Abstracts of FPGA2017 papers (Temporary Version)
Download as PPTX, PDF8 likes1,388 views

Just a single page summery for each paper presented FPGA2017.
























![FPGA-Accelerated Transactional Execution of Graph Workloads
? Š▐┤¾ź░źķźšżžż╬źóź»ź╗ź╣żŪżŽźßźŌźĻź│ź¾źšźĻź»ź╚ż¼ŲżŁżļ
? ź╣ź▒®`źķźųźļż╩ź│ź¾źšźĻź»ź╚Ś╩│÷ż“╩Šż╣
? Intel Haswelż╚ż»żķż┘żŲ2▒Čż╬ąį─▄Ž“╔ŽŻ¼
22▒Čż╬ź©ź═źļź«®`ä┐┬╩
? FPGA Research Infrastructure Cloud[42]ż“└¹ė├
? http://www.openfabric.org](https://image.slidesharecdn.com/abstractsoffpga2017papers-170405125308/85/Abstracts-of-FPGA2017-papers-Temporary-Version-26-320.jpg)



![Hardware Acceleration of the Pair-HMM Algorithm for DNA Variant
Calling
Pair HMM forwardźóźļź┤źĻź║źÓż╬FPGAżŪż╬Ė▀╦┘╗»
źĻź¾ź░śŗįņż╬PEżŪILPż╚źŪ®`ź┐üK┴ąąįż“┐╝æ]żĘżŲśöĪ®ż╩śŗ│╔ż“ż╚żļ
C++ź┘®`ź╣ż╬CPUīgąąż╚ż»żķż┘żŲ487xĖ▀╦┘Ż¼źŽ®`ź╔ź”ź¦źóīgū░ż╚▒╚ż┘żŲ1.56xĖ▀╦┘](https://image.slidesharecdn.com/abstractsoffpga2017papers-170405125308/85/Abstracts-of-FPGA2017-papers-Temporary-Version-31-320.jpg)




























![[DL Hacks]FPGA╚ļķT](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=560&fit=bounds)

More Related Content
What's hot (20)
Similar to Abstracts of FPGA2017 papers (Temporary Version) (20)

















![[Track2-2] ūŅą┬ż╬NVIDIA Ampereźó®`źŁźŲź»ź┴źŃż╦żĶżļNVIDIA A100 Tensorź│źóGPUż╬╠žķLż╚żĮż╬ąį─▄ż“ę²żŁ│÷ż╣ĘĮĘ©](https://cdn.slidesharecdn.com/ss_thumbnails/2020801nvidia-200807073343-thumbnail.jpg?width=560&fit=bounds)
More from Takefumi MIYOSHI (20)




















Abstracts of FPGA2017 papers (Temporary Version)
- 1. Abstracts of FPGA2017 papers (Ģ║Č©░µ) šiż¾ż└╚╦: ż▀żĶżĘż┐ż▒żšż▀ šiż¾ż└╚š: 6th March, 2017
