並列計算への道 2015年版
Download as pptx, pdf1 like1,995 views

並列計算への道 2015年版。CPUとかGPUとかFPGAについてかなり大ざっぱに説明。















![科学技術計算例
void matrixmultiply(double a[N][N],double b[N][N],double c[N][N])
{
int i,j,k;
for(i=0;i<N;i++) {
for(j=0;j<N;j++) {
for(k=0;k<N;k++) {
c[i][j]+=a[i][k]*b[k][j];
}
}
}
}](https://image.slidesharecdn.com/fpga-gpu-cpu-160114081027/85/2015-41-320.jpg)
![1976→2010
1976 TK-80
? 8bit CPU
? 2.4576MHz
? ROM:256 B
? RAM:128 B
2010 NEC PC
? 64bit CPU
? 3.6 GHz(4.0GHz)
? HDD:1T
? RAM:16G
void matrixmultiply(double a[N][N],double b[N][N],double c[N][N])
{
int i,j,k;
for(i=0;i<N;i++) {
for(j=0;j<N;j++) {
for(k=0;k<N;k++) {
c[i][j]+=a[i][k]*b[k][j];
}
}
}
}
勝手に1000倍以上早くなる](https://image.slidesharecdn.com/fpga-gpu-cpu-160114081027/85/2015-42-320.jpg)
![こう書いても早くならない
void matrixmultiply(double a[N][N],double b[N][N],double c[N][N])
{
int i,j,k;
for(i=0;i<N;i++) {
for(j=0;j<N;j++) {
for(k=0;k<N;k++) {
c[i][j]+=a[i][k]*b[k][j];
}
}
}
}](https://image.slidesharecdn.com/fpga-gpu-cpu-160114081027/85/2015-48-320.jpg)



























並列計算への道 2015年版
- 1. 並列計算への道 2015年版 The Road of Parallel Computing シンビー 2015/5/1
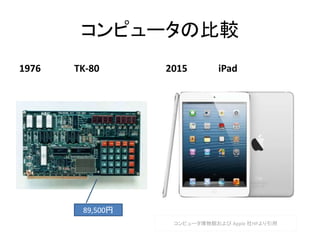
- 2. コンピュータの比較 1976 TK-80 2015 iPad 89,500円 コンピュータ博物館および Apple 社HPより引用
- 3. ゲーム機比較 1979 TVブロックゲーム 2013 PlayStation 4 <=""> 13,500 円 akiba.geocities.yahoo.co.jp Playstation.com から引用
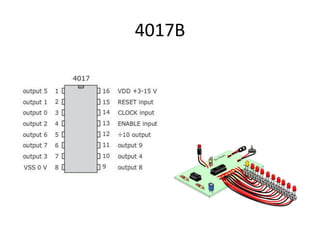
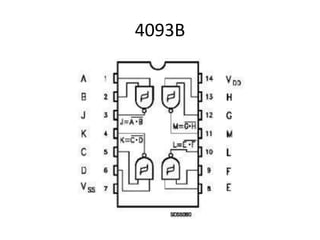
