3. Vertex AIを用いた時系列テ?ータの解析
1 like666 views
機械学習の社会実装勉強会第6回で発表した内容です。Vertex AIでCovid-19の感染者数予測モデルを作成しました。 https://www.youtube.com/channel/UCrjRZ4D2tpqV5UI2XSUKQ6g
1 of 15
Download to read offline








Ad
Recommended
Vertex AI Pipelinesで BigQuery MLのワークフローを管理 (ETL ~ デプロイまで)
Vertex AI Pipelinesで BigQuery MLのワークフローを管理 (ETL ~ デプロイまで)幸太朗 岩澤
?
Vertex AI Pipelinesで
BigQuery MLのワークフローを作成しました。機械学習の社会実装勉強会 第12回の発表内容です。
https://machine-learning-workshop.connpass.com/event/250263/惭尝翱辫蝉の概要と初学者が気をつけたほうが良いこと
惭尝翱辫蝉の概要と初学者が気をつけたほうが良いことSho Tanaka
?
2021/7/31 機械学習の社会実装勉強会にて発表した内容です。
タイトル:惭尝翱辫蝉の概要と初学者が気をつけたほうが良いこと机械学习によるデータ分析まわりのお话
机械学习によるデータ分析まわりのお话Ryota Kamoshida
?
某所で機械学習の講習会(?)のようなものをしたときの資料です.
機械学習によるデータ分析について,アルゴリズムやツールの使い方*以外*の部分で
重要だと思うことを重点的にまとめたつもりです.データサイエンティストのつくり方
データサイエンティストのつくり方Shohei Hido
?
2012/09/13 PFIセミナー「データサイエンティストのつくり方」資料
Ustreamの録画はこちらです→ http://www.ustream.tv/recorded/25376704トピックモデルの評価指標 Perplexity とは何なのか?
トピックモデルの評価指標 Perplexity とは何なのか?hoxo_m
?
『トピックモデルによる統計的潜在意味解析』読書会ファイナル ~佐藤一誠先生スペシャル~ LT 資料
http://topicmodel.connpass.com/event/27999/机械学习モデルの判断根拠の説明
机械学习モデルの判断根拠の説明Satoshi Hara
?
The document discusses the rights of data subjects under the EU GDPR, particularly regarding automated decision-making and profiling. It outlines conditions under which such decisions can be made, emphasizing the need for measures that protect the data subjects' rights and freedoms. Additionally, it includes references to various machine learning and artificial intelligence interpretability frameworks and studies.机械学习を使った时系列売上予测
机械学习を使った时系列売上予测DataRobotJP
?
顿补迟补搁辞产辞迟を用いて时系列モデルの作成する方法を绍介します。その后、どのような特徴量を使えば精度が良くなるのか、データにどのような前処理を行えば良いのか、トレンドデータや集约データを使った时系列予测など様々なトピックについて触れていきます。Deep Learningで似た画像を見つける技術 | OHS勉強会#5
Deep Learningで似た画像を見つける技術 | OHS勉強会#5Toshinori Hanya
?
Deep Learningで画像間の類似度を扱う技術を勉強しました。Chainerによる実験も行っています。深層学習の不確実性 - Uncertainty in Deep Neural Networks -
深層学習の不確実性 - Uncertainty in Deep Neural Networks -tmtm otm
?
Twitter: ottamm_190
追記 2022/4/24
speakerdeck版:https://speakerdeck.com/masatoto/shen-ceng-xue-xi-falsebu-que-shi-xing-uncertainty-in-deep-neural-networks
コンパクト版:https://speakerdeck.com/masatoto/shen-ceng-xue-xi-niokerubu-que-shi-xing-ru-men【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
【DL輪読会】Efficiently Modeling Long Sequences with Structured State SpacesDeep Learning JP
?
