[DLİÕi»á]Temporal DifferenceVariationalAuto-Encoder
Download as PPTX, PDF15 likes6,783 views

2018/11/30 Deep Learning JP: http://deeplearning.jp/seminar-2/
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Temporal DifferenceVariational Auto-Encoder
Presenter: Masahiro Suzuki, Matsuo Lab
2018/11/30£¨°k±íááÒ»²¿ĞŞÕı£©](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-1-320.jpg)








![×´B¿Õég¥â¥Ç¥ë¤Ë¤ª¤±¤ëÌõ¼ş¸¶¤·Ö²¼¤ÎELBO
? ×´B¿Õég¥â¥Ç¥ë¤ÎÓȶȤòÌõ¼ş¸¶¤·Ö²¼¤Î·e¤Ç±í¤¹£¨×Ô¼º»Ø¢µÄ¤Ë·Ö½â£©£®
¨C ¤³¤Î¤È¤Ìõ¼ş¸¶¤·Ö²¼¤ÎELBO¤Ï£¬ĞÅÄî×´B?(??|?¡Ü?)¤ò§È뤹¤ë¤³¤È¤Ç£¬2¤Ä¤ÎDZÔÚäÊı£¨ ???1 , ??£©¤À¤±¤ò
ʹ¤Ã¤Æ±í¬F¤Ç¤¤ë£®
13
ĞÅÄî×´B ÍÆÕ¥â¥Ç¥ë
ĞÅÄî×´B
¤µ¤ê¤²¤Ê¤¯ß^È¥¤Ø¤ÎÍÆդˤʤäƤë
log ? ? =
?
log ?(? ?|?<?)
log ?(??|?<?) ¡İ ? ?(? ??1 ? ?|?¡Ü?) log
?(??, ???1 ??|?<?)
? ???1, ?? ?¡Ü?
= ? ?(? ?|?¡Ü?)?(? ??1|? ?,?¡Ü?)[log ? ?? ?? + log ?(???1|?<?) + log ?(??|???1)
? log ? ?? ?¡Ü? ? log ?(???1|??, ?¡Ü?)]
Éú³É¥â¥Ç¥ëÉú³É¥â¥Ç¥ë
? ??1
???1
? ?
??](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-13-320.jpg)
![ĞÅÄî×´B¤Î¥³©`¥É¤Î§Èë
? ĞÅÄî×´B¤Î¡¸¥³©`¥É¡¹?? = ?(???1, ??)¤ò§È뤹¤ë£®
¨C ?¤ÏÈÎÒâ¤ÎévÊı£¨RNN¤È¤«£©
¨C ¤¹¤ë¤ÈĞÅÄî×´B¤Ï? ?? ?¡Ü? = ?(??|??)¤È±í¤»¤ë£¨ÈëÁ¦¤¬?¤Ë¤Ê¤ë£©£®
¨C ¤Ş¤¿£¬ÍÆÕ·Ö²¼¤Ï¥³©`¥É¤òʹ¤Ã¤Æ? ???1 ??, ?¡Ü? = ?(???1|??, ???1, ??)¤È
¤Ê¤ë£®
? ÒÔÉϤè¤ê£¬Ä¿µÄévÊı£¨ELBO£©¤Ï´Î¤Î¤è¤¦¤Ë¤Ê¤ë£®
14
ĞÅÄî×´B ÍÆÕ¥â¥Ç¥ë
ĞÅÄî×´B
? log ? ? ?? ?? ? log ?(???1|??, ???1, ??)]
Éú³É¥â¥Ç¥ëÉú³É¥â¥Ç¥ë
? = ? ? ?(? ?|? ?)?(? ??1|? ?,? ??1,? ?)[log ? ?? ?? + log ? ?(???1|???1) + log ?(??|???1)
???1
???1
??
??
???1 ??
???1
???1
??
??](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-14-320.jpg)

![TD-VAE
? Ç°¥Ú©`¥¸¤Î×hÕ¤«¤é£¬rég¤Ë¤Ä¤¤¤Æ³éÏ󻯤Ǥ¤ë¤è¤¦¤Ë¥â¥Ç¥ë¤ò¤¹¤ë£®
¨C ?¤«¤é? + 1¤ÎßwÒƤò¥â¥Ç¥ë»¯¤¹¤ë¤Î¤Ç¤Ï¤Ê¤¯£¬ÈÎÒâ¤Î¥¹¥Æ¥Ã¥× ?1 £¬?2 ég¤Î×´B¤òjumpy¤ËÍÆÕ¤¹¤ë¥â¥Ç¥ë¤ò¿¼¤¨¤ë£®
¨C ELBO¤Ï´Î¤Î¤è¤¦¤Ëä¤ï¤ë£¨rég¥¹¥Æ¥Ã¥×¤¬ä¤ï¤Ã¤¿¤À¤±£©
¨C ѧÁ¤¹¤ë¤È¤¤Ë¤Ï?2 ? ?1¤È¤·¤Æ[1, ?]¤ÎÈÎÒâ¤Î¹ ì¤ò¥µ¥ó¥×¥ê¥ó¥°¤·¤ÆѧÁ¤¹¤ë£®
? ?(??2
|??1
)¤È?(??1
|??2
, ??1
, ??2
)¤Ï¤É¤¦ÔOÓ¤¹¤ë¤Î£¿£¿£¿£¿
¨C ¤³¤ì¤é¤Î·Ö²¼¤ÏÈÎÒâ¤Îrég·ù¤Çïw¤Ù¤ë¤é¤·¤¤£¨?2 ? ?1 = ??¤È¤·¤Æ?(?2|?1, ??)¤È¤¤¤Ã¤¿¸Ğ¤¸£©
¨C arXiv°æ¤ò¤ß¤ë¤È£¬
¤È¤¤¤¦¸Ğ¤¸¤Ç¥Ñ¥é¥á©`¥¿»¯¤·¤Æ¤¤¤ë£®
16
? ?1,?2
= ? ? ?(? ?2|? ?2)?(? ?1|? ?2,? ?1,? ?2)[log ? ??2
??2
+ log ? ?(??1
|??1
) + log ?(??2
|??1
)
? log ? ? ??2
??2
? log ?(??1
|??2
, ??1
, ??2
)]](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-16-320.jpg)
![¥İ¥¤¥ó¥È
? ÖØÒª¤Ê¤Î¤Ï£¬µÚ2í¤ÈµÚ5í
¨C ѧÁ¤¹¤ë¤È¤¤Ë¤Ï£¨ÏȤۤɤÎí¤Ç¤Ï£©KL¥À¥¤¥Ğ©`¥¸¥§¥ó¥¹¤Ë¤Ê¤Ã¤Æ¤¤¤ë£®
¨C ¤³¤ì¤Ï¤Ä¤Ş¤ê£¬¬FÔÚ¤ÎÍÆÕ¤òδÀ´¤«¤é¤ÎÍÆդȽü¤Å¤±¤Æ¤¤¤ë¤È¤¤¤¦¤³¤È
¨C ?1¤Îrµã¤ÇÀûÓÿÉÄܤÊÇéó¤À¤±¤òʹ¤Ã¤Æ£¬¤É¤ì¤À¤±Î´À´¤«¤é¤ÎÍÆÕ¤Èͬ¤¸¤¯¤é¤¤¤ÎÍÆÕ¤¬¤Ç¤¤¿¤«£¿¤òÔuı¤·¤Æ
¤¤¤ë
-> CVAE¤äGQN¤Ê¤É¤È¹²Í¨¤¹¤ë¿¼¤¨·½
¨C ¡°TD¡±-VAE¤È¤¤¤¦ÃûÇ°¤Ï£¬¤³¤Î¤¢¤¿¤ê¤ÈTDÕ`²î¤È¤ÎévßBĞÔ¤«¤é£® 18
? ??1
???1
? ?
??
???1 ??
? ?1,?2
= ? ? ?(? ?2|? ?2)?(? ?1|? ?2,? ?1,? ?2)[log ? ? ?2
??2
+ log ? ?(??1
|??1
) + log ?(??2
|??1
)
? log ? ? ??2
??2
? log ?(??1
|??2
, ??1
, ??2
)]
? ??[?(??1
|??2
, ??1
, ??2
)| ?(??1
??1
)]](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-18-320.jpg)
![Ña×㣺VAE¡ÁRNN Zoo
? VAE¡ÁRNN¤ÎÑо¿Ò»ÓE£¨Éú³É¥â¥Ç¥ë£¨É϶Σ©¤Ç·ÖVSMCϵ¤Ïİd¤»¤Æ¤¤¤Ê¤¤£©
¡ù·Ö²¼£¨Ê¸Ó¡£©¤Ï¸Å¤Ír¿Ì?¤Ëév¤¹¤ë¤â¤Î¤Î¤ßÃè»
???1
???1
??
??
Deep Markov Model [Krishnan+ 17]
£¨Deep Kalman Filter [Krishnan+ 15]£©
¡ùÍÆÕ·Ö²¼¤ÏÕÎÄÄڤǤ¤¤¯¤Ä¤«Ìá°¸¤µ¤ì¤Æ¤¤¤ë
? ??1 ? ?
???1
???1
??
??
SRNN [Fraccaro+ 16]
? ??1 ? ?
? ??1 ? ?
???1
???1
??
??
TD-VAE [Gregor+ 18]
???1 ??
???1
???1
??
??
VRNN [Chung+ 16]
? ??1 ? ?
???1
???1
??
??
STORN [Bayer+ 15]
? ??1 ? ?
? ??1 ? ?
???1
???1
??
??
Z-forcing [Goyal+ 17]
? ??1 ? ?
???1 ??
? ?????(??) = ?(??|?1:??1, ?1:??1)
? ?????(??) = ?(??) ? ?????(??) = ?(??|???1, ?)
???1
???1
??
??
×´B¿Õég¥â¥Ç¥ë
¡ùaction¤ÏÊ¡ÂÔ
? ?, ? = ¦° ? ? ?? ?? ? ?? ???1
???1
??
??
???1
? ?, ? = ¦° ? ? ?? ?1:??1, ?1:? ? ?????(??)
???1
??
??
???1
? ?, ?
= ¦° ? ? ??+1 ?1:?, ?1:? ? ?????(??)
19](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-19-320.jpg)