- 2. Can FPGAs Beat GPUs in Accelerating Next-Generation Deep Neural Networks? Intel 14nm Stratix10 FPGAż“╩╣ż├żŲDNNźóź»ź╗źķźņ®`ź┐ū„ż├ż┐ GEMMź¬ź┌źņ®`źĘźńź¾ż“įuü²Ż«Titan X Pascal GPUż╚▒╚ż┘żŲ pruendżŪ10% Int6żŪ50% Binarized DNNżŪ5.4x Ternary ResNetżŪTitan X Pascal GPUż╬ 60%ż╬ąį─▄ 2.3xż╬ąį─▄/ļŖ┴”
- 3. Accelerating Binarized Convolutional Neural Networks with Software- Programmable FPGAs C++ż½żķż╬║Ž│╔żŪBNNżõż├żŲż▀ż┐ SDSoC 2016.1 Zynq 7Z020 44.2 GOPS/W
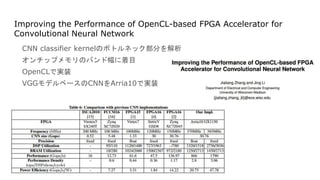
- 4. Improving the Performance of OpenCL-based FPGA Accelerator for Convolutional Neural Network CNN classifier kernelż╬ź▄ź╚źļź═ź├ź»▓┐Ęųż“ĮŌ╬÷ ź¬ź¾ź┴ź├źūźßźŌźĻż╬źąź¾ź╔Ę∙ż╦ū┼─┐ OpenCLżŪīgū░ VGGźŌźŪźļź┘®`ź╣ż╬CNNż“Arria10żŪīgū░
- 5. Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System? «Æż▀▐zż▀īėż╬ėŗ╦Ńż“£pżķż╣ż┐żßż╦FFTż╚Overlap-and-Addż“└¹ė├ ╣▓ėąźßźŌźĻż╬źŪ®`ź┐źņźżźóź”ź╚ż“╣żĘ“ VGG16, AlexNet, GoogLeNetż“123.48GFLOPS, 83.00GFLOPS, 96.60GFLOPS Intel Quick-Assist QPI FPGA Platformż“╩╣ż├żŲįuü²
- 6. Optimizing Loop Operation and Dataflow in FPGA Acceleration of Deep Convolutional Neural Networks CNNż╬«Æż▀▐zż▀īėżŪżŽ3┤╬į¬MACż¼4źņź┘źļż╬źļ®`źūż╦ż╩żļ CNNż╬źßźŌźĻźóź»ź╗ź╣ż╩ż╔ż╬īgīØŽ¾ż“ĮŌ╬÷Ż¼ūŅ▀m╗»ż╣żļ▒žę¬ż¼żóżļ źßźŌźĻźóź»ź╗ź╣ż╚źßźŌźĻęŲäėż“ūŅąĪ╗»Ż¼źĻźĮ®`ź╣╩╣ė├┴┐ż╚ąį─▄ż“ūŅ┤¾╗» Arria10GX1150ż╦īgū░ VGG-16 CNNżŪ645.25GOPSŻ¼47.97msźņźżźŲź¾źĘż“▀_│╔ State-of-the-artż╬3.2x
- 7. An OpenCLTM Deep Learning Accelerator on Arria 10 OpenCL╩╣ż├żŲźŪ®`ź┐į┘└¹ė├ż╚═Ō▓┐źßźŌźĻźąź¾ź╔Ę∙ūŅąĪ╗»ż“īg¼F Intel FPGA SDK for OpenCL Deep Learning Accelerator(DLA) AlexNetCNNź┘ź¾ź┴ź▐®`ź»żŪArria10╩╣ż├żŲ1020img/sŻ¼23img/s/W -> 1382GFLOPSż╦ŽÓĄ▒Ż©ÅŠ└┤FPGAż╬8.4xż╬GFLOPSŻ¼5.8xż╬ä┐┬╩╗»Ż® 23 img/s/WżŽnVidiaż╬TitanX GPUż╚competitive
