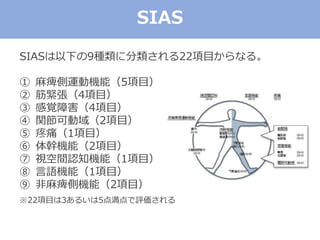
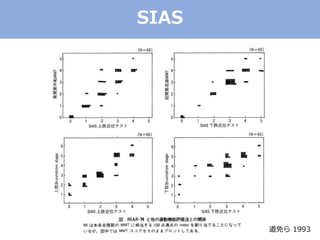
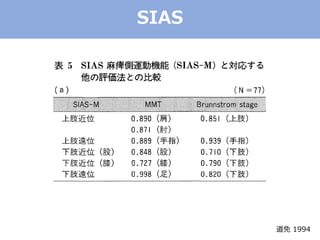
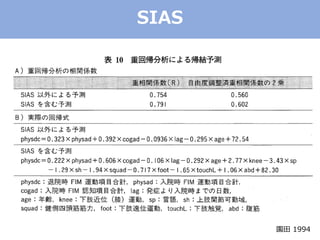
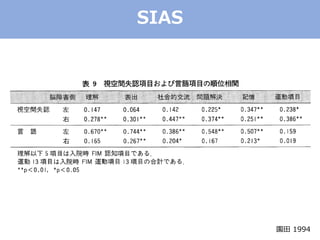
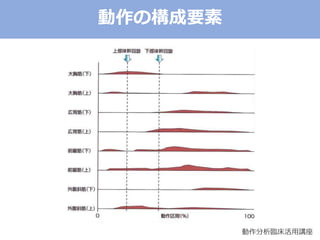
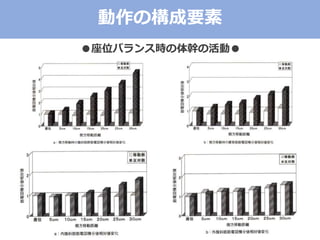
The document discusses categorical factor analysis using R, emphasizing the importance of suitable data scales for accurate results. It outlines the procedure for conducting factor analysis, including correlation matrix creation and factor determination through eigenvalue decomposition. The text also highlights the use of specific correlation coefficients for ordinal data, such as polychoric and polyserial correlations, and presents R code examples for practical implementation.
This document summarizes a research paper on scaling laws for neural language models. Some key findings of the paper include:
- Language model performance depends strongly on model scale and weakly on model shape. With enough compute and data, performance scales as a power law of parameters, compute, and data.
- Overfitting is universal, with penalties depending on the ratio of parameters to data.
- Large models have higher sample efficiency and can reach the same performance levels with less optimization steps and data points.
- The paper motivated subsequent work by OpenAI on applying scaling laws to other domains like computer vision and developing increasingly large language models like GPT-3.
The document discusses categorical factor analysis using R, emphasizing the importance of suitable data scales for accurate results. It outlines the procedure for conducting factor analysis, including correlation matrix creation and factor determination through eigenvalue decomposition. The text also highlights the use of specific correlation coefficients for ordinal data, such as polychoric and polyserial correlations, and presents R code examples for practical implementation.
This document summarizes a research paper on scaling laws for neural language models. Some key findings of the paper include:
- Language model performance depends strongly on model scale and weakly on model shape. With enough compute and data, performance scales as a power law of parameters, compute, and data.
- Overfitting is universal, with penalties depending on the ratio of parameters to data.
- Large models have higher sample efficiency and can reach the same performance levels with less optimization steps and data points.
- The paper motivated subsequent work by OpenAI on applying scaling laws to other domains like computer vision and developing increasingly large language models like GPT-3.