de-noising
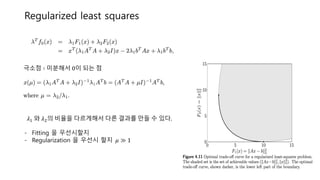
- 17. Regularized least squares A : data set, b : label Ļ░Ć ņŻ╝ņ¢┤ņ¦ĆĻ│Ā ņäĀĒśĢĒÜīĻĘĆļź╝ Ē¢łņØäļĢī, ņĀüļŗ╣ĒĢ£ ņĀüļŗ╣ĒĢ£ parameter Øæź ļź╝ ņ░ŠļŖö ļ¼ĖņĀ£ ØÉ┤Øæ¢ØæÜ ŌłČ ØæōØæ¢ØæøØææ Øæź ØæĪŌäÄØæÄØæĪ ØæöØæ¢ØæŻØæÆØæĀ ØæÄ ØæöØæ£Øæ£Øææ ØæōØæ¢ØæĪ ØæÄØæøØææ ØæĪŌäÄØæÄØæĪ Øæ¢ØæĀ ØæøØæ£ØæĪ ØæĪØæ£Øæ£ ØæÖØæÄØæ¤ØæöØæÆ ņØ┤ ļ¼ĖņĀ£ņØś Pareto optimalņØä ņ░ŠļŖö ļ▓Ģ?? Scalarization !!
- 18. Recall : Pareto optimal ņØä ņ░ŠļŖö ļ░®ļ▓Ģ ŌĆō Scalarization ņØ┤ ļ░®ļ▓Ģņ£╝ļĪ£ ļ¬©ļōĀ pareto optimal ņØä ņ░ŠņØä ņłś ņ׳ļŖö Ļ▓āņØĆ ņĢäļŗłļŗż.
- 19. Regularized least squares ĻĘ╣ņåīņĀÉ ŌłČ ļ»ĖļČäĒĢ┤ņä£ 0ņØ┤ ļÉśļŖö ņĀÉ Ø£å[ ņÖĆ Ø£åņØś ļ╣äņ£©ņØä ļŗżļź┤Ļ▓īĒĢ┤ņä£ ļŗżļźĖ Ļ▓░Ļ│╝ļź╝ ļ¦īļōż ņłś ņ׳ļŗż. - Fitting ņØä ņÜ░ņäĀņŗ£ĒĢĀņ¦Ć - Regularization ņØä ņÜ░ņäĀņŗ£ ĒĢĀņ¦Ć Ø£ć Ōē½ 1
- 20. Application ŌĆó Regularized least squares ŌĆó Smoothing regularization ŌĆó Reconstruction, smoothing and de-noising
- 21. Smoothing regularization ŌĆó ņØ╝ļ░śņĀüņØĖ RegularizationņØś ņØæņÜ®. ŌĆó ØæÜØæ¢ØæøØæ¢ØæÜØæ¢Øæ¦ØæÆ (ØÉ┐ ØÉ┤, ØÆÖ, ØæÅ , Ōłź ØÆÖ Ōłź) ŌĆó ØÆÖ Ļ░Ć ņŗ£Ļ░äņŚÉ ļö░ļźĖ ļ│ĆņłśņØ╝ ļĢī ŌĆó (ex, Øæźd : [0, 1]ņØä nļČäĒĢĀ Ē¢łņØä ļĢī, i/n ņŗ£ņĀÉņØś ņś©ļÅä) ŌĆó | ØÆÖ | ļīĆņŗĀņŚÉ | ØÉĘØÆÖ | ļź╝ ļäŻļŖöļŗż. ŌĆó ØÉĘØæź : Øæź ņØś ļ│ĆļÅÖņä▒ņØ┤ļéś ļ¦żļüäļ¤¼ņÜ┤ ņĀĢļÅäļź╝ ņĖĪņĀĢĒĢśļŖö ĒĢ©ņłś
- 22. Smoothing regularization ŌłåØæź d = iļ▓łņ¦Ė ņŗ£ņĀÉņØś Ļ│ĪļźĀņØś ĻĘ╝ņé¼Ļ░Æ
- 23. Øø┐ = 0 Ø£ć = 0.005 Øø┐ = 0 Ø£ć = 0.05 Øø┐ = 0.3 Ø£ć = 0.05 Øø┐ Ļ░Ć ņ╗żņ¦łņłśļĪØ smoothing ĒĢ┤ņ¦ĆĻ│Ā Ø£ć Ļ░Ć ņ╗żņ¦łņłśļĪØ inputņØś Ēü¼ĻĖ░Ļ░Ć ņ×æņĢäņ¦äļŗż.