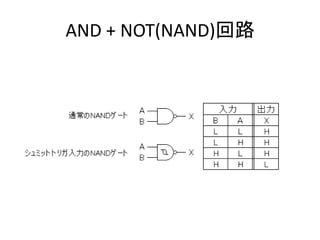
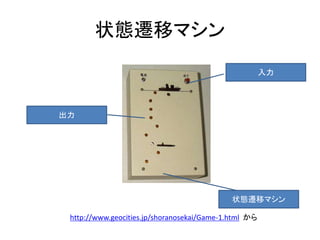
- 10. 中身はこう C-MOS の IC が 3個使ってあります(4017B×2、4093B×1) http://www.geocities.jp/shoranosekai/Game-2.html から
- 11. 4017B
- 12. 4093B
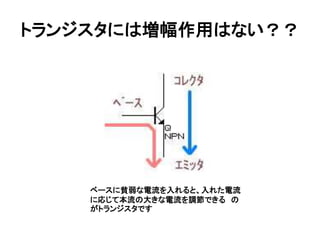
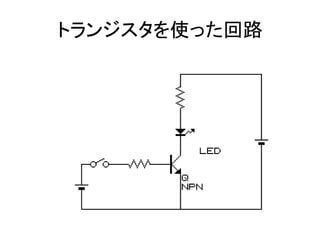
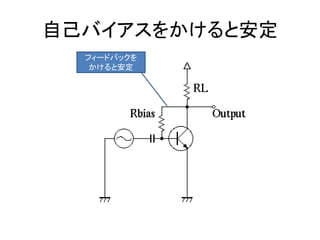
- 19. トランジスタを使った回路
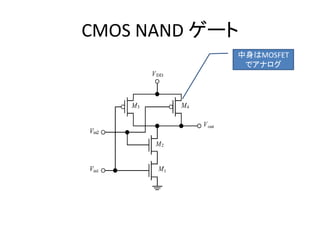
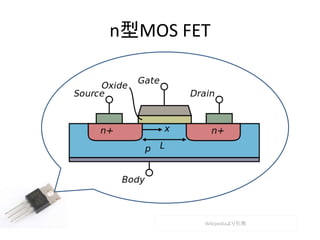
- 21. アナログ → デジタル
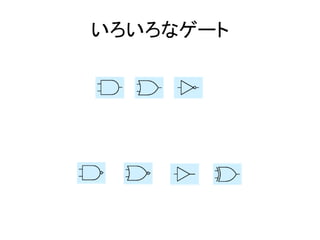
- 22. いろいろなゲート
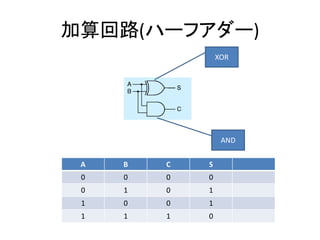
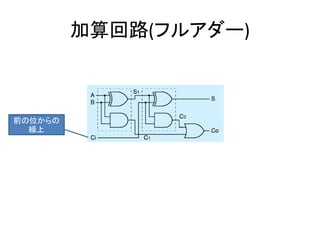
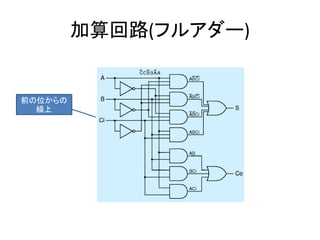
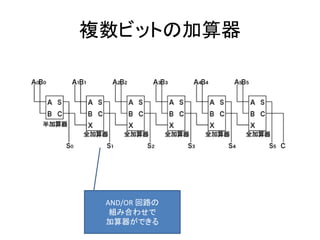
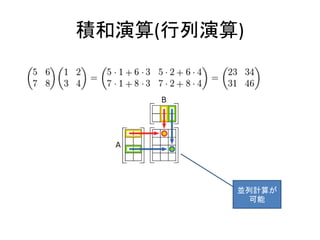
- 23. 加算回路(ハーフアダー) A B C S 0 0 0 0 0 1 0 1 1 0 0 1 1 1 1 0 XOR AND
- 28. 2の補数 ? 2の補数を使うと – 足し算だけで引き算ができる ? 4bit の引き算: 0100 – 0011 を考える(4-3) ? 0100 – 0011 ? 0100 + (0011 の2の補数) ? 0100 + (1100 + 1) ? 0100 + 1101 ? 0100 + 1101 => 10001 => 0001
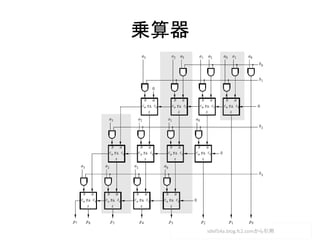
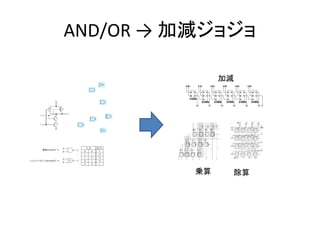
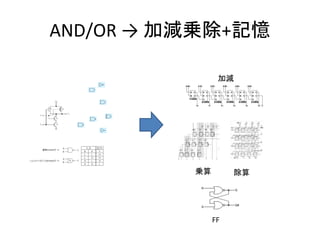
- 30. AND/OR → 加減ジョジョ 加減 乗算 除算
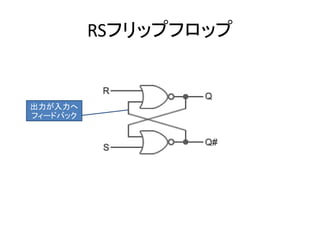
- 33. AND/OR → 加減乗除+記憶 加減 乗算 除算 FF
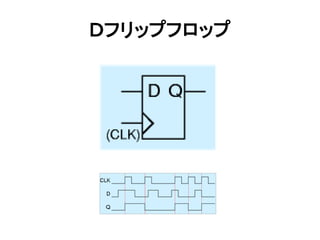
- 34. Dフリップフロップ
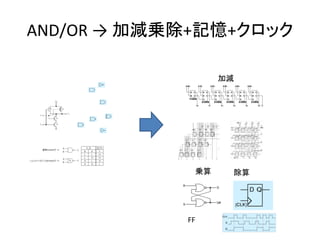
- 35. AND/OR → 加減乗除+記憶+クロック 加減 乗算 除算 FF
- 38. アナログ → デジタル
- 40. コンピュータの比較 1976 TK-80 ? 8bit CPU ? 2.4576MHz ? ROM:256 B ? RAM:128 B 2015 NEC PC ? 64bit CPU ? 3.6 GHz(4.0GHz) ? HDD:1T ? RAM:16G