![gòY1
? ²¿·ÖÓQy¤ÊMiniPacman [Racanie?re et al., 2017]
¨C ¥¨©`¥¸¥§¥ó¥È¤ÏÓÄë¤ò±Ü¤±¤Ê¤¬¤éÃÔ·ÄڤΤ¹¤Ù¤Æ¤ÎʳÎï¤òʳ¤Ù¤è¤¦¤È¤¹¤ë£®
¨C ÓQy¤Ç¤¤ë¤Î¤Ï5¡Á5¤Î¥¦¥£¥ó¥É¥¦£¨ÓÒ£©
-> ¸ß¤¤¥¹¥³¥¢¤òß_³É¤¹¤ë¤¿¤á¤Ë¤Ï£¨ß^È¥¤Î½UòY¤äh¾³¤Î²»´_gĞÔ¤ò¿¼]¤·¤Ä¤Ä£©ĞÅÄî×´B¤òĞγɤ¹¤ë±ØÒª¤¬¤¢¤ë£®
? ¤³¤ÎgòY¤Ç¤Ï£¬non-jumpy¤ÊTD-VAE¤¬ßmÇФËѧÁ¤Ç¤¤ë¤«´_ÕJ¤¹¤ë£®
¨C ËʵĤÊELBO¤ÎϤǤÎ2¤Ä¤Î×´B¿Õég¥â¥Ç¥ë¤È±Èİ^
-> TD-VAE¤ÎELBO¤ÎÓĞ¿ĞÔ¤òÔuı
21
Under review as aconference paper at ICLR 2019
ELBO ? logp(x) (est.)
Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007
Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010
TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006
Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is
navigating the mazetrying to eat all the food (blue) whilebeing chased by aghost (red). Top right:
A sequence of observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right:
ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter.
Log probability isestimated using importance sampling with theencoder as proposal.
Under review asaconference paper at ICLR 2019
ELBO ? logp(x) (est.)
Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007
Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010
TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006
Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is
navigating themazetrying to eat all thefood (blue) whilebeing chased by aghost (red). Top right:
A sequenceof observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right:
ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter.
Log probability isestimated using importance sampling with theencoder asproposal.](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-21-320.jpg)

![gòY2
? Moving MNIST
¨C ¸÷¥¹¥Æ¥Ã¥×¤ÇÒÆÓ¤¹¤ëMNIST
¨C [1,4]¤Î¹ ì¤Ç¥¹¥Æ¥Ã¥×¤òïw¤ÓÔ½¤¨¤ÆѧÁ¤·£¬Éú³É¤Ç¤¤ë¤«¤ògòY
? gòY½Y¹û£º
¨C ¥¹¥Æ¥Ã¥×Êı¤òïw¤Ğ¤·¤Æ¤âÉú³É¤Ç¤¤¿£®
¨C £¨Ã÷ʾµÄ¤Ëø¤¤¤Æ¤Ê¤¤¤¬¿Ö¤é¤¯£©Ò»·¬×ó¤¬Ôª»Ïñ¤Ç¸÷ÁФ¬ïw¤Ğ¤·¤¿¥¹¥Æ¥Ã¥×Êı[1,4]¤Ëꤷ¤Æ¤¤¤ë
23
Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is
navigating themazetrying to eat all the food (blue) whilebeing chased by aghost (red). Top right:
A sequence of observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right:
ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter.
Log probability isestimated using importance sampling with theencoder asproposal.
Figure 3: Moving MNIST. Left: Rowsare example input sequences. Right: Jumpy rollouts from
themodel. Weseethat themodel isable to roll forward by skipping frames, keeping thecorrect digit
and thedirection of motion.
5.2 MOVING MNIST
In thisexperiment, weshow that themodel isable to learn thestateand roll forward in jumps. We
consider sequencesof length 20 of images of MNIST digits. For each sequence, arandom digit from
thedataset ischosen, aswell asthedirection of movement (left or right). At each timestep, thedigit
movesby one pixel in the chosen direction, asshown in Figure 3. Wetrain the model with t1 and
t2 separated by arandom amount t2 ? t1 from theinterval [1, 4]. Wewould liketo seewhether the
model at agiven timecan roll out asimulated experience in timesteps t1 = t + ¦Ä1, t2 = t1 + ¦Ä2, . . .
with ¦Ä1, ¦Ä2, . . . > 1, without considering theinputsin between thesetimepoints. Notethat it isnot
suf?cient to predict thefuture inputs xt 1 , . . . asthey do not contain information about whether the
digit movesleft or right. Weneed to sample astate that contains this information.
Weroll out asequence from themodel asfollows: (a) bt iscomputed by the aggregation recurrent
network from observations up to time t; (b) a state zt is sampled from pB (zt | bt ); (c) a sequence
0 0
ELBO ? logp(x) (est.)
Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007
Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010
TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006
re 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is
gating themazetrying to eat all the food (blue) whilebeing chased by aghost (red). Top right:
quence of observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right:
O and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter.
probability isestimated using importance sampling with theencoder asproposal.
re 3: Moving MNIST. Left: Rowsare example input sequences. Right: Jumpy rollouts from
model. Wesee that themodel isable to roll forward by skipping frames, keeping thecorrect digit
the direction of motion.](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-23-320.jpg)
![gòY3
? ¥Î¥¤¥º¤Î¶à¤¤¸ßÕ{²¨°kÕñÆ÷¤«¤éµÃ¤é¤ì¤¿1´ÎÔª¥·©`¥±¥ó¥¹
¨C ¸÷ÓQy¤ÇÇé󤬤ۤȤó¤É¤Ê¤¯¤Æ¤â£¨¥Î¥¤¥º¤¬Èë¤Ã¤Æ¤¤¤Æ¤â£©¥â¥Ç¥ë¤¬×´B¤òºB¤Ç¤¤ë¤³¤È¤òʾ¤¹£®
¨C RNN¤Ë¤ÏLSTM¤òÓ䤤ƣ¬ëAÓTD-VAE¤òʹ¤Ã¤ÆѧÁ£®
? b¤¬ëAÓ»¯¤·¤Æ¤¤¤ë£¨ÕhÃ÷¤ÏÊ¡ÂÔ£©
¨C ¥¹¥Æ¥Ã¥×·ù¤Ï´_ÂÊ0.8¤Ç[1,10]¤Îég£¬´_ÂÊ0.2¤Ç[1,120]¤Îég¤È¤·¤ÆѧÁ
? gòY½Y¹û£º
¨C 20¥¹¥Æ¥Ã¥×¼°¤Ó100¥¹¥Æ¥Ã¥×ïw¤Ğ¤·¤¿½Y¹û
¨C ¥Î¥¤¥º¤¬¶à¤¤ÓQy¥Ç©`¥¿¤Ç¤âÉú³É¤Ç¤¤Æ¤¤¤ë£®
24
Under review asaconference paper at ICLR 2019
Figure4: Skip-state prediction for 1D signal. Theinput isgenerated by anoisy harmonic oscillator.
Rollouts consist of (a) ajumpy state transition with either dt = 20 or dt = 100, followed by 20 state
transitions with dt = 1. The model is able to create a state and predict it into the future, correctly
predicting frequency and magnitude of thesignal.
predict asmuch aspossible about thestate, which consists of frequency, magnitude and position, and
it isonly theposition that cannot beaccurately predicted.](https://image.slidesharecdn.com/20181130new-190205051636/85/DL-Temporal-DifferenceVariationalAuto-Encoder-24-320.jpg)