This document summarizes a research paper on modeling long-range dependencies in sequence data using structured state space models and deep learning. The proposed S4 model (1) derives recurrent and convolutional representations of state space models, (2) improves long-term memory using HiPPO matrices, and (3) efficiently computes state space model convolution kernels. Experiments show S4 outperforms existing methods on various long-range dependency tasks, achieves fast and memory-efficient computation comparable to efficient Transformers, and performs competitively as a general sequence model.失败から学ぶ机械学习応用
失败から学ぶ机械学习応用Hiroyuki Masuda
?
社内勉强会での発表資料です。
「失敗事例を通じて、機械学習の検討で抑えるべきポイントを学ぶ」をコンセプトに作成しました。AI?機械学習を検討する広くの方々に活用していただけると幸いです。
あとがきを下記に書きました。よければこちらもご参照ください。
https://qiita.com/bezilla/items/1e1abac767e10d0817d1CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1Masashi Shibata
?
Optuna Meetup #1
https://optuna.connpass.com/event/207545/アンサンブル木モデル解釈のためのモデル简略化法
アンサンブル木モデル解釈のためのモデル简略化法Satoshi Hara
?
* Satoshi Hara and Kohei Hayashi. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. AISTATS'18 (to appear).
arXiv ver.: https://arxiv.org/abs/1606.09066#
* GitHub
https://github.com/sato9hara/defragTrees【DL輪読会】AUTOGT: AUTOMATED GRAPH TRANSFORMER ARCHITECTURE SEARCH
【DL輪読会】AUTOGT: AUTOMATED GRAPH TRANSFORMER ARCHITECTURE SEARCHDeep Learning JP
?
2023/3/31
Deep Learning JP
http://deeplearning.jp/seminar-2/7. Vertex AI Model Registryで BigQuery MLのモデルを管理する
7. Vertex AI Model Registryで BigQuery MLのモデルを管理する幸太朗 岩澤
?
機械学習の社会実装勉強会第10回で発表した内容です。Vertex AIのモデル管理サービス Vertex AI Model Registryを紹介しました。
<YouTube リンクを追って記載>潜在ディリクレ配分法
潜在ディリクレ配分法y-uti
?
勤め先の社内勉强会での発表資料です。日本語版 Wikipedia の抄録を対象として gensim の LdaModel を利用する例を説明した後、LDA の生成モデルについて説明します。そのうえで、gensim の LdaModel に指定できるパラメータや提供されているメソッドの意味を LDA の生成モデルに照らして確認します。摆顿尝轮読会闭相互情报量最大化による表现学习
摆顿尝轮読会闭相互情报量最大化による表现学习Deep Learning JP
?
2019/09/13
Deep Learning JP:
http://deeplearning.jp/seminar-2/ Amazon SageMaker で始める機械学習
Amazon SageMaker で始める機械学習Amazon Web Services Japan
?
Amazon SageMaker is a fully managed service that enables developers and data scientists to build, train, and deploy machine learning (ML) models quickly. It provides algorithms, notebooks, APIs and scalable infrastructure for building ML models. Some key features of SageMaker include algorithms for common ML tasks, notebooks for developing models, APIs for training and deployment, and scalable infrastructure for training and hosting models. It also integrates with other AWS services like S3, EC2 and VPC.PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健Preferred Networks
?
The document discusses the Optuna hyperparameter optimization framework, highlighting its features like define-by-run, pruning, and distributed optimization. It provides examples of successful applications in competitions and introduces the use of LightGBM hyperparameter tuning. Additionally, it outlines the installation procedure, key components of Optuna, and the introduction of the lightgbmtuner for automated optimization.[DL Hacks] code_representation
[DL Hacks] code_representationDeep Learning JP
?
2019/04/22
Deep Learning JP:
http://deeplearning.jp/hacks/ 14. BigQuery ML を用いた多変量時系列テ?ータの解析.pdf
14. BigQuery ML を用いた多変量時系列テ?ータの解析.pdf幸太朗 岩澤
?
機械学習の社会実装勉強会 第20回の発表内容です。
https://machine-learning-workshop.connpass.com/event/246825/機械学習 - MNIST の次のステップ
機械学習 - MNIST の次のステップDaiyu Hatakeyama
?