- 41. 科学技術計算例 void matrixmultiply(double a[N][N],double b[N][N],double c[N][N]) { int i,j,k; for(i=0;i<N;i++) { for(j=0;j<N;j++) { for(k=0;k<N;k++) { c[i][j]+=a[i][k]*b[k][j]; } } } }
- 42. 1976→2010 1976 TK-80 ? 8bit CPU ? 2.4576MHz ? ROM:256 B ? RAM:128 B 2010 NEC PC ? 64bit CPU ? 3.6 GHz(4.0GHz) ? HDD:1T ? RAM:16G void matrixmultiply(double a[N][N],double b[N][N],double c[N][N]) { int i,j,k; for(i=0;i<N;i++) { for(j=0;j<N;j++) { for(k=0;k<N;k++) { c[i][j]+=a[i][k]*b[k][j]; } } } } 勝手に1000倍以上早くなる
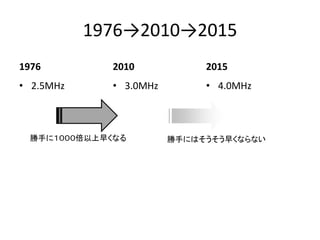
- 44. 1976→2010→2015 1976 ? 2.5MHz 2010 ? 3.0MHz 2015 ? 4.0MHz 勝手に1000倍以上早くなる 勝手にはそうそう早くならない
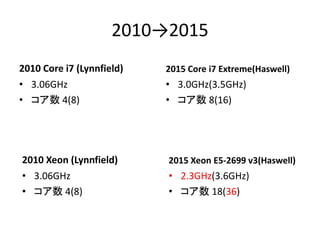
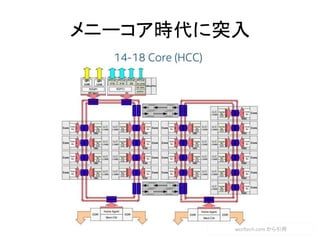
- 45. 2010→2015 2010 Core i7 (Lynnfield) ? 3.06GHz ? コア数 4(8) 2015 Core i7 Extreme(Haswell) ? 3.0GHz(3.5GHz) ? コア数 8(16) 2010 Xeon (Lynnfield) ? 3.06GHz ? コア数 4(8) 2015 Xeon E5-2699 v3(Haswell) ? 2.3GHz(3.6GHz) ? コア数 18(36)
- 48. こう書いても早くならない void matrixmultiply(double a[N][N],double b[N][N],double c[N][N]) { int i,j,k; for(i=0;i<N;i++) { for(j=0;j<N;j++) { for(k=0;k<N;k++) { c[i][j]+=a[i][k]*b[k][j]; } } } }
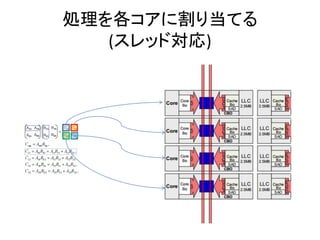
- 52. 並列化の方法 ? スレッド ? OpenMP ? MPI ? Intel Threading Building Blocks(TBB) ? GPGPU – OpenCL – CUDA ? Parallella (Epiphany) ? FPGAで専用ハードを作る
- 53. Agenda ? GPGPU – OpenCL – CUDA ? Parallella (Epiphany) ? FPGAで専用ハードを作る ? 何を計算させるか?