- 8. FINN: A Framework for Fast, Scalable Binarized Neural Network Inference ? FINN: ╚ß▄øż╩źžźŲźĒźĖź╦źóź╣ź╣ź╚źĻ®`ź▀ź¾ź░źó®`źŁźŲź»ź┴źŃż“╩╣ż├żŲ╦┘ż»╚ß▄øż╩ FPGAźóź»ź╗źķźņ®`ź┐ż“śŗ║Bż╣żļźšźņ®`źÓź’®`ź» ? ZC706żŪź╚®`ź┐źļ25Wż╬źĘź╣źŲźÓ ? MNISTżŪ12.3M╗ŁŽ±/sż╬ĘųŅÉŻ«źņźżźŲź¾źĘ0.31usŻ¼Š½Č╚95.8% ? CIFAR-10ż╚SVHNż╬21906╗ŁŽ±/sż╬ĘųŅÉŻ«źņźżźŲź¾źĘ283usŻ¼Š½Č╚żŽżĮżņżŠżņ 801.%Ż¼94.9%
- 9. ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA ? Load-balance-aware pruning methodżŪLSTMźŌźŪźļż╬źĄźżź║ż“1/20ż╦ ? č}╩²ż╬PEż╦Ż¼łR┐sźŌźŪźļż“ź©ź¾ź│®`ź╔ż╚ĘųĖŅż╣żļź╣ź▒źĖźÕ®`źķ ? Efficient Speech Recognition Engine(ESE)ż╚├³├¹ ? XCKU060ż╦īgū░Ż«200MHzżŪäėū„Ż«282GOPSŻ«41W ? Core i7 5930kż╚▒╚ż┘żŲ43xĖ▀╦┘Ż¼ļŖ┴”ä┐┬╩40x ? Pascal Titan X GPUż╚▒╚ż┘żŲ3xĖ▀╦┘Ż¼ļŖ┴”ä┐┬╩11.5x
- 10. Quality-Time Tradeoffs in Component-Specific Mapping: How to Train Your Dynamically Reconfigurable Array of Gates with Outrageous Network- delays ? Component-specific▀mė├ ? A prioriż╩źŪźąźżź╣ż╬╠žÅšż╚ź½ź╣ź┐ź▐źżź║ż╩żĘżŪFPGAÜ░ż╬ź▐ź├źįź¾ź░ż“ż╣żļ ? 48-77%ż╬źŪźŻźņźżŻ¼57%ż╬ź©ź═źļź«®`ä┐┬╩ż“20├ļ╬┤£║ż╬ź▐ź├źįź¾ź░ĢrķgżŪ
- 11. Synchronization Constraints for Interconnect Synthesis źżź¾ź┐ź│ź═ź»ź╚║Ž│╔Ż«źŪ®`ź┐▄×╦═ż╬źĄźżź»źļźņź┘źļż╬═¼Ų┌ż“ūįäėĄ─ż╦Ż« FIFOź┘®`ź╣żĶżĻ43%╔┘ż╩żż├µĘe╩╣ė├┴┐ż╦ż╩żļ
- 12. Corolla: GPU-Accelerated FPGA Routing Based on Subgraph Dynamic Expansion A GPU-accelerated FPGA routing method GPUŽ“ż▒ż╬FPGA─┌ż╬ūŅČ╠źčź╣źóźļź┤źĻź║źÓż╬▀mė├ż“┐╔─▄ż╦ż╣żļ FPGAźļ®`źŲźŻź¾ź░ż╬ź½®`ź═źļżŽsingole-source shortest path(SSSP)źĮźļźą®`żŪ żóżļ
- 13. DonĪ»t Forget the Memory: Automatic Block RAM Modelling, Optimization, and Architecture Exploration BlockRAMż“ūįäėĄ─ż╦ū„żļįÆ SRAMż╚MTJ╝╝ągż╬üIĘĮż“╩╣ė├ ├µĘeŻ¼ļŖ┴”ż“ūŅ▀m╗»
- 14. Automatic Construction of Program-Optimized FPGA Memory Networks źßźŌźĻźņźżźŲź¾źĘżŽįOėŗĢrż╬ųžę¬ź▌źżź¾ź╚ źßźŌźĻź═ź├ź╚ź’®`ź»ż╬ūŅ▀m╗»ż¼ąį─▄Ž“╔Žż╬ź½ź« źšźŻ®`ź╔źąź├ź»ź╔źĻźųź¾ż╬ź═ź├ź╚ź’®`ź»ź│ź¾źčźżźķż“įOėŗżĘż┐ 45%ż╬įOėŗź▓źżź¾ż“▀_│╔ ꬿŽLEAPż╬įÆ