機械学習の jupyternotebook のコードを動かした後は、実プロジェクトへの応用を始めると思います。
そのプロジェクト自体の全体像と、その中の一部ですが
- 環境構築
- Hyperparameter Turning
- Responsible AI (Model Explanation
について、扱いますMore Related Content
What's hot (20)
机械学习を使った时系列売上予测
机械学习を使った时系列売上予测DataRobotJP
?
顿补迟补搁辞产辞迟を用いて时系列モデルの作成する方法を绍介します。その后、どのような特徴量を使えば精度が良くなるのか、データにどのような前処理を行えば良いのか、トレンドデータや集约データを使った时系列予测など様々なトピックについて触れていきます。Deep Learningで似た画像を見つける技術 | OHS勉強会#5
Deep Learningで似た画像を見つける技術 | OHS勉強会#5Toshinori Hanya
?
Deep Learningで画像間の類似度を扱う技術を勉強しました。Chainerによる実験も行っています。深層学習の不確実性 - Uncertainty in Deep Neural Networks -
深層学習の不確実性 - Uncertainty in Deep Neural Networks -tmtm otm
?
Twitter: ottamm_190
追記 2022/4/24
speakerdeck版:https://speakerdeck.com/masatoto/shen-ceng-xue-xi-falsebu-que-shi-xing-uncertainty-in-deep-neural-networks
コンパクト版:https://speakerdeck.com/masatoto/shen-ceng-xue-xi-niokerubu-que-shi-xing-ru-men【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
【DL輪読会】Efficiently Modeling Long Sequences with Structured State SpacesDeep Learning JP
?
This document summarizes a research paper on modeling long-range dependencies in sequence data using structured state space models and deep learning. The proposed S4 model (1) derives recurrent and convolutional representations of state space models, (2) improves long-term memory using HiPPO matrices, and (3) efficiently computes state space model convolution kernels. Experiments show S4 outperforms existing methods on various long-range dependency tasks, achieves fast and memory-efficient computation comparable to efficient Transformers, and performs competitively as a general sequence model.失败から学ぶ机械学习応用
失败から学ぶ机械学习応用Hiroyuki Masuda
?
社内勉强会での発表資料です。
「失敗事例を通じて、機械学習の検討で抑えるべきポイントを学ぶ」をコンセプトに作成しました。AI?機械学習を検討する広くの方々に活用していただけると幸いです。
あとがきを下記に書きました。よければこちらもご参照ください。
https://qiita.com/bezilla/items/1e1abac767e10d0817d1CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1Masashi Shibata
?
Optuna Meetup #1
https://optuna.connpass.com/event/207545/アンサンブル木モデル解釈のためのモデル简略化法
アンサンブル木モデル解釈のためのモデル简略化法Satoshi Hara
?
* Satoshi Hara and Kohei Hayashi. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. AISTATS'18 (to appear).
arXiv ver.: https://arxiv.org/abs/1606.09066#
* GitHub
https://github.com/sato9hara/defragTrees【DL輪読会】AUTOGT: AUTOMATED GRAPH TRANSFORMER ARCHITECTURE SEARCH
【DL輪読会】AUTOGT: AUTOMATED GRAPH TRANSFORMER ARCHITECTURE SEARCHDeep Learning JP
?
2023/3/31
Deep Learning JP
http://deeplearning.jp/seminar-2/7. Vertex AI Model Registryで BigQuery MLのモデルを管理する
7. Vertex AI Model Registryで BigQuery MLのモデルを管理する幸太朗 岩澤
?
機械学習の社会実装勉強会第10回で発表した内容です。Vertex AIのモデル管理サービス Vertex AI Model Registryを紹介しました。
<YouTube リンクを追って記載>潜在ディリクレ配分法
潜在ディリクレ配分法y-uti
?