![[DLİÕi»á]Dream to Control: Learning Behaviors by Latent Imagination](https://cdn.slidesharecdn.com/ss_thumbnails/20200313furutav2-200313025657-thumbnail.jpg?width=560&fit=bounds)
![[DLİÕi»á]¡°SimPLe¡±,¡°Improved Dynamics Model¡±,¡°PlaNet¡± ½üÄê¤ÎVAE¥Ù©`¥¹ÏµÁĞ¥â¥Ç¥ë¤ÎßMÕ¹¤È¤½¤Î¥â¥Ç¥ë¥Ù©`¥¹...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=560&fit=bounds)



![[DLİÕi»á]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=560&fit=bounds)
![[DLİÕi»á]Deep Learning µÚ15Õ ±í¬FѧÁ](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=560&fit=bounds)

![[DLİÕi»á]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=560&fit=bounds)
![[DLİÕi»á]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=560&fit=bounds)





![[DLİÕi»á]¥â¥Ç¥ë¥Ù©`¥¹»¯Ñ§Á¤ÈEnergy Based Model](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-191129002008-thumbnail.jpg?width=560&fit=bounds)


![[DLİÕi»á]ÉîÓ»¯Ñ§Á¤Ï¤Ê¤¼ëy¤·¤¤¤Î¤«£¿Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=560&fit=bounds)


![[DLİÕi»á]Control as Inference¤È°kÕ¹](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=560&fit=bounds)


![[DLİÕi»á]Meta Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/metarl-190201005548-thumbnail.jpg?width=560&fit=bounds)




More Related Content
What's hot (20)
Similar to [DLİÕi»á]Temporal DifferenceVariationalAuto-Encoder (20)




![[DLİÕi»á]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...](https://cdn.slidesharecdn.com/ss_thumbnails/20190816-190816001737-thumbnail.jpg?width=560&fit=bounds)













More from Deep Learning JP (20)




