- 15. NAND-NOR: A Compact, Fast, and Delay Balanced FPGA Logic Element And-Inverter Cone(AIC)żŽLUTż╦īØż╣żļ┤·╠µż╚żĘżŲ╠ß░ĖżĄżņż┐ ąį─▄ż╚źĻźĮ®`ź╣źµ®`źŲźŻźĻź╝®`źĘźńź¾ż“Ž“╔Ž Delay discrepancy problemż¼żóżļ įOėŗ╩ųĘ©ż¼ūŅ▀mż½żĄżņżŲżżż╩żż Ī·żŌż├ż╚ūŅ▀mż╩NAND-NORż╚delay-balancedż╩dual-phasedż╩ź▐źļź┴źūźņź»źĄż╩źó®` źŁźŲź»ź┴źŃż“╠ß░Ėż╣żļżĶ
- 16. 120-core microAptiv MIPS Overlay for the Terasic DE5-NET FPGA board 120-core 94MHzż╬MIPSźūźĒź╗ź├źĄż“ū„ż├ż┐ ▌X┴┐ż╩źßź├ź╗®`źĖźčź├źĘź¾ź░ÖCśŗżŪĮėŠAżĄżņżļ Stratix V GX (5SGXEA7N2F45C2)ż╦īgū░
- 17. A Parallelized Iterative Improvement Approach to Area Optimization for LUT-Based Technology Mapping źĒźĖź├ź»ź▐ź├źįź¾ź░ż╚źŪźąźżź╣ź▐ź├źįź¾ź░ż╦żŽź«źŃź├źūż¼żóżļ PIMapż“╠ß░Ė ├µĘeż“ūŅąĪ╗»ż╣ż┘ż»źĒźĖź├ź»ēõōQż╚źŲź»ź╬źĒźĖ®`ź▐ź├źįź¾ź░ż“Ę┤Å═Ą─ż╦ąąż” EPFLź┘ź¾ź┴ż╦īØżĘżŲūŅ┤¾14%Ż¼ŲĮŠ∙żŪ7%├µĘeŽ„£pż“▀_│╔
- 18. A Parallel Bandit-Based Approach for Autotuning FPGA Compilation ║Ž│╔ź─®`źļź¬źūźĘźńź¾ż╬ūįäėź┴źÕ®`ź╦ź¾ź░ Multi-armed bandit(MAB)żŪź¬źūźĘźńź¾ż“ź┴źÕ®`ź╦ź¾ź░
- 19. Hardware Synthesis of Weakly Consistent C Concurrency Cż½żķż╬Ė▀╬╗║Ž│╔żŪLock-freeźóźļź┤źĻź║źÓ LegUpż╦sequentially consistent(SC)ż╚weakly consistent(weak) atmicsż“ī¦╚ļ 裣hźąź├źšźĪż╬īgū░żŪŻ¼źĒź├ź»żóżĻż╬ł÷║Žż╚▒╚ż┘żŲ2.5xĖ▀╦┘╗» Weak atomicsżŽżĄżķż╦1.5xź╣źį®`ź╔źóź├źū
- 20. A New Approach to Automatic Memory Banking using Trace-Based Address Mining TraceBankingż“╠ß░Ė Trace-drivenż╩źóź╔źņź╣ūŅąĪ╗»źóźļź┤źĻź║źÓ ŅåŚ╩│÷źóźļź┤źĻź║źÓż╦īØżĘżŲarea-efficientż╩źßźŌźĻĘųĖŅż“īg¼FżŪżŁż┐ ź│ź¾źčźżźļź┐źżźÓż╬Š▓Ą─ż╩ūŅ▀m╗»żŪżŽż╩ źóź»ź╗ź╣źčź┐ź¾ż“├„╩ŠĄ─ż╦ųĖČ©ż╣żļ▒žę¬ż¼ż╩żż
- 21. Dynamic Hazard Resolution for Pipelining Irregular Loops in High-Level Synthesis ? HLSż╬źčźżźūźķźżź╦ź¾ź░żŽŻ¼ęÄätĄ─żŪź╣ź┐źŲźŻź├ź»ż╩źßźŌźĻźóź»ź╗ź╣źčź┐ź¾ż╦żŽżÓżż żŲżżżļ -> infrequent data-dependent structuralż╦żŽėąä┐żŪżŽż╩żż ? źżźņź«źÕźķż╩źļ®`źūż╦īØż╣żļĖ▀ź╣źļ®`źūź├ź╚ż╬źčźżźūźķźżź¾╗»ż“īg¼Fż╣żļ ? ź│ź¾źčźżźļĢrż╦źŽźČ®`ź╔ż“ĮŌøQżĘż┐źóź░źņź├źĘźųż╩źčźżźūźķźżź¾ż“╔·│╔ ? Hazard Resolution Unit(HRU)ż“ī¦╚ļŻ«D-HRU(data)ż╚S-HUR(structure)