勤め先の社内勉强会での発表資料です。日本語版 Wikipedia の抄録を対象として gensim の LdaModel を利用する例を説明した後、LDA の生成モデルについて説明します。そのうえで、gensim の LdaModel に指定できるパラメータや提供されているメソッドの意味を LDA の生成モデルに照らして確認します。摆顿尝轮読会闭相互情报量最大化による表现学习
摆顿尝轮読会闭相互情报量最大化による表现学习Deep Learning JP
?
2019/09/13
Deep Learning JP:
http://deeplearning.jp/seminar-2/ Amazon SageMaker で始める機械学習
Amazon SageMaker で始める機械学習Amazon Web Services Japan
?
Amazon SageMaker is a fully managed service that enables developers and data scientists to build, train, and deploy machine learning (ML) models quickly. It provides algorithms, notebooks, APIs and scalable infrastructure for building ML models. Some key features of SageMaker include algorithms for common ML tasks, notebooks for developing models, APIs for training and deployment, and scalable infrastructure for training and hosting models. It also integrates with other AWS services like S3, EC2 and VPC.PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健
PyData.Tokyo Meetup #21 講演資料「Optuna ハイパーパラメータ最適化フレームワーク」太田 健Preferred Networks
?
The document discusses the Optuna hyperparameter optimization framework, highlighting its features like define-by-run, pruning, and distributed optimization. It provides examples of successful applications in competitions and introduces the use of LightGBM hyperparameter tuning. Additionally, it outlines the installation procedure, key components of Optuna, and the introduction of the lightgbmtuner for automated optimization.[DL Hacks] code_representation
[DL Hacks] code_representationDeep Learning JP
?
2019/04/22
Deep Learning JP:
http://deeplearning.jp/hacks/ Similar to 3. Vertex AIを用いた時系列テ?ータの解析 (20)
14. BigQuery ML を用いた多変量時系列テ?ータの解析.pdf
14. BigQuery ML を用いた多変量時系列テ?ータの解析.pdf幸太朗 岩澤
?
機械学習の社会実装勉強会 第20回の発表内容です。
https://machine-learning-workshop.connpass.com/event/246825/機械学習 - MNIST の次のステップ
機械学習 - MNIST の次のステップDaiyu Hatakeyama
?
機械学習の jupyternotebook のコードを動かした後は、実プロジェクトへの応用を始めると思います。
そのプロジェクト自体の全体像と、その中の一部ですが
- 環境構築
- Hyperparameter Turning
- Responsible AI (Model Explanation
について、扱います机械学习システムの33のアーキテクチャパターンおよびデザインパターン
机械学习システムの33のアーキテクチャパターンおよびデザインパターンHironori Washizaki
?
鷲崎弘宜, 机械学习システムの33のアーキテクチャパターンおよびデザインパターン, スマートエスイーセミナー: 機械学習デザインパターンとアジャイル品質パターン, 2019年11月8日(金), 早稲田大学 西早稲田キャンパス机械学习アーキテクチャ?デザインパターン
机械学习アーキテクチャ?デザインパターンHironori Washizaki
?
鷲崎弘宜, 机械学习システムの33のアーキテクチャパターンおよびデザインパターン, スマートエスイーセミナー: 機械学習デザインパターンとアジャイル品質パターン, 2019年11月8日(金), 早稲田大学 西早稲田キャンパス骋谤补诲-颁础惭の始まりのお话
骋谤补诲-颁础惭の始まりのお话Shintaro Yoshida
?
骋谤补诲-颁础惭は齿础滨の方法の一つとして知られています。しかし、そのアイデアの期限については十分に知られていないように感じ、このスライドを作成しました。鷲崎弘宜, "高品質なAIシステムの開発?運用のための"フレームワーク", eAIシンポジウム 2025年1月16日
鷲崎弘宜, "高品質なAIシステムの開発?運用のための"フレームワーク", eAIシンポジウム 2025年1月16日Hironori Washizaki
?
鷲崎弘宜, "高品質なAIシステムの開発?運用のための"フレームワーク", eAIシンポジウム 2025年1月16日Azure Machine Learning Services 概要 - 2019年3月版
Azure Machine Learning Services 概要 - 2019年3月版Daiyu Hatakeyama
?