- 54. GPGPU を使う方法 ? GPU = Graphics Processing Unit 16,480円 3Dのゲームに強い msi.com から引用(?)
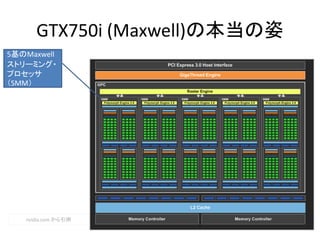
- 55. GTX 750i CUDA コア 640 クロック 1.02 GHz(1.085G) メモリインタフェース 128-bit GDDR5 Processing Power 1306GFlops(Single float) Wikipediaより Intel Xeon E5-2699 v3(Haswell) 16~18コア 569,915 円 VS?? Intel Xeon?? 16,480円 547.2Gflops
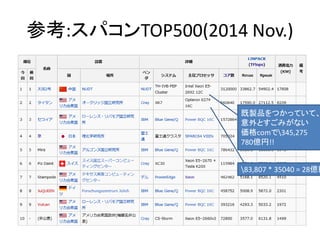
- 56. 16,480円 GTX 750i vs スパコン?? CUDA コア 640 クロック 1.02 GHz(1.085G) メモリインタフェース 128-bit GDDR5 Processing Power 1306GFlops(Single float) Wikipediaより PRIMEHPC FX10 2014 理研が購入 384ノードx16コア =6144 2億円~ 90.8TFLOPS 69倍以上の性能差?
- 59. GTX 750i vs Intel Xeon GTX750i Xeon E5-2699 CPU 的コア 20? 36 クロック 1.02 GHz (1.085G) 2.3GHz (3.6GHz) 計算用Core 640 8?x36=288 理論GFLOPSから逆算 GFLOPS 1306 547.2 569,915 円16,480円 GPUに特化した プロセッサー OSも載る汎用 プロセッサー CUDAコアが640あるが それを効率的に生かせるかどうかは 対象となるアプリしだい スパコンのFLOPSと比べるのはおそらくナンセンスでしょう
- 61. GPGPU 科学技術計算とかにつかえるのでは? 2001 プログラマブルGPU「GeForce3」 General-purpose computing on graphics processing units This example performs an NBody simulation which calculates a gravity field and corresponding velocity and acceleration contributions accumulated by each body in the system from every other body. This example also shows how to mitigate computation between all available devices including CPU and GPU devices, as well as a hybrid combination of both, using separate threads for each simulator
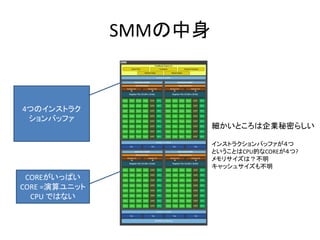
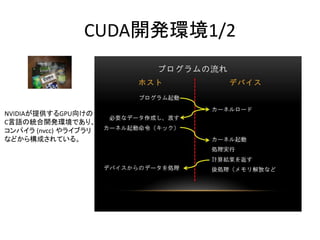
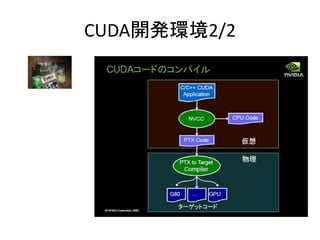
- 63. 颁鲍顿础开発环境2/2
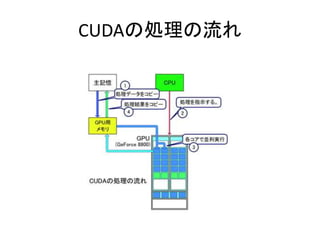
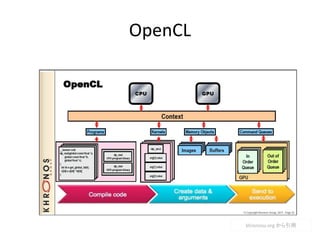
- 64. 颁鲍顿础の処理の流れ
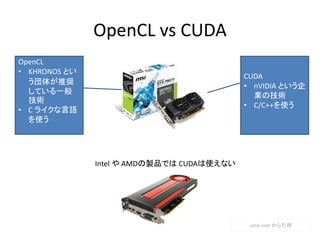