- 22. Accelerating Face Detection on Programmable SoC Using C-Based Synthesis ? HLSżŽ▀M╗»żĘżŲżļż▒ż╔¼FīgĄ─ż╩ź┘ź¾ź┴ź▐®`ź»ż¼▓╗ūѿʿŲżżżļ ? Viola Jonesźóźļź┤źĻź║źÓź┘®`ź╣ż╬ŅåŚ╩│÷źóź»ź╗źķźņ®`ź┐ż╬ź▒®`ź╣ź╣ź┐źŪźŻ ? źĮźšź╚ź”ź¦źóź┘®`ź╣ż╬źŪźČźżź¾ż½żķHLS╠ž╗»źŪ®`ź┐śŗįņż╚ūŅ▀m╗»ż“╩╣ż├ż┐║Ž│╔┐╔─▄ż╩ īgū░żžż╬ęŲų▓żŪż’ż½ż├ż┐ż│ż╚ż“źĘź¦źó ? ż│ż╬źŪźČźżź¾żŽ30FPSżŪŻ¼ÅŠ└┤ż╬RTLįOėŗż╚comparableżŪżóżļ
- 23. Packet Matching on FPGAs Using HMC Memory: Towards One Million Rules ? Hybrid Memory Cube(HMC)ż“╩╣ż├ż┐FPGAż╦żĶżļźčź▒ź├ź╚ĘųŅÉ ? źūźĻźšź¦ź├ź┴żŪHMCźóź»ź╗ź╣źņźżźŲź¾źĘż“ļL▒╬żĘźßźŌźĻż½żķź▐ź├ź┴ź¾ź░ź©ź¾źĖź¾ż╦źļ ®`źļż“▄×╦═ ? Kintex Ultrascale 060ż╦īgū░Ż«160źčź▒ź├ź╚ż“üK┴ąż╦äI└ĒŻ«10Gbpsźķźżź¾źņ®`ź╚żŪ ╝s1500źļ®`źļż“Ż¼16Mbpsźķźżź¾źņ®`ź╚żŪ1Mźļ®`źļż“äI└Ē
- 24. Boosting the Performance of FPGA-based Graph Processor using Hybrid Memory Cube: A Case for Breadth First Search ? Š▐┤¾ż╩īg╩└Įńź░źķźšż“ÆQż”ż╬żŽļyżĘżż ? ģgż╦źšź├ź╚źūźĻź¾ź╚ż╬å¢Ņ}ż└ż▒żŪż╩ż»żŲŻ¼źūźóż╩Šų╦∙ąįŻ¼źóź»ź╗ź╣źņźżźŲź¾źĘż╬ż┐żß ? HMC╩╣ż├żŲż▀ż┐ ? HMCźóź»ź╗ź╣źņźżźŲź¾źĘż╚BFS(Ę∙ā׎╚╠Į╦„)ąį─▄ż╦īØż╣żļ Č©┴┐Ą─ż╩įuü²ż╬ż┐żßż╬ĮŌ╬÷Ą─ż╩ąį─▄źŌźŪźļż“ķ_░k ? 2-level bitmap scheme ? Micronż╬AC-510ķ_░kźŁź├ź╚żŪįuü²Ż« ? GRAPH500ź┘ź¾ź┴ź▐®`ź»żŪ(ź╣ź▒®`źļ25/źšźĪź»ź┐16)żŪįuü² ? 166M edge traverced/s(MTEPS)ż“▀_│╔
- 25. ForeGraph: Exploring Large-scale Graph Processing on Multi-FPGA Architecture FPGAż╬ź¬ź¾ź┴ź├źūźßźŌźĻżŽźķź¾ź└źÓźŪ®`ź┐źóź»ź╗ź╣ż╦Ė▀żżź╣źļ®`źūź├ź╚ ģgę╗ż╬FPGAż╬ź¬ź¾ź┴ź├źūźßźŌźĻż╦żŽųŲ╝sż¼żóżļ č}╩²FPGAż“╩╣ż├ż┐┤¾ęÄ─Żź░źķźšäI└Ēź©ź¾źĖź¾ż“╠ß░Ė Xilinx Virtex UltraScale XVCU190(VCU110ź▄®`ź╔)ż“╩╣ė├ YT,WK,LJ,TW,YHź░źķźšż╦īØżĘżŲBFS,PR,WCCż“äI└Ē TW(41.7M Vertecies, 1.47M Edge)żŽ4FPGAżŪäI└Ē State-of-the Art(PowerGraph)ż╦īØżĘżŲ5.04xĖ▀╦┘╗»ż“▀_│╔ Ž╚ąąFPGAż╦īØżĘżŲŲĮŠ∙ź╣źļ®`źūź├ź╚żŪ2.03▒Čż“▀_│╔