Azure Machine Learning Services の概要です。
データの準備、学習ジョブ、モデルの展開、Automated Machine Learning、Hyperparameter Explorer、ONNIX、WindowsMLなどが含まれています。概念モデリングによるビジネスの见える化とシステム开発のデジタルトランスフォーメーション.辫辫迟虫
概念モデリングによるビジネスの见える化とシステム开発のデジタルトランスフォーメーション.辫辫迟虫Knowledge & Experience
?
2022/12/6 に実施した、ALGYAN オンラインセミナー資料
https://algyan.connpass.com/event/265295
”概念モデリングによるビジネスの見える化”と、”概念モデリングをベースにした変換による実装を活用したシステム開発のデジタルトランスフォーメーション”を解説。
データ仮想化を活用したデータ分析のフローと分析モデル作成の自动化のご绍介
データ仮想化を活用したデータ分析のフローと分析モデル作成の自动化のご绍介Denodo
?
Watch full webinar here: https://bit.ly/3QM4bgI
データ仮想化(Denodo)を活用した当社の考えるアーキテクチャーの中から今回はDenodoとプログラミング言語の一例としてPythonにフォーカスをあてて、データの理解?データの準備?モデル作成?評価?展開のフローとそれぞれで用いる仕組みと注目ポイントについてご紹介致します。
また分析モデル作成の自動化をご支援する仕組みとしてDataRobotの概要と注目ポイント についてもご紹介致します。Python / R で使うSAS Viya
Python / R で使うSAS ViyaSAS Institute Japan
?
SASの新データ分析プラットフォームはSAS言語のみならずPython、R、Java、Lua、REST APIで操作することができます。本資料ではPython、RでSAS Viyaを使って機械学習する方法を紹介します。厂别蝉蝉颈辞苍4:「先进ビッグデータ応用を支える机械学习に求められる新技术」/比戸将平
厂别蝉蝉颈辞苍4:「先进ビッグデータ応用を支える机械学习に求められる新技术」/比戸将平Preferred Networks
?
PFIオープンセミナー2012「多様化する情報を支える技術」
2012年9月21日(金)実施
?概要?Hadoopが大規模データ処理に広く用いられれる一方、その限界も見え始めてきた。一方、データに潜む複雑な因果関係や傾向を発見し精度の良い予測を実現する機械学習技術は性能向上と適用範囲の拡大を続けている。本講演ではビッグデータとその先進アプリケーションについて、間を繋ぐ機械学習技術の観点から最新動向について述べる。特に、PFIがフォーカスしているリアルタイム性とトレーサビリティについて詳しく述べ、JubatusとBazilという製品を紹介する。 機械学習応用システムのアーキテクチャ?デザイパターン(2020-07 ドラフトバージョン))
機械学習応用システムのアーキテクチャ?デザイパターン(2020-07 ドラフトバージョン))HironoriTAKEUCHI1
?
JST未来社会 未来社会創造事業 機械学習を用いたシステムの高品質化?実用化を加速する”Engineerable AI”(eAI)プロセスパターンチーム による機械学習応用システムのアーキテクチャ?デザインパターンの整理
Azure Machine Learning services 2019年6月版
Azure Machine Learning services 2019年6月版Daiyu Hatakeyama
?
Azure Machine Learning servicesの概要資料です。データクリーニング?AutoML含む学習?k8s, IoTも選択肢の展開、そしてMLOpsの概要です。
サービス自体が逐次更新されますので、あくまでスナップショットとして。Ad
More from 幸太朗 岩澤 (11)
15. Transformerを用いた言語処理技術の発展.pdf
15. Transformerを用いた言語処理技術の発展.pdf幸太朗 岩澤
?
機械学習の社会実装勉強会 第21回の発表内容です。
https://machine-learning-workshop.connpass.com/event/275945/BigQuery ML for unstructured data
BigQuery ML for unstructured data幸太朗 岩澤
?