- 66. OpenCL vs CUDA CUDA ? nVIDIA という企 業の技術 ? C/C++を使う OpenCL ? KHRONOS とい う団体が推奨 している一般 技術 ? C ライクな言語 を使う Intel や AMDの製品では CUDAは使えない amd.com から引用
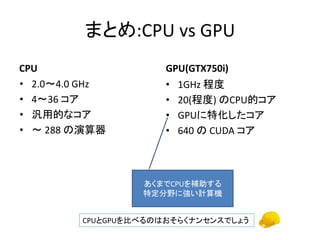
- 67. まとめ:CPU vs GPU CPU ? 2.0~4.0 GHz ? 4~36 コア ? 汎用的なコア ? ~ 288 の演算器 GPU(GTX750i) ? 1GHz 程度 ? 20(程度) のCPU的コア ? GPUに特化したコア ? 640 の CUDA コア あくまでCPUを補助する 特定分野に強い計算機 CPUとGPUを比べるのはおそらくナンセンスでしょう
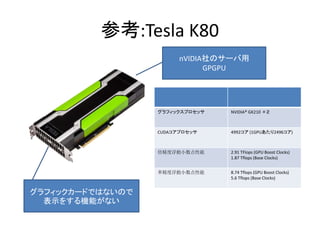
- 68. 参考:Tesla K80 nVIDIA社のサーバ用 GPGPU グラフィックスプロセッサ NVIDIA? GK210 ×2 CUDAコアプロセッサ 4992コア (1GPUあたり2496コア) 倍精度浮動小数点性能 2.91 TFlops (GPU Boost Clocks) 1.87 Tflops (Base Clocks) 単精度浮動小数点性能 8.74 Tflops (GPU Boost Clocks) 5.6 Tflops (Base Clocks) グラフィックカードではないので 表示をする機能がない
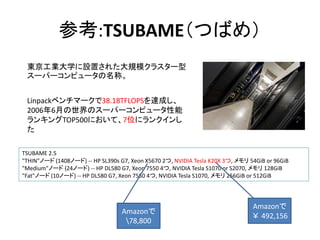
- 69. 参考:TSUBAME(つばめ) 東京工業大学に設置された大規模クラスター型 スーパーコンピュータの名称。 Linpackベンチマークで38.18TFLOPSを達成し、 2006年6月の世界のスーパーコンピュータ性能 ランキングTOP500において、7位にランクインし た TSUBAME 2.5 "THIN"ノード (1408ノード) -- HP SL390s G7, Xeon X5670 2つ, NVIDIA Tesla K20X 3つ, メモリ 54GiB or 96GiB "Medium"ノード (24ノード) -- HP DL580 G7, Xeon 7550 4つ, NVIDIA Tesla S1070 or S2070, メモリ 128GiB "Fat"ノード (10ノード) -- HP DL580 G7, Xeon 7550 4つ, NVIDIA Tesla S1070, メモリ 256GiB or 512GiB Amazonで 78,800 Amazonで ¥ 492,156
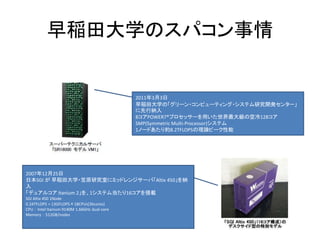
- 72. 早稲田大学のスパコン事情 2011年3月3日 早稲田大学の「グリーン?コンピューティング?システム研究開発センター」 に先行納入 8コアPOWER7?プロセッサーを用いた世界最大級の空冷128コア SMP(Symmetric Multi-Processor)システム 1ノードあたり約8.2TFLOPSの理論ピーク性能 2007年12月25日 日本SGI が 早稲田大学?笠原研究室にミッドレンジサーバ「Altix 450」を納 入 「デュアルコア Itanium 2」を、1システム当たり16コアを搭載 SGI Altix 450 1Node 0.24TFLOPS = 13GFLOPS×18CPUs(36cores) CPU : Intel Itanium 9140M 1.66GHz dual-core Memory : 512GB/nodes
- 73. Agenda ? GPGPU – OpenCL – CUDA ? Parallella (Epiphany) ? FPGAで専用ハードを作る ? 何を計算させるか?