[DLİÕi»á]Temporal DifferenceVariationalAuto-Encoder
- 1. 1 DEEP LEARNING JP [DL Papers] http://deeplearning.jp/ Temporal DifferenceVariational Auto-Encoder Presenter: Masahiro Suzuki, Matsuo Lab 2018/11/30£¨°k±íááÒ»²¿ĞŞÕı£©
- 2. İÕiÄÚÈݤˤĤ¤¤Æ ? Temporal Difference Variational Auto-Encoder ¨C Karol Gregor, Frederic Besse ? Gregor¤µ¤ó¤ÏDRAW¤òÌá°¸¤·¤¿ÈË ? ICLR¤Ëñåh£¨¥ª©`¥é¥ë£¬¥¹¥³¥¢¤¬8,9,7£© ? TD-VAE¤òÌá°¸¤·¤¿ÕÎÄ ¨C ϵÁĞÇéó¤òQ¤¦ÉîÓÉú³É¥â¥Ç¥ë ¨C ¤¢¤ëÈÎÒ⥹¥Æ¥Ã¥×¤Ş¤Ç¡¸ïw¤ÓÔ½¤¨¤Æ¡¹ÍÆÕ¤¬¤Ç¤¤ëµã¤¬¤¹¤´¤¤ -> øÓÃAI¤Î´ó¤¤ÊÕnî}¤ÎÒ»¤Ä¤Ç¤¢¤ë¡¸rϵÁФγéÏ󻯡¹¤ËÌô¤ó¤ÀÑо¿ ? ±¾ÕÎĤˤĤ¤¤Æ¤ÎË½Ò ¨C »¯Ñ§Á£¨ÌؤËPOMDP£©¤È¤ÎévS¤òÒâ×R¤·¤Æ¤ª¤ê£¬ÊÀ½ç¥â¥Ç¥ëÑо¿¤Î1¤Ä¤ÈλÖ䍱¤é¤ì¤ë£® ? ¤É¤¦¤Ç¤â¤¤¤¤¤±¤É×î½ü¡¸ÊÀ½ç¥â¥Ç¥ë¡¹¤¬¥Ğ¥º¥ï©`¥É»¯¤·¤Ê¤¤¤«ÙÊÖ¤ËĞÄÅ䤷¤Æ¤¤¤ë£® ¨C ·Ç³£¤ËËØÖ±¤Ê¥â¥Ç¥ë¤À¤¬£¬¤Ñ¤Ã¤ÈÒ·Ö¤«¤ê¤Å¤é¤¤£® ? ICLR°æ¤Ç¤À¤¤¤Ö¸ÄÉƤµ¤ì¤Æ¤¤¤ë£® ? Öx×ï ¨C évßBÑо¿¤Ë¤Ä¤¤¤Æ¤¢¤Ş¤êÕ{¤Ù¤é¤ì¤Ş¤»¤ó¤Ç¤·¤¿£® ¨C ÍêÈ«°æ¤Ï¤Ş¤¿e¤ÎÃã»á£¨»¯Ñ§Á¥¢©`¥¥Æ¥¯¥Á¥ã¤È¤«£©¤ÇÔ¤¹¤«¤â¤·¤ì¤Ê¤¤£® 2
- 4. ±³¾° 4
- 5. Ñо¿±³¾° ? ϵÁФÎÉú³É¥â¥Ç¥ë¤Ï¡©¤ÊîIÓò¤ÇêÓ䵤ì¤Æ¤¤¤ë£® ¨C ÒôÉùºÏ³É£¨WaveNet£¬PixelRNN£© ¨C ·ÔU£¨NMT£© ¨C »Ïñ¥¥ã¥×¥·¥ç¥Ë¥ó¥° ? ±¾Ñо¿¤Ç¤Ï²¿·ÖÓQyh¾³¤Î»¯Ñ§Á¤Îî}¤ò¿¼¤¨¤ë ¨C ¥¨©`¥¸¥§¥ó¥È¤Ï¤³¤ì¤Ş¤Ç §¼¯¤·¤¿Çé󤫤éÓË㤷¤¿£¬ÊÀ½ç¤Î²»´_gĞÔ¤ò±í¬F¤¹¤ë±ØÒª¤¬¤¢¤ë£® ¨C ¥â¥Ç¥ë¥Ù©`¥¹¤Ç¿¼¤¨¤ë¤È£¬¥¨©`¥¸¥§¥ó¥È¤Ïß^È¥¤ÈÒ»ØĞԤΤ¢¤ëßh¤¤Î´À´¤òÏëÏñ¤·¤Ê¤±¤ì¤Ğ¤Ê¤é¤Ê¤¤£® ? ¥¹¥Æ¥Ã¥×¤´¤È¤Ë¥×¥é¥ó¥Ë¥ó¥°¤¹¤ë¤Î¤ÏÕJ֪ѧµÄ¤Ë¤âÓËãÁ¿µÄ¤Ë¤â¬FgµÄ¤Ç¤Ï¤Ê¤¤£® -> ¤³¤ì¤é¤òһݤ˽âQ¤Ç¤¤ë¤è¤¦¤ÊÊÀ½ç¥â¥Ç¥ë¤ò¿¼¤¨¤¿¤¤ 5
- 6. ²¿·ÖÓQyh¾³¤Ë¤ª¤±¤ëÊÀ½ç¥â¥Ç¥ë¤ËÇó¤á¤é¤ì¤ë¤³¤È ? ÖøÕߤé¤Ï´Î¤Î3¤Ä¤ÎĞÔÙ|¤òͬr¤Ë³Ö¤Ä¤³¤È¤¬±ØÒª¤Ç¤¢¤ë¤È¤·¤Æ¤¤¤ë£® 1. ¥Ç©`¥¿¤«¤é³éÏóµÄ¤Ê×´B±í¬F¤òѧÁ¤·¤Æ£¬×´B±í¬F¤òÀûÓä·¤¿Óèy¤òĞФ¨¤ë±ØÒª¤¬¤¢¤ë£® 2. ¤¢¤ërég¤Ş¤Ç¤ÎÈ«¤Æ¤ÎÓQy¥Ç©`¥¿¤¬Ó뤨¤é¤ì¤¿Ï¤ǤΣ¬×´B¤Î¥Õ¥£¥ë¥¿¥ê¥ó¥°·Ö²¼¤ÎQ¶¨ÕµÄ¤«¤Ä¥³©`¥É»¯¤µ¤ì ¤¿±í¬F£¨ĞÅÄî×´B£©¤òѧÁ¤·¤Ê¤±¤ì¤Ğ¤Ê¤é¤Ê¤¤£® ? ¤³¤ÎĞÅÄî×´B¤Ë¤Ï¥¨©`¥¸¥§¥ó¥È¤¬ÊÀ½ç¤Ë¤Ä¤¤¤ÆÖª¤Ã¤Æ¤¤¤ëÈ«¤Æ¤ÎÇé󤬺¬¤Ş¤ì¤Æ¤¤¤ë£® ? ¤Ä¤Ş¤ê£¬×îßm»¯¤¹¤ë¤¿¤á¤ÎĞĞÓ¤Ëév¤¹¤ëÇéó¤âº¬¤Ş¤ì¤Æ¤¤¤ë£® 3. rég·½Ïò¤Ë¤Ä¤¤¤Æ³éÏ󻯤·¤Æ¤¤¤ë±ØÒª¤¬¤¢¤ë£® ? ¥¹¥Æ¥Ã¥×¤òïw¤ÓÔ½¤¨¤Æ£¨jumpy£©Î´À´¤òÓèy¤¹¤ë¤³¤È¤¬¤Ç¤¤ë£® ? régµÄ¤Ëëx¤ì¤¿¥Ç©`¥¿¤«¤é£¨¤½¤Îég¤Î¥¹¥Æ¥Ã¥×¤òÕ`²îÄ滲¥¤»¤º¤Ë£©Ñ§Á¤Ç¤¤ë±ØÒª¤¬¤¢¤ë£® ? ¼È´æÑо¿¤Ç¤Ï¤³¤ì¤é¤ò¤¹¤Ù¤Æº¤¿¤¹Ñо¿¤Ï´æÔÚ¤·¤Ê¤¤£® -> Temporal Difference Variational Auto-Encoder £¨TD-VAE£©¤òÌá°¸ 6
- 8. ϵÁĞÇéó¤ÎQ¤¤·½£º×Ô¼º»Ø¢¥â¥Ç¥ë ϵÁХǩ`¥¿(?1, ¡ , ? ?)¤ò¥â¥Ç¥ë»¯¤¹¤ë·½·¨¤È¤·¤Æ¤Ï£¬×Ô¼º»Ø¢¥â¥Ç¥ë¤È×´B¿Õég¥â¥Ç ¥ë¤¬Öª¤é¤ì¤Æ¤¤¤ë£® ? ×Ô¼º»Ø¢¥â¥Ç¥ë ¨C ÓȶȤòÌõ¼ş¸¶¤·Ö²¼¤Î·e¤Ç±í¤¹£® log ?(?1, ¡ , ? ?) = ? log ?(??|?1, ¡ , ???1) ¨C RNN¤ò¤Ä¤«¤Ã¤Æ£¬¤³¤ì¤Ş¤Ç¤Î¥Ç©`¥¿¤òÄÚ²¿×´B?¤Ë¤Ş¤È¤á¤ë¤³¤È¤Çº g¤ËÓËã¤Ç¤¤ë£® ? Ç·µã£º ¨C Ôª¤ÎÓQy¿Õég¤Ç¤·¤«Ñ§Á¤·¤Ê¤¤£¨R¿s¤·¤¿±í¬F¤òѧÁ¤·¤Ê¤¤£©£® ¨C ÓË㥳¥¹¥È¤¬¤«¤«¤ë£¨¸÷¥¹¥Æ¥Ã¥×¤Ç¥Ç¥³©`¥É¤È¥¨¥ó¥³©`¥É¤òÀR¤ê·µ¤¹±ØÒªĞÔ£©£® ¨C ²»°²¶¨£¨g¥Ç©`¥¿¤òÈë¤ì¤ëRNN¤Ë¤Ï£¬¥Æ¥¹¥Èr¤ËÇ°¤ÎÓèy¤¬Èë¤Ã¤Æ¤¯¤ë£©£® 8 ? ? = ?(? ??1, ??)
- 9. ϵÁĞÇéó¤ÎQ¤¤·½£º×´B¿Õég¥â¥Ç¥ë ? ×´B¿Õég¥â¥Ç¥ë ¨C ×´BϵÁĞ? = (?1, ¡ , ? ?)¤ª¤è¤ÓÓQyϵÁĞ? = (?1, ¡ , ? ?)¤¬Ó뤨¤é¤ì¤¿¤È¤¤Ë£¬ ¤È¤¹¤ë¤È£¬ELBO£¨ä·ÖϽ磩¤Ï´Î¤Î¤è¤¦¤Ë¤Ê¤ë£® ? ÌØÕ£º ¨C ÈëÁ¦?¤ò´_ÂʵĤÊ×´B£¨Ç±ÔÚäÊı£©?¤ËR¿s¤¹¤ë£® ? ¤Á¤Ê¤ß¤Ë£¬¤³¤ÎŞx¤ê¤ÎÑо¿¤Ç¤Ïx¤Èz¤òÄæ¤Ë¤·¤¿¤ê¤¹¤ë¤é¤·¤¤£® ¨C ×´B¿ÕégÄڤǤÎßwÒƤ¬¿ÉÄÜ£¨×Ô¼º»Ø¢¥â¥Ç¥ë¤Î¤è¤¦¤Ë°»Ø¥¨¥ó¥³©`¥É¤È¥Ç¥³©`¥É¤ò¤¹¤ë±ØÒª¤¬¤Ê¤¤£© 9 ͬr·Ö²¼£º?(?, ?) = ? ? ?? ???1 ?(??|??) ÍÆÕ·Ö²¼£º?(?|?) = ? ? ?? ???1, ? ?(?) £¨×Ô¼º»Ø¢£© log ?(?) ¡İ ? ?~? ?|? ? log ? ?? ?? + log ? ?? ???1 ? log ? ?? ???1, ? ?(?) ???1 ???1 ?? ??