機械学習の社会実装勉強会 第15回の発表内容です。
オブジェクトテーブルという新しい仕組みを使ってBigQuery ML で画像データを推論することができるようになりました。12. Diffusion Model の数学的基礎.pdf
12. Diffusion Model の数学的基礎.pdf幸太朗 岩澤
?
巷で話題の画像生成サービス, Stable Diffusion, Midjourney, DALL-E2 の基盤となる 生成モデルDiffusion Model の解説です。
機械学習の社会実装勉強会 第15回の発表内容です。
https://machine-learning-workshop.connpass.com/event/246825/行列分解の数学的基础.辫诲蹿
行列分解の数学的基础.辫诲蹿幸太朗 岩澤
?
第13回に引き続き、行列分解モデルの数学的な基礎を紹介しました。機械学習の社会実装勉強会 第14回の発表内容です。
<Attach YouTube link>BigQuery MLの行列分解モデルを 用いた推薦システムの基礎
BigQuery MLの行列分解モデルを 用いた推薦システムの基礎幸太朗 岩澤
?
BigQuery MLの行列分解モデルを用いて映画のレコメンドエンジンを作成しました。機械学習の社会実装勉強会 第13回の発表内容です。
<Attach YouTube link>Vertex AI Pipelinesで BigQuery MLのワークフローを管理
Vertex AI Pipelinesで BigQuery MLのワークフローを管理幸太朗 岩澤
?
Vertex AI Pipelinesで
BigQuery MLのワークフローを作成しました。機械学習の社会実装勉強会 第11回の発表内容です。
https://machine-learning-workshop.connpass.com/event/246825/
6. Vertex AI Workbench による Notebook 環境.pdf
6. Vertex AI Workbench による Notebook 環境.pdf幸太朗 岩澤
?
機械学習の社会実装勉強会第9回で発表した内容です。Vertex AIの1サービスしてインスタンスベースでJupyter 環境が使用できるWorkbenchを紹介しました。
<YouTubeリンクを追って記載>5. Big Query Explainable AIの紹介
5. Big Query Explainable AIの紹介幸太朗 岩澤
?
機械学習の社会実装勉強会第8回で発表した内容です。
https://www.youtube.com/watch?v=fmMy2fp0pOQ4. CycleGANの画像変換と現代美術への応用
4. CycleGANの画像変換と現代美術への応用幸太朗 岩澤
?
CycleGANを用いてHenri Matisse の作品を学習させた画像変換モデルを作成しました。
https://www.youtube.com/watch?v=Bjbbcng6qOQ2. BigQuery ML を用いた時系列テ?ータの解析 (ARIMA model)
2. BigQuery ML を用いた時系列テ?ータの解析 (ARIMA model)幸太朗 岩澤
?
This document discusses using ARIMA models with BigQuery ML to analyze time series data. It provides an overview of time series data and ARIMA models, including how ARIMA models incorporate AR and MA components as well as differencing. It also demonstrates how to create an ARIMA prediction model and visualize results using BigQuery ML and Google Data Studio. The document concludes that ARIMA models in BigQuery ML can automatically select the optimal order for time series forecasting and that multi-variable time series are not yet supported.1. BigQueryを中心にした ML datapipelineの概要
1. BigQueryを中心にした ML datapipelineの概要幸太朗 岩澤
?