- 26. FPGA-Accelerated Transactional Execution of Graph Workloads ? Š▐┤¾ź░źķźšżžż╬źóź»ź╗ź╣żŪżŽźßźŌźĻź│ź¾źšźĻź»ź╚ż¼ŲżŁżļ ? ź╣ź▒®`źķźųźļż╩ź│ź¾źšźĻź»ź╚Ś╩│÷ż“╩Šż╣ ? Intel Haswelż╚ż»żķż┘żŲ2▒Čż╬ąį─▄Ž“╔ŽŻ¼ 22▒Čż╬ź©ź═źļź«®`ä┐┬╩ ? FPGA Research Infrastructure Cloud[42]ż“└¹ė├ ? http://www.openfabric.org
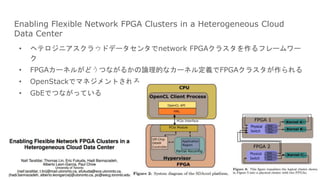
- 27. Enabling Flexible Network FPGA Clusters in a Heterogeneous Cloud Data Center ? źžźŲźĒźĖź╦źóź╣ź»źķź”ź╔źŪ®`ź┐ź╗ź¾ź┐żŪnetwork FPGAź»źķź╣ź┐ż“ū„żļźšźņ®`źÓź’®` ź» ? FPGAź½®`ź═źļż¼ż╔ż”ż─ż╩ż¼żļż½ż╬šō└ĒĄ─ż╩ź½®`ź═źļČ©┴xżŪFPGAź»źķź╣ź┐ż¼ū„żķżņżļ ? OpenStackżŪź▐ź═źĖźßź¾ź╚żĄżņżļ ? GbEżŪż─ż╩ż¼ż├żŲżżżļ
- 28. Energy Efficient Scientific Computing on FPGAs using OpenCL ? Partial differential equations(PDE; Ų½╬óĘųĘĮ│╠╩Į) ż╬ä┐┬╩Ą─ż╩īgū░ż¼▒žę¬ ? FPGAż╬źŪ®`ź┐üK┴ąąįżŪPDEźĮźļźąż“ ? HDLżŽļyżĘżżż╬żŪOpenCLżŪĪ·żŪżŌļyżĘżż ? OpenCLż“╩╣ż├ż┐PDEźĮźļźąż╬ż┐żßż╬ę╗░ŃĄ─żŪūŅ▀m╗»ż╬╠žü²żĘż┐░³└©Ą─ż╩ź╗ź├ź╚ż“╠ß░Ė
- 29. Secure Function Evaluation Using an FPGA Overlay Architecture SFEŽ“ż▒ż╬źŽ®`ź╔ź”ź¦źóźóź»ź╗źķźņ®`ź┐ ę╗░ŃĄ─ż╩źĻź│ź¾źšźŻź«źŃźķźųźļźŽ®`ź╔ź”ź¦źóŽ“żŁż╬┤ų┴ŻČ╚ż╩FPGAź¬®`źą®`źņźżźó®`źŁźŲź»ź┴źŃ
- 30. FPGA Acceleration for Computational Glass-Free Displays FPGAźóź»ź╗źķźņ®`źĘźńź¾ż“ż─ż½ż├ż┐eyeglasses-freeźŪźŻź╣źūźņźż Sparse matrix-vector multiplication L-BFGS iterative optimization algorithm glass-freeźŪźŻź╣źūźņźżźóźūźĻź▒®`źĘźńź¾żŪ12.78xż╬Ė▀╦┘╗»
- 31. Hardware Acceleration of the Pair-HMM Algorithm for DNA Variant Calling Pair HMM forwardźóźļź┤źĻź║źÓż╬FPGAżŪż╬Ė▀╦┘╗» źĻź¾ź░śŗįņż╬PEżŪILPż╚źŪ®`ź┐üK┴ąąįż“┐╝æ]żĘżŲśöĪ®ż╩śŗ│╔ż“ż╚żļ C++ź┘®`ź╣ż╬CPUīgąąż╚ż»żķż┘żŲ487xĖ▀╦┘Ż¼źŽ®`ź╔ź”ź¦źóīgū░ż╚▒╚ż┘żŲ1.56xĖ▀╦┘