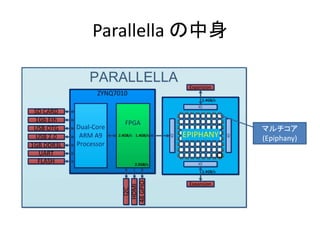
- 74. Parallellaについて ? Parallella は Adapteva社が販売をしている – Epiphany というマルチコアチップ – 並列コンピューティングをターゲット – 名刺サイズのコンピュータ 17,318 ~ 34,493
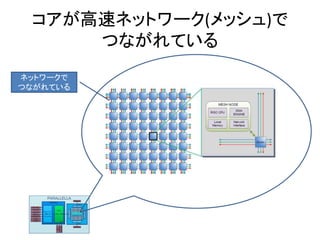
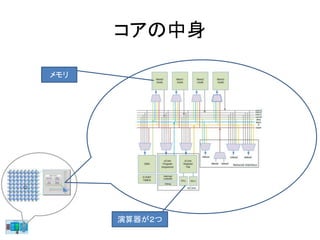
- 77. コアの中身 メモリ 演算器が2つ
- 78. GPU vs Parallella GPU(GTX750i) ? 1.02GHz ? 20(程度) のCPU的コア ? GPUに特化したコア ? 640 の CUDA コア ? 詳細スペック未公開 – PTXコードと呼ばれる仮想的 なコードだけ公開 ? 1306 GFLOPS(Peak Performance) – 640 * 2 * 1.02GHz Parallella(Epiphany) ? 1GHz ? 16個のEpiphany(拡張可能) ? 汎用CPU ? 演算器2つ ? 32K バイトのローカルメモリ ? DMAエンジン ? 32 GFLOPS (Peak Performance) – 16 x 2 x 1 GHz GPUとParallellaを比べるのはおそらくナンセンスでしょう
- 82. Parallella まとめ ? Parallella をつかうと“なにか”できそう。 – C/C++ でプログラミングができる
- 83. Agenda ? GPGPU – OpenCL – CUDA ? Parallella (Epiphany) ? FPGAで専用ハードを作る ? 何を計算させるか?
- 84. FPGAとはなにか? ? Field Programmable Gate Array の略 自分の好 きな回路 を書ける xilinx.com から引用(?)
- 85. Lチカ(LED チカチカ) SW
- 86. いろんな回路を作ることができる
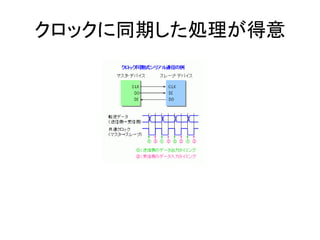
- 87. クロックに同期した処理が得意
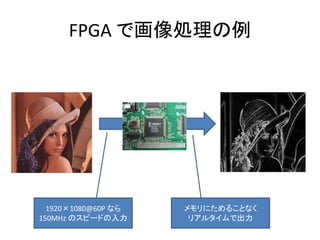
- 88. FPGA で画像処理の例 1920×1080@60P なら 150MHz のスピードの入力 メモリにためることなく リアルタイムで出力
- 89. FPGA の特徴 ? 自分で回路を組むことができる – 並列処理で特殊処理を組むことが可能 ? ソフトウェアでは達成できないタイミングの処理、 とりわけクロックに同期する処理を可能とする – 処理時間が一定しない処理は苦手 ? 動作スピードは 100MHz ~ 200MHz – 中には特殊な機能を積んであるチップで 1G Hzを超 える入出力も可能なものもある。その場合でも、内部 は 100MHz ~ 200MHz
- 90. Agenda ? GPGPU – OpenCL – CUDA ? Parallella (Epiphany) ? FPGAで専用ハードを作る ? 何を計算させるか?