- 10. TD-VAE 10
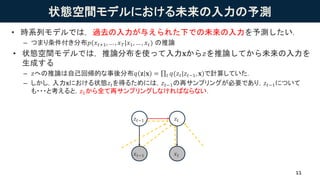
- 11. ×´B¿Õég¥â¥Ç¥ë¤Ë¤ª¤±¤ëδÀ´¤ÎÈëÁ¦¤ÎÓèy ? rϵÁĞ¥â¥Ç¥ë¤Ç¤Ï£¬ß^È¥¤ÎÈëÁ¦¤¬Ó뤨¤é¤ì¤¿Ï¤ǤÎδÀ´¤ÎÈëÁ¦¤òÓèy¤·¤¿¤¤£® ¨C ¤Ä¤Ş¤êÌõ¼ş¸¶¤·Ö²¼?(??+1, ¡ , ? ?|?1, ¡ , ??) ¤ÎÍÆÕ ? ×´B¿Õég¥â¥Ç¥ë¤Ç¤Ï£¬ÍÆÕ·Ö²¼¤òʹ¤Ã¤ÆÈëÁ¦?¤«¤é?¤òÍÆÕ¤·¤Æ¤«¤éδÀ´¤ÎÈëÁ¦¤ò Éú³É¤¹¤ë ¨C ?¤Ø¤ÎÍÆÕ¤Ï×Ô¼º»Ø¢µÄ¤ÊÊÂáá·Ö²¼? ? ? = ? ?(??|???1, ?)¤ÇÓË㤷¤Æ¤¤¤¿£® ¨C ¤·¤«¤·£¬ÈëÁ¦?¤Ë¤ª¤±¤ë×´B??¤òµÃ¤ë¤¿¤á¤Ë¤Ï£¬???1¤ÎÔÙ¥µ¥ó¥×¥ê¥ó¥°¤¬±ØÒª¤Ç¤¢¤ê£¬???1¤Ë¤Ä¤¤¤Æ ¤â???¤È¿¼¤¨¤ë¤È£¬?1¤«¤éÈ«¤ÆÔÙ¥µ¥ó¥×¥ê¥ó¥°¤·¤Ê¤±¤ì¤Ğ¤Ê¤é¤Ê¤¤£® 11 ? ??1 ???1 ? ? ??
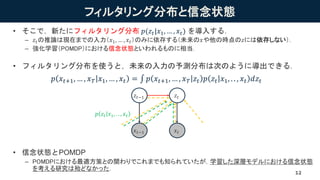
- 12. ¥Õ¥£¥ë¥¿¥ê¥ó¥°·Ö²¼¤ÈĞÅÄî×´B ? ¤½¤³¤Ç£¬Ğ¤¿¤Ë¥Õ¥£¥ë¥¿¥ê¥ó¥°·Ö²¼ ?(??|?1, ¡ , ??) ¤ò§È뤹¤ë£® ¨C ??¤ÎÍÆդϬFÔڤޤǤÎÈëÁ¦£¨?1, ¡ , ??£©¤Î¤ß¤ËÒÀ´æ¤¹¤ë£¨Î´À´¤Î?¤äËû¤Îrµã¤Î?¤Ë¤ÏÒÀ´æ¤·¤Ê¤¤£©£® ¨C »¯Ñ§Á£¨POMDP£©¤Ë¤ª¤±¤ëĞÅÄî×´B¤È¤¤¤ï¤ì¤ë¤â¤Î¤ËÏ൱£® ? ¥Õ¥£¥ë¥¿¥ê¥ó¥°·Ö²¼¤òʹ¤¦¤È£¬Î´À´¤ÎÈëÁ¦¤ÎÓèy·Ö²¼¤Ï´Î¤Î¤è¤¦¤Ë§³ö¤Ç¤¤ë£® ? ĞÅÄî×´B¤ÈPOMDP ¨C POMDP¤Ë¤ª¤±¤ë×îßm·½²ß¤È¤Îév¤ï¤ê¤Ç¤³¤ì¤Ş¤Ç¤âÖª¤é¤ì¤Æ¤¤¤¿¤¬£¬Ñ§Á¤·¤¿ÉîÓ¥â¥Ç¥ë¤Ë¤ª¤±¤ëĞÅÄî×´B ¤ò¿¼¤¨¤ëÑо¿¤Ï´ù¤É¤Ê¤«¤Ã¤¿£® 12 ? ??1 ???1 ? ? ?? ? ??+1, ¡ , ? ? ?1, ¡ , ?? = ? ??+1, ¡ , ? ? ?? ? ?? ?1, . . , ?? ??? ? ?? ?1, . . , ? ?
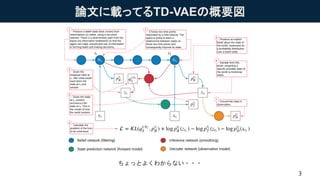
- 13. ×´B¿Õég¥â¥Ç¥ë¤Ë¤ª¤±¤ëÌõ¼ş¸¶¤·Ö²¼¤ÎELBO ? ×´B¿Õég¥â¥Ç¥ë¤ÎÓȶȤòÌõ¼ş¸¶¤·Ö²¼¤Î·e¤Ç±í¤¹£¨×Ô¼º»Ø¢µÄ¤Ë·Ö½â£©£® ¨C ¤³¤Î¤È¤Ìõ¼ş¸¶¤·Ö²¼¤ÎELBO¤Ï£¬ĞÅÄî×´B?(??|?¡Ü?)¤ò§È뤹¤ë¤³¤È¤Ç£¬2¤Ä¤ÎDZÔÚäÊı£¨ ???1 , ??£©¤À¤±¤ò ʹ¤Ã¤Æ±í¬F¤Ç¤¤ë£® 13 ĞÅÄî×´B ÍÆÕ¥â¥Ç¥ë ĞÅÄî×´B ¤µ¤ê¤²¤Ê¤¯ß^È¥¤Ø¤ÎÍÆդˤʤäƤë log ? ? = ? log ?(? ?|?<?) log ?(??|?<?) ¡İ ? ?(? ??1 ? ?|?¡Ü?) log ?(??, ???1 ??|?<?) ? ???1, ?? ?¡Ü? = ? ?(? ?|?¡Ü?)?(? ??1|? ?,?¡Ü?)[log ? ?? ?? + log ?(???1|?<?) + log ?(??|???1) ? log ? ?? ?¡Ü? ? log ?(???1|??, ?¡Ü?)] Éú³É¥â¥Ç¥ëÉú³É¥â¥Ç¥ë ? ??1 ???1 ? ? ??
- 14. ĞÅÄî×´B¤Î¥³©`¥É¤Î§Èë ? ĞÅÄî×´B¤Î¡¸¥³©`¥É¡¹?? = ?(???1, ??)¤ò§È뤹¤ë£® ¨C ?¤ÏÈÎÒâ¤ÎévÊı£¨RNN¤È¤«£© ¨C ¤¹¤ë¤ÈĞÅÄî×´B¤Ï? ?? ?¡Ü? = ?(??|??)¤È±í¤»¤ë£¨ÈëÁ¦¤¬?¤Ë¤Ê¤ë£©£® ¨C ¤Ş¤¿£¬ÍÆÕ·Ö²¼¤Ï¥³©`¥É¤òʹ¤Ã¤Æ? ???1 ??, ?¡Ü? = ?(???1|??, ???1, ??)¤È ¤Ê¤ë£® ? ÒÔÉϤè¤ê£¬Ä¿µÄévÊı£¨ELBO£©¤Ï´Î¤Î¤è¤¦¤Ë¤Ê¤ë£® 14 ĞÅÄî×´B ÍÆÕ¥â¥Ç¥ë ĞÅÄî×´B ? log ? ? ?? ?? ? log ?(???1|??, ???1, ??)] Éú³É¥â¥Ç¥ëÉú³É¥â¥Ç¥ë ? = ? ? ?(? ?|? ?)?(? ??1|? ?,? ??1,? ?)[log ? ?? ?? + log ? ?(???1|???1) + log ?(??|???1) ???1 ???1 ?? ?? ???1 ?? ???1 ???1 ?? ??
- 15. Jumpy×´B¤Î¥â¥Ç¥ê¥ó¥° ? ¤³¤³¤Ş¤Ç§³ö¤·¤¿¥â¥Ç¥ë¤Ï£¬¤¢¤ë¥¹¥Æ¥Ã¥×¤«¤é´Î¤Î¥¹¥Æ¥Ã¥×¤Ç×´B¤¬¤É¤Î¤è¤¦¤Ëä¤ï¤ë ¤«¤ò±í¤·¤¿¥â¥Ç¥ë ? ¤·¤«¤·gëH¤Î¥×¥é¥ó¥Ë¥ó¥°¤Ç¤Ï£¬¸÷¥¹¥Æ¥Ã¥×¤ÇÓQy¤òÊܤ±È¡¤Ã¤Æ g¼¤ËĞĞÓ¤¹¤ëÔU¤Ç¤Ï ¤Ê¤¤£® ¨C Àı£ºº£ÍâÂÃĞФΥץé¥ó¥Ë¥ó¥°¤Ç¤Ï£¬ÂÃĞĞ¥ª¥×¥·¥ç¥ó¤Î×hÕ£¬Ä¿µÄµØ¤Îßxk£¬¥Á¥±¥Ã¥ÈÙÈë¤Ê¤É ¨C ¤½¤ì¤¾¤ì¤Ï®¤Ê¤ë¥¿¥¤¥à¥¹¥±©`¥ë¤Ë¤Ê¤Ã¤Æ¤ª¤ê£¬Ò»Ã뤴¤È¤Ë¥×¥é¥ó¥Ë¥ó¥°¤òÁ¢¤Æ¤ëÔU¤Ç¤Ï¤Ê¤¤£® -> Ö±½Ó½«À´¤Î×´B¤òÏëÏñ¤Ç¤¤ë£¨jumpy£©¥â¥Ç¥ë¤¬±ØÒª ? ¤½¤ÎËû¤Ë¤âδÀ´¤òÖ±½Ó¥â¥Ç¥ë»¯¤¹¤ëפĤ«¤Î¥â¥Á¥Ù©`¥·¥ç¥ó¤¬¤¢¤ë£® ¨C δÀ´¤«¤é¤ÎÓ¾ĞźŤÏrég¥¹¥Æ¥Ã¥×ég¤ÎĞ¡¤µ¤Ê仯¤Ë¤·¤ÆîB½¡¤Ç¤¢¤ë¤Ù¤£® ¨C rég¤òÈÎÒâ¤ËÈ¡¤ê¤¿¤¤öºÏ£¬¥Ç©`¥¿¤ÎrégµÄ¤Ê¥µ¥Ö¥µ¥ó¥×¥ê¥ó¥°¤È¶ÀÁ¢¤Ç¤¢¤ë¤Ù¤£® ¨C JumpyÓèy¤Ï£¬rég¿ÂʵĤˤ⤤¤¤£® ? îËƤÎÑо¿¤Ï¤¢¤ë¤¬£¬×´B¤ÎѧÁ¤òĞФ鷺£¬ÍêÈ«ÓQyî}¤Î¤ß¤Ë½¹µã¤òµ±¤Æ¤Æ¤¤¤ë£® 15