This document discusses using BigQuery as the central part of an ML data pipeline from ETL to model creation to visualization. It introduces BigQuery and BigQuery ML, showing how ETL jobs can load data from Cloud Storage into BigQuery for analysis and model training. Finally, it demonstrates this process by loading a sample CSV dataset into BigQuery and using BigQuery ML to create and evaluate a prediction model.Ad
3. Vertex AIを用いた時系列テ?ータの解析
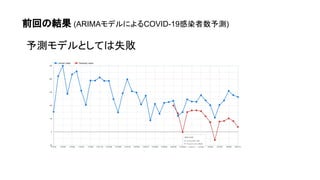
- 3. 前回やったこと - ARIMAモデルの概要 - ARIMAモデルを用いたCOVID-19感染者数予測 【第5回】BigQueryML を用いた時系列データの分析( ARIMAモデル)
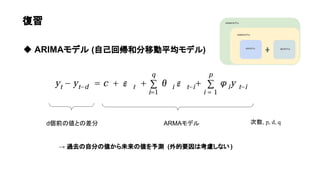
- 4. ◆ ARIMAモデル (自己回帰和分移動平均モデル) ARMAモデル 次数, p, d, q d個前の値との差分 復習 → 過去の自分の値から未来の値を予測 (外的要因は考慮しない ) (ARMA + 和分過程 ) ARモデル MAモデル ARMAモデル ARIMAモデル
- 6. 反省:時系列データ予測の難しさ 一変量時系列解析 - 日付、 感染者数 多変量時系列解析 - 日付、感染者数、 人出、ワクチン接種者数、 人口統計、気温、... 長期的傾向(トレンド) - 増加 or 減少 周期性 - 週次 - 季節性 (?) 外的要因 (複数の特徴量) - 大規模イベント - 衛生意識の変化 - 変異株の出現 - … 過去の自分の値から 将来の値を予測
- 7. 本日の内容 - Vertex AI の概要 - Vertex AI を用いた時系列データの解析 - 予測結果の可視化
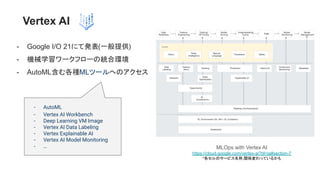
- 8. Vertex AI MLOps with Vertex AI https://cloud.google.com/vertex-ai?hl=ja#section-7 *各セルのサービス名称,関係変わっているかも - Google I/O 21にて発表(一般提供) - 機械学習ワークフローの統合環境 - AutoML含む各種MLツールへのアクセス - AutoML - Vertex AI Workbench - Deep Learning VM Image - Vertex AI Data Labeling - Vertex Explainable AI - Vertex AI Model Monitoring - …
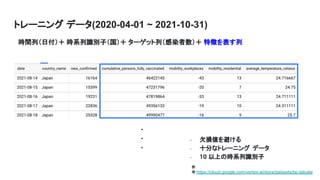
- 10. トレーニング データ(2020-04-01 ~ 2021-10-31) 時間列(日付)+ 時系列識別子(国)+ ターゲット列(感染者数)+ 特徴を表す列 - 欠損値を避ける - 十分なトレーニング データ - 10 以上の時系列識別子 . . . 参 考:https://cloud.google.com/vertex-ai/docs/datasets/bp-tabular
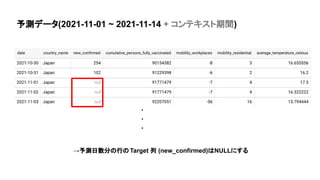
- 11. 予測データ(2021-11-01 ~ 2021-11-14 + コンテキスト期間) →予測日数分の行のTarget 列 (new_confirmed)はNULLにする . . .
- 12. Demo
- 13. ….… ( ^ ω ^ )
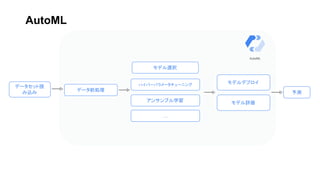
- 14. - 最新の知見を用いた多変量時系列解析がUI上で実行できた - 人の手はある程度必要 - 一定のデータセット理解 - 説明変数選択 - 前処理 - 評価指標選択 - 説明性 - Auto MLの料金のご確認を、ご利用は計画的に 所感
- 15. 参考文献?リンク コードはこちら https://github.com/kootr/ml-study-session Vertex AI AutoML ForecastingでDNNの強力な多変量時系列予測を自動モデリングしてしまおう Vertex AI ではじめる時系列分析入門 How to build forecasting models with Vertex AI ML 入門: Vertex AI のラーニングパス Using AutoML for Time Series Forecasting GCP: AutoML AutoMLで破産しないように気をつけたいポイント GCPのAutoMLを使っていたら12万の請求?がきてしまった話 Summary of rules for identifying ARIMA models