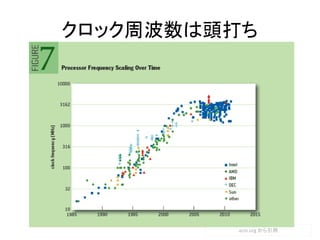
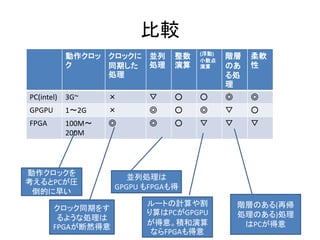
- 91. 比較 動作クロッ ク クロックに 同期した 処理 並列 処理 整数 演算 (浮動) 小数点 演算 階層 のあ る処 理 柔軟 性 PC(intel) 3G~ × ▽ ○ ○ ◎ ◎ GPGPU 1~2G × ◎ ○ ◎ ▽ ○ FPGA 100M~ 200M ◎ ◎ ○ ▽ ▽ ▽ 動作クロックを 考えるとPCが圧 倒的に早い クロック同期をす るような処理は FPGAが断然得意 並列処理は GPGPU もFPGAも得 ルートの計算や割 り算はPCがGPGPU が得意。積和演算 ならFPGAも得意 階層のある(再帰 処理のある)処理 はPCが得意
- 92. 何を計算させるか? ? マンデンブロ集合? – 並列処理のデモとして格 好の対象 ? それぞれの計算が独立 ? 分割が用意 – 入力がない ? 入力データがなく、結果は 出力だけ
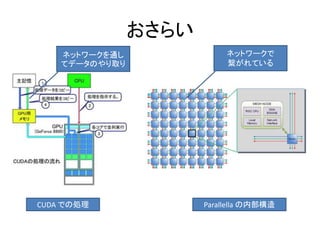
- 94. おさらい CUDA での処理 Parallella の内部構造 ネットワークを通し てデータのやり取り ネットワークで 繋がれている
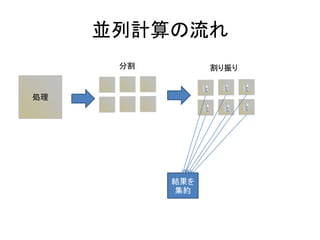
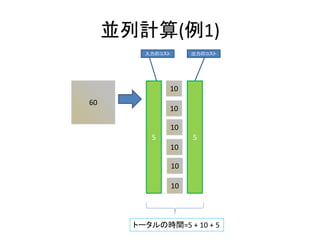
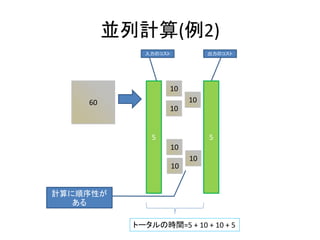
- 95. 並列処理のコスト ? 計算のコスト ? ネットワークのコスト – 処理を割り振るときにネットワークを使用する – 処理結果を得るときにネットワークを使用する
- 97. 並列計算(例2) 60 10 10 10 10 10 10 5 入力のコスト 出力のコスト 5 トータルの時間=5 + 10 + 10 + 5 計算に順序性が ある
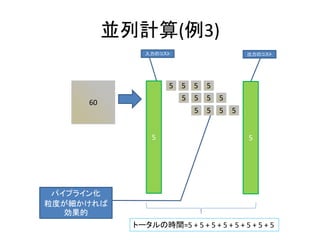
- 98. 並列計算(例3) 60 5 5 入力のコスト 出力のコスト 5 トータルの時間=5 + 5 + 5 + 5 + 5 + 5 + 5 + 5 パイプライン化 粒度が細かければ 効果的 5 5 5 5 5 5 5 5 5 5 5
- 99. 最適な手段はケースバイケース ? 4GHz CPU で単純に計算した方が早い ? 1GHz の GPGPU で並列計算した方が早い ? 100MHz の FPGA で並列計算した方が早い ? 関連する項目 – 並列の粒度 – 順序性 – ネットワークのスピード – ノード計算能力
- 100. 力尽きたのでこの辺で终わり