- 16. TD-VAE ? Ç°¥Ú©`¥¸¤Î×hÕ¤«¤é£¬rég¤Ë¤Ä¤¤¤Æ³éÏ󻯤Ǥ¤ë¤è¤¦¤Ë¥â¥Ç¥ë¤ò¤¹¤ë£® ¨C ?¤«¤é? + 1¤ÎßwÒƤò¥â¥Ç¥ë»¯¤¹¤ë¤Î¤Ç¤Ï¤Ê¤¯£¬ÈÎÒâ¤Î¥¹¥Æ¥Ã¥× ?1 £¬?2 ég¤Î×´B¤òjumpy¤ËÍÆÕ¤¹¤ë¥â¥Ç¥ë¤ò¿¼¤¨¤ë£® ¨C ELBO¤Ï´Î¤Î¤è¤¦¤Ëä¤ï¤ë£¨rég¥¹¥Æ¥Ã¥×¤¬ä¤ï¤Ã¤¿¤À¤±£© ¨C ѧÁ¤¹¤ë¤È¤¤Ë¤Ï?2 ? ?1¤È¤·¤Æ[1, ?]¤ÎÈÎÒâ¤Î¹ ì¤ò¥µ¥ó¥×¥ê¥ó¥°¤·¤ÆѧÁ¤¹¤ë£® ? ?(??2 |??1 )¤È?(??1 |??2 , ??1 , ??2 )¤Ï¤É¤¦ÔOÓ¤¹¤ë¤Î£¿£¿£¿£¿ ¨C ¤³¤ì¤é¤Î·Ö²¼¤ÏÈÎÒâ¤Îrég·ù¤Çïw¤Ù¤ë¤é¤·¤¤£¨?2 ? ?1 = ??¤È¤·¤Æ?(?2|?1, ??)¤È¤¤¤Ã¤¿¸Ğ¤¸£© ¨C arXiv°æ¤ò¤ß¤ë¤È£¬ ¤È¤¤¤¦¸Ğ¤¸¤Ç¥Ñ¥é¥á©`¥¿»¯¤·¤Æ¤¤¤ë£® 16 ? ?1,?2 = ? ? ?(? ?2|? ?2)?(? ?1|? ?2,? ?1,? ?2)[log ? ??2 ??2 + log ? ?(??1 |??1 ) + log ?(??2 |??1 ) ? log ? ? ??2 ??2 ? log ?(??1 |??2 , ??1 , ??2 )]
- 18. ¥İ¥¤¥ó¥È ? ÖØÒª¤Ê¤Î¤Ï£¬µÚ2í¤ÈµÚ5í ¨C ѧÁ¤¹¤ë¤È¤¤Ë¤Ï£¨ÏȤۤɤÎí¤Ç¤Ï£©KL¥À¥¤¥Ğ©`¥¸¥§¥ó¥¹¤Ë¤Ê¤Ã¤Æ¤¤¤ë£® ¨C ¤³¤ì¤Ï¤Ä¤Ş¤ê£¬¬FÔÚ¤ÎÍÆÕ¤òδÀ´¤«¤é¤ÎÍÆդȽü¤Å¤±¤Æ¤¤¤ë¤È¤¤¤¦¤³¤È ¨C ?1¤Îrµã¤ÇÀûÓÿÉÄܤÊÇéó¤À¤±¤òʹ¤Ã¤Æ£¬¤É¤ì¤À¤±Î´À´¤«¤é¤ÎÍÆÕ¤Èͬ¤¸¤¯¤é¤¤¤ÎÍÆÕ¤¬¤Ç¤¤¿¤«£¿¤òÔuı¤·¤Æ ¤¤¤ë -> CVAE¤äGQN¤Ê¤É¤È¹²Í¨¤¹¤ë¿¼¤¨·½ ¨C ¡°TD¡±-VAE¤È¤¤¤¦ÃûÇ°¤Ï£¬¤³¤Î¤¢¤¿¤ê¤ÈTDÕ`²î¤È¤ÎévßBĞÔ¤«¤é£® 18 ? ??1 ???1 ? ? ?? ???1 ?? ? ?1,?2 = ? ? ?(? ?2|? ?2)?(? ?1|? ?2,? ?1,? ?2)[log ? ? ?2 ??2 + log ? ?(??1 |??1 ) + log ?(??2 |??1 ) ? log ? ? ??2 ??2 ? log ?(??1 |??2 , ??1 , ??2 )] ? ??[?(??1 |??2 , ??1 , ??2 )| ?(??1 ??1 )]
- 19. Ña×㣺VAE¡ÁRNN Zoo ? VAE¡ÁRNN¤ÎÑо¿Ò»ÓE£¨Éú³É¥â¥Ç¥ë£¨É϶Σ©¤Ç·ÖVSMCϵ¤Ïİd¤»¤Æ¤¤¤Ê¤¤£© ¡ù·Ö²¼£¨Ê¸Ó¡£©¤Ï¸Å¤Ír¿Ì?¤Ëév¤¹¤ë¤â¤Î¤Î¤ßÃè» ???1 ???1 ?? ?? Deep Markov Model [Krishnan+ 17] £¨Deep Kalman Filter [Krishnan+ 15]£© ¡ùÍÆÕ·Ö²¼¤ÏÕÎÄÄڤǤ¤¤¯¤Ä¤«Ìá°¸¤µ¤ì¤Æ¤¤¤ë ? ??1 ? ? ???1 ???1 ?? ?? SRNN [Fraccaro+ 16] ? ??1 ? ? ? ??1 ? ? ???1 ???1 ?? ?? TD-VAE [Gregor+ 18] ???1 ?? ???1 ???1 ?? ?? VRNN [Chung+ 16] ? ??1 ? ? ???1 ???1 ?? ?? STORN [Bayer+ 15] ? ??1 ? ? ? ??1 ? ? ???1 ???1 ?? ?? Z-forcing [Goyal+ 17] ? ??1 ? ? ???1 ?? ? ?????(??) = ?(??|?1:??1, ?1:??1) ? ?????(??) = ?(??) ? ?????(??) = ?(??|???1, ?) ???1 ???1 ?? ?? ×´B¿Õég¥â¥Ç¥ë ¡ùaction¤ÏÊ¡ÂÔ ? ?, ? = ¦° ? ? ?? ?? ? ?? ???1 ???1 ?? ?? ???1 ? ?, ? = ¦° ? ? ?? ?1:??1, ?1:? ? ?????(??) ???1 ?? ?? ???1 ? ?, ? = ¦° ? ? ??+1 ?1:?, ?1:? ? ?????(??) 19
- 20. gòY 20
- 21. gòY1 ? ²¿·ÖÓQy¤ÊMiniPacman [Racanie?re et al., 2017] ¨C ¥¨©`¥¸¥§¥ó¥È¤ÏÓÄë¤ò±Ü¤±¤Ê¤¬¤éÃÔ·ÄڤΤ¹¤Ù¤Æ¤ÎʳÎï¤òʳ¤Ù¤è¤¦¤È¤¹¤ë£® ¨C ÓQy¤Ç¤¤ë¤Î¤Ï5¡Á5¤Î¥¦¥£¥ó¥É¥¦£¨ÓÒ£© -> ¸ß¤¤¥¹¥³¥¢¤òß_³É¤¹¤ë¤¿¤á¤Ë¤Ï£¨ß^È¥¤Î½UòY¤äh¾³¤Î²»´_gĞÔ¤ò¿¼]¤·¤Ä¤Ä£©ĞÅÄî×´B¤òĞγɤ¹¤ë±ØÒª¤¬¤¢¤ë£® ? ¤³¤ÎgòY¤Ç¤Ï£¬non-jumpy¤ÊTD-VAE¤¬ßmÇФËѧÁ¤Ç¤¤ë¤«´_ÕJ¤¹¤ë£® ¨C ËʵĤÊELBO¤ÎϤǤÎ2¤Ä¤Î×´B¿Õég¥â¥Ç¥ë¤È±Èİ^ -> TD-VAE¤ÎELBO¤ÎÓĞ¿ĞÔ¤òÔuı 21 Under review as aconference paper at ICLR 2019 ELBO ? logp(x) (est.) Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007 Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010 TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006 Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is navigating the mazetrying to eat all the food (blue) whilebeing chased by aghost (red). Top right: A sequence of observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right: ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter. Log probability isestimated using importance sampling with theencoder as proposal. Under review asaconference paper at ICLR 2019 ELBO ? logp(x) (est.) Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007 Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010 TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006 Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is navigating themazetrying to eat all thefood (blue) whilebeing chased by aghost (red). Top right: A sequenceof observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right: ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter. Log probability isestimated using importance sampling with theencoder asproposal.
- 22. gòY1 ? gòY½Y¹û ¨C ¥Æ¥¹¥È¼¯ºÏ¤Ë¤¹¤ë£¨¿Ö¤é¤¯Ø¤Î£©ä·ÖϽç¤ÈؤÎÊıÓȶȤǤÎÔuı ¨C Ğ¡¤µ¤¤·½¤¬Á¼¤¤¥â¥Ç¥ë£® ¨C TD-VAE¤¬×î¤âÁ¼¤¤½Y¹û ¨C ƽ¾ùö¥â¥Ç¥ë¤¬µÍ¤¤½Y¹û¤Ë¤Ê¤Ã¤Æ¤¤¤ë ? ƽ¾ùö¥â¥Ç¥ë¤Ç¤Ï??¤¬ĞÅÄî×´B¤Î¥³©`¥É¤Ë¤Ê¤Ã¤Æ¤¤¤ë¤¬£¬¥Õ¥£¥ë¥¿¥ê¥ó¥°¥â¥Ç¥ë¤Ç¤Ï¤½¤¦¤Ê¤Ã¤Æ¤¤¤Ê¤¤¤³¤È¤Ë×¢Ò⣨¥Õ¥£¥ë¥¿¥ê¥ó¥°¥â¥Ç¥ë¤Ç¤Ï£¬ ¥¨¥ó¥³©`¥À¤ÇÇ°¤Î¥¹¥Æ¥Ã¥×¤Î?¤ËÒÀ´æ¤·¤Æ¤¤¤ë¤Î¤Ç£© ĞÅÄî×´B¤òµÃ¤ë¤¿¤á¤Ë g¼¤Ë¥¨¥ó¥³©`¥À¤òÖÆÏŞ¤¹¤ë¤À¤±¤Ç¤Ï¾«¶È¤¬Ï¤¬¤ë 22 Under review asaconference paper at ICLR 2019 ELBO ? logp(x) (est.) Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007 Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010 TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006 Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is navigating themazetrying to eat all thefood (blue) whilebeing chased by aghost (red). Top right: A sequenceof observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right: ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter. Log probability isestimated using importance sampling with theencoder asproposal.
- 23. gòY2 ? Moving MNIST ¨C ¸÷¥¹¥Æ¥Ã¥×¤ÇÒÆÓ¤¹¤ëMNIST ¨C [1,4]¤Î¹ ì¤Ç¥¹¥Æ¥Ã¥×¤òïw¤ÓÔ½¤¨¤ÆѧÁ¤·£¬Éú³É¤Ç¤¤ë¤«¤ògòY ? gòY½Y¹û£º ¨C ¥¹¥Æ¥Ã¥×Êı¤òïw¤Ğ¤·¤Æ¤âÉú³É¤Ç¤¤¿£® ¨C £¨Ã÷ʾµÄ¤Ëø¤¤¤Æ¤Ê¤¤¤¬¿Ö¤é¤¯£©Ò»·¬×ó¤¬Ôª»Ïñ¤Ç¸÷ÁФ¬ïw¤Ğ¤·¤¿¥¹¥Æ¥Ã¥×Êı[1,4]¤Ëꤷ¤Æ¤¤¤ë 23 Figure 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is navigating themazetrying to eat all the food (blue) whilebeing chased by aghost (red). Top right: A sequence of observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right: ELBO and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter. Log probability isestimated using importance sampling with theencoder asproposal. Figure 3: Moving MNIST. Left: Rowsare example input sequences. Right: Jumpy rollouts from themodel. Weseethat themodel isable to roll forward by skipping frames, keeping thecorrect digit and thedirection of motion. 5.2 MOVING MNIST In thisexperiment, weshow that themodel isable to learn thestateand roll forward in jumps. We consider sequencesof length 20 of images of MNIST digits. For each sequence, arandom digit from thedataset ischosen, aswell asthedirection of movement (left or right). At each timestep, thedigit movesby one pixel in the chosen direction, asshown in Figure 3. Wetrain the model with t1 and t2 separated by arandom amount t2 ? t1 from theinterval [1, 4]. Wewould liketo seewhether the model at agiven timecan roll out asimulated experience in timesteps t1 = t + ¦Ä1, t2 = t1 + ¦Ä2, . . . with ¦Ä1, ¦Ä2, . . . > 1, without considering theinputsin between thesetimepoints. Notethat