- 24. Application ŌĆó Regularized least squares ŌĆó Smoothing regularization ŌĆó Reconstruction, smoothing and de-noising
- 25. Reconstruction, smoothing and de-noising ŌĆó Øæź ŌłČ ØæĀØæ¢ØæöØæøØæÄØæÖ Øæ¤ØæÆØæØØæ¤ØæÆØæĀØæÆØæøØæĪØæÆØææ ØæÅØæ” ØæÄ ØæŻØæÆØæÉØæĪØæ£Øæ¤ Øæ¢Øæø ŌäØm ŌĆó ØÆÖ = Øæź[, Øæź, ŌĆ” , Øæźm , Øæźd = Øæźd(ØæĪ) ŌĆó Assume that ØÆÖ usually doesnŌĆÖt vary rapidly. ŌĆó e.g. audio signal or video. ŌĆó ØæźoSp = Øæź + ØæŻ, ØæŻ ŌłČ ØæøØæ£Øæ¢ØæĀØæÆ ŌĆó ņøÉļל ņŗĀĒśĖ(Øæź)ņŚÉ ļģĖņØ┤ņ”ł(ØæŻ)Ļ░Ć ņä×ņØĖ ņŗĀĒśĖ(ØæźoSp) ļź╝ ņāśĒöīļ¦ü Ē¢łņØä ļĢī, ņøÉļל ņŗĀĒśĖ(Øæź) Ļ░Ć ļ¼┤ņŚćņØĖņ¦Ć ņČöņĀĢĒĢśĻ│Ā ņŗČļŗż. ŌĆó ØæżØæÆ ØæżØæÄØæøØæĪ ØæĪØæ£ ØæÆØæĀØæĪØæ¢ØæÜØæÄØæĪØæÆ sØæź Øæ£Øæō ØæĪŌäÄØæÆ Øæ£Øæ¤Øæ¢ØæöØæ¢ØæøØæÄØæÖ ØæĀØæ¢ØæöØæøØæÄØæÖ Øæź, ØæöØæ¢ØæŻØæÆØæø ØæĪŌäÄØæÆ ØæÉØæ£Øæ¤Øæ¤ØæóØæØØæĪØæÆØææ ØæĀØæ¢ØæöØæøØæÄØæÖ ØæźoSp.
- 26. Reconstruction, smoothing and de-noising Ø£Ö ŌłČ Øæ¤ØæÆØæöØæóØæÖØæÄØæ¤Øæ¢Øæ¦ØæÄØæĪØæ¢Øæ£Øæø ØæōØæóØæøØæÉØæĪØæ¢Øæ£Øæø Øæ£Øæ¤ ØæĀØæÜØæ£Øæ£ØæĪŌäÄØæ¢ØæøØæö Øæ£ØæÅØæŚØæÆØæÉØæĪØæ¢ØæŻØæÆ Ø£Ö ØæÜØæÆØæÄØæĀØæóØæ¤ØæÆØæĀ Øæ¤Øæ£ØæóØæöŌäÄØæøØæÆØæĀØæĀ Øæ£Øæ¤ ØæÖØæÄØæÉØæś Øæ£Øæō ØæĀØæÜØæ£Øæ£ØæĪŌäÄØæøØæÆØæĀØæĀ Øæ£Øæō sØæź + convex
- 27. Reconstruction, smoothing and de-noising
- 28. Reconstruction, smoothing and de-noising
- 29. Reconstruction, smoothing and de-noising Rapid variationņØ┤ ņ׳ļŖö Ļ▓ĮņÜ░
- 30. ļüØ.