it isnot suf?cient to predict thefuture inputs xt 1 , . . . asthey do not contain information about whether the digit movesleft or right. Weneed to sample astate that contains this information. Weroll out asequence from themodel asfollows: (a) bt iscomputed by the aggregation recurrent network from observations up to time t; (b) a state zt is sampled from pB (zt | bt ); (c) a sequence 0 0 ELBO ? logp(x) (est.) Filtering model 0.1169¡À 0.0003 0.0962¡À 0.0007 Mean-?eld model 0.1987¡À 0.0004 0.1678¡À 0.0010 TD-VAE 0.0773 ¡À 0.0002 0.0553 ¡À 0.0006 re 2: MiniPacman. Left: A full frame from the game (size 15 ? 19). Pacman (green) is gating themazetrying to eat all the food (blue) whilebeing chased by aghost (red). Top right: quence of observations, consisting of consecutive5?5 windowsaround Pacman. Bottom right: O and estimated negativelog probability on atest set of MiniPacman sequences. Lower isbetter. probability isestimated using importance sampling with theencoder asproposal. re 3: Moving MNIST. Left: Rowsare example input sequences. Right: Jumpy rollouts from model. Wesee that themodel isable to roll forward by skipping frames, keeping thecorrect digit the direction of motion.
- 24. gòY3 ? ¥Î¥¤¥º¤Î¶à¤¤¸ßÕ{²¨°kÕñÆ÷¤«¤éµÃ¤é¤ì¤¿1´ÎÔª¥·©`¥±¥ó¥¹ ¨C ¸÷ÓQy¤ÇÇé󤬤ۤȤó¤É¤Ê¤¯¤Æ¤â£¨¥Î¥¤¥º¤¬Èë¤Ã¤Æ¤¤¤Æ¤â£©¥â¥Ç¥ë¤¬×´B¤òºB¤Ç¤¤ë¤³¤È¤òʾ¤¹£® ¨C RNN¤Ë¤ÏLSTM¤òÓ䤤ƣ¬ëAÓTD-VAE¤òʹ¤Ã¤ÆѧÁ£® ? b¤¬ëAÓ»¯¤·¤Æ¤¤¤ë£¨ÕhÃ÷¤ÏÊ¡ÂÔ£© ¨C ¥¹¥Æ¥Ã¥×·ù¤Ï´_ÂÊ0.8¤Ç[1,10]¤Îég£¬´_ÂÊ0.2¤Ç[1,120]¤Îég¤È¤·¤ÆѧÁ ? gòY½Y¹û£º ¨C 20¥¹¥Æ¥Ã¥×¼°¤Ó100¥¹¥Æ¥Ã¥×ïw¤Ğ¤·¤¿½Y¹û ¨C ¥Î¥¤¥º¤¬¶à¤¤ÓQy¥Ç©`¥¿¤Ç¤âÉú³É¤Ç¤¤Æ¤¤¤ë£® 24 Under review asaconference paper at ICLR 2019 Figure4: Skip-state prediction for 1D signal. Theinput isgenerated by anoisy harmonic oscillator. Rollouts consist of (a) ajumpy state transition with either dt = 20 or dt = 100, followed by 20 state transitions with dt = 1. The model is able to create a state and predict it into the future, correctly predicting frequency and magnitude of thesignal. predict asmuch aspossible about thestate, which consists of frequency, magnitude and position, and it isonly theposition that cannot beaccurately predicted.
- 25. gòY4 ? DeepMInd Labh¾³ ¨C ¥¢©`¥¥Æ¥¯¥Á¥ã¤ÏConvDRAW¤ò²Î¿¼¤·¤¿¤â¤Î¤Ëä¸ü£¨¿Ö¤é¤¯GQN¤Èͬ¤¸Ê¹¤¤·½£© ? gòY½Y¹û£º ¨C ¥â¥Ç¥ë¤ÎĞÅÄî¤Î´_ÕJ£¨¤¢¤ëĞÅÄ¤é¥é¥ó¥À¥à¤Ë?¤òÉú³É£© ¨C ×ó¤Î»Ïñ£º¤½¤ì¤¾¤ì¤Î?¥µ¥ó¥×¥ë¤«¤é»Ïñ¤òÉú³É -> ͬ¤¸¥Õ¥ì©`¥à¤¬Éú³É¤Ç¤¤Æ¤¤¤ë ¨C ÓҤλÏñ£º¤½¤ì¤¾¤ì¤Î?¥µ¥ó¥×¥ë¤«¤éÈÎÒâ¤Ë¥¹¥Æ¥Ã¥×¤òïw¤ó¤ÇÉú³É ? ¸÷ĞÅÄîÄڤǤÏͬ¤¸¤è¤¦¤Ê»Ïñ¤¬Éú³É¤µ¤ì¤Æ¤¤¤ë¤¬£¬ĞÅÄî¤Ë¤è¤Ã¤Æ³ö¤Æ¤¯¤ë¥Õ¥ì©`¥à¤¬®¤Ê¤ë ->¸÷ĞÅÄî¤ÇÈ¡¤ê¤¦¤ëδÀ´¤¬®¤Ê¤Ã¤Æ¤¤¤ë 25
- 26. gòY4 ? gòY½Y¹û£º ¨C ¥¹¥Æ¥Ã¥×¤òïw¤ÓÔ½¤¨¤ÆĞĞÓ¤òßM¤á¤ë¤³¤È¤¬¤Ç¤¤ë£® ¨C í¤ò¤É¤¦Ò¤ì¤Ğ¤¤¤¤¤«¤ÏÕıÖ±²»Ã÷£¨rollout¤Èø¤¤¤Æ¤¤¤ë¤Î¤Ç£¬¶à·ÖMNIST¤Èͬ¤¸¸Ğ¤¸£© 26
- 27. ¤Ş¤È¤á 27
- 28. ¤Ş¤È¤á ? ±¾Ñо¿¤Ç¤Ï£¬rϵÁФòQ¤¦ÊÀ½ç¥â¥Ç¥ë¤È¤·¤ÆTD-VAE¤òÌá°¸¤·¤¿£® ¨C Ìؤˣ¬rég·½Ïò¤Î³éÏ󻯤òÒâ×R¤·¤Æ¤¤¤ë£® ¨C arXiv°æ¤Ç¤Ï¤¢¤Ş¤êÕ{¤µ¤ì¤Æ¤¤¤Ê¤«¤Ã¤¿İ¤¬¤¹¤ë£® ? ¸ĞÏ룺 ¨C ÊÀ½ç¥â¥Ç¥ë¤Ë¤ª¤¤¤Æ¡¸rég¤ò³éÏ󻯡¹¤Ç¤¤ë¤è¤¦¤Ë¤Ê¤Ã¤¿³õ¤á¤Æ¤ÎÑо¿£¨ICLRµÄ¤Ë¤Ï½YÊܤ±¤½¤¦£© ¨C È˵ĤˤÏGQN¤è¤ê¤âºÃ¤£® ¨C ¼¤«¤¤ÓÊö¤¬¤Ê¤«¤Ã¤¿¤ê¤¹¤ë¤Î¤Ç£¬¤È¤ê¤¢¤¨¤ºPixyz¤È¤«¤Çg×°¤·¤ÆÓ×÷´_ÕJ¤·¤Æ¤ß¤¿¤¤£¨¹«Ê½¤Îg×°¤Ï¹«é_¤µ¤ì ¤Æ¤¤¤Ê¤¤£